reflexive, symmetric, irreflexive의내용을
숙지하여 이것을 이용한 프로그램을 만드는 것이 이번 프로젝트의 목표입니다.
이번 프로젝트를 진행하게 된 배경은 먼저 이산치 수학의 관계에서부터 시작하게 되었습니다.
*관계란? 네이버의 사전의 정의에 의하면 여러 가지 뜻을 가지고 있으나 그중에 대표적인 것으로는 “둘
이상의 사람, 사물, 현상 따위가 서로 관련을 맺거나 관련이 있음. 또는 그런 관련.”으로 정의 되어있다. 즉,
수학에서 말하는 관계라 하면 둘 이상의 집합이 서로 관계 되는 것을 말한다. 이러한 관계 중에서 이번
프로젝트에서 중점을 둔 관계는 이항 관계에 대한 것입니다.
*이항관계(binary relation)이란? 집합 A와 집합B가 존재 할 때, A에서 B로의 이항관계 R은 AXB의
부분집합. 즉,(x,y)가 R에 속할 때, x is related to y by R.
로 정의되어 있다. 이 말은 AXB는 Cartesian Product이므로 이것은 집합일 때 성립하는 것으로 이항 관계는
집합론만을 가지고 정의 될수 있다고 ‘
A에 대하여 xRx가
성립하고(즉, 각원소가 자기 자신과 관계있을때를 칭함), R이 대칭성(symmetric)이면 모든 A의 원소
x,y A에 대하여, xRy이면 yRx가 성립한다.
(즉 이것은 한원소가 두 번째 원소와 관계에 있다면, 거꾸로도 성립함)그리고 transitive(이행성)은 모든
x,y A에 대해,xRy이고 yRz이면 xRz가 성립하는 것을 말한다.(즉, 1원소가 2원소가 관계있고, 2원소와
3원소가 관계있다면, 1원소와 3원소가 관계있다.) 이것은 다음 그림을 보던 더 자세히 알 수 있다.
4.
일정 03.14(수요일)
http://air.changwon.ac.kr/wp-content/uploads/2012/01/02-relation-
function.pdf
위의 내용이 이번 과제의 문제와 학습할 내용이 포함된 자료인데,
서로의 업무를 분담하기 전에 각자 자료를 조사한 후에 이번 주
회의
토요일 까지 각자 자료를 조사하기로 결정하였다.
내용.
이 내용을 토대로 알수 있는 것은 만약 대칭성을 가진 자료를
테이블에서 추출 해내서 새로운 테이블로 합치려고 할 때 이
프로그램을 토대로 사용하면 하나의 새로운 테이블을 생성(Join) 할수
있다는 것을 토의를 통해 알게 되었다.
회의 다음 모임 까지 이번 과제의 학습내용에 대한 정리와 어떤 식
결과
및 으로 보고서를 정리 할 것 인지에 대해서 조사해 오기로 결정
하였다.
토의
일정 03.17(토요일)
문제 파악과 학습내용의 자료(노트정리자료 참조)를 토대로 크게
2팀으로 나누기로 결정하였는데 프로그래밍 팀과 조사팀으로 나누기로
결정을 하였다.
여기서 프로그래밍 팀의 박찬흥 팀원이 알고리즘을 행렬로 바로
받아서 이번 프로그램을 만들어 보겠다고 하였고, 조장인 윤정현이
책의 자료를 조사한 것을 보고 1차원 배열로 받아 집합을 증명하는
회의
방법으로 하는 것으로 토의 하였었는데. 그렇게 해서 함수를 받으면
내용.
오히려 프로그램을 만드는 것에 대해서 조금더 복잡해질수도 있다는
것을 프로그래밍 팀에서 말을 해주었고, 그래서 결국 행렬에서
문자열로 받아서 2차원 배열로 만드는 식으로 알고리즘을 짜는 것으로
결정을 내리게 되었다. 그리고 조사팀에서는 학습내용에 관한 문제를
찾고, N항 관계와 관계 데이터 베이스 시스템에 대해서 간단히 조사해
오는 것으로 결정하였다.
5.
-알고리즘은 입력값을 받고바로 입력 받은 값을 비교하는 소
회의
결과 스로 만들기로 결정하였습니다.
-조사팀에서는 학습내용에 관한 예시 문제와 N항 관계와 데이
및 터 베이스 시스템에 대한 관계에 대해서 조사하기로 결정하였
토의
습니다.
일정 03.19(월요일)
회의
내용.
6.
회의 -다음번 모임 때 까지 프로그램의 소스 보완점을 찾고, 보고서
결과 내용을 정리 하는 것으로 결정 하였습니다.
및 -함수에 대한 내용 정리를 해서 같이 공부하는 것으로 결정하
토의 였습니다.
일정 03.23(금요일)
회의
내용.
8.
-OUTT라는 라벨을 이용해서goto문을 사용해서 나가는 방식을
이용해 출력 구문의 크기를 줄이기로 결정하였습니다.
-그리고 함수에 관한 학습내용은
프로그램 실행시 입력부분은 [[0,1][0,0,1][1,0]]과 같이 프로젝트
문제와 같은 방식으로 문자를 입력하게 하였고 그 결과로 나
회의 오는 것으로 만들어 졌다.
결과 출력 부분은 프로젝트 과제의 목표와 같이 만들어 졌으며,
및 위의 소스 설명처럼 정방 행렬이 아니면 반사성(reflexive)와 비
토의 반사성(irreflexive)가 no를 출력하는 형식으로 만들게 되었습니
다.
B3조 이산치 수학
과제 보고서
[Project #3 : How fast can we sort?]
조장 : 최완철
조원 : 박찬흥
김재찬
정의수
백지원
13.
과제수행일지
소속 조원
A3 조장 : 최완철 자료조사 : 정의수, 백지원 프로그래밍 : 박찬흥
과제수행기간 3일
I. 계획의 작성
연구제목 Sorting
학습한 내용에 대해 이해를 하고, k-combination의 정의를 알고, 이것을 프로그램으
로 만들어 봄으로써 활용법을 안다.
연구배경
이산수학 및 응용/Susanna S.Epp 지음/임은기, 김환구, 안동언, 이주영,
정태충, 차운옥, 최종민, 허성우 옮김
이산수학 제6판/Richard Johnsonbaugh 지음/강흥식, 김정인, 박창현, 이
참고 서적
명재 옮김
참고자료
http://www.ktword.co.kr/abbr_view.php?m_temp1=4065&mgid=145
-> k-combination의 용어에 대한 의미와 공식
참고 URL http://www.ktword.co.kr/abbr_view.php?nav=&m_temp1=4123&mgid=4
24
-> Permutation에 관한 설명
II. 계획의 실행
첫째 날 2012년 4월 9일 월요일
오늘의 작업 조원의 업무 분담과 학습할 내용 및 과제에 대한 이해와 숙지
조장 : 최완철
자료조사 : 정의수, 백지원
프로그래밍 : 박찬흥
토의 내용
위와 같이 조원의 업무 분담을 하였으며 3번째 과제와 관련된 순열, 조합을 중심으로
프로그래밍 과제에 대한 내용을 인식하고 개별적으로 분담을 해서 조사를 하고 이해를
해 온 다음 그것을 조원들에게 설명해주는 것으로 방향을 잡았다.
과제준비에서 조편성을 모르다가 수업이후 따로 모여 각자의 역할을 정하면서, 미리 준비하지 못했던
느낀 점 만큼의 역할에 대한 책임감을 갖게 되었다.
14.
둘째 날 2012년 4월 14일 토요일
오늘의 작업 학습할 내용에 대한 설명 및 이해
경우의 수 과제를 수행하기 위해서는 가장 먼저 이해해야 할 k-permutation,
k-combination, k-sample, k-selection을 중심적으로 설명을 하였다.
원소의 순서
순서 유관 순서 무관
원소의 반복
k-permutation k-combination
비 반복 추출
(k-순열) (k-조합)
반복 추출 k-sample k-selection
k-permutation
k-순열에서는 집합 S로부터 k개를 선택하는데 반복을 허락하지 않는다. 하지만 선택된
원소들의 순서는 목록에서 구별한다. 이 목록을 집합 S로부터의 k-순열
토의 내용 (k-permutations)이라고 부른다.
k-combination
집합 S로부터 k개를 선택하는데, 반복을 허락하지 않고 순서에 상관없이 구성이 같은
원소는 똑같이 취급하는 경우의 목록을 k-조합(k-combinations)라고 한다. 집합 S의
k-조합은 S의 부분 집합과 정확히 일치한다.
k-sample
k-samples는 집합 S로부터 k개를 선택하는 작업중 하나이다. 반복을 허락하지만, 다른
순서의 똑같은 원소는 목록(list)에서 구별된다. 이런 종류의 목록을 k-sample이라고
부른다.
k-selection
집합 S로부터 k개를 선택할 경우 반복은 허락하지만, 순서에 상관없이 같은 원소는 동
일하게 취급하는데, 이 경우의 목록을 집합 S로부터의 k-selections라고 한다.
k-selections는 여러 번 동전 던지기의 결과를 알아보기 등에 유용하다.
순열과 조합이라는 과목은 중, 고등과정에서 배운 것이었지만, 단순히 공식을 외워서 문
과제준비에서 제풀이만 했다는 것을 느꼈다.
느낀 점 이번 회의를 진행하면서 가장 기본이 되지만, 평소에는 생각을 그다지 하지 않는 이론
적이고 원론적인 것에 대하여 알게 되어 많은 생각을 해보게 되었다.
셋째 날 2012년 4월 16일 월요일
오늘의 작업 과제1 풀이 및 과제2 알고리즘 작성
강의시간동안 과제1에 대하여 조원 모두 문제를 해결해보았고, 과제2에 대해서는 알고
리즘을 작성해보면서 해결방법을 모색해보았다.
토의 내용
위의 전제를 통해 관계 찾기 과제의 알고리즘을 작성하였다.
15.
행렬 입력
입력받은 행렬을 관계행렬의 형태로 출력
행과 열이 같은 경우(2x2,3x3,4x4,5x5)에 대한 구분
YES=reflexive, symmetric, irreflexive 중 선택하는 부분 출력
NO=reflexive, symmetric, irreflexive가 전부 NO로 출력
reflexive, symmetric, irreflexive 중 선택하면 그 관계에 대한 결과가 Y/N으로 출력
프로그램 종료
이산치수학 과제를 하다보면 소스코딩에 치중하는 경항이 강한데, 소스코딩보다 관련된
문제를 해결해봄으로써, 그 해결법을 참고하거나 이용하면 보다 수월하게 소스코딩을
과제준비에서
할 수 있다는 것을 느꼈다.
