Downloaded 19 times




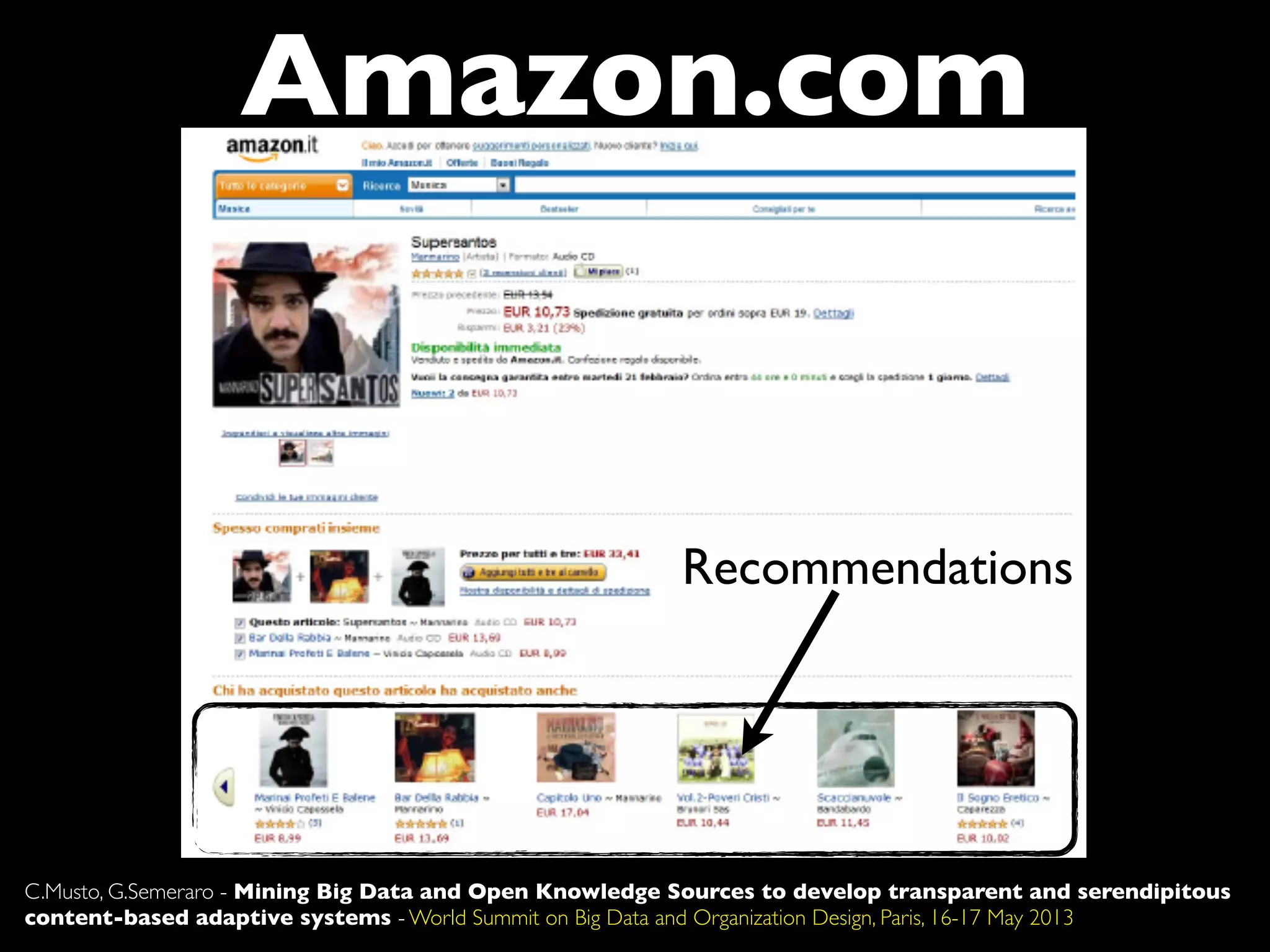













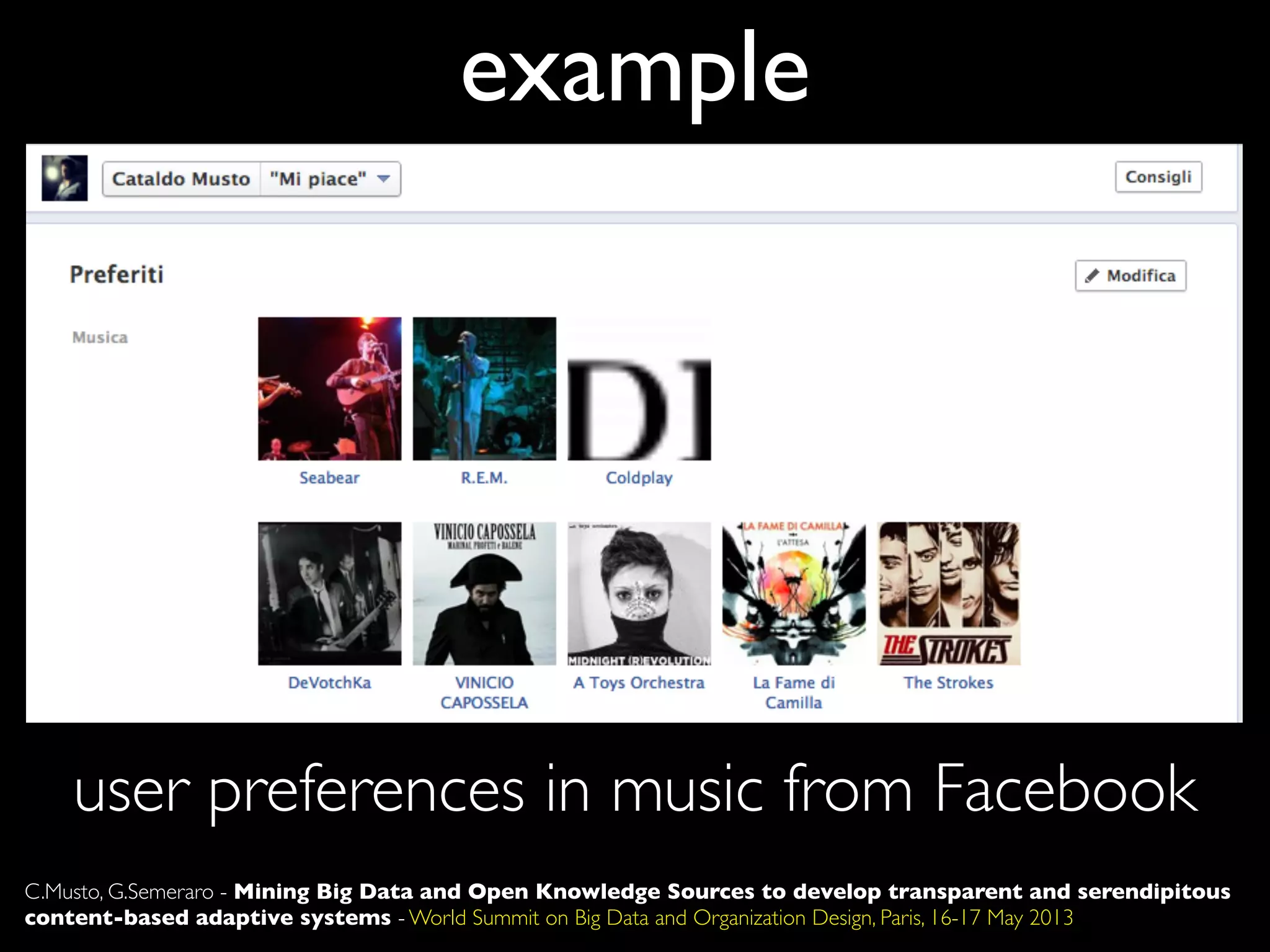
