Downloaded 11 times



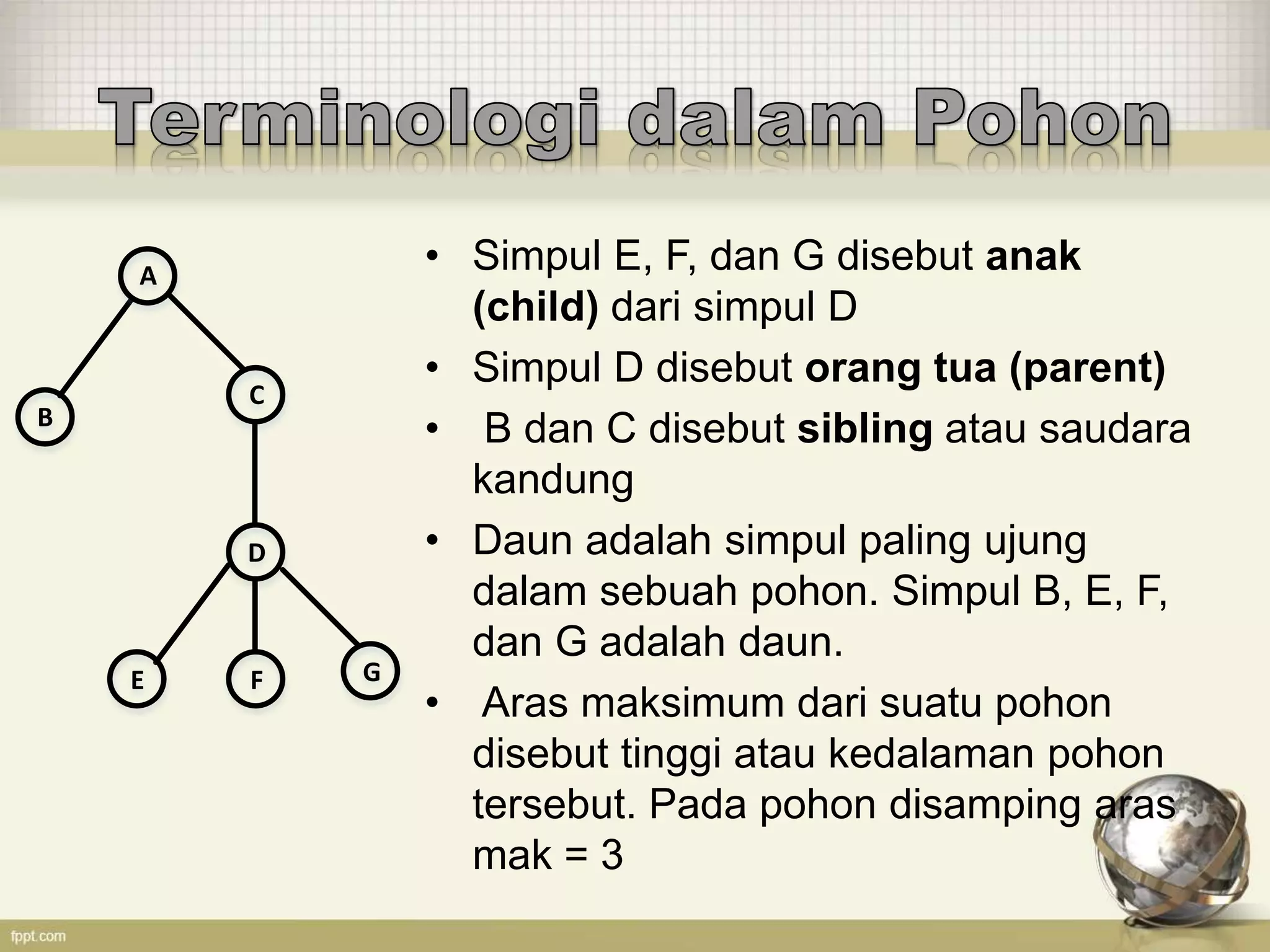








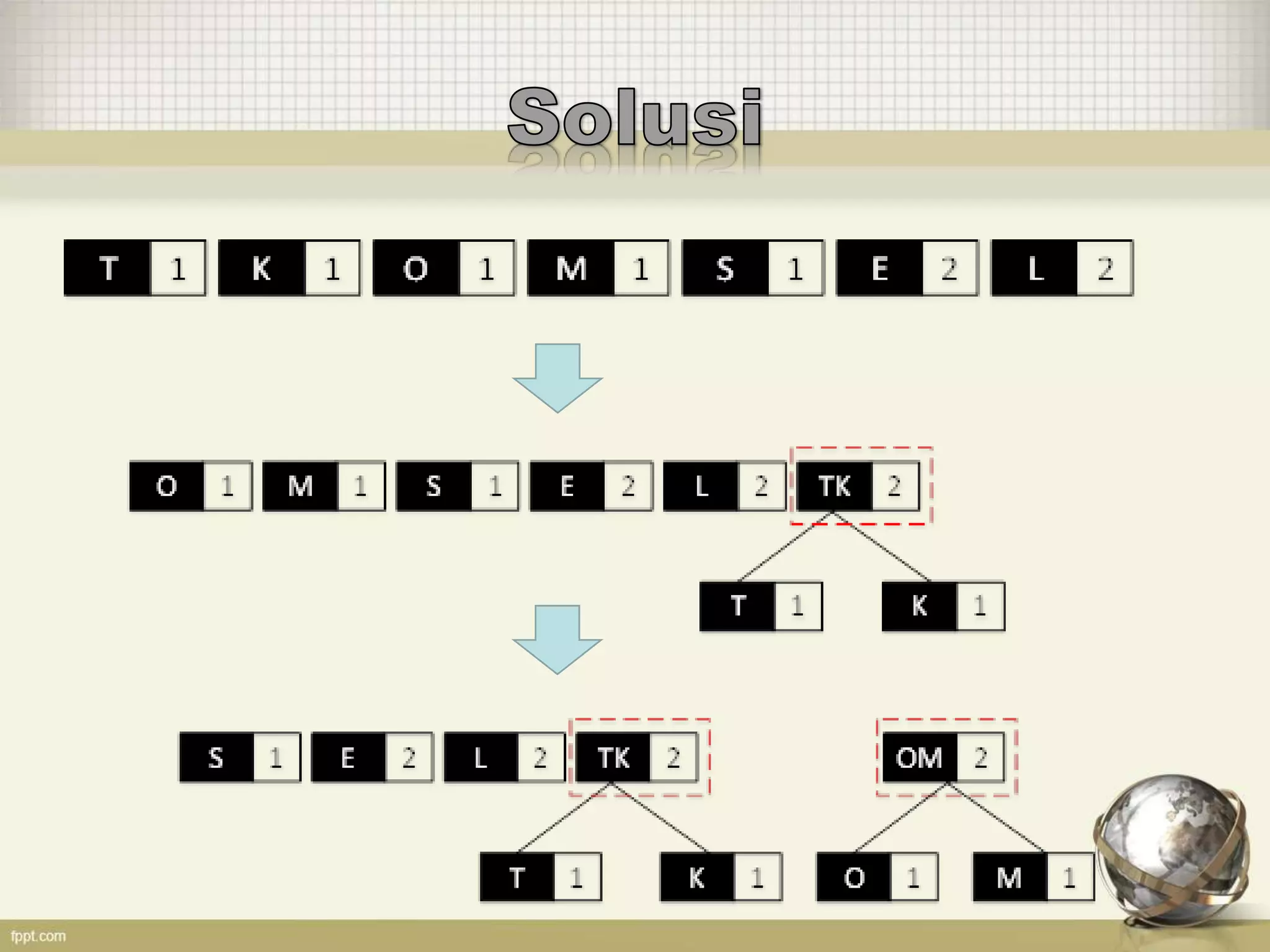
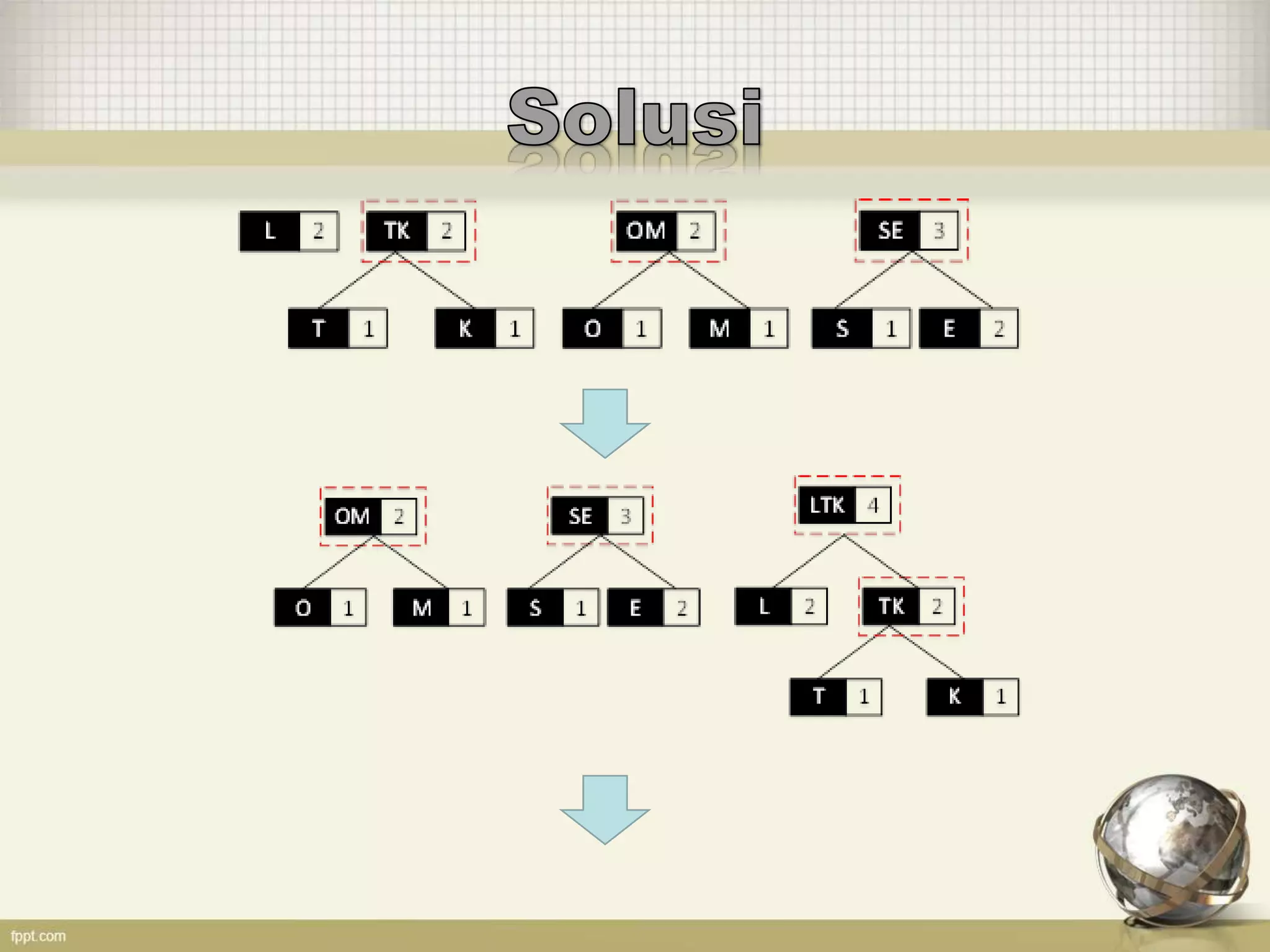