느낀 점
넷째 날 2012년 4월 17일 화요일
오늘의 작업 관계 찾기 과제의 프로그램 소스 초안 코딩
#include <stdio.h>
#include <stdlib.h>
struct powerset{
char com;
};
int Reflexive(int *arr,int x);
int Symmetric(int *arr,int x);
int Irreflexive(int *arr,int x);
typedef struct powerset ps;
초안
int main(){
ps *set;
int i=0,j=1,x=0,y=0,z=0,a=0;
printf("집합을 입력하시오 : ");
set = (ps *)malloc(sizeof(ps));
for(;;){
scanf("%c", &set[i].com);
if(set[i].com == 91 || set[i].com == 44) continue; // "[" 는 건너띔
if(set[i].com == 93){
if (y==0) x=i;
16.
y++;
continue;
}
if(set[i].com == 10) break; // "Enter"를 입력받으면 반복문 탈출
i++;
}
// x=x좌표, y=y좌표
y--;
printf("%d %dn",x,y);
char Temp[i];
if(x != y){ // x != y 면 모두 성립하지 않으므로 NO 출력후 종료
printf("reflexive, symmetric, irreflexive = NO!");
scanf("%c", &set[i].com);
return 0;
}
int arr[x][y]; // 입력한 크기의 배열 지정
for (i=0 ; i<y ; i++){
for (j=0 ; j<x ; j++){
if (set[z].com == 44) z++;
Temp[a] = set[z].com;
arr[i][j] = atoi(Temp);
a=0;
}
}
// 여기까지 입력부
// 여기부터 출력부
printf("입력한 집합은n");
for (i=0 ; i<y ; i++){
for (j=0 ; j<x ; j++){
printf("%d ",arr[i][j]);
}
printf("n");
}
printf(" 입니다.n 확인을 하고자 하는 옵션의 숫자를 입력해 주십시오.n 1.reflexiven
2.symmetricn 3.irreflexiven");
scanf("%d", &i);
switch (i){
case 1:
j = Reflexive(arr,x);
break;
case 2:
j = Symmetric(arr,x);
17.
break;
case 3:
j = Irreflexive(arr,x);
break;
default:
printf("올바르지 않는 입력입니다.n");
break;
}
if (j==1) printf("%YES!");
if (j==0) printf("%NO!");
scanf("%d", &set[i].com); //dev 환경 상 결과를 보려면 이것을 써줘야 함
return 0;
}
int Reflexive(int *arr,int x){
return 0;
}
int Symmetric(int *arr,int x){
return 0;
}
int Irreflexive(int *arr,int x){
return 0;
}
문제점 함수에서 사용한 2차원 배열이 제대로 기능이 되지 않아 오류가 났다.
해결 방안 함수로 따로 뺀 2차원 배열을 바로 메인 함수에 넣기로 하였다.
다섯째 날 2012년 4월 18일 수요일
오늘의 작업 관계 찾기 과제의 프로그램 소스 초안에 대한 문제점 해결
#include <stdio.h>
#include <stdlib.h>
struct powerset{
char com;
};
typedef struct powerset ps;
2안
int main(){
ps *set;
int i=0,j=1,x=0,y=0,z=0,a=0,b=0,c=0;
printf("집합을 입력하시오 : ");
set = (ps *)malloc(sizeof(ps));
18.
for(;;){
scanf("%c", &set[i].com);
if(set[i].com == 91 || set[i].com == 44) continue; // "[" 는 건너띔
if(set[i].com == 93){
if (y==0) x=i;
y++;
continue;
}
if(set[i].com == 10) break; // "Enter"를 입력받으면 반복문 탈출
i++;
}
// x=x좌표, y=y좌표
y--;
char Temp[i];
if(x != y){ // x != y 면 모두 성립하지 않으므로 NO 출력후 종료
printf("reflexive, symmetric, irreflexive = NO!");
scanf("%c", &set[i].com);
return 0;
}
int arr[x][y]; // 입력한 크기의 배열 지정
for (i=0 ; i<y ; i++){
for (j=0 ; j<x ; j++){
if (set[z].com == 44)
z++;
for (c=0;c<=3;c++){
Temp[c] = 0;
}
Temp[a] = set[z].com;
arr[i][j] = atoi(Temp);
z++;
a=0;
}
}
// 여기까지 입력부
// 여기부터 출력부
printf("입력한 집합은n");
for (i=0 ; i<y ; i++){
for (j=0 ; j<x ; j++){
printf("%d ",arr[i][j]);
}
printf("n");
}
for(;;){
printf(" 입니다.n 확인을 하고자 하는 옵션의 숫자를 입력해 주십시오.n 1.reflexiven
19.
2.symmetricn 3.irreflexiven");
scanf("%d", &i);
switch (i){
case 1:
j=1;
for(b=0;b<x;b++){
if(arr[b][b]==1){
if (j!=0) j=1;
}else{
j=0;
}
}
break;
case 2:
j=1;
for (b=0;b<x;b++) {
for (c=b;c<y;c++) {
if (arr[c][b] != arr[b][c])
j = 0;
}
}
break;
case 3:
j=1;
for(b=0;b<x;b++){
if(arr[b][b]==0){
if (j!=0) j=1;
}else{
j=0;
}
}
break;
default:
printf("올바르지 않는 입력입니다.n");
break;
}
if (j==1) printf("YES!");
if (j==0) printf("NO!");
}
printf("종료하시려면 아무키나 눌러주세요.");
return 0;
}
문제점 결과 출력이 무한 반복되는 문제가 생겼다.
해결방안 <conio.h> 헤더와 getch()를 이용하여 결과 출력이 무한 반복되는 문제를 해결하였
20.
다.
III. 결과
#include <stdio.h>
#include <stdlib.h>
#include <conio.h>
struct powerset{
char com;
};
typedef struct powerset ps;
int main(){
ps *set;
int i=0,j=1,x=0,y=0,z=0,a=0,b=0,c=0;
printf("집합을 입력하시오 : ");
set = (ps *)malloc(sizeof(ps));
for(;;){ // 입력 받기. [, ]
scanf("%c", &set[i].com);
if(set[i].com == 91 || set[i].com == 44) continue; // "[", "," 는 건너띔
if(set[i].com == 93){
if (y==0) x=i;
y++;
최종 프로그램
continue;
소스
}
if(set[i].com == 10) break; // "Enter"를 입력받으면 반복문 탈출
i++;
}
// x = x좌표, y = y좌표
y--;
char Temp[i];
if(x != y){ // x != y 면 모두 성립하지 않으므로 NO 출력후 종료
printf("reflexive, symmetric, irreflexive = NO!");
scanf("%c", &set[i].com);
return 0;
}
int arr[x][y]; // 입력한 크기의 배열 지정
for (i=0 ; i<y ; i++){ // char 형으로 받은 자료를 처리하기 쉽게 int형 2차원 배열에 입
력한다.
for (j=0 ; j<x ; j++){
if (set[z].com == 44)
z++;
for (c=0;c<=3;c++){
Temp[c] = 0;
21.
}
Temp[a] = set[z].com;
arr[i][j] = atoi(Temp);
z++;
a=0;
}
}
printf("입력한 집합은n");
for (i=0 ; i<y ; i++){ // 입력한 자료를 행렬로 띄워준다.
for (j=0 ; j<x ; j++){
printf("%d ",arr[i][j]);
}
printf("n");
}
printf(" 입니다.n 확인을 하고자 하는 옵션의 숫자를 입력해 주십시오.n 1.reflexiven
2.symmetricn 3.irreflexiven");
scanf("%d", &i);
switch (i){ // 여기서 Yes, No 를 판별한다.
case 1: // reflexive를 판별
j=1;
for(b=0;b<x;b++){
if(arr[b][b]==1){
if (j!=0) j=1;
}else{
j=0;
}
}
break;
case 2: // symmetric 를 판별
j=1;
for (b=0;b<x;b++){
for (c=b;c<y;c++){
if (arr[c][b] != arr[b][c])
j = 0;
}
}
break;
case 3: // irreflexive 를 판별
j=1;
for(b=0;b<x;b++){
if(arr[b][b]==0){
if (j!=0) j=1;
}else{
j=0;
}
22.
}
break;
default: // 예외처리
printf("올바르지 않는 입력입니다.n");
break;
}
if (j==1) printf("YES!n");
if (j==0) printf("NO!n");
printf("종료하시려면 아무키나 눌러주세요.");
getch();
return 0;
}
Ex) 3x3 [[1,0,1][1,1,0][0,1,1]]일 때의 reflexive
결과 출력
Ⅳ. 반성
조원의 구성이 랜덤하게 배정되는 만큼 조원 개개인의 분야별 능력도 상이한데, 조원의
구성에 따라서 맞춤식으로 각자의 역할을 배분해야 한다는 것을 느꼈고,
조원별로 회의 가능한 시간이 각자 달라서 모이려면 주말이나 공휴일을 이용해야 서로
과제를 마치면서
가 편했다. 하지만 조원 모두가 가능한 각주의 수업시간을 조금 더 잘 활용한다면, 주말
느낀 점
에 굳이 모이지 않더라도 충분한 토의를 할 수 있었다고 생각되어서 이점이 아쉽다.
이산치수학 이라는 과목을 공부한다는 생각보다, 소스코딩에 조원들의 신경이 집중되는
점이 아쉬웠다.
기타
23.
B3조 이산치 수학
과제 보고서
[Project #4 :Syntax of languages]
조장 : 백지원
조원 : 박찬흥
김재찬
정의수
최완철
24.
과제수행일지
소속 조원
B3 조장 : 백지원 자료조사 : 정의수, 최완철 프로그래밍 : 박찬흥
과제수행기간 4일 8시간
I. 계획의 작성
연구제목 Syntax of languages
학습한 내용에 대한 이해 및 정의를 자세히 알고, Minimum Spanning Tree를 프로그램
연구배경
으로 구성하여 봄으로써 활용법을 안다.
이산수학 및 응용/Susanna S.Epp 지음/임은기, 김환구, 안동언, 이주영,
정태충, 차운옥, 최종민, 허성우 옮김
참고자료 참고 서적
이산수학 제6판/Richard Johnsonbaugh 지음/강흥식, 김정인, 박창현, 이
명재 옮김
II. 계획의 실행
첫째 날 2012년 4월 24일 화요일
오늘의 작업 조원의 업무 분담과 학습할 내용 및 과제에 대한 이해와 숙지
조장 : 백지원
자료조사 : 정의수, 최완철
프로그래밍 : 박찬흥
토의 내용
위와 같이 조원의 업무 분담을 하였으며 4번째 과제와 관련된 Minimum Spanning Tree를
중심으로 프로그래밍 과제에 대한 내용을 인식하고 개별적으로 분담을 해서 조사를 하
고 이해를 해 온 다음 그것을 조원들에게 설명해주는 것으로 방향을 잡았다.
그리고 조원 한 명이 수업을 들어오지 않아 역할 분담에서 제외를 하였다.
과제준비에서 조 편성을 모르다가 수업이후 따로 모여 각자의 역할을 정하면서, 미리 준비하지 못했
느낀 점 던 만큼의 역할에 대한 책임감을 갖게 되었다.
