Downloaded 24 times







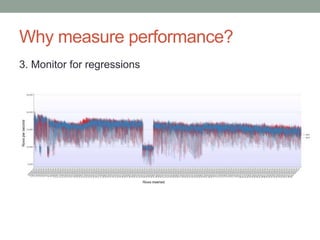
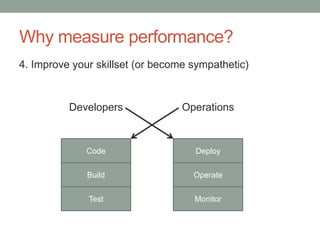

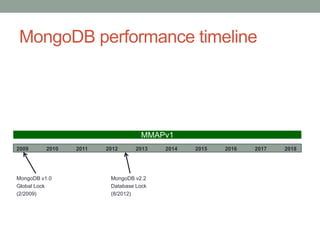
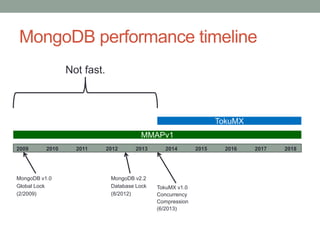
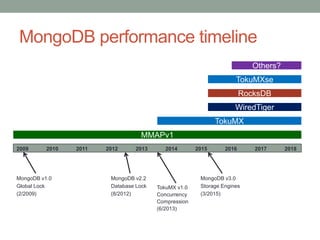
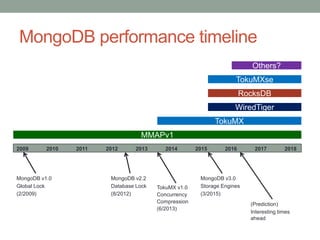















The document presents an overview of MongoDB performance, highlighting the evolution of its storage engines and performance metrics from its inception in 2009 to the present. It emphasizes the importance of measuring performance through various techniques, including modeling workloads and sharing benchmarks, to optimize database usage. The author also discusses future developments and competitive dynamics in database technologies, particularly regarding the improvements in concurrency and replication mechanisms.































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)










