Download as PDF, PPTX


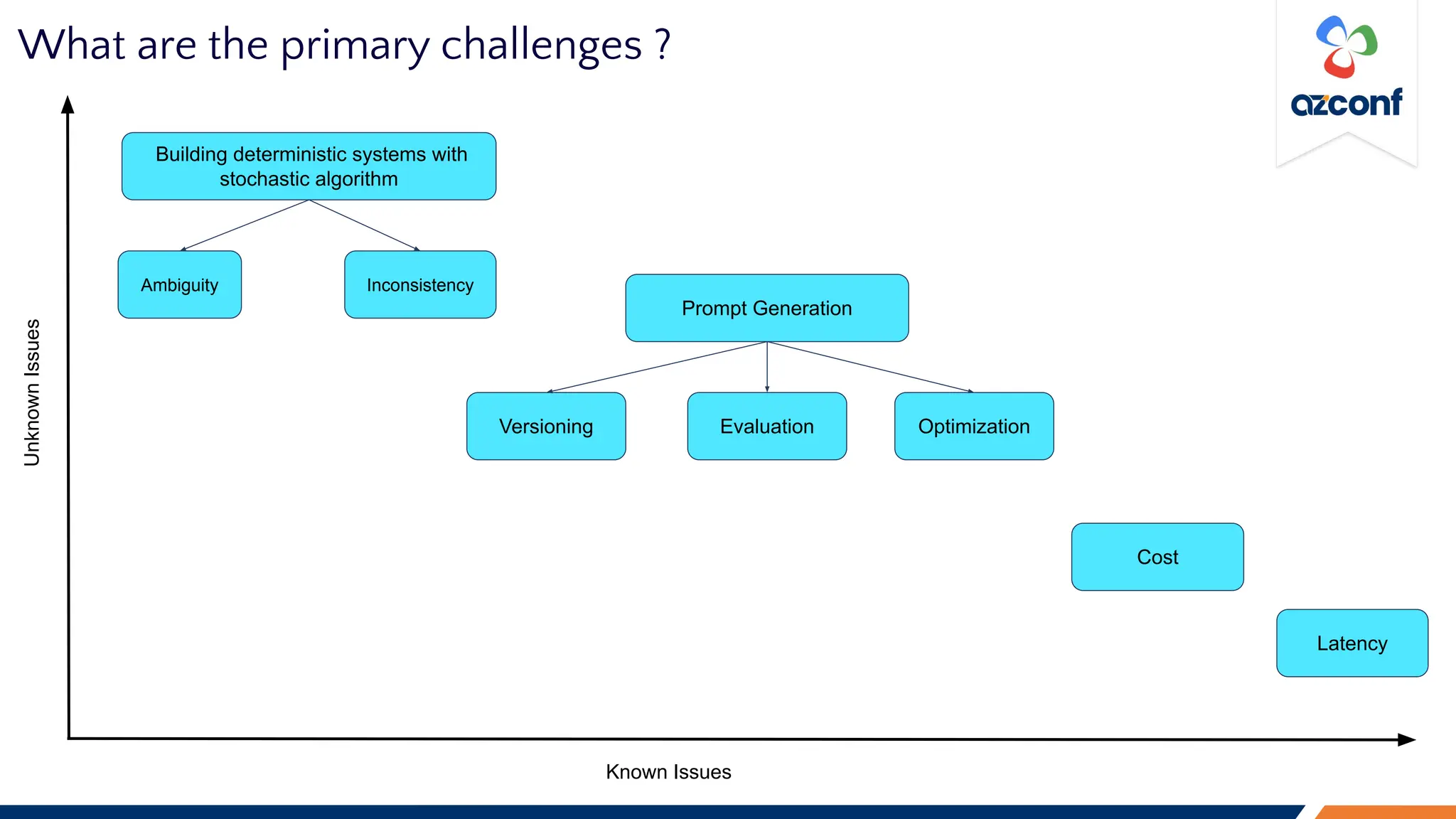

![Latency
1. No SLA [Ref: Running into a Fire: OpenAI Has No SLA (aragonresearch.com)]
a. Huge networking overhead
b. Exponentially volatile development speed
2. No clear indication of latency due to model size, networking or engineering overhead
a. With newer bigger models model size would be impact factor for latency