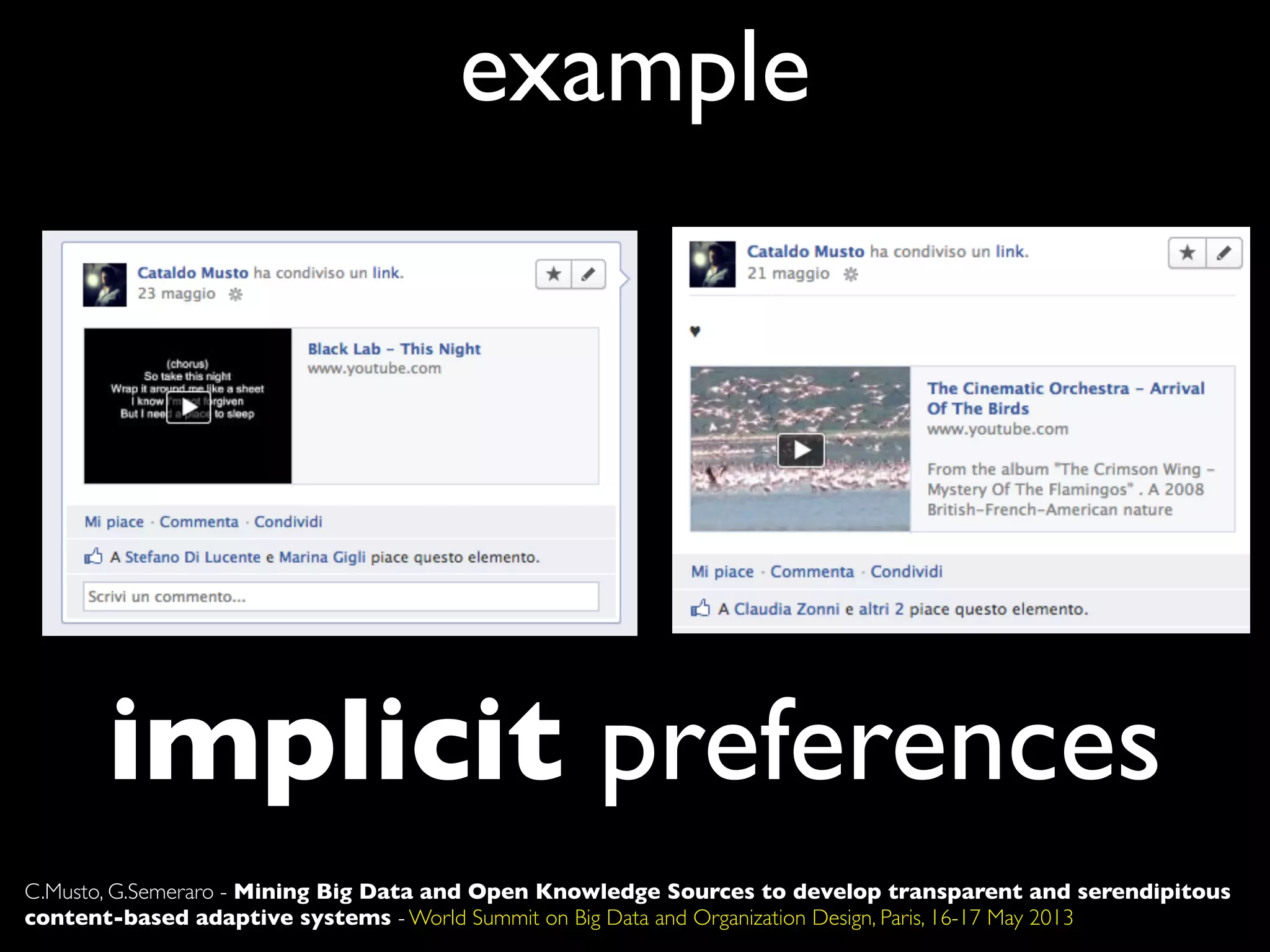
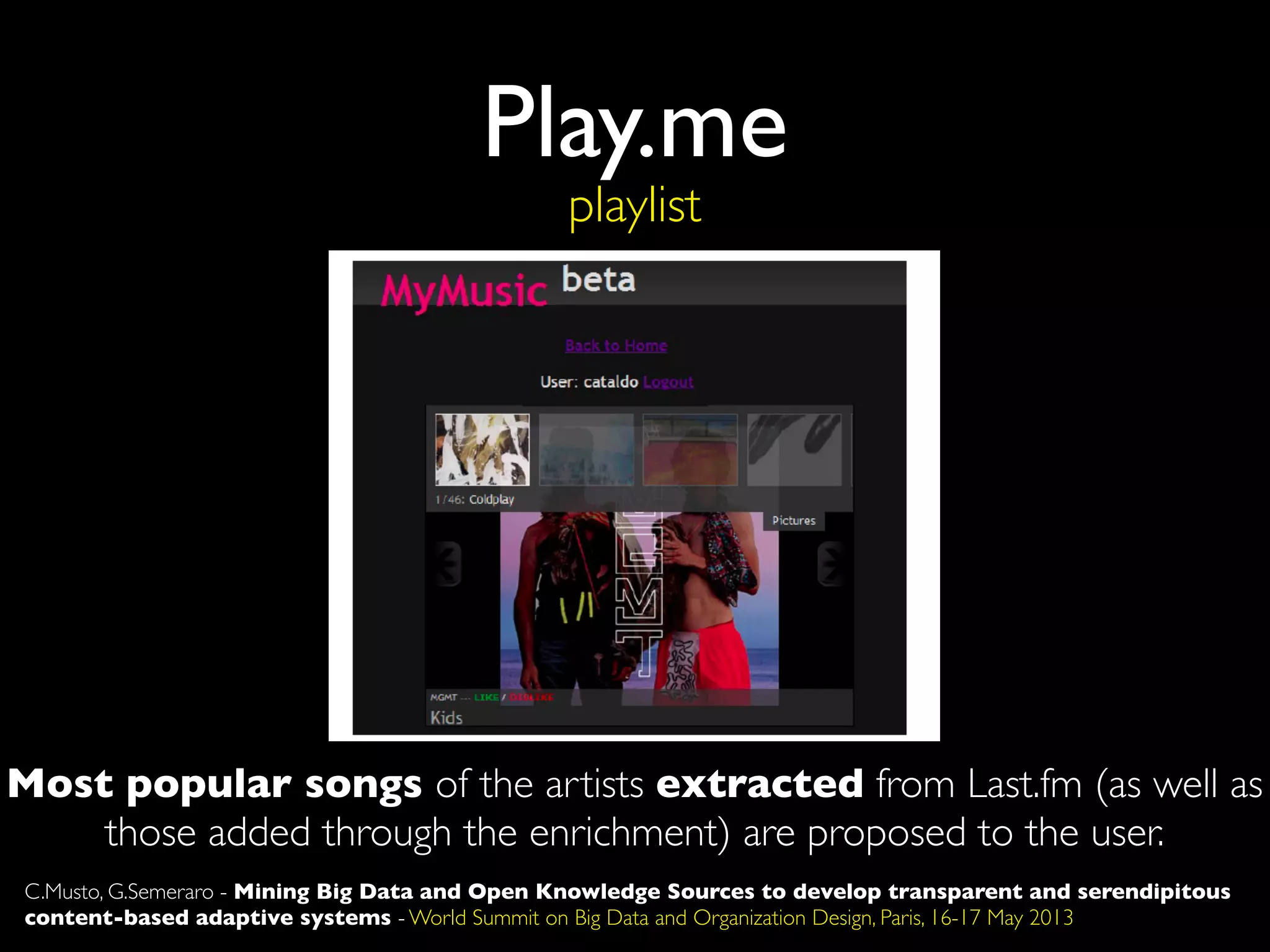


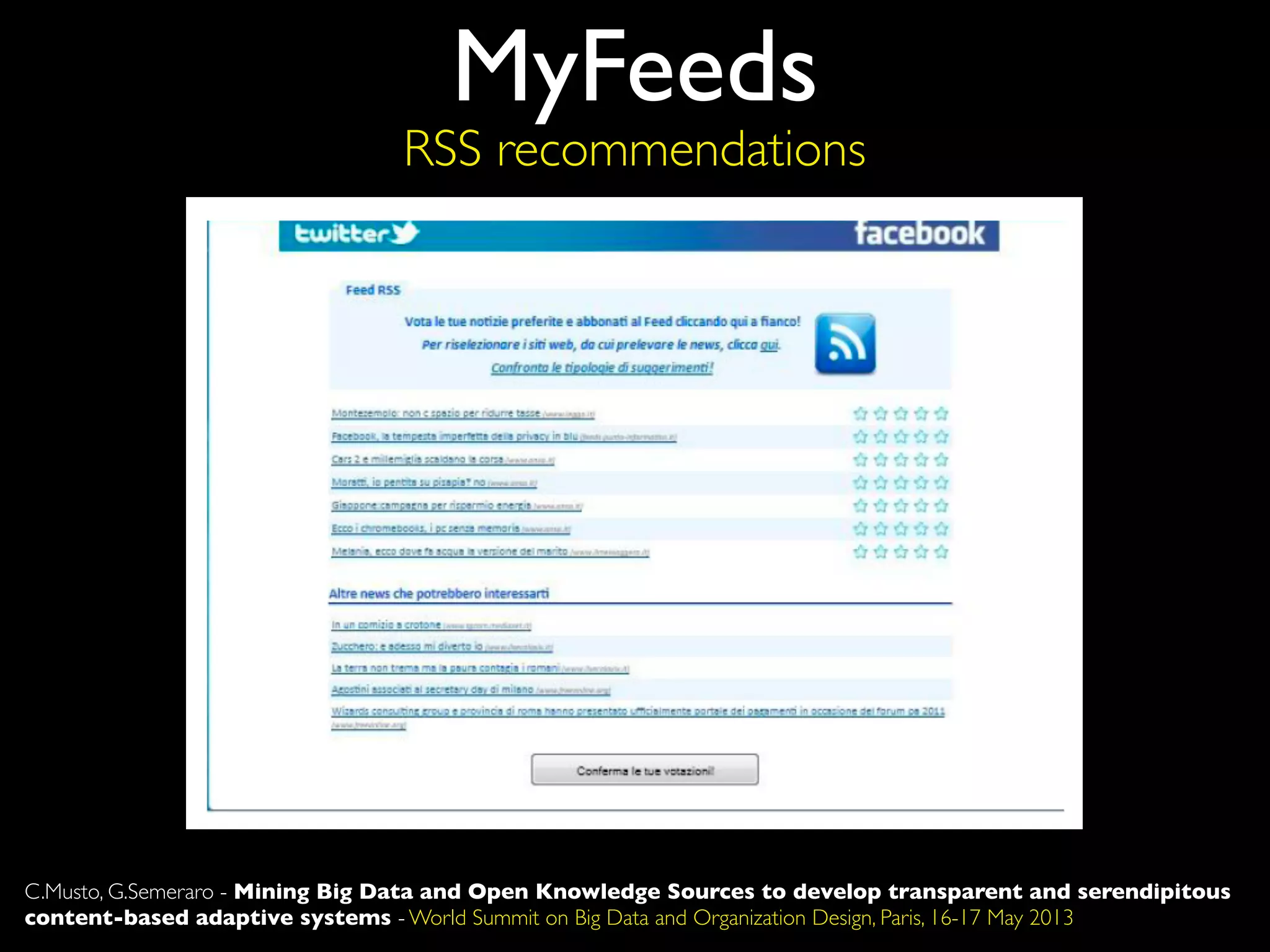

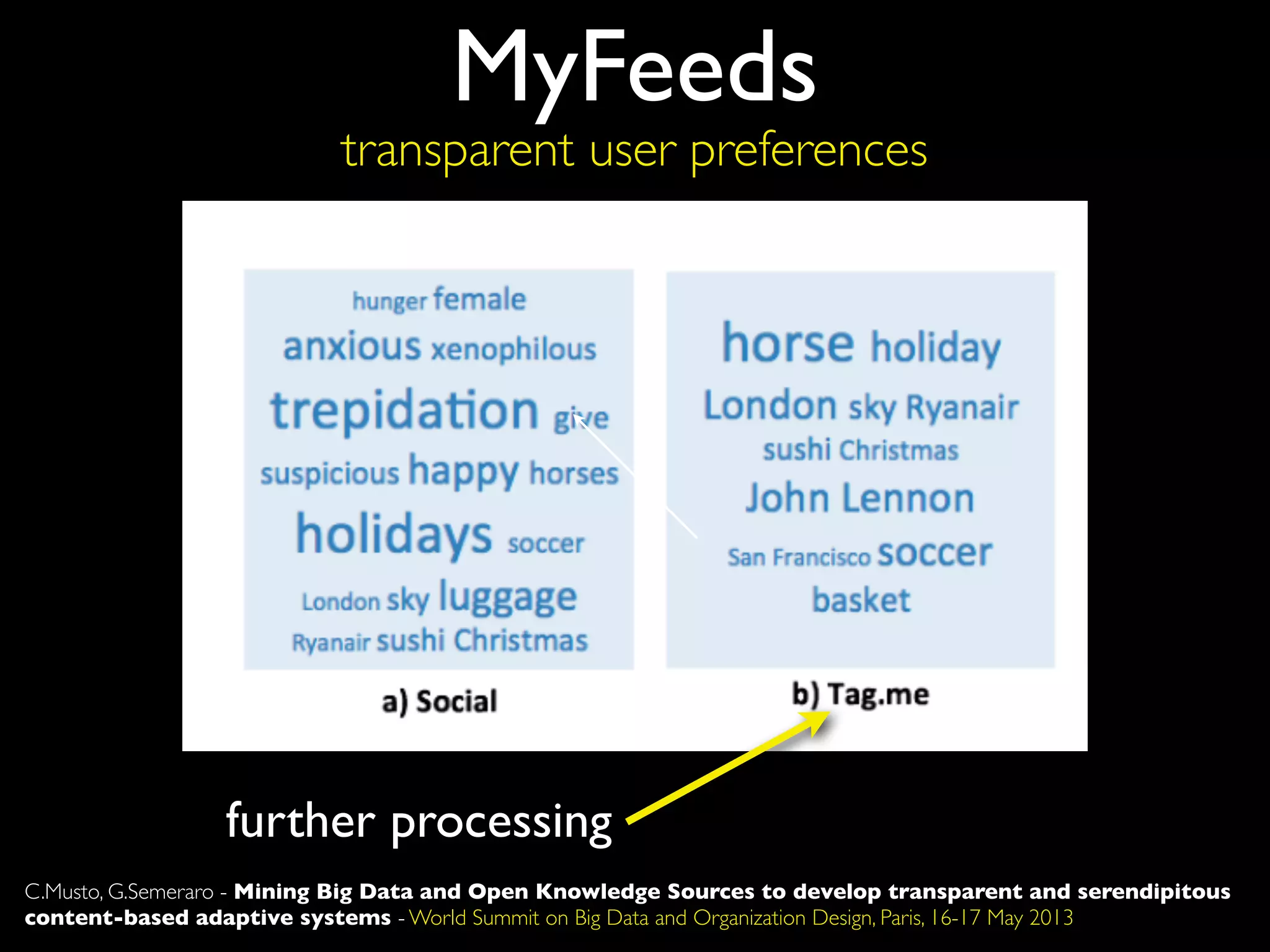


