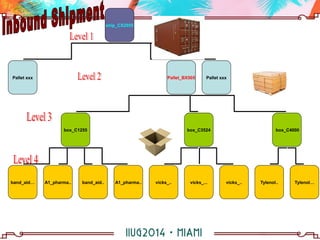
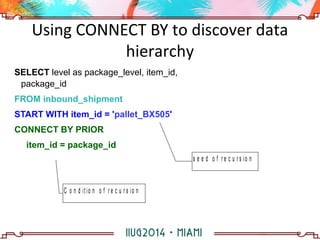
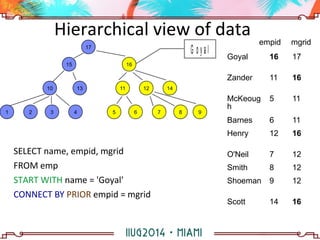
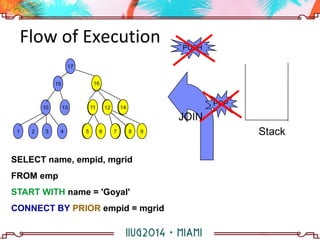
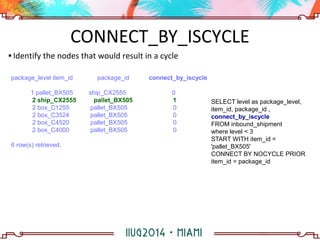
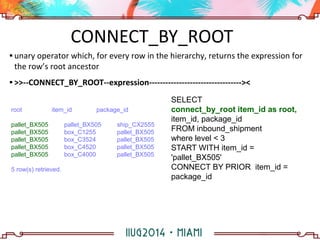
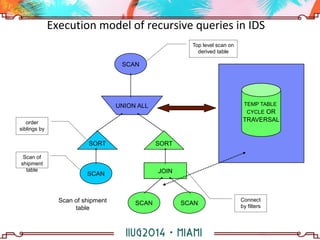
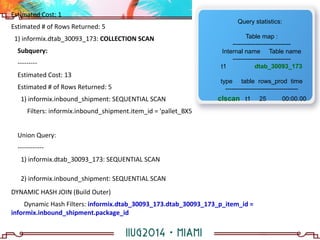
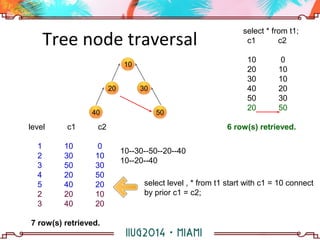
The document discusses building a hierarchical data model using IBM Informix features, focusing on querying hierarchical data through self-referencing structures. It covers techniques like 'connect by', recursion, and offers SQL examples for managing complex queries involving employee-manager relationships and package-item associations. Challenges such as query transformations, data traversal, and cycle detection are also addressed, along with strategies for effective data representation and execution in hierarchical queries.







































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

