b. Networking and engineering overhead will be easier with newer releases
3. Difficult to estimate cost and latency for LLMs
a. Build vs buy estimates are tricky and outdated very quickly
b. Open-source vs Proprietary model comparison for enterprise use case are difficult
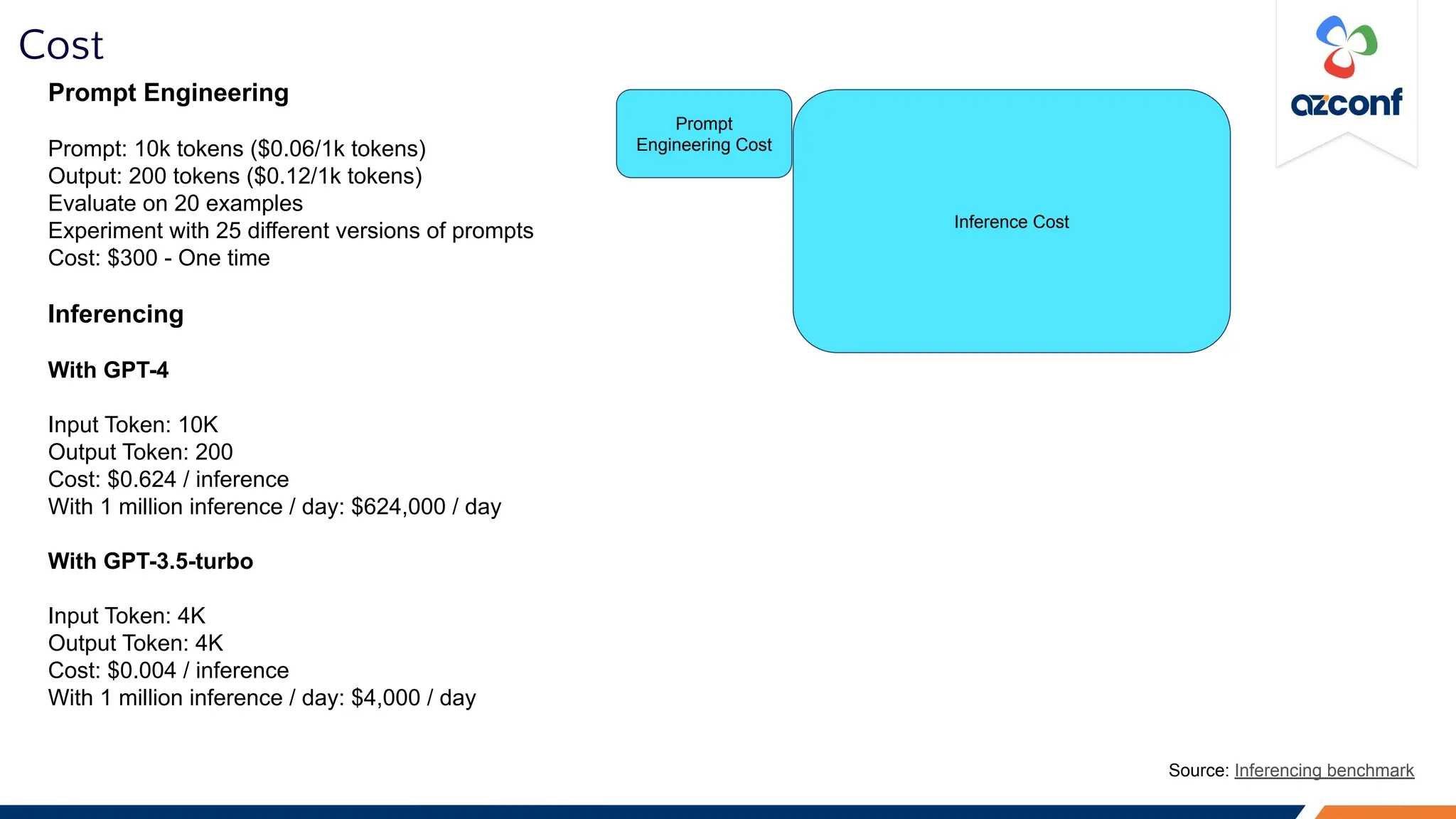
Latency for short token size:
Input token: 51
Output token: 1
Latency for GPT-3.5-turbo: 500 ms
