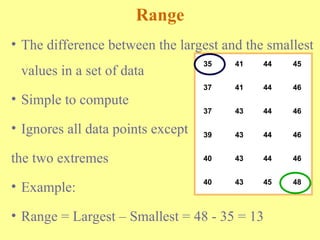
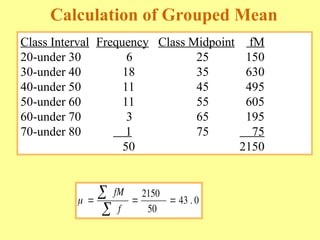
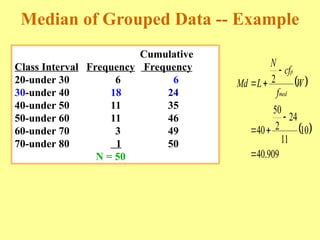
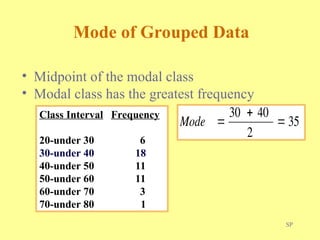
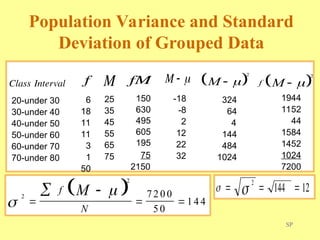
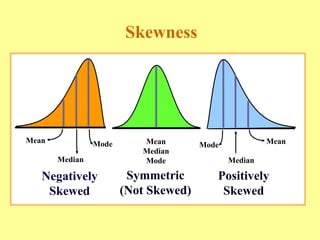
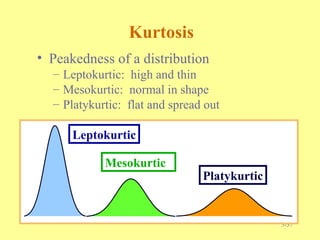
Chapter three discusses measures of central tendency and variability, focusing on ungrouped data. Key concepts include mode, median, mean, percentiles, and quartiles as measures of central location, as well as various measures of variability such as range and standard deviation. The chapter provides computational procedures and examples for understanding and calculating these statistical measures.