25.
둘째 날 2012년 4월 27일 금요일
오늘의 작업 학습할 내용에 대한 설명 및 이해
과제를 수행하기 위해서는 가장 먼저 이해해야 할 Minimum Spanning Tree을 중심적으로
설명을 하였다.
Spanning tree
그래프에서 그래프의 모든 정점을 다 포함하는 트리.
부분 그래프이다. 트리라서 사이클이 없다.
Minimum spanning tree (MST)
spanning tree 중에서 가중치 합이 최소가 되는 spanning tree.
N개 vertex가 있으면 edge는 N-1개 있다.
토의 내용 일반적인 MST
처음에 A를 0으로 놓고 safe edge를 계속 추가해 나간다. 더 이상 안나올때까지 반복.
safe edge : 단계마다 하나의 edge를 선택할 때, minimum spanning tree를 유지하도록
하는 edge.
respect a set A : 그래프를 하나의 선으로 나눌 때, A의 어떤 edge도 그 선을 지나가
지 않을 때, 그 선이 A를 respect한다고 한다.
light edge : respect하게 cut(나눈 선)을 지나는 edge 중에서 최소 weight를 가진
edge들 중 하나. (light edge가 여러개 일 수도 있다. 그리고 어떻게 cut을 하느냐에
따라 light edge가 달라질 수 있다.)light edge면 safe edge이다.
과제준비에서 프로젝트를 진행함에 있어 조원들 간 의견이 너무 다르고 배경지식 또한 부족함이 느껴
느낀 점 져서 이 내용에 대해 다시한번 조사하여 의견과 배경지식의 통일을 이루었다.
셋째 날 2012년 5월 1일 화요일
오늘의 작업 과제1 풀이 및 과제2 알고리즘 작성
MST 구하는 방법
1. Kruskal algorithm
set A는 forest이다.
전체 forest에서 두개의 tree를 연결하는 weight가 가장 작은 edge를 찾는다. vertex
하나도 하나의 tree이다.
토의 내용
그 edge가 light edge이면 safe edge이다.
safe edge를 set A의 forest에 추가해 나간다.
사이클을 이루지 않도록 최소 weight edge를 하나씩 선택해서 모든 vertex가 다 포함되
면 minimum spanning tree가 된다.
구현
26.
disjoint-set 이용.
vertexset을 만든다. edge들을 정렬한 다음 제일 작은 edge부터 선택한다. 선택된
edge가 사이클을 안만드는 것이어야 한다. edge (u,v)에서 u와 v를 find-set(x)해서 두
개 값이 똑같으면 같은 set에 있다는 거니까 다른 값이 나와야 한다. 다르면 union한
다.
성능
disjoint-set의 구조에 따라 성능 차이가 있다. union-by-rank와 path-compression을
이용하면 빠르다.
Edge수를 m, Vertex 수를 n이라 하면
1. set 초기화 Θ(n)
2. edge 정렬 Θ(m lg m),
3. find, equal, merge는 Θ(lg m), 이것을 모든 Edge에 대해 반복하므로 Θ(m lg m)
이다.
m >= n-1이기 때문에 2,3 번이 1번을 지배. 따라서 Θ(m lg m)
최악의 경우 완전그래프일 경우 edge의 개수는 m=n(n-1)/2. 따라서 시간복잡도가
(n^2lg n)
Greedy method를 사용해서 값을 구하면 이게 정말 optimal solution인지 확인해야 한
다.
2. Prim algorithm
마찬가지로 탐욕적인 방법.
set A는 언제나 하나의 tree이다.(Kruskal은 forest)
set A와 연결되는 light edge 구하기. set A와 나머지를 나누는 선을 긋고, 그 선을
지나는 최소 edge중 하나가 light edge.
root vertex에서 시작한다.
구현
Minimum spanning tree를 A라고 하자.
모든 노드를 우선순위큐에 넣고
최소 key를 가진 vertex를 꺼낸다. (처음에 초기화할 때 루트의 key가 0이고 나머지는
다 무한대로 설정해서 처음에 루트가 꺼내져서 A에 들어간다.) 꺼낸 vertex(u)의 인접
vertex(v) (큐에 아직 남아있는 것)만 탐색하여 v의 키값이 (u,v) edge의 weight 값보
다 크다면 key값을 weight 값으로 변경한다. 그리고 부모노드를 u로 설정한다. 큐가 비
워질 때까지 이 과정을 반복한다.
성능
큐에 vertex가 없을 때까지 while문 반복, |V|번. (V는 vertex수)
큐에서 최소값 뽑는 것이 O(lg V).
while 다 돌면 큐에서 모든 vertex를 뽑으니까 O(V lg V) ----------1번
그래프의 인접리스트의 총 edge 길이는 2|E| (undirected graph, E는 edge 수)
그래서 큐에서 vertex 뽑고 그 vertex의 인접리스트를 탐색하는 거 O(E).
탐색 과정에서 vertex가 큐에 있는지 확인하고 있으면 key값 변경하고, 부모노드 설정.
27.
큐에 있는지 확인하는것은 vertex에 bit하나를 할당하여 큐에 있는지 없는지 상태를
나타내면 큐를 다 뒤지지 않고도 상수시간에 큐에 존재여부를 확인 할 수 있다.
부모노드 설정도 상수시간.
그리고 key값 변경하는 것은 min-heap에서 Decrease-key랑 같은거다.(key값 변경하고
min-heap이 유지되도록 변경된 vertex의 트리에서의 위치를 찾는 것) O(lg V)이다.
따라서 인접리스트 탐색하면서 key값 변경하는 시간은 O(E lgV) ----------2번
1,2번에 의해 total time은 O(V lg V + E lg E) = O(E lg V)
Fibonacci heap을 통해 성능향상을 할 수 있다.
과제준비에서 Minimum spanning tree을 구현하는데 두가지 방법이 있는데 두가지 방법을 다 적용시켜
느낀 점 서 코딩해보기로 하였다.
넷째 날 2012년 5월 10일 목요일
오늘의 작업 k-combination 프로그램 소스 초안 코딩
#include <stdio.h> // 노드를 그만 입력하고 싶을경우엔
#include <stdlib.h> // 0을 입력하면 입력이 종료되는 프로그램 입니다.
struct mst_edge{ //노드와 가중치를 입력받을 구조체
char edge[5];
int node;
};
typedef struct mst_edge mst;
int insert(mst *set2[], int j); // 구조체에 노드와 엣지를 입력하는 함수
void union_set(mst *set2[], char uni[], int no); // 사이클을 찾아서 사이클이
// 사이클이 안되게 엣지를 뽑음
int main(){
int no;
int i, j=0, k=0, sum=0, end=0;
초안
scanf("%d", &no); // 노드갯수 입력받음
char uni[no]; // 노드갯수 만큼 배열지정 사이클을 찾을때 씀
for(i=0; i<no; i++){ // 0으로 초기화
uni[i] = 0;
}
for(i=no-1; i>0; i--) sum = sum+i; // 최대로 입력받을수 있는 엣지 수
mst *set2[sum]; // 각 엣지와 가중치의 주소를 저장하는 포인트배열
mst *temp[sum]; // 임의로 만들어준 배열
for(j=0; j<sum; j++){ // 최대로 입력받을수 있는
end = insert(set2, j); // 엣지만큼 입력받음
if(end==1) break; // 혹은 0을 입력받으면
} // 입력종료
28.
for(i=0; i<j-1; i++){ // 가중치를 오름차순 정렬함
for(k=i+1; k<j; k++){
if(set2[i]->node > set2[k]->node){
temp[i]=set2[i];
set2[i]=set2[k];
set2[k]=temp[i];
}
}
}
uni[0] = set2[0]->edge[1]; // uni 집합에 각
uni[1] = set2[0]->edge[2]; // 처음 노드들을 넣음
printf("%c%c, ", set2[0]->edge[1], set2[0]->edge[2]);//가중치가 제일 작은
//처음의 엣지를 출력
union_set(set2, uni, no); // 사이클을 찾아서 출력
/*printf("n%dn%dnn", sum, j);
for(i=0; i<j; i++){
printf("n%c%cn", set2[i]->edge[1], set2[i]->edge[2]);
}
printf("n");
for(i=0; i<no; i++){
printf("%ct", uni[i]);
}*/
printf("%c%c", 8, 8); // 마지막에 , 를 지워줌
//getch();
return;
}
int insert(mst *set2[], int j){
mst *set;
set = (mst *)malloc(sizeof(mst)); // 구조체 할당받음
int i, last;
for(i=0; i<5; i++){ // 엣지를 입력받음
scanf("%c", &(set->edge[i]));
if(set->edge[i] == ' ') break;
if(set->edge[i] == '0'){ // 0을 입력받으면 종료
last = 1;
return last;
}
}
scanf("%d", &(set->node)); // 가중치를 입력받음
set2[j]=set; // 포인터 배열에 주소를 넘김
last = 0; // 나중에 정렬을 위해서
return last;
29.
}
void union_set(mst *set2[],char uni[], int no){ //uni집합에서 두 노드를 검색하여
int a, count=1, i=1; // 두 노드 모두 uni 집합에 있으면
while(1){ // 사이클 이 있으므로 뽑지 않음
for(a=1; a<3; a++){
if(uni[set2[i]->edge[a]-65] ==0){
printf("%c%c, ", set2[i]->edge[1],
set2[i]->edge[2]);
uni[set2[i]->edge[a]-65] =
set2[i]->edge[a];
count++;
break;
}
}
i++;
if(count==no-1) return;// 노드 -1개 까지 뽑으면 리턴
}
}
/*
void union_set(mst *set2[], char uni[], int i, int no){
int a, b, c, count=0;
for(a=0; a<no; a++){
if(set2[i]->edge[1] != uni[a]){
printf("%c%c, ", set2[i]->edge[1], set2[i]->edge[2]);
count++;
for(b=0; b<no; b++){
if(uni[b]==0){
uni[b]=set2[i]->edge[1];
uni[b+1]=set2[i]->edge[2];
return;
}
}
}
if(set2[i]->edge[1] == uni[a]){
for(b=0; b<no; b++){
if(set2[i]->edge[2] == uni[b]) return;
else if(set2[i]->edge[2] != uni[b]){
printf("%c%c, ", set2[i]->edge[1],
set2[i]->edge[2]);
count++;
for(c=0; c<no; c++){
if(uni[c]==0){
uni[c]=set2[i]->edge[2];
return;
}
}
30.
}
}
}
}
}
*/
/*
void counting(mst *set2[], int count[], int no){
int i=0, j;
for(j=0; j<no-1; j++){
for(i=1; i<3; i++) count[set2[j]->edge[i]-65] =
count[set2[j]->edge[i]-65]+1;
if(count[set2[j]->edge[1]-65]<2 || count[set2[j]->edge[2]-65]<2){
for(i=1; i<3; i++){
printf("%c", set2[j]->edge[i]);
}
}
printf(", ");
}
} */ // 이방법은 실패함
문제점 프로그램 실행이 되지 않는다.