Input Token Size Output Token Size Latency (Sec) for 90th Percentile
51 1 0.75
232 1 0.64
228 26 1.62
Source: Inferencing benchmark](https://image.slidesharecdn.com/azconf2023-considerationsforllmopsrunningllmsinproduction-231208084301-b3f79127/75/AZConf-2023-Considerations-for-LLMOps-Running-LLMs-in-production-10-2048.jpg)
![References
1. MLOps guide (huyenchip.com)
2. How many data points is a prompt worth [How Many Data Points is a Prompt Worth? | Abstract (arxiv.org)]
3. OpenAI GPT-3 Text Embeddings - Really a new state-of-the-art in dense text embeddings? | by Nils Reimers |
Medium
4. llama-chat [randaller/llama-chat: Chat with Meta's LLaMA models at home made easy (github.com)]
5. Understanding LLMOps: Large Language Model Operations - Weights & Biases (wandb.ai)
6. OpenAI Cookbook [openai/openai-cookbook: Examples and guides for using the OpenAI API (github.com)]
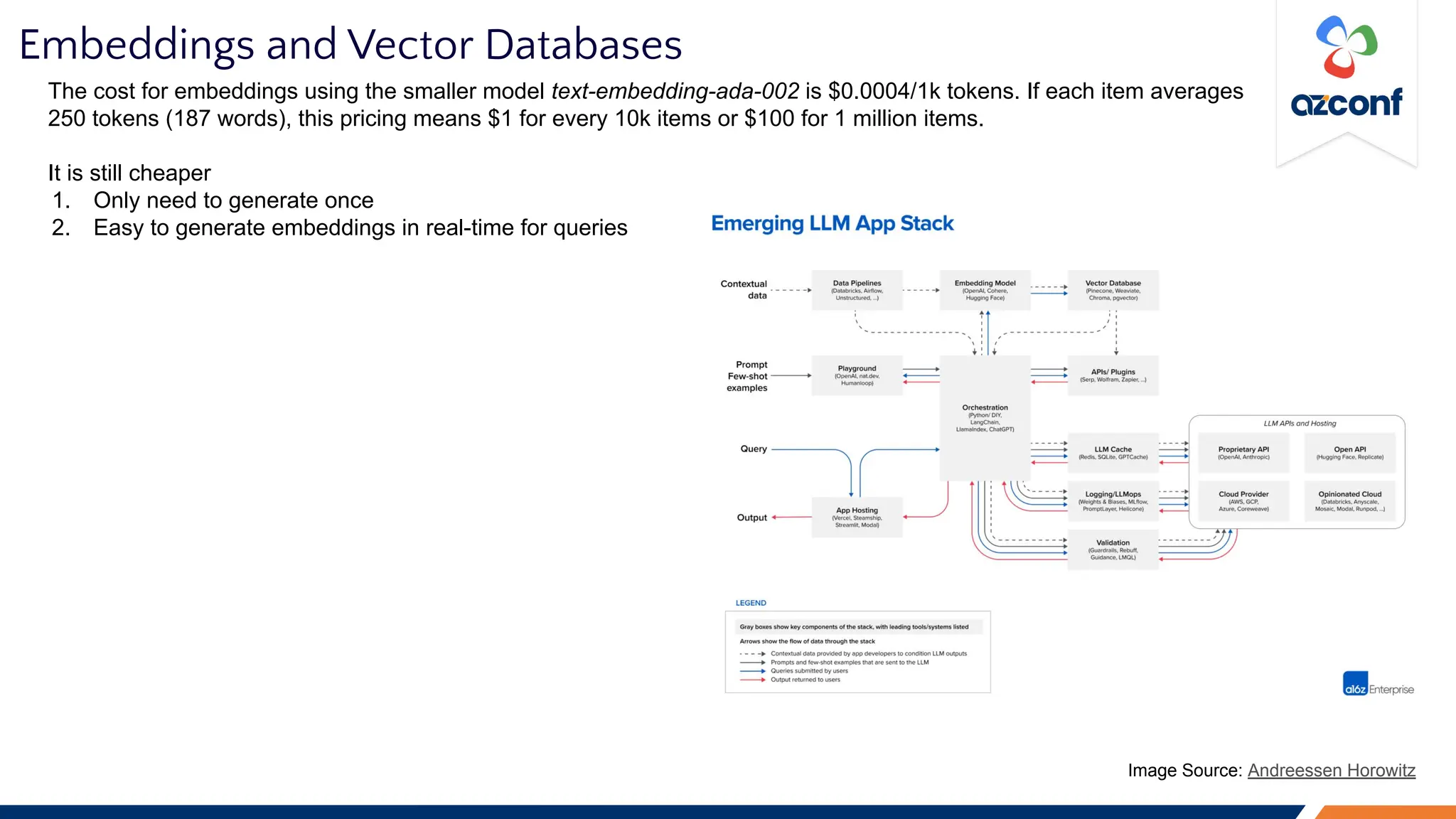
Image Source: Andreessen Horowitz](https://image.slidesharecdn.com/azconf2023-considerationsforllmopsrunningllmsinproduction-231208084301-b3f79127/75/AZConf-2023-Considerations-for-LLMOps-Running-LLMs-in-production-14-2048.jpg)



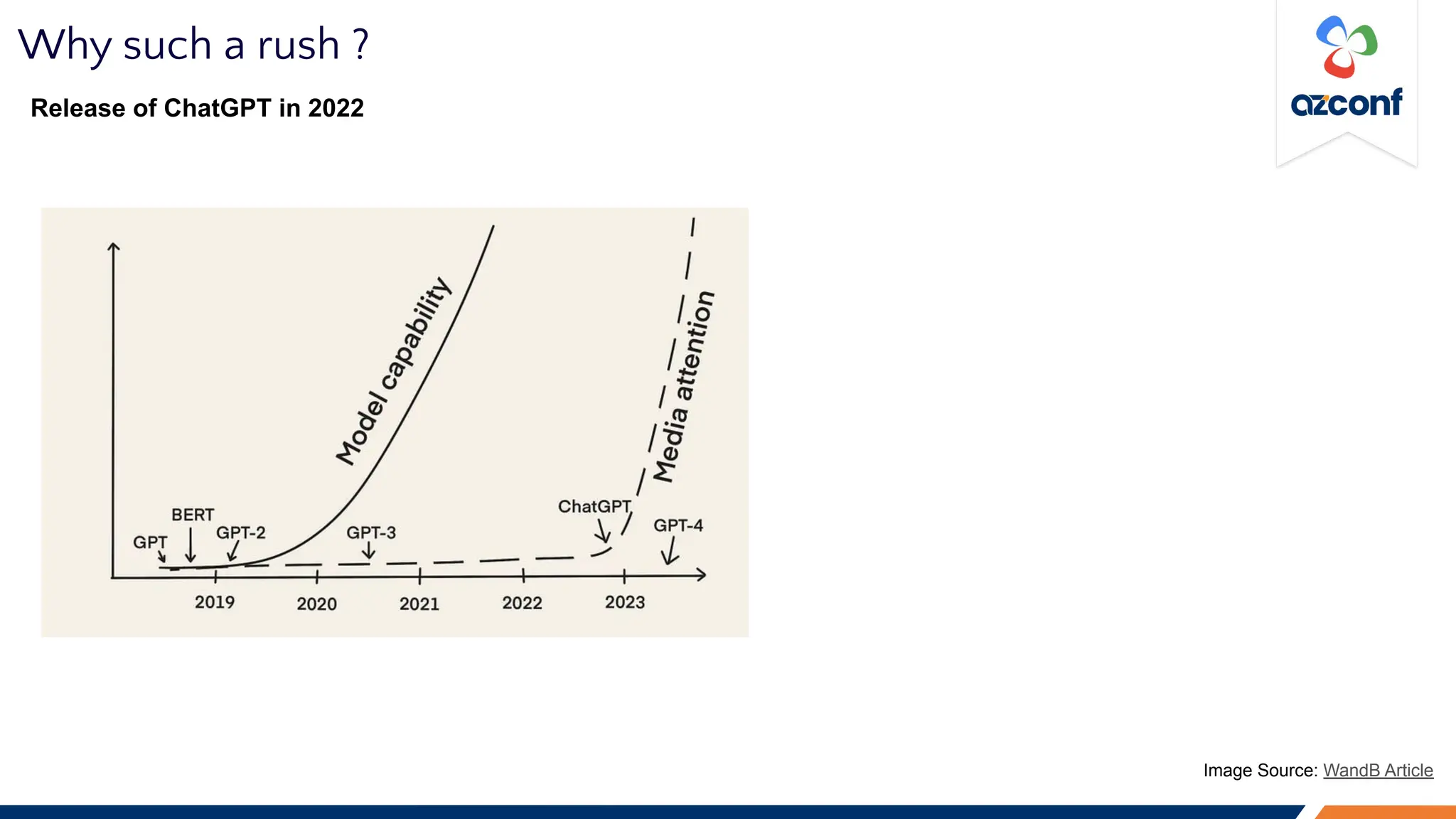
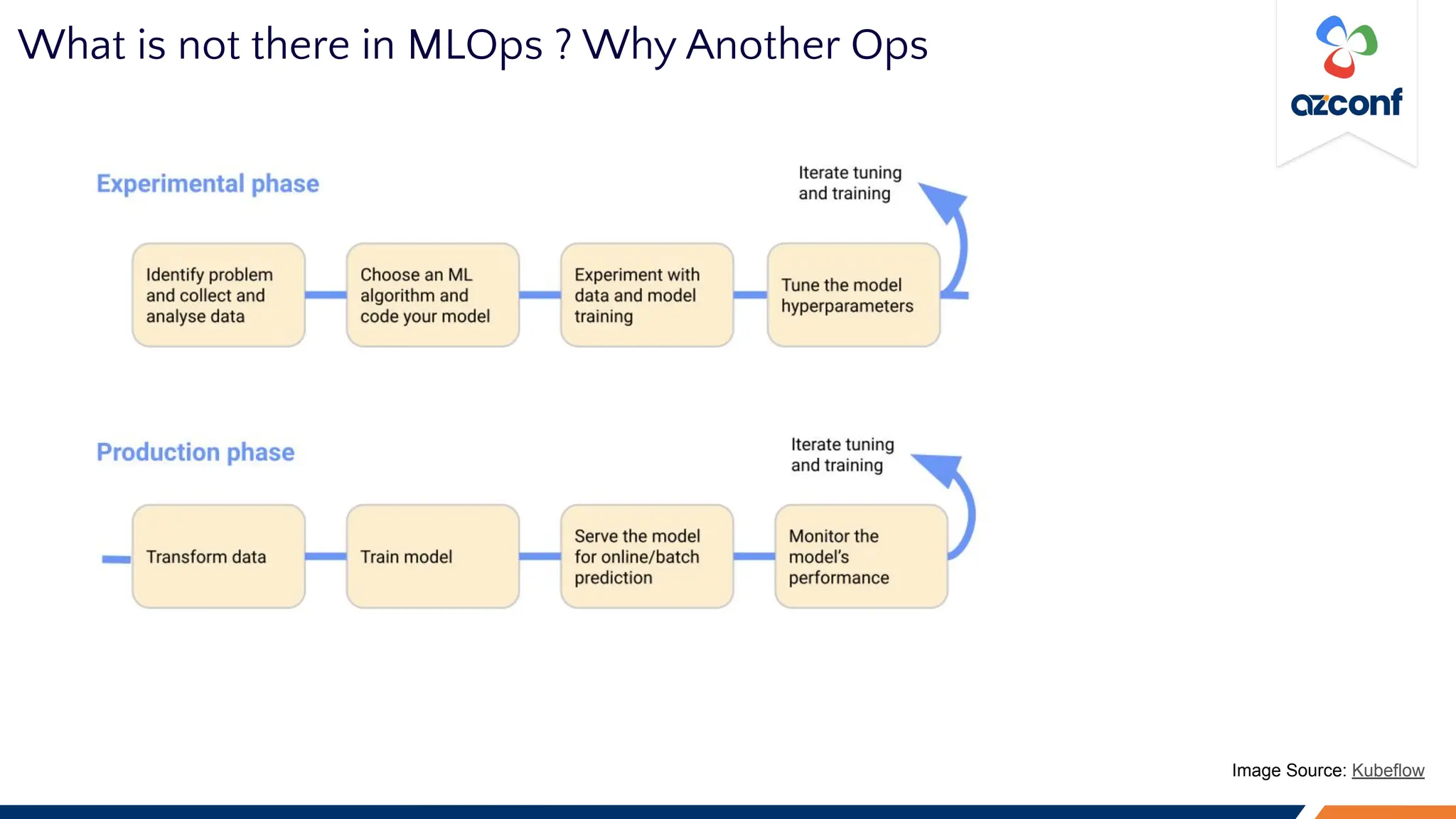