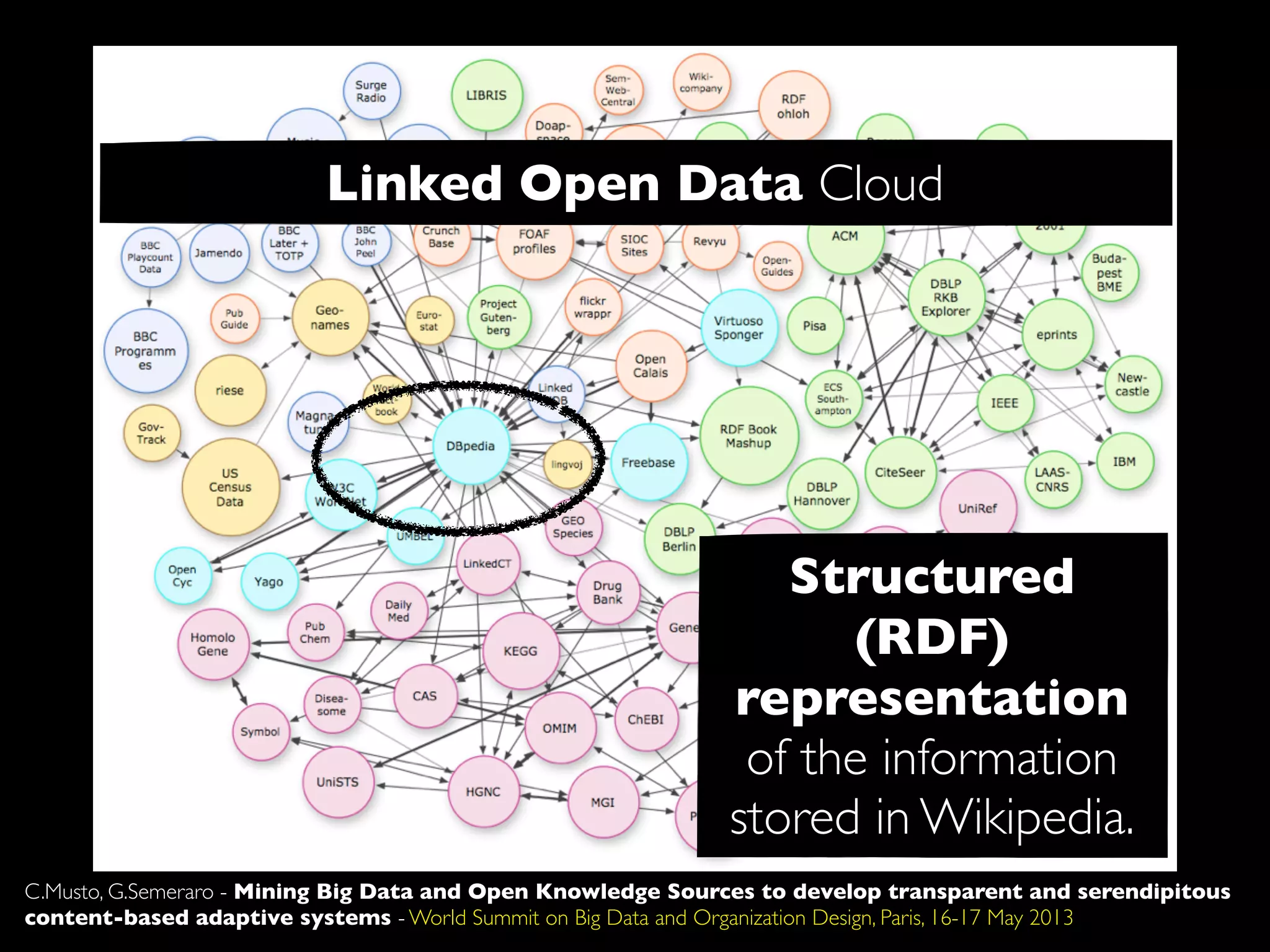


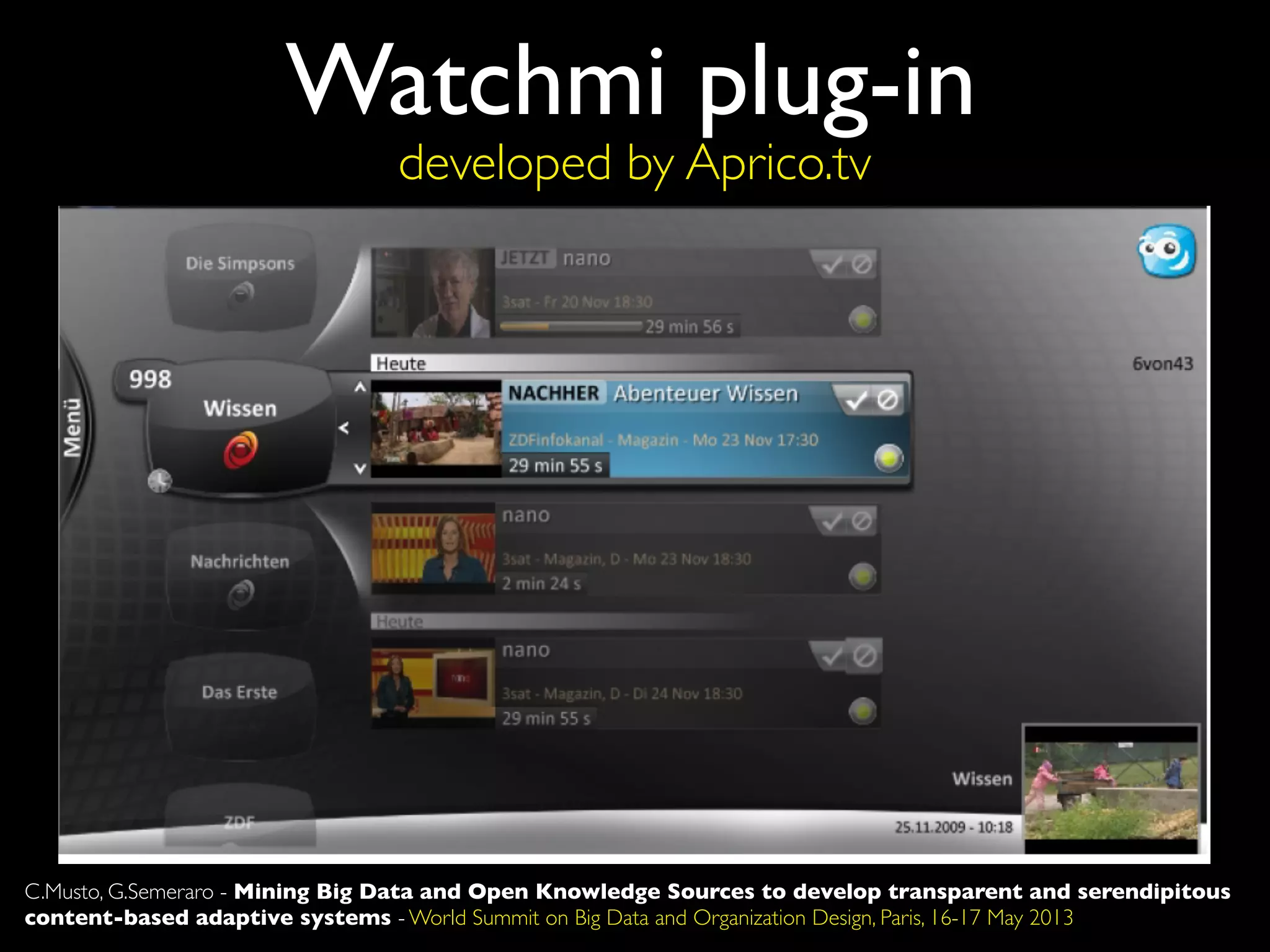







The document discusses developing transparent and serendipitous content-based adaptive systems using big data and open knowledge sources. It identifies three drawbacks of current recommendation technologies: training is a bottleneck, they are black boxes, and suggestions lack surprise. The authors propose a solution exploiting social media to model user preferences, entity linking to make profiles transparent and linked open data aware, and open knowledge sources to increase serendipity. Challenges include data representation and filtering while recommendations include promoting linked open data and interconnecting data silos.

















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















