Downloaded 24 times



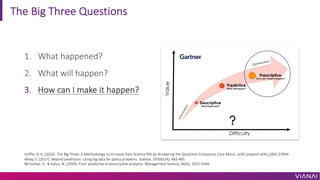



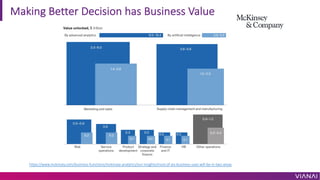




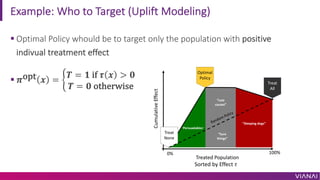
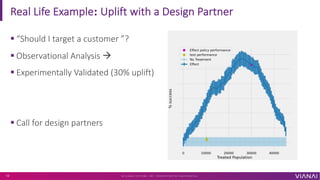

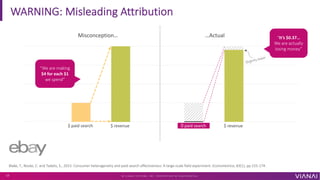
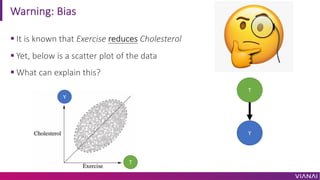
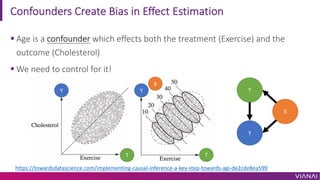
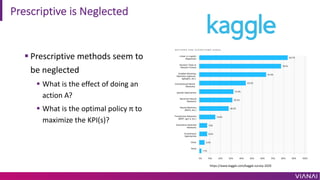





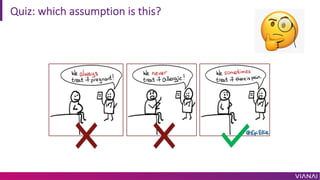

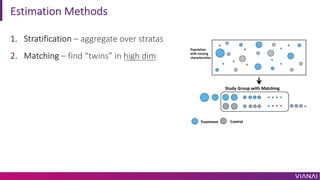






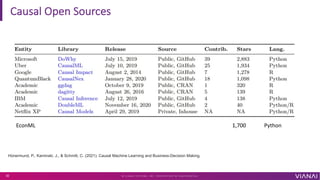



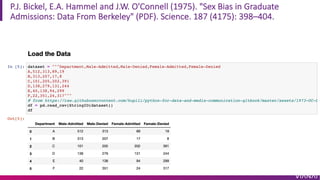
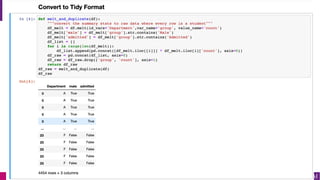
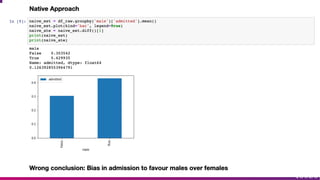
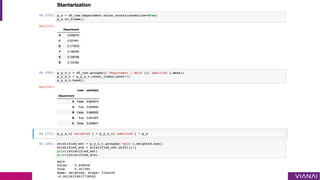
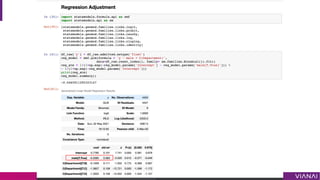
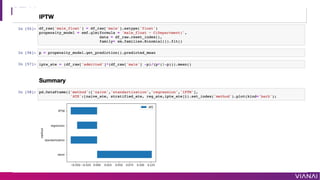

The document discusses causal inference and its importance for business decision making. It notes that causal inference allows companies to make better decisions by understanding the causal effects of actions using past data. This can help companies optimize outcomes by targeting interventions only to individuals expected to benefit. The document outlines key causal inference concepts like treatment effects and explores methods like matching, weighting, and experiments to estimate causal relationships from data.















![[DSC DACH 23] ChatGPT and Beyond: How generative AI is Changing the way peopl...](https://cdn.slidesharecdn.com/ss_thumbnails/chatgptandbeyond-230424074311-fa7c1960-thumbnail.jpg?width=640&height=640&fit=bounds)













































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)