초안 프로그램에서 수정을 하려고 하였으나 문제점이 해결이 되지 않아 다른 방법의 알
해결 방안
고리즘으로 프로그램을 구성하기로 하였다.
III. 결과
#include <stdio.h> // 노드를 그만 입력하고 싶을경우엔
#include <stdlib.h> // 0을 입력하면 입력이 종료되는 프로그램 입니다.
struct mst_edge{ //노드와 가중치를 입력받을 구조체
char edge[5];
int node;
};
typedef struct mst_edge mst;
최종 프로그램
소스 int insert(mst *set2[], int j); // 구조체에 노드와 엣지를 입력하는 함수
void union_set(mst *set2[], char uni[], int no); // 사이클을 찾아서 사이클이
// 사이클이 안되게 엣지를 뽑음
int main(){
int no;
int i, j=0, k=0, sum=0, end=0;
scanf("%d", &no); // 노드갯수 입력받음
char uni[no]; // 노드갯수 만큼 배열지정 사이클을 찾을때 씀
for(i=0; i<no; i++){ // 0으로 초기화
31.
uni[i] = 0;
}
for(i=no-1; i>0; i--) sum = sum+i; // 최대로 입력받을수 있는 엣지 수
mst *set2[sum]; // 각 엣지와 가중치의 주소를 저장하는 포인트배열
mst *temp[sum]; // 임의로 만들어준 배열
for(j=0; j<sum; j++){ // 최대로 입력받을수 있는
end = insert(set2, j); // 엣지만큼 입력받음
if(end==1) break; // 혹은 0을 입력받으면
} // 입력종료
for(i=0; i<j-1; i++){ // 가중치를 오름차순 정렬함
for(k=i+1; k<j; k++){
if(set2[i]->node > set2[k]->node){
temp[i]=set2[i];
set2[i]=set2[k];
set2[k]=temp[i];
}
}
}
uni[0] = set2[0]->edge[1]; // uni 집합에 각
uni[1] = set2[0]->edge[2]; // 처음 노드들을 넣음
printf("%c%c, ", set2[0]->edge[1], set2[0]->edge[2]);//가중치가 제일 작은
//처음의 엣지를 출력
union_set(set2, uni, no); // 사이클을 찾아서 출력
/*printf("n%dn%dnn", sum, j);
for(i=0; i<j; i++){
printf("n%c%cn", set2[i]->edge[1], set2[i]->edge[2]);
}
printf("n");
for(i=0; i<no; i++){
printf("%ct", uni[i]);
}*/
printf("%c%c", 8, 8); // 마지막에 , 를 지워줌
//getch();
return;
}
int insert(mst *set2[], int j){
mst *set;
set = (mst *)malloc(sizeof(mst)); // 구조체 할당받음
int i, last;
for(i=0; i<5; i++){ // 엣지를 입력받음
scanf("%c", &(set->edge[i]));
32.
if(set->edge[i] == '') break;
if(set->edge[i] == '0'){ // 0을 입력받으면 종료
last = 1;
return last;
}
}
scanf("%d", &(set->node)); // 가중치를 입력받음
set2[j]=set; // 포인터 배열에 주소를 넘김
last = 0; // 나중에 정렬을 위해서
return last;
}
void union_set(mst *set2[], char uni[], int no){ //uni집합에서 두 노드를 검색하여
int a, count=1, i=1; // 두 노드 모두 uni 집합에 있으면
while(1){ // 사이클 이 있으므로 뽑지 않음
for(a=1; a<3; a++){
if(uni[set2[i]->edge[a]-65] ==0){
printf("%c%c, ", set2[i]->edge[1],
set2[i]->edge[2]);
uni[set2[i]->edge[a]-65] =
set2[i]->edge[a];
count++;
break;
}
}
i++;
if(count==no-1) return;// 노드 -1개 까지 뽑으면 리턴
}
}
/*
void union_set(mst *set2[], char uni[], int i, int no){
int a, b, c, count=0;
for(a=0; a<no; a++){
if(set2[i]->edge[1] != uni[a]){
printf("%c%c, ", set2[i]->edge[1], set2[i]->edge[2]);
count++;
for(b=0; b<no; b++){
if(uni[b]==0){
uni[b]=set2[i]->edge[1];
uni[b+1]=set2[i]->edge[2];
return;
}
}
}
if(set2[i]->edge[1] == uni[a]){
for(b=0; b<no; b++){
if(set2[i]->edge[2] == uni[b]) return;
else if(set2[i]->edge[2] != uni[b]){
printf("%c%c, ", set2[i]->edge[1],
33.
set2[i]->edge[2]);
count++;
for(c=0; c<no; c++){
if(uni[c]==0){
uni[c]=set2[i]->edge[2];
return;
}
}
}
}
}
}
}
*/
/*
void counting(mst *set2[], int count[], int no){
int i=0, j;
for(j=0; j<no-1; j++){
for(i=1; i<3; i++) count[set2[j]->edge[i]-65] =
count[set2[j]->edge[i]-65]+1;
if(count[set2[j]->edge[1]-65]<2 || count[set2[j]->edge[2]-65]<2){
for(i=1; i<3; i++){
printf("%c", set2[j]->edge[i]);
}
}
printf(", ");
}
}
결과 출력 방법을 바꾸어 보았으나 프로그램 자체가 실행이 되지 않는다.
Ⅳ. 반성
역할분담은 잘 되었으나 과제를 이해함에 있어서 초반에 의견차이가 조금 있었다. 그래
서 의견과 배경지식의 재정립에 시간이 조금 소모하여서 알고리즘 구축에 소비한 시간
과제를 마치면서
이 부족하였다. 그래서 자연히 코딩하는 시간도 부족했고 오류 수정하는 시간 또한 부
느낀 점
족하여 결국 프로그램이 실행되지 않았다. 다음 과제때에는 첫 회의때 조원들끼리 배경
지식을 확실히 습득한 이후에 모였으면 바람직할거 같다.
과제수행일지
소속 조원
B3 조장 : 최완철 자료조사 : 정의수, 백지원 프로그래밍 : 박찬흥
과제수행기간 3일 약 18시간
I. 계획의 작성
연구제목 2-비트 덧셈기 설계
학습내용인 가산기의 개념과 구성을 알고, 2bit 가산기를 직접 설계와 구현을 해보고
조사해 봄으로써, 보다 심층적으로 내용을 이해하고 공부한다.
연구배경
http://ko.wikipedia.org/wiki/%EA%B0%80%EC%82%B0%EA%B8%B0
참고자료 참고 URL
- 가산기의 개념과 종류 및 설명
II. 계획의 실행
첫째 날 2012년 5월 29일 화요일
오늘의 작업 조원의 업무 분담 및 과제에 대한 이해와 숙지
조장 : 최완철
자료조사 : 정의수, 백지원
프로그래밍 : 박찬흥
토의 내용
위와 같이 임무 분담을 나누었으며, 학습할 내용에 대하여 각자가 맡은 분야에 대한
공부와 함께 몇 개씩 나누어 자료조사를 하기로 하고 해산하였다.
2학년 1학기 때 배우는 논리설계 과목에서 자주 사용하는 회로도가 있고, 내용도 연관
성이 있어서 두 가지 과목을 서로 연관하여 생각해보며 공부할 수 있어서 지루하지 않
과제준비에서
고 좋았다.
느낀 점
36.
둘째 날 2012년 5월 31일 목요일
오늘의 작업 덧셈기(가산기)에 대한 이해와 숙지 및 프로그램 과제 알고리즘 작성
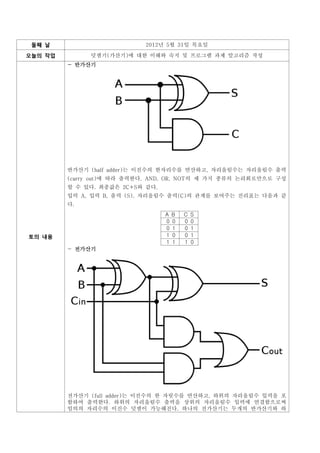
- 반가산기
반가산기 (half adder)는 이진수의 한자리수를 연산하고, 자리올림수는 자리올림수 출력
(carry out)에 따라 출력한다. AND, OR, NOT의 세 가지 종류의 논리회로만으로 구성
할 수 있다. 최종값은 2C+S와 같다.
입력 A, 입력 B, 출력 (S), 자리올림수 출력(C)의 관계를 보여주는 진리표는 다음과 같
다.
A B C S
0 0 0 0
0 1 0 1
토의 내용 1 0 0 1
1 1 1 0
- 전가산기
전가산기 (full adder)는 이진수의 한 자릿수를 연산하고, 하위의 자리올림수 입력을 포
함하여 출력한다. 하위의 자리올림수 출력을 상위의 자리올림수 입력에 연결함으로써
임의의 자리수의 이진수 덧셈이 가능해진다. 하나의 전가산기는 두개의 반가산기와 하
37.
나의 OR로 구성된다.
입력이 3개 존재해서 (입력 A, 입력 B, 자리올림수 입력) 모두 대등하게 동작한다. 하
지만 회로상에서 3개 입력이 대칭되어 있다고 할 수 없다.
입력 A, 입력 B, 자리올림수 입력 (X), 출력 (S), 자리올림수 출력 (C)의 관계를 보여
주는 진리표는 다음과 같다.
A B X C S
0 0 0 0 0
0 0 1 0 1
0 1 0 0 1
0 1 1 1 0
1 0 0 0 1
1 0 1 1 0
1 1 0 1 0
1 1 1 1 1
전가산기는 전통적인 트랜지스터 수준의 회로나 여러 게이트들의 조합과 같이 여러가지
방법으로 구현될 수 있다. 한 가지 예는 와 로 표현한 것이다. 이 구현 방식에서 자리
올림수 출력 전의 마지막 OR 게이트를 XOR 게이트로 바꾸어도 논리값이 바뀌지 않을
것이다. 오직 두 가지 종류의 게이트를 사용하는 것이 칩 하나에 게이트 한 종류를 포
함하는 간단한 IC 칩을 이용하여 전가산기를 구현할 때 유용하다. 이러한 관점에서
Cout은 로 구현될 것이다.
전가산기는 또한 반가산기 두 개를 이용하여 구현할 수 있다. A와 B를 첫 번째 반가산
기에 연결하고 그 출력값을 두 번째 반가산기의 입력에 연결한다. 그 후 두 번째 반가
산기의 다른 입력에 Ci을 연결하여 두 번째 반가산기의 출력값이 S값이 되고, 자리올림
수 출력인 Cout은 두 반가산기의 자리올림수 출력을 OR 연산이 된다. 마찬가지로 S는
A, B, Ci 세 비트의 XOR 연산으로 만들어질 수 있으며 Cout은 A, B, Ci 세 비트의 다
수결 함수로 만들어질 수 있다.
