BLAS (Basic Linear Algebra Subprograms) is a specification that defines low-level routines for common linear algebra operations like vector addition and matrix multiplication. It aims to improve performance by allowing these operations to be optimized for specific hardware. BLAS has three levels - level 1 for vector operations, level 2 for matrix-vector operations, and level 3 for matrix-matrix operations. Many numerical software packages use BLAS to perform linear algebra computations. Batched BLAS was later introduced to improve performance on parallel architectures by performing operations on multiple matrices simultaneously.





![Most libraries that offer linear algebra
routines conform to the BLAS interface,
allowing library users to develop programs
that are indifferent to the BLAS library
being used. BLAS implementations have
known a spectacular explosion in uses with
the development of GPGPU, with cuBLAS
and rocBLAS being prime examples.
CPU-based examples of BLAS libraries
include: OpenBLAS, BLIS (BLAS-like
Library Instantiation Software), Arm
Performance Libraries,[5] ATLAS, and
Intel Math Kernel Library (MKL).
BLAS
applications](https://image.slidesharecdn.com/blsa-220421074935/85/BLSA-pptx-5-320.jpg)







![Level 1
This level consists of all the routines described in the original presentation of
BLAS (1979),[1] which defined only vector operations on strided arrays: dot
products, vector norms, a generalized vector addition of the form](https://image.slidesharecdn.com/blsa-220421074935/85/BLSA-pptx-15-320.jpg)

![Level 3
This level, formally published in 1990,[19] contains matrix-matrix
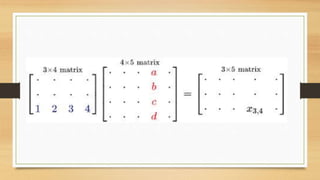
operations, including a "general matrix multiplication" (gemm), of the form
𝛼𝐴𝐵 + 𝛽𝐶 → 𝐶
where A and B can optionally be transposed or hermitian-conjugated inside
the routine, and all three matrices may be strided. The ordinary matrix
multiplication A B can be performed by setting α to one and C to an all-zeros
matrix of the appropriate size.
Also included in Level 3 are routines for computing](https://image.slidesharecdn.com/blsa-220421074935/85/BLSA-pptx-17-320.jpg)
![Batched BLAS
The traditional BLAS functions have been
also ported to architectures that support large
amounts of parallelism such as GPUs. Here,
the traditional BLAS functions provide
typically good performance for large matrices.
However, when computing e.g., matrix-
matrix-products of many small matrices by
using the GEMM routine, those architectures
show significant performance losses. To
address this issue, in 2017 a batched version
of the BLAS function has been specified]](https://image.slidesharecdn.com/blsa-220421074935/85/BLSA-pptx-18-320.jpg)

![Batched BLAS
Batched BLAS functions can be a
versatile tool and allow e.g. a fast
implementation of exponential
integrators and Magnus integrators that
handle long integration periods with
many time steps.[53] Here, the matrix
exponentiation, the computationally
expensive part of the integration, can
be implemented in parallel for all time-
steps by using Batched BLAS
functions.](https://image.slidesharecdn.com/blsa-220421074935/85/BLSA-pptx-20-320.jpg)







































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)