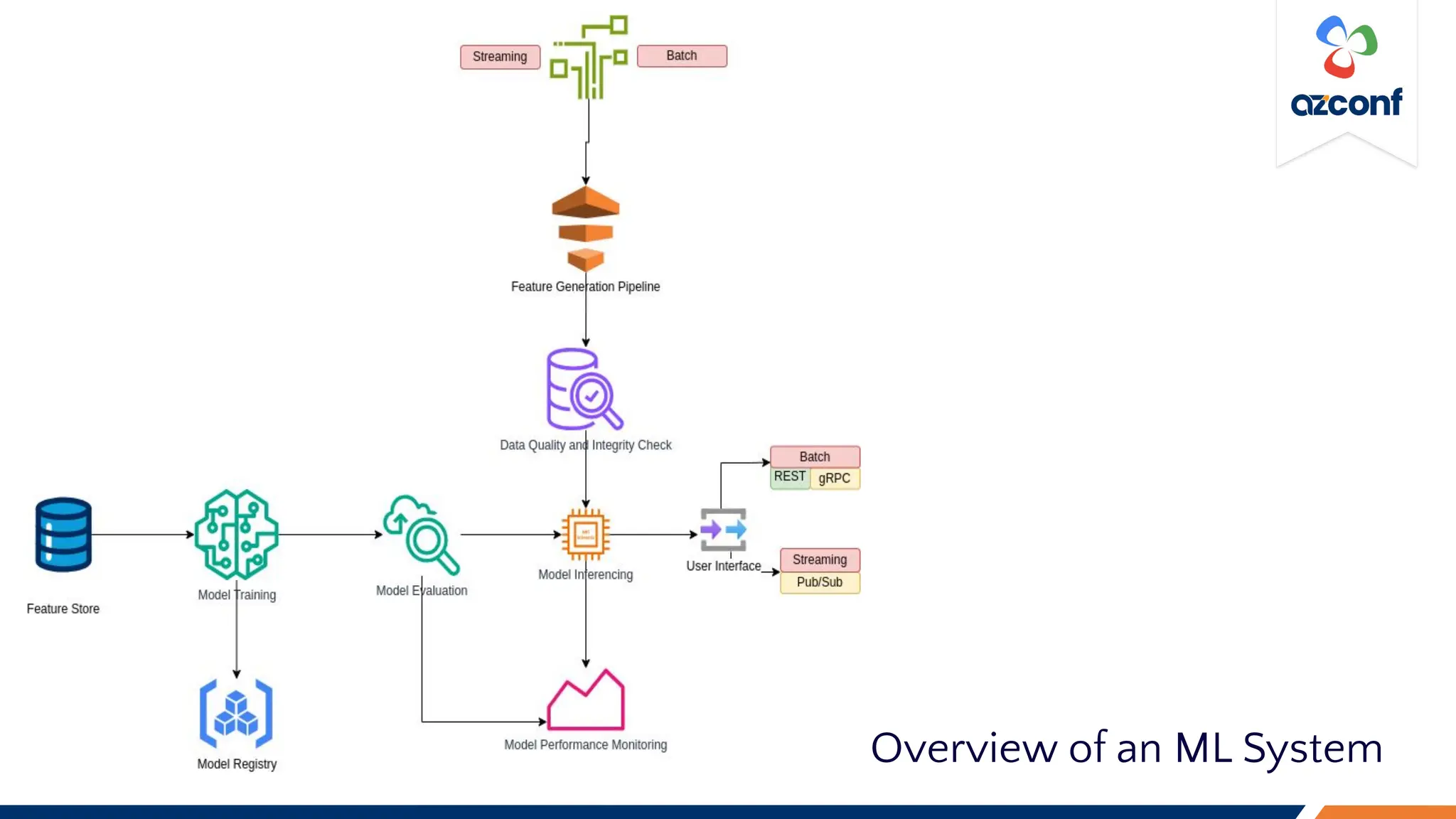
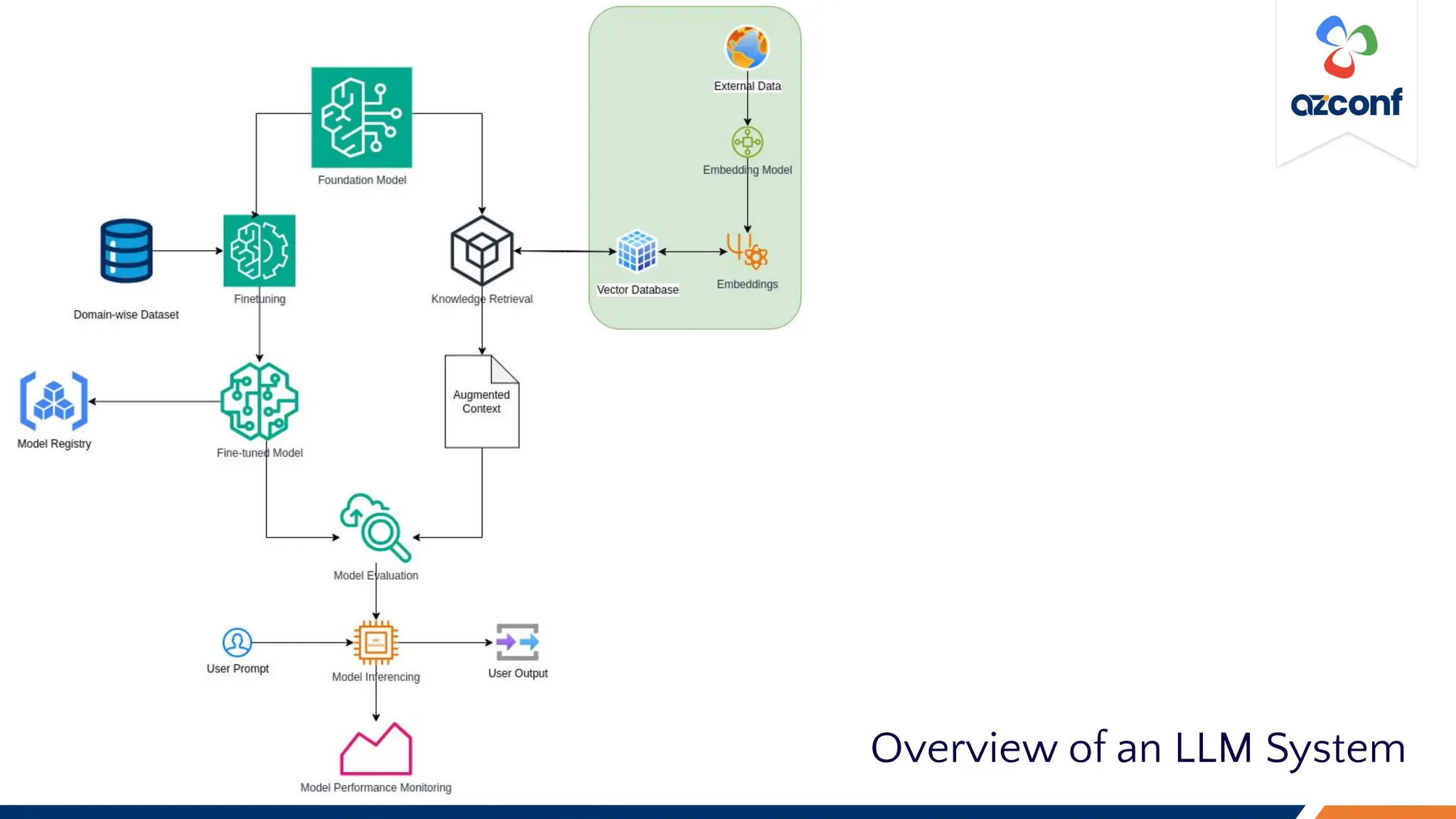
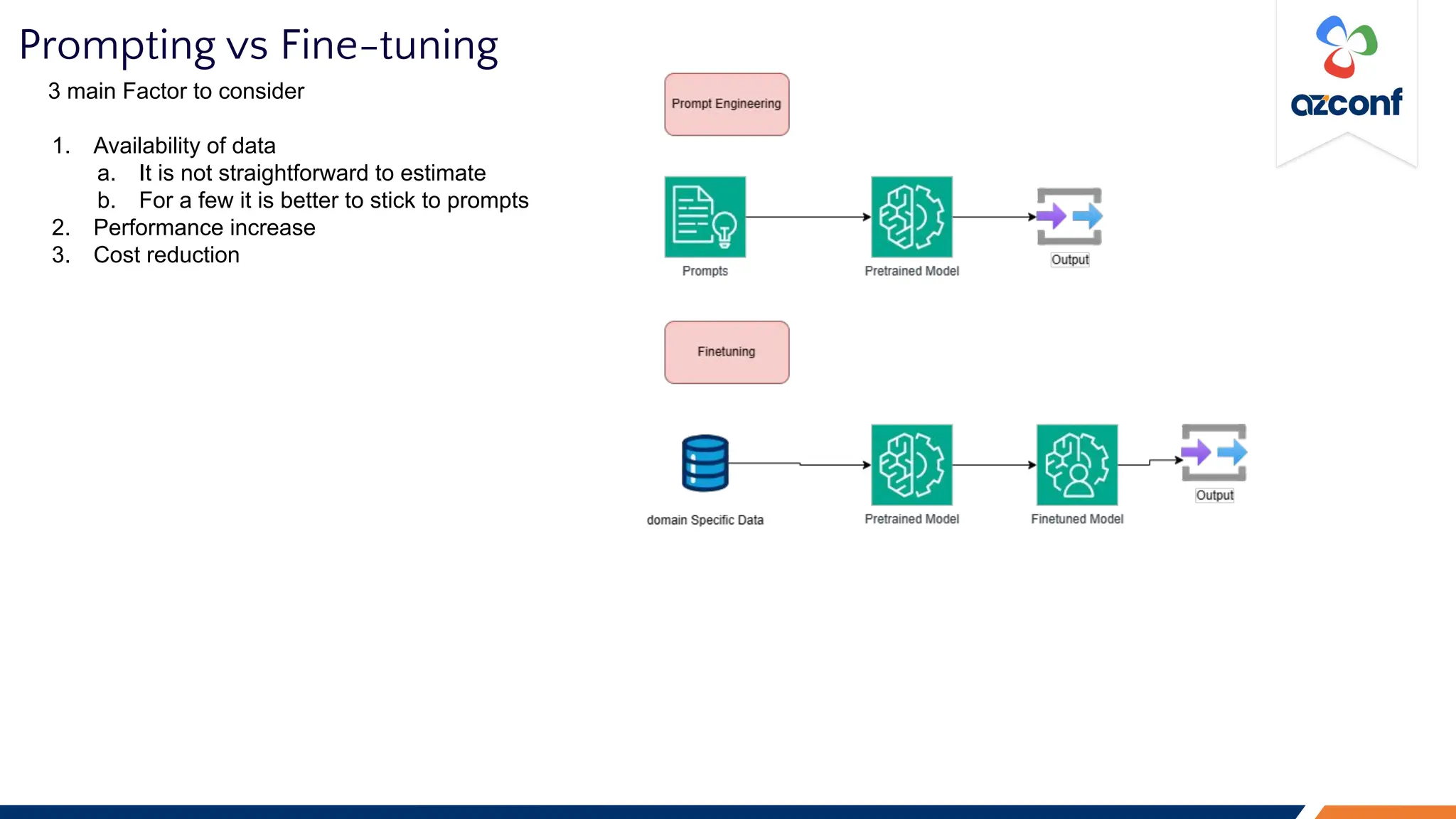
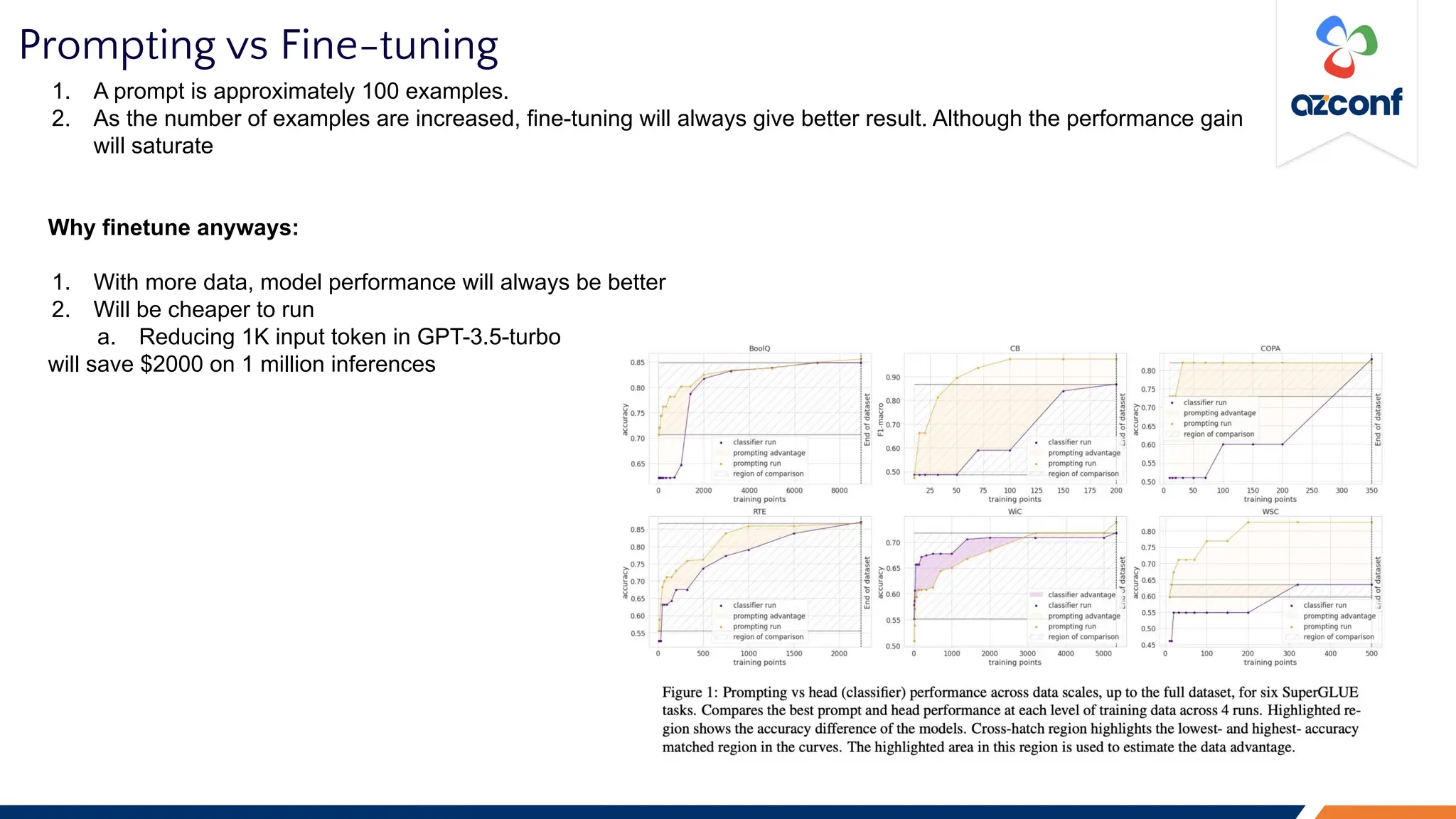
The Cloud & AI Conference 2023, held at IIT Madras on November 17-18, focuses on the challenges and costs associated with running Large Language Models (LLMs) in production settings. Key discussion points include the importance of deterministic outputs, the intricacies of cost and latency management, and the trade-offs between prompt engineering and fine-tuning. The document outlines optimization strategies for inference costs and emphasizes the need for evolving design mindsets to handle the stochastic nature of LLMs.











![[DSC Europe 23] Tamara Stankovic - From Prompt To Product Microsoft 365 Copil...](https://cdn.slidesharecdn.com/ss_thumbnails/dsceurope23tamarastankovic-fromprompttoproductmicrosoft365copilot-231128230444-9b77578f-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 23] Dmitry Ustalov - Design and Evaluation of Large Language Models](https://cdn.slidesharecdn.com/ss_thumbnails/dmitryustalov-designandevaluationofllms-231128235048-b0b24f5d-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)