가산기에 위에서 나열한 것들 이외에도 많은 종류가 포함되어 있다는 것을 알게 되었
고, 각각의 개념을 이해하면서 우리가 과제를 해결하는데 어떤 것을 이용해야할지, 왜
과제준비에서
그것을 이용해야 하는지를 알게 되어 많은 공부가 되었다.
느낀 점
셋째 날 2012년 6월 7일 목요일
오늘의 작업 2-비트 덧셈기 과제의 프로그램 소스 초안
#include <stdio.h>
int u_halfAdder(int a, int b);
int v_halfAdder(int a, int b);
int main(){
int a, b, c, d;
토의 내용 int u1, v1, u2, v2;
및 int e, f;
소스 초안 char ch;
while(1){
scanf("%d %d %d %d", &a, &b, &c, &d);
u1 = u_halfAdder(a, c);
v1 = v_halfAdder(a, c);
u2 = u_halfAdder(b, d);
v2 = v_halfAdder(b, d);
38.
e = u_halfAdder(v1,u2);
f = v_halfAdder(v1, u2);
e = u_halfAdder(u1, e);
printf("%d %d %dn", e, f, v2);
printf("continued (Y/N) : ");
fflush(stdin);
scanf("%c", &ch);
if(ch == 'N') break
}
getch();
return
}
int u_halfAdder(int a, int b){
if(a!=b) return 0;
else if(a==b){
if(a==0) return 0;
else return 1;
}
}
int v_halfAdder(int a, int b){
if(a!=b) return 1;
else if(a==b) return 0;
}
1. 2-비트 덧셈기의 회로도에서 제일 마지막 부분의 논리합을 구성하지 않고 Half
adder로 해버려서 제대로 출력되지 않음.
2. N입력 전까지 반복해서 프로그램이 돌아가도록 했는데, 원인은 모르겠으나 이전 값
문제점
을 계속해서 출력하는 문제가 있음.
문제점1 - 마지막에 논리합(OR) function을 만들어서 이용함
문제점2 반복해서 입력을 받지 않도록 수정함
해결 방안
III. 결과
#include <stdio.h>
int u_halfAdder(int a, int b);
최종 프로그램
int v_halfAdder(int a, int b);
소스
int l_sum(int a, int b);
39.
int main(){
int a, b, c, d;
int u1, v1, u2, v2, u3;
int e, f;
char ch;
scanf("%d %d %d %d", &a, &b, &c, &d);
u1 = u_halfAdder(a, c);
v1 = v_halfAdder(a, c);
u2 = u_halfAdder(b, d);
v2 = v_halfAdder(b, d);
u3 = u_halfAdder(v1, u2);
f = v_halfAdder(v1, u2);
e = l_sum(u1, u3);
printf("e : %dnf : %dng : %dn", e, f, v2);
return;
}
int u_halfAdder(int a, int b){
if(a!=b) return 0;
else if(a==b){
if(a==1) return 1;
if(a==0) return 0;
}
}
int v_halfAdder(int a, int b){
if(a!=b) return 1;
else if(a==b) return 0;
}
int l_sum(int a, int b){
if(a==b){
if(a==1) return 1;
if(a==0) return 0;
}
if(a!=b) return 1;
}
40.
결과 출력
Ⅳ. 반성
앞에서도 말했지만, 다른 과목에서 배우고 있는, 배웠던 내용과 많은 연관성이 있어서
문제를 푸는데 많은 도움이 되었고, 그 과목과 자료구조 과목을 연관 지어 생각해볼
과제를 마치면서
수 있는 기회여서 많은 공부가 되었다.
느낀 점
41.
이산치 수학 B3조
과제 보고서
[Project #7: Group codes]
조장 : 박찬흥
조원 : 정의수
최완철
백지원
42.
과제수행일지
소속 조원
B3 조장 : 박찬흥 자료조사 : 정의수, 최완철 프로그래밍 : 박찬흥, 백지원
과제수행기간 3일 약 29시간
I. 계획의 작성
연구제목 Group codes
학습내용을 공부하고 프로그램 코딩을 직접 해보면서 허프만 코드에 대해 이해를 하
고 숙지한다.
연구배경
전산수학 및 전산이론을 위한 이산수학 및 응용/박진홍 지음
이산수학/박종안, 이재진, 이준열 지음
참고 서적
참고자료
http://blog.naver.com/zenix4078?Redirect=Log&logNo=10463440
참고 URL http://blog.naver.com/aih303?Redirect=Log&logNo=20127176173
//Huffman code 자료
II. 계획의 실행
첫째 날 2012년 6월 11일 월요일
오늘의 작업 조원의 업무 분담 및 과제에 대한 이해와 숙지
조장 :
자료조사 :
프로그래밍 :
토의 내용
위와 같이 임무 분담을 나누었으며, Huffman code에 대해 교수님의 설명을 들었다.
Huffman code에 대한 자세한 내용은 각자 자료조사를 통해서 개인적으로 공부를 해 온
다음 수요일 모여 토의를 하며 조사해 온 내용을 설명하고 공부하기로 하였다.
이번 과제는 교수님께서 따로 지정해 주신 학습내용이 없었기 때문에 수업시간에 교수
님께 설명을 들었던 Huffman code가 과제를 수행하면서 가장 중요한 내용이라고 판단
과제준비에서
을 내려 그것을 중점적으로 공부해야 할 필요성을 느꼈다.
느낀 점
43.
둘째 날 2012년 6월 13일 수요일
오늘의 작업 Huffman code에 대한 이해와 숙지
과제 수행을 하는 데에 필요한 허프만 코드에 대해 자료조사를 하고 조사한 내용을 토
의시간에 조원들에게 설명을 하면서 이해를 하였다.
허프만코드 : 일종의 파일 압축 알고리즘
텍스트에 나타나는 특정 문자에 대한 빈도수를 이용
자주 사용되는 문자는 짧은 코드를, 자주 사용하지 않는 문자는 긴 코드를 지정
실제 평균 문자 코드 길이를 줄여 압축하는 방법
파일에 사용되는 문자의 사용빈도가 높은 것은 이진트리의 높은 위치에, 낮은 것은
이진트리의 낮은 위치에 놓아 코드화
허프만 코드는 접두 코드를 회피하여 문자 표현
어떤 코드가 다른 코드의 접두사가 되지 않으면 코드의 길이는 서로 달라도 문자를
표현하는데 지장 없음
이진트리를 생성하여 트리의 왼쪽 종속트리로 갈 때에는 0, 오른쪽 종속트리로 갈 때
에는 1로 코드화
허프만 코드는 가장 널리 쓰이는 압축 방법
문자가 나타나는 빈도수에 따라 그 크기를 다르게 하는 것 : 빈도수 의존 코드
모음과 'L', 'R', 'S', 'N', 'T' 등과 같이 자주 나타나는 문자들은 더 작은 비트를 할당
토의 내용
허프만코드 생성 방법
단 하나의 노드만을 가지고 있는 이진트리와 각 문자를 매핑
각 트리에 문자들의 빈도수를 할당 : 트리의 가중치(weight) - 내림차순으로 정렬
두 개의 가장 작은 가중치를 가지고 있는 트리를 찾아 하나의 트리로 합치고 새로운
루트 노드를 만들어 냄 (이 새 트리의 가중치는 합쳐진 두 트리의 가중치의 합)
마지막으로 하나의 트리가 남을 때까지 이 과정을 반복
이 과정이 끝났을 때 원래 노드들의 각각은 마지막 이진트리의 말단 노드(leaf)가 됨
이진트리에서 루트로부터 말단 노드에 이르는 유일한 길(path)이 있게 되고 이 길이
허프만 코드가 됨 ( 각 왼쪽 자식 포인터에 0을 할당하고, 오른쪽 자식 포인터에 1을
할당해서 결정)
위와 같이 허프만 코드가 어떤 것인지에 대해 공부하였고 허프만 코드의 생성 방법에
대해 이해를 하였다. 다음 토의 시간에는 부족한 내용에 대해 보충 자료조사를 해 온
다음 공부하기로 하였다.
Huffman code에 대한 기본적인 이론만 조사를 하고 난 다음 토의를 했기 때문에 더 정
과제준비에서 확한 이해를 위해서는 조금 더 넓은 범위의 자료조사를 통해서 공부를 해야 할 필요성
느낀 점 을 느꼈다. Huffman code를 알고리즘 적으로 어떻게 사용이 되는지 알아보고 이것을
어떤 식으로 과제에 적용할 것인지 생각해보게 되었다.
셋째 날 2012년 6월 18일 월요일
오늘의 작업 Huffman code에 대한 보충 설명과 프로그램 과제 이해 및 숙지
44.
■ 허프만 코드알고리즘 단계.
1)압축을 하기 위한 텍스트 문서를 입력 후 버퍼에 저장한다.
2)버퍼에 저장한 문자들을 하나씩 읽어서 빈도수를 구한다.
3) 빈도수가 낮은 것일수록 먼저 합치고 높은 것은 나중에 합쳐서 트리를 구성한다.
(단, 일반적인 트리와는 같지만 단지 아래서 위로 트리를 구성한다는 것은 다르다.)
4)트리가 구성되면 전위탐색을 통해서 각 단어의 경로 번호를 구성 받는다. 만일 트리
가 왼쪽에 있으면 0, 오른쪽에 있으면 1 이런식으로 번호를 부여한다.
5) 부여 받은 번호와 단어를 매칭하는 테이블을 구성한다.
6) 테이블을 통해서 매칭 받은 단어들과 원래 단어를 매칭해서 비트 연산을 한다.(압축
을한다)
-헤더 파일을 구성한다(4byte(int형) =head길이, 4byte(int형) = table길이, 4byte(int
형) = 총데이타 길이, 4byte(int형)= 비트단위 연산을 한 데이터 길이,
2byte(char형)= table문자(아스키코드), 4byte(int형)=table 빈도수,byte = data총길
이)
-원본 문자들을 비트단위로 저장한다.
이렇게 비트단위로 변경한 data를 .huff만이라는 임의의 확장자에 저장한다.
7) 압축 푸는 프로그램을 만든다.
-헤더 파일에 내용을 읽어서 버퍼에 저장한다.
-버퍼에 저장하기 전에 비트 연산을 통해서 원래 문자로 변경한다.
- table을 구성한다.
- table을 구성하고 빈도수를 가지고 트리를 구성한다.
토의 내용 - 트리(코드)과 원본 문자를 비교를 통해서 본래의 문자로 바꾼 후 텍스트 문서로 다
시 만든다.
■ 트리 구성 원리
45.