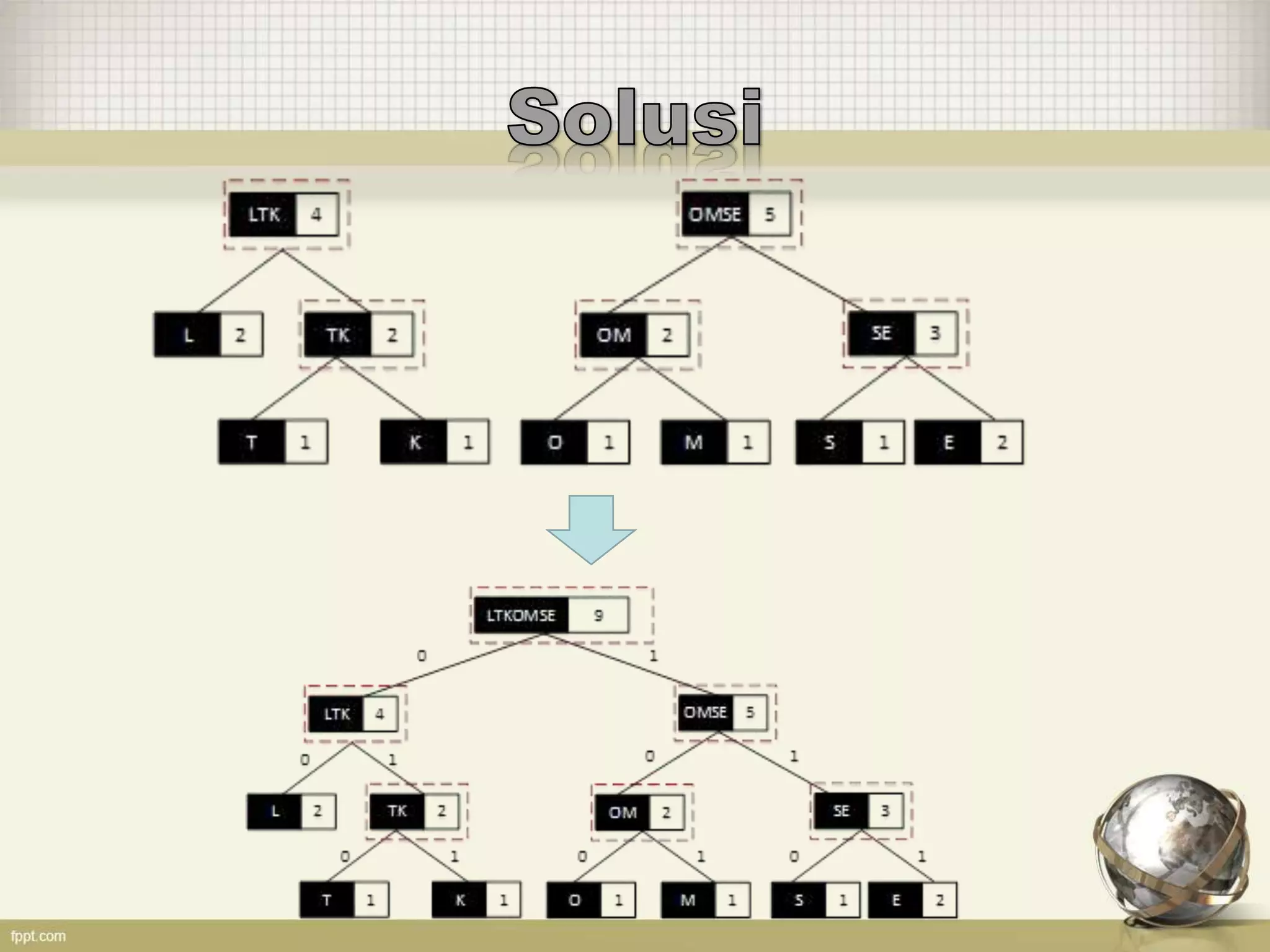


Dokumen tersebut membahas tentang kode Huffman, yaitu algoritma kompresi data yang memberi kode terpendek untuk simbol yang sering muncul dan kode terpanjang untuk simbol yang jarang muncul. Kode tersebut dibuat berdasarkan pohon biner Huffman yang disusun berdasarkan frekuensi kemunculan simbol. Contoh penerapannya untuk kata "SCIENCE" dan "TELKOMSEL" juga dijelaskan.






































