Downloaded 18 times


![Est. 2001
Improving Knowledge Turning,
Enabling Reuse and Reproducibility
[Josh Sommer]
Keep the vision, modify the plan](https://image.slidesharecdn.com/bosc2012goble-120714170448-phpapp01/85/If-we-build-it-will-they-come-BOSC2012-Keynote-Goble-2-320.jpg)









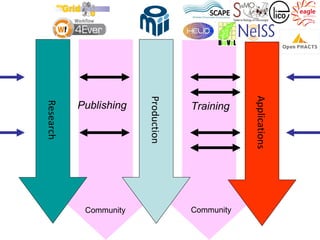









![Ladder Model of OSS Adoption
(adapted from Carbone P., Value Derived
from Open Source is a Function of
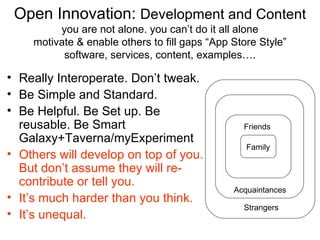
Family Acquaintances
Friends Maturity Levels) Strangers
Moore's technology adoption curve
[FLOSS@Sycracuse]](https://image.slidesharecdn.com/bosc2012goble-120714170448-phpapp01/85/If-we-build-it-will-they-come-BOSC2012-Keynote-Goble-32-320.jpg)



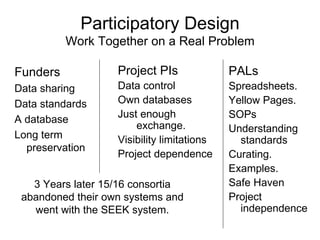

![Participation Cooperation? Coordination? Collaboration?
Citizens Integration? Evolution and entropy models
Public
scientists
Trusted
Collaborators
Private
Groups
Lone
scholars
Closed Controlled Open
[based on an idea by Liz Lyon] Access](https://image.slidesharecdn.com/bosc2012goble-120714170448-phpapp01/85/If-we-build-it-will-they-come-BOSC2012-Keynote-Goble-39-320.jpg)
![Critical mass spiral: 90:9:1
Driven by needs of
and benefits to the
scientist, rather
than top down
policies.
Content tipping
point
[Andrew Su]](https://image.slidesharecdn.com/bosc2012goble-120714170448-phpapp01/85/If-we-build-it-will-they-come-BOSC2012-Keynote-Goble-40-320.jpg)



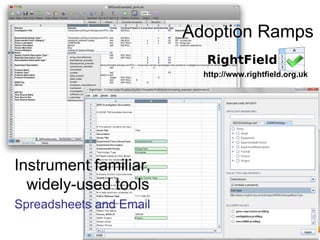



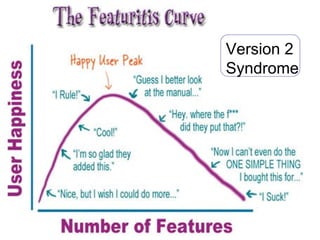






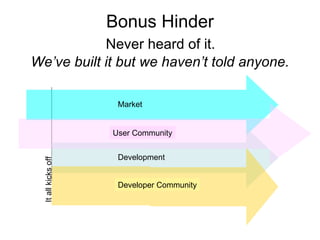
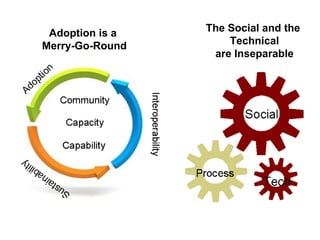
![Jam not forever
• Acquire
• Retain
• Widen
– More/Different
• Reposition
– Different/New Stage
• Changing Community
is Challenging… [Daron Green]](https://image.slidesharecdn.com/bosc2012goble-120714170448-phpapp01/85/If-we-build-it-will-they-come-BOSC2012-Keynote-Goble-55-320.jpg)




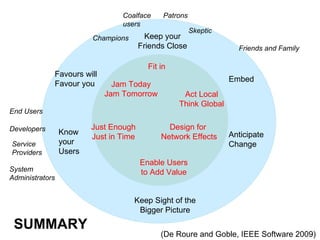

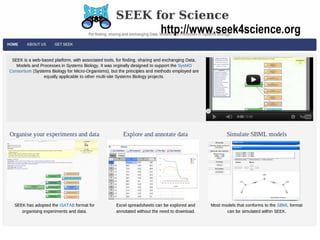
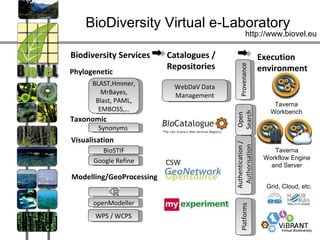
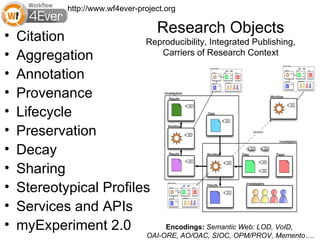
The document discusses the challenges and strategies related to the adoption of software and services in scientific communities, emphasizing the importance of usability, community engagement, and the need for value in fostering adoption. It highlights various projects and platforms aimed at improving collaboration, reproducibility, and resource sharing among researchers while warning against issues like lack of documentation, community support, and flexibility. Ultimately, it underscores the necessity of meeting user needs and building a supportive ecosystem to ensure successful implementation and use of scientific software.



































