■ 테이블 구성원리
자료조사를 통한 토의내용으로 공부를 하면서 Huffman code를 사용할 때 이진트리를
함께 사용해야 한다는 것을 알게 되었고 이것을 과제에 적용시키기 위해서는 좀 더 다
과제준비에서
양한 방법을 생각해 봐야 할 것 같다고 느꼈다.
느낀 점
넷째 날 2012년 6월 19일 화요일
오늘의 작업 Group code 과제의 프로그램 소스 초안
#include <stdio.h>
#include <stdlib.h>
struct save{
char alpha;
char sub[20];
double beta;
};
typedef struct save save;
토의 내용
및 int insert(save *set2[], int i, int counting[]);
소스 초안 void probability(int a, int counting[], save *set2[]);
void change(save *tem[], int count);
int main(){
save *set2[20];
int counting[27];
int count=0, temp=0, i=0, j=0, k=0;
int stop;
for(i=0; i<27; i++) counting[i] = 0;
printf("%c", set2[j]->sub[k]);
}
}
}
getch();
return
}
int insert(save *set2[], int i, int counting[]){
save *set;
set = (save *)malloc(sizeof(save));
scanf("%c", &(set->alpha));
if(set->alpha == 10) return 1;
if(set->alpha>='a' && set->alpha<='z') counting[set->alpha-97] += 1;
else if(set->alpha == ' ') counting[26] += 1;
set2[i] = set;
return 0;
}
void probability(int a, int counting[], save *set2[]){
int i=0, j=0;
for(i=0; i<27; i++){
if(counting[i] > 0){
for(j=0; j<a; j++){
if(i+97 == (int)set2[j]->alpha) set2[j]->beta
= (double)counting[i]/a;
}
}
}
}
void change(save *tem[], int count){
save *dlatl[count];
int q=2, w=0, e=0, r=0, t=0, y=0;
tem[1]->beta = tem[0]->beta + tem[1]->beta;
tem[0]->beta = tem[1]->beta;
tem[0]->sub[0] = '1'
tem[1]->sub[0] = '0'
while(1){
for(e=q-1; e<count-1; e++){
48.
for(r=e+1; r<count; r++){
if(tem[e]->beta > tem[r]->beta){
dlatl[e] = tem[e];
tem[e] = tem[r];
tem[r] = dlatl[e];
}
}
}
if(tem[q-1]->beta <= tem[q-2]->beta){
tem[q-1]->sub[0] = '1'
for(t=0; t<q-1; t++){
for(y=0; y<20; y++){
if(tem[t]->sub[y] == '2'){
tem[t]->sub[y] =
'0'
break
}
}
tem[q]->sub[y] = '0'
}
}
if((tem[q]->sub[0] == '2') || (tem[q-1]->sub[0] == '2')){
tem[q]->sub[0] = '0'
tem[q-1]->sub[0] = '1'
}
tem[q]->beta = tem[q]->beta + tem[q-1]->beta;
tem[q-1]->beta = tem[q]->beta;
if(q+2==count) return
q++;
}
}
단어를 입력을 받았을 때 출력이 정상적으로 나오지 않고 쓰레기 값이 출력이 되는 것
을 확인하였다.
문제점
Huffman code 함수에 대한 알고리즘을 다시 작성하여 프로그램 소스를 수정해 보기로
해결 방안
하였다.
49.
III. 결과
프로그램 소스를 완성하지 못하였음.
최종 프로그램
소스
Ⅳ. 반성
기말 시험기간이 겹쳐서 과제 진행을 하는 데에 시간을 많이 할애하지 못하는 조원이
많았다. 그래서 토의를 한 시간도 지금까지의 과제에 비하여 상대적으로 적었고 과제
과제를 마치면서
진척도도 많이 느렸던 것 같았다.
느낀 점
시간이 여유가 좀 더 있었고 과제에 대한 이해가 조금 더 빨랐었다면 과제 수행이 훨씬
수월해 질 수 있었던 것을 생각하면 많이 아쉬웠다.
기타







![-OUTT라는 라벨을 이용해서 goto문을 사용해서 나가는 방식을
이용해 출력 구문의 크기를 줄이기로 결정하였습니다.
-그리고 함수에 관한 학습내용은
프로그램 실행시 입력부분은 [[0,1][0,0,1][1,0]]과 같이 프로젝트
문제와 같은 방식으로 문자를 입력하게 하였고 그 결과로 나
회의 오는 것으로 만들어 졌다.
결과 출력 부분은 프로젝트 과제의 목표와 같이 만들어 졌으며,
및 위의 소스 설명처럼 정방 행렬이 아니면 반사성(reflexive)와 비
토의 반사성(irreflexive)가 no를 출력하는 형식으로 만들게 되었습니
다.](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-8-320.jpg)



![B3조 이산치 수학
과제 보고서
[Project #3 : How fast can we sort?]
조장 : 최완철
조원 : 박찬흥
김재찬
정의수
백지원](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-12-320.jpg)


![행렬 입력
입력받은 행렬을 관계행렬의 형태로 출력
행과 열이 같은 경우(2x2,3x3,4x4,5x5)에 대한 구분
YES=reflexive, symmetric, irreflexive 중 선택하는 부분 출력
NO=reflexive, symmetric, irreflexive가 전부 NO로 출력
reflexive, symmetric, irreflexive 중 선택하면 그 관계에 대한 결과가 Y/N으로 출력
프로그램 종료
이산치수학 과제를 하다보면 소스코딩에 치중하는 경항이 강한데, 소스코딩보다 관련된
문제를 해결해봄으로써, 그 해결법을 참고하거나 이용하면 보다 수월하게 소스코딩을
과제준비에서
할 수 있다는 것을 느꼈다.
느낀 점
넷째 날 2012년 4월 17일 화요일
오늘의 작업 관계 찾기 과제의 프로그램 소스 초안 코딩
#include <stdio.h>
#include <stdlib.h>
struct powerset{
char com;
};
int Reflexive(int *arr,int x);
int Symmetric(int *arr,int x);
int Irreflexive(int *arr,int x);
typedef struct powerset ps;
초안
int main(){
ps *set;
int i=0,j=1,x=0,y=0,z=0,a=0;
printf("집합을 입력하시오 : ");
set = (ps *)malloc(sizeof(ps));
for(;;){
scanf("%c", &set[i].com);
if(set[i].com == 91 || set[i].com == 44) continue; // "[" 는 건너띔
if(set[i].com == 93){
if (y==0) x=i;](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-15-320.jpg)
![y++;
continue;
}
if(set[i].com == 10) break; // "Enter"를 입력받으면 반복문 탈출
i++;
}
// x=x좌표, y=y좌표
y--;
printf("%d %dn",x,y);
char Temp[i];
if(x != y){ // x != y 면 모두 성립하지 않으므로 NO 출력후 종료
printf("reflexive, symmetric, irreflexive = NO!");
scanf("%c", &set[i].com);
return 0;
}
int arr[x][y]; // 입력한 크기의 배열 지정
for (i=0 ; i<y ; i++){
for (j=0 ; j<x ; j++){
if (set[z].com == 44) z++;
Temp[a] = set[z].com;
arr[i][j] = atoi(Temp);
a=0;
}
}
// 여기까지 입력부
// 여기부터 출력부
printf("입력한 집합은n");
for (i=0 ; i<y ; i++){
for (j=0 ; j<x ; j++){
printf("%d ",arr[i][j]);
}
printf("n");
}
printf(" 입니다.n 확인을 하고자 하는 옵션의 숫자를 입력해 주십시오.n 1.reflexiven
2.symmetricn 3.irreflexiven");
scanf("%d", &i);
switch (i){
case 1:
j = Reflexive(arr,x);
break;
case 2:
j = Symmetric(arr,x);](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-16-320.jpg)
![break;
case 3:
j = Irreflexive(arr,x);
break;
default:
printf("올바르지 않는 입력입니다.n");
break;
}
if (j==1) printf("%YES!");
if (j==0) printf("%NO!");
scanf("%d", &set[i].com); //dev 환경 상 결과를 보려면 이것을 써줘야 함
return 0;
}
int Reflexive(int *arr,int x){
return 0;
}
int Symmetric(int *arr,int x){
return 0;
}
int Irreflexive(int *arr,int x){
return 0;
}
문제점 함수에서 사용한 2차원 배열이 제대로 기능이 되지 않아 오류가 났다.
해결 방안 함수로 따로 뺀 2차원 배열을 바로 메인 함수에 넣기로 하였다.
다섯째 날 2012년 4월 18일 수요일
오늘의 작업 관계 찾기 과제의 프로그램 소스 초안에 대한 문제점 해결
#include <stdio.h>
#include <stdlib.h>
struct powerset{
char com;
};
typedef struct powerset ps;
2안
int main(){
ps *set;
int i=0,j=1,x=0,y=0,z=0,a=0,b=0,c=0;
printf("집합을 입력하시오 : ");
set = (ps *)malloc(sizeof(ps));](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-17-320.jpg)
![for(;;){
scanf("%c", &set[i].com);
if(set[i].com == 91 || set[i].com == 44) continue; // "[" 는 건너띔
if(set[i].com == 93){
if (y==0) x=i;
y++;
continue;
}
if(set[i].com == 10) break; // "Enter"를 입력받으면 반복문 탈출
i++;
}
// x=x좌표, y=y좌표
y--;
char Temp[i];
if(x != y){ // x != y 면 모두 성립하지 않으므로 NO 출력후 종료
printf("reflexive, symmetric, irreflexive = NO!");
scanf("%c", &set[i].com);
return 0;
}
int arr[x][y]; // 입력한 크기의 배열 지정
for (i=0 ; i<y ; i++){
for (j=0 ; j<x ; j++){
if (set[z].com == 44)
z++;
for (c=0;c<=3;c++){
Temp[c] = 0;
}
Temp[a] = set[z].com;
arr[i][j] = atoi(Temp);
z++;
a=0;
}
}
// 여기까지 입력부
// 여기부터 출력부
printf("입력한 집합은n");
for (i=0 ; i<y ; i++){
for (j=0 ; j<x ; j++){
printf("%d ",arr[i][j]);
}
printf("n");
}
for(;;){
printf(" 입니다.n 확인을 하고자 하는 옵션의 숫자를 입력해 주십시오.n 1.reflexiven](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-18-320.jpg)
![2.symmetricn 3.irreflexiven");
scanf("%d", &i);
switch (i){
case 1:
j=1;
for(b=0;b<x;b++){
if(arr[b][b]==1){
if (j!=0) j=1;
}else{
j=0;
}
}
break;
case 2:
j=1;
for (b=0;b<x;b++) {
for (c=b;c<y;c++) {
if (arr[c][b] != arr[b][c])
j = 0;
}
}
break;
case 3:
j=1;
for(b=0;b<x;b++){
if(arr[b][b]==0){
if (j!=0) j=1;
}else{
j=0;
}
}
break;
default:
printf("올바르지 않는 입력입니다.n");
break;
}
if (j==1) printf("YES!");
if (j==0) printf("NO!");
}
printf("종료하시려면 아무키나 눌러주세요.");
return 0;
}
문제점 결과 출력이 무한 반복되는 문제가 생겼다.
