


















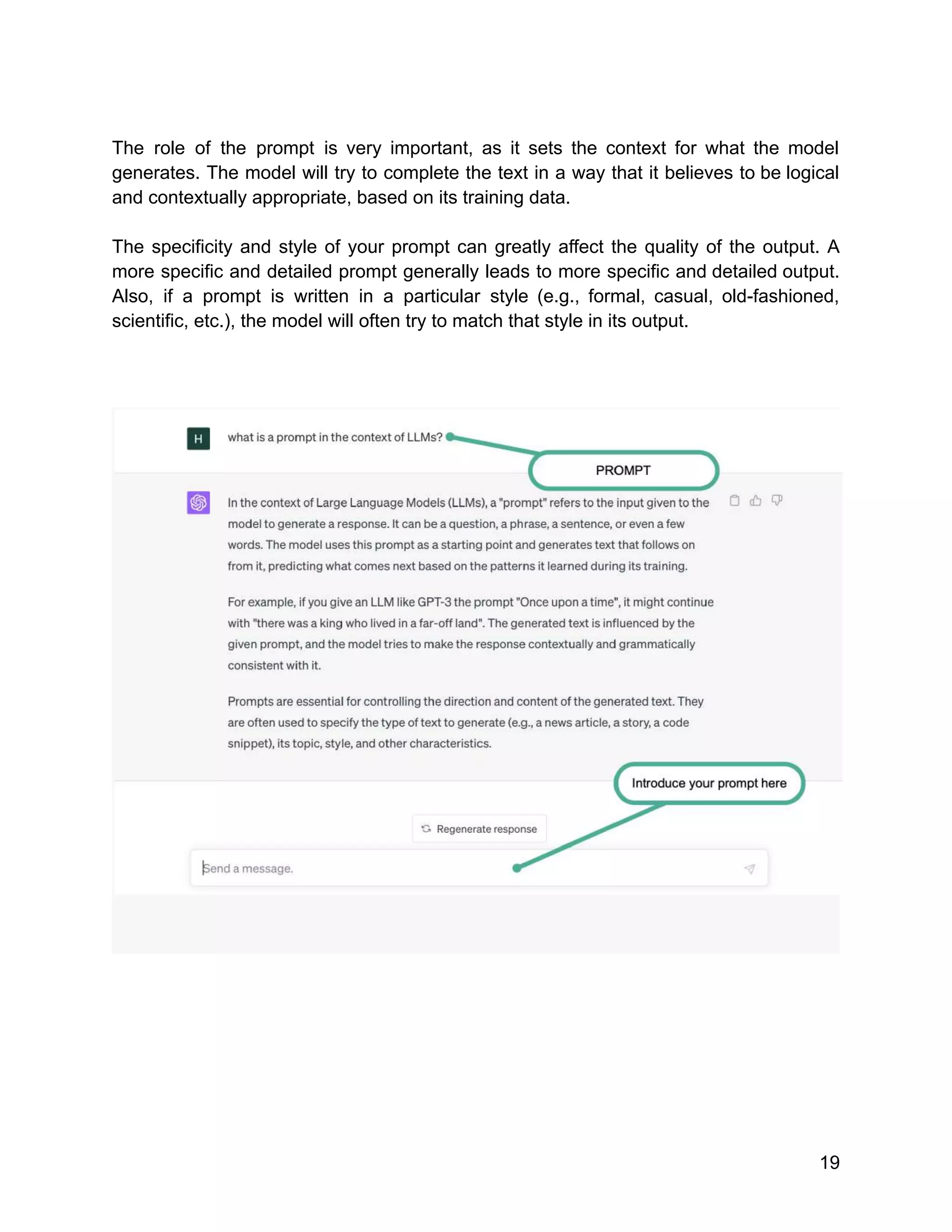







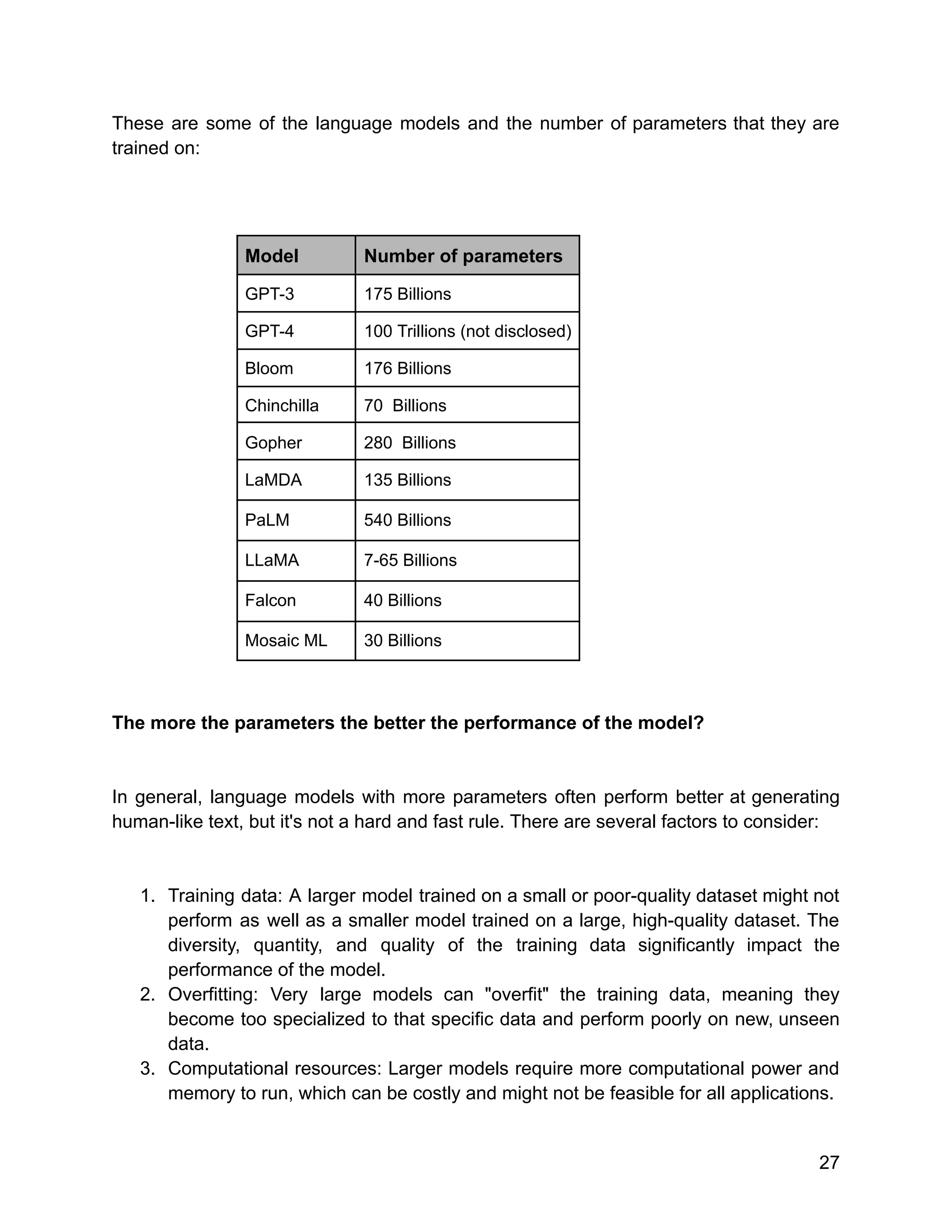



