Download as PDF, PPTX






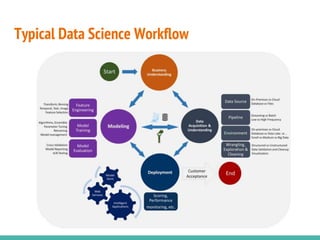




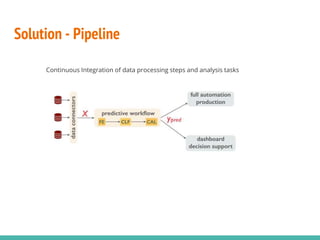





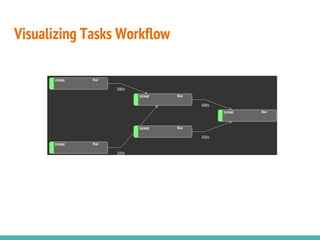
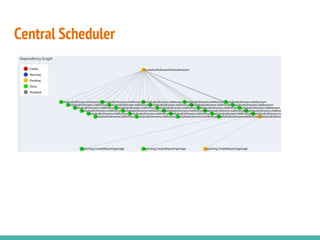






This document describes building data science pipelines in Python using Luigi. It discusses the typical data science workflow, challenges with the current workflow approach, and how data science pipelines with Luigi can help address these challenges. Key features of Luigi that make it useful for data science pipelines are presented, including task templating, scheduling, monitoring, failure recovery, and enabling batch and parallel processing. The document concludes with a demonstration Luigi pipeline example to predict the performance score of mobile game users.
























































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)