해결방안 <conio.h> 헤더와 getch()를 이용하여 결과 출력이 무한 반복되는 문제를 해결하였](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-19-320.jpg)
![다.
III. 결과
#include <stdio.h>
#include <stdlib.h>
#include <conio.h>
struct powerset{
char com;
};
typedef struct powerset ps;
int main(){
ps *set;
int i=0,j=1,x=0,y=0,z=0,a=0,b=0,c=0;
printf("집합을 입력하시오 : ");
set = (ps *)malloc(sizeof(ps));
for(;;){ // 입력 받기. [, ]
scanf("%c", &set[i].com);
if(set[i].com == 91 || set[i].com == 44) continue; // "[", "," 는 건너띔
if(set[i].com == 93){
if (y==0) x=i;
y++;
최종 프로그램
continue;
소스
}
if(set[i].com == 10) break; // "Enter"를 입력받으면 반복문 탈출
i++;
}
// x = x좌표, y = y좌표
y--;
char Temp[i];
if(x != y){ // x != y 면 모두 성립하지 않으므로 NO 출력후 종료
printf("reflexive, symmetric, irreflexive = NO!");
scanf("%c", &set[i].com);
return 0;
}
int arr[x][y]; // 입력한 크기의 배열 지정
for (i=0 ; i<y ; i++){ // char 형으로 받은 자료를 처리하기 쉽게 int형 2차원 배열에 입
력한다.
for (j=0 ; j<x ; j++){
if (set[z].com == 44)
z++;
for (c=0;c<=3;c++){
Temp[c] = 0;](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-20-320.jpg)
![}
Temp[a] = set[z].com;
arr[i][j] = atoi(Temp);
z++;
a=0;
}
}
printf("입력한 집합은n");
for (i=0 ; i<y ; i++){ // 입력한 자료를 행렬로 띄워준다.
for (j=0 ; j<x ; j++){
printf("%d ",arr[i][j]);
}
printf("n");
}
printf(" 입니다.n 확인을 하고자 하는 옵션의 숫자를 입력해 주십시오.n 1.reflexiven
2.symmetricn 3.irreflexiven");
scanf("%d", &i);
switch (i){ // 여기서 Yes, No 를 판별한다.
case 1: // reflexive를 판별
j=1;
for(b=0;b<x;b++){
if(arr[b][b]==1){
if (j!=0) j=1;
}else{
j=0;
}
}
break;
case 2: // symmetric 를 판별
j=1;
for (b=0;b<x;b++){
for (c=b;c<y;c++){
if (arr[c][b] != arr[b][c])
j = 0;
}
}
break;
case 3: // irreflexive 를 판별
j=1;
for(b=0;b<x;b++){
if(arr[b][b]==0){
if (j!=0) j=1;
}else{
j=0;
}](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-21-320.jpg)
![}
break;
default: // 예외처리
printf("올바르지 않는 입력입니다.n");
break;
}
if (j==1) printf("YES!n");
if (j==0) printf("NO!n");
printf("종료하시려면 아무키나 눌러주세요.");
getch();
return 0;
}
Ex) 3x3 [[1,0,1][1,1,0][0,1,1]]일 때의 reflexive
결과 출력
Ⅳ. 반성
조원의 구성이 랜덤하게 배정되는 만큼 조원 개개인의 분야별 능력도 상이한데, 조원의
구성에 따라서 맞춤식으로 각자의 역할을 배분해야 한다는 것을 느꼈고,
조원별로 회의 가능한 시간이 각자 달라서 모이려면 주말이나 공휴일을 이용해야 서로
과제를 마치면서
가 편했다. 하지만 조원 모두가 가능한 각주의 수업시간을 조금 더 잘 활용한다면, 주말
느낀 점
에 굳이 모이지 않더라도 충분한 토의를 할 수 있었다고 생각되어서 이점이 아쉽다.
이산치수학 이라는 과목을 공부한다는 생각보다, 소스코딩에 조원들의 신경이 집중되는
점이 아쉬웠다.
기타](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-22-320.jpg)
![B3조 이산치 수학
과제 보고서
[Project #4 :Syntax of languages]
조장 : 백지원
조원 : 박찬흥
김재찬
정의수
최완철](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-23-320.jpg)



![큐에 있는지 확인하는 것은 vertex에 bit하나를 할당하여 큐에 있는지 없는지 상태를
나타내면 큐를 다 뒤지지 않고도 상수시간에 큐에 존재여부를 확인 할 수 있다.
부모노드 설정도 상수시간.
그리고 key값 변경하는 것은 min-heap에서 Decrease-key랑 같은거다.(key값 변경하고
min-heap이 유지되도록 변경된 vertex의 트리에서의 위치를 찾는 것) O(lg V)이다.
따라서 인접리스트 탐색하면서 key값 변경하는 시간은 O(E lgV) ----------2번
1,2번에 의해 total time은 O(V lg V + E lg E) = O(E lg V)
Fibonacci heap을 통해 성능향상을 할 수 있다.
과제준비에서 Minimum spanning tree을 구현하는데 두가지 방법이 있는데 두가지 방법을 다 적용시켜
느낀 점 서 코딩해보기로 하였다.
넷째 날 2012년 5월 10일 목요일
오늘의 작업 k-combination 프로그램 소스 초안 코딩
#include <stdio.h> // 노드를 그만 입력하고 싶을경우엔
#include <stdlib.h> // 0을 입력하면 입력이 종료되는 프로그램 입니다.
struct mst_edge{ //노드와 가중치를 입력받을 구조체
char edge[5];
int node;
};
typedef struct mst_edge mst;
int insert(mst *set2[], int j); // 구조체에 노드와 엣지를 입력하는 함수
void union_set(mst *set2[], char uni[], int no); // 사이클을 찾아서 사이클이
// 사이클이 안되게 엣지를 뽑음
int main(){
int no;
int i, j=0, k=0, sum=0, end=0;
초안
scanf("%d", &no); // 노드갯수 입력받음
char uni[no]; // 노드갯수 만큼 배열지정 사이클을 찾을때 씀
for(i=0; i<no; i++){ // 0으로 초기화
uni[i] = 0;
}
for(i=no-1; i>0; i--) sum = sum+i; // 최대로 입력받을수 있는 엣지 수
mst *set2[sum]; // 각 엣지와 가중치의 주소를 저장하는 포인트배열
mst *temp[sum]; // 임의로 만들어준 배열
for(j=0; j<sum; j++){ // 최대로 입력받을수 있는
end = insert(set2, j); // 엣지만큼 입력받음
if(end==1) break; // 혹은 0을 입력받으면
} // 입력종료](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-27-320.jpg)
![for(i=0; i<j-1; i++){ // 가중치를 오름차순 정렬함
for(k=i+1; k<j; k++){
if(set2[i]->node > set2[k]->node){
temp[i]=set2[i];
set2[i]=set2[k];
set2[k]=temp[i];
}
}
}
uni[0] = set2[0]->edge[1]; // uni 집합에 각
uni[1] = set2[0]->edge[2]; // 처음 노드들을 넣음
printf("%c%c, ", set2[0]->edge[1], set2[0]->edge[2]);//가중치가 제일 작은
//처음의 엣지를 출력
union_set(set2, uni, no); // 사이클을 찾아서 출력
/*printf("n%dn%dnn", sum, j);
for(i=0; i<j; i++){
printf("n%c%cn", set2[i]->edge[1], set2[i]->edge[2]);
}
printf("n");
for(i=0; i<no; i++){
printf("%ct", uni[i]);
}*/
printf("%c%c", 8, 8); // 마지막에 , 를 지워줌
//getch();
return;
}
int insert(mst *set2[], int j){
mst *set;
set = (mst *)malloc(sizeof(mst)); // 구조체 할당받음
int i, last;
for(i=0; i<5; i++){ // 엣지를 입력받음
scanf("%c", &(set->edge[i]));
if(set->edge[i] == ' ') break;
if(set->edge[i] == '0'){ // 0을 입력받으면 종료
last = 1;
return last;
}
}
scanf("%d", &(set->node)); // 가중치를 입력받음
set2[j]=set; // 포인터 배열에 주소를 넘김
last = 0; // 나중에 정렬을 위해서
return last;](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-28-320.jpg)
![}
void union_set(mst *set2[], char uni[], int no){ //uni집합에서 두 노드를 검색하여
int a, count=1, i=1; // 두 노드 모두 uni 집합에 있으면
while(1){ // 사이클 이 있으므로 뽑지 않음
for(a=1; a<3; a++){
if(uni[set2[i]->edge[a]-65] ==0){
printf("%c%c, ", set2[i]->edge[1],
set2[i]->edge[2]);
uni[set2[i]->edge[a]-65] =
set2[i]->edge[a];
count++;
break;
}
}
i++;
if(count==no-1) return;// 노드 -1개 까지 뽑으면 리턴
}
}
/*
void union_set(mst *set2[], char uni[], int i, int no){
int a, b, c, count=0;
for(a=0; a<no; a++){
if(set2[i]->edge[1] != uni[a]){
printf("%c%c, ", set2[i]->edge[1], set2[i]->edge[2]);
count++;
for(b=0; b<no; b++){
if(uni[b]==0){
uni[b]=set2[i]->edge[1];
uni[b+1]=set2[i]->edge[2];
return;
}
}
}
if(set2[i]->edge[1] == uni[a]){
for(b=0; b<no; b++){
if(set2[i]->edge[2] == uni[b]) return;
else if(set2[i]->edge[2] != uni[b]){
printf("%c%c, ", set2[i]->edge[1],
set2[i]->edge[2]);
count++;
for(c=0; c<no; c++){
if(uni[c]==0){
uni[c]=set2[i]->edge[2];
return;
}
}](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-29-320.jpg)
![}
}
}
}
}
*/
/*
void counting(mst *set2[], int count[], int no){
int i=0, j;
for(j=0; j<no-1; j++){
for(i=1; i<3; i++) count[set2[j]->edge[i]-65] =
count[set2[j]->edge[i]-65]+1;
if(count[set2[j]->edge[1]-65]<2 || count[set2[j]->edge[2]-65]<2){
for(i=1; i<3; i++){
printf("%c", set2[j]->edge[i]);
}
}
printf(", ");
}
} */ // 이방법은 실패함
문제점 프로그램 실행이 되지 않는다.
초안 프로그램에서 수정을 하려고 하였으나 문제점이 해결이 되지 않아 다른 방법의 알
해결 방안
고리즘으로 프로그램을 구성하기로 하였다.
III. 결과
#include <stdio.h> // 노드를 그만 입력하고 싶을경우엔
#include <stdlib.h> // 0을 입력하면 입력이 종료되는 프로그램 입니다.
struct mst_edge{ //노드와 가중치를 입력받을 구조체
char edge[5];
int node;
};
typedef struct mst_edge mst;
최종 프로그램
소스 int insert(mst *set2[], int j); // 구조체에 노드와 엣지를 입력하는 함수
void union_set(mst *set2[], char uni[], int no); // 사이클을 찾아서 사이클이
// 사이클이 안되게 엣지를 뽑음
int main(){
int no;
int i, j=0, k=0, sum=0, end=0;
scanf("%d", &no); // 노드갯수 입력받음
char uni[no]; // 노드갯수 만큼 배열지정 사이클을 찾을때 씀
for(i=0; i<no; i++){ // 0으로 초기화](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-30-320.jpg)
![uni[i] = 0;
}
for(i=no-1; i>0; i--) sum = sum+i; // 최대로 입력받을수 있는 엣지 수
mst *set2[sum]; // 각 엣지와 가중치의 주소를 저장하는 포인트배열
mst *temp[sum]; // 임의로 만들어준 배열
for(j=0; j<sum; j++){ // 최대로 입력받을수 있는
end = insert(set2, j); // 엣지만큼 입력받음
if(end==1) break; // 혹은 0을 입력받으면
} // 입력종료
for(i=0; i<j-1; i++){ // 가중치를 오름차순 정렬함
for(k=i+1; k<j; k++){
if(set2[i]->node > set2[k]->node){
temp[i]=set2[i];
set2[i]=set2[k];
set2[k]=temp[i];
}
}
}
uni[0] = set2[0]->edge[1]; // uni 집합에 각
uni[1] = set2[0]->edge[2]; // 처음 노드들을 넣음
printf("%c%c, ", set2[0]->edge[1], set2[0]->edge[2]);//가중치가 제일 작은
//처음의 엣지를 출력
union_set(set2, uni, no); // 사이클을 찾아서 출력
/*printf("n%dn%dnn", sum, j);
for(i=0; i<j; i++){
printf("n%c%cn", set2[i]->edge[1], set2[i]->edge[2]);
}
printf("n");
for(i=0; i<no; i++){
printf("%ct", uni[i]);
}*/
printf("%c%c", 8, 8); // 마지막에 , 를 지워줌
//getch();
return;
}
int insert(mst *set2[], int j){
mst *set;
set = (mst *)malloc(sizeof(mst)); // 구조체 할당받음
int i, last;
for(i=0; i<5; i++){ // 엣지를 입력받음
scanf("%c", &(set->edge[i]));](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-31-320.jpg)
![if(set->edge[i] == ' ') break;
if(set->edge[i] == '0'){ // 0을 입력받으면 종료
last = 1;
return last;
}
}
scanf("%d", &(set->node)); // 가중치를 입력받음
set2[j]=set; // 포인터 배열에 주소를 넘김
last = 0; // 나중에 정렬을 위해서
return last;
}
void union_set(mst *set2[], char uni[], int no){ //uni집합에서 두 노드를 검색하여
int a, count=1, i=1; // 두 노드 모두 uni 집합에 있으면
while(1){ // 사이클 이 있으므로 뽑지 않음
for(a=1; a<3; a++){
if(uni[set2[i]->edge[a]-65] ==0){
printf("%c%c, ", set2[i]->edge[1],
set2[i]->edge[2]);
uni[set2[i]->edge[a]-65] =
set2[i]->edge[a];
count++;
break;
}
}
i++;
if(count==no-1) return;// 노드 -1개 까지 뽑으면 리턴
}
}
/*
void union_set(mst *set2[], char uni[], int i, int no){
int a, b, c, count=0;
for(a=0; a<no; a++){
if(set2[i]->edge[1] != uni[a]){
printf("%c%c, ", set2[i]->edge[1], set2[i]->edge[2]);
count++;
for(b=0; b<no; b++){
if(uni[b]==0){
uni[b]=set2[i]->edge[1];
uni[b+1]=set2[i]->edge[2];
return;
}
}
}
if(set2[i]->edge[1] == uni[a]){
for(b=0; b<no; b++){
if(set2[i]->edge[2] == uni[b]) return;
else if(set2[i]->edge[2] != uni[b]){
printf("%c%c, ", set2[i]->edge[1],](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-32-320.jpg)
![set2[i]->edge[2]);
count++;
for(c=0; c<no; c++){
if(uni[c]==0){
uni[c]=set2[i]->edge[2];
return;
}
}
}
}
}
}
}
*/
/*
void counting(mst *set2[], int count[], int no){
int i=0, j;
for(j=0; j<no-1; j++){
for(i=1; i<3; i++) count[set2[j]->edge[i]-65] =
count[set2[j]->edge[i]-65]+1;
if(count[set2[j]->edge[1]-65]<2 || count[set2[j]->edge[2]-65]<2){
for(i=1; i<3; i++){
printf("%c", set2[j]->edge[i]);
}
}
printf(", ");
}
}
결과 출력 방법을 바꾸어 보았으나 프로그램 자체가 실행이 되지 않는다.
Ⅳ. 반성
역할분담은 잘 되었으나 과제를 이해함에 있어서 초반에 의견차이가 조금 있었다. 그래
서 의견과 배경지식의 재정립에 시간이 조금 소모하여서 알고리즘 구축에 소비한 시간
과제를 마치면서
이 부족하였다. 그래서 자연히 코딩하는 시간도 부족했고 오류 수정하는 시간 또한 부
느낀 점
족하여 결국 프로그램이 실행되지 않았다. 다음 과제때에는 첫 회의때 조원들끼리 배경
지식을 확실히 습득한 이후에 모였으면 바람직할거 같다.](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-33-320.jpg)
![이산치 수학 B3조
과제 보고서
[Project#6 : 2-비트 덧셈기 설계]
조장 : 최완철
조원 : 박찬흥
정의수
백지원](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-34-320.jpg)





![이산치 수학 B3조
과제 보고서
[Project #7: Group codes]
조장 : 박찬흥
조원 : 정의수
최완철
백지원](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-41-320.jpg)



![■ 테이블 구성 원리
자료조사를 통한 토의내용으로 공부를 하면서 Huffman code를 사용할 때 이진트리를
함께 사용해야 한다는 것을 알게 되었고 이것을 과제에 적용시키기 위해서는 좀 더 다
과제준비에서
양한 방법을 생각해 봐야 할 것 같다고 느꼈다.
느낀 점
넷째 날 2012년 6월 19일 화요일
오늘의 작업 Group code 과제의 프로그램 소스 초안
#include <stdio.h>
#include <stdlib.h>
struct save{
char alpha;
char sub[20];
double beta;
};
typedef struct save save;
토의 내용
및 int insert(save *set2[], int i, int counting[]);
소스 초안 void probability(int a, int counting[], save *set2[]);
void change(save *tem[], int count);
int main(){
save *set2[20];
int counting[27];
int count=0, temp=0, i=0, j=0, k=0;
int stop;
for(i=0; i<27; i++) counting[i] = 0;](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-45-320.jpg)
![for(i=0; i<20; i++){
stop = insert(set2, i, counting);
if(stop == 1) break
}
for(j=0; j<i; j++){
for(k=0; k<20; k++){
set2[j]->sub[k] = '2'
}
}
for(j=0; j<27; j++)
if(counting[j] > 0) count += 1;
save *set3[count];
save *tem[count];
probability(i, counting, set2);
for(j=0; j<27; j++){
if(counting[j] > 0){
for(k=0; k<i; k++){
if(j+97 == (int)set2[k]->alpha){
set3[temp] = set2[k];
temp++;
break
}
}
}
}
for(j=0; j<count-1; j++){
for(k=j+1; k<count; k++){
if(set3[j]->beta > set3[k]->beta){
tem[j] = set3[j];
set3[j] = set3[k];
set3[k] = tem[j];
}
}
}
for(j=0; j<count; j++) tem[j] = set3[j];
change(tem, count);
for(j=0; j<i; j++){
for(k=20; k>=0; k--){
if(set2[j]->sub[k] != '2'){](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-46-320.jpg)
![printf("%c", set2[j]->sub[k]);
}
}
}
getch();
return
}
int insert(save *set2[], int i, int counting[]){
save *set;
set = (save *)malloc(sizeof(save));
scanf("%c", &(set->alpha));
if(set->alpha == 10) return 1;
if(set->alpha>='a' && set->alpha<='z') counting[set->alpha-97] += 1;
else if(set->alpha == ' ') counting[26] += 1;
set2[i] = set;
return 0;
}
void probability(int a, int counting[], save *set2[]){
int i=0, j=0;
for(i=0; i<27; i++){
if(counting[i] > 0){
for(j=0; j<a; j++){
if(i+97 == (int)set2[j]->alpha) set2[j]->beta
= (double)counting[i]/a;
}
}
}
}
void change(save *tem[], int count){
save *dlatl[count];
int q=2, w=0, e=0, r=0, t=0, y=0;
tem[1]->beta = tem[0]->beta + tem[1]->beta;
tem[0]->beta = tem[1]->beta;
tem[0]->sub[0] = '1'
tem[1]->sub[0] = '0'
while(1){
for(e=q-1; e<count-1; e++){](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-47-320.jpg)
![for(r=e+1; r<count; r++){
if(tem[e]->beta > tem[r]->beta){
dlatl[e] = tem[e];
tem[e] = tem[r];
tem[r] = dlatl[e];
}
}
}
if(tem[q-1]->beta <= tem[q-2]->beta){
tem[q-1]->sub[0] = '1'
for(t=0; t<q-1; t++){
for(y=0; y<20; y++){
if(tem[t]->sub[y] == '2'){
tem[t]->sub[y] =
'0'
break
}
}
tem[q]->sub[y] = '0'
}
}
if((tem[q]->sub[0] == '2') || (tem[q-1]->sub[0] == '2')){
tem[q]->sub[0] = '0'
tem[q-1]->sub[0] = '1'
}
tem[q]->beta = tem[q]->beta + tem[q-1]->beta;
tem[q-1]->beta = tem[q]->beta;
if(q+2==count) return
q++;
}
}
단어를 입력을 받았을 때 출력이 정상적으로 나오지 않고 쓰레기 값이 출력이 되는 것
을 확인하였다.
문제점
Huffman code 함수에 대한 알고리즘을 다시 작성하여 프로그램 소스를 수정해 보기로
해결 방안
하였다.](https://image.slidesharecdn.com/2012dmb310-13408951265733-phpapp02-120628095238-phpapp02/85/2012-Dm-B3-10-48-320.jpg)



















































![[이산수학]4 관계, 함수 및 행렬](https://cdn.slidesharecdn.com/ss_thumbnails/4-100318103220-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)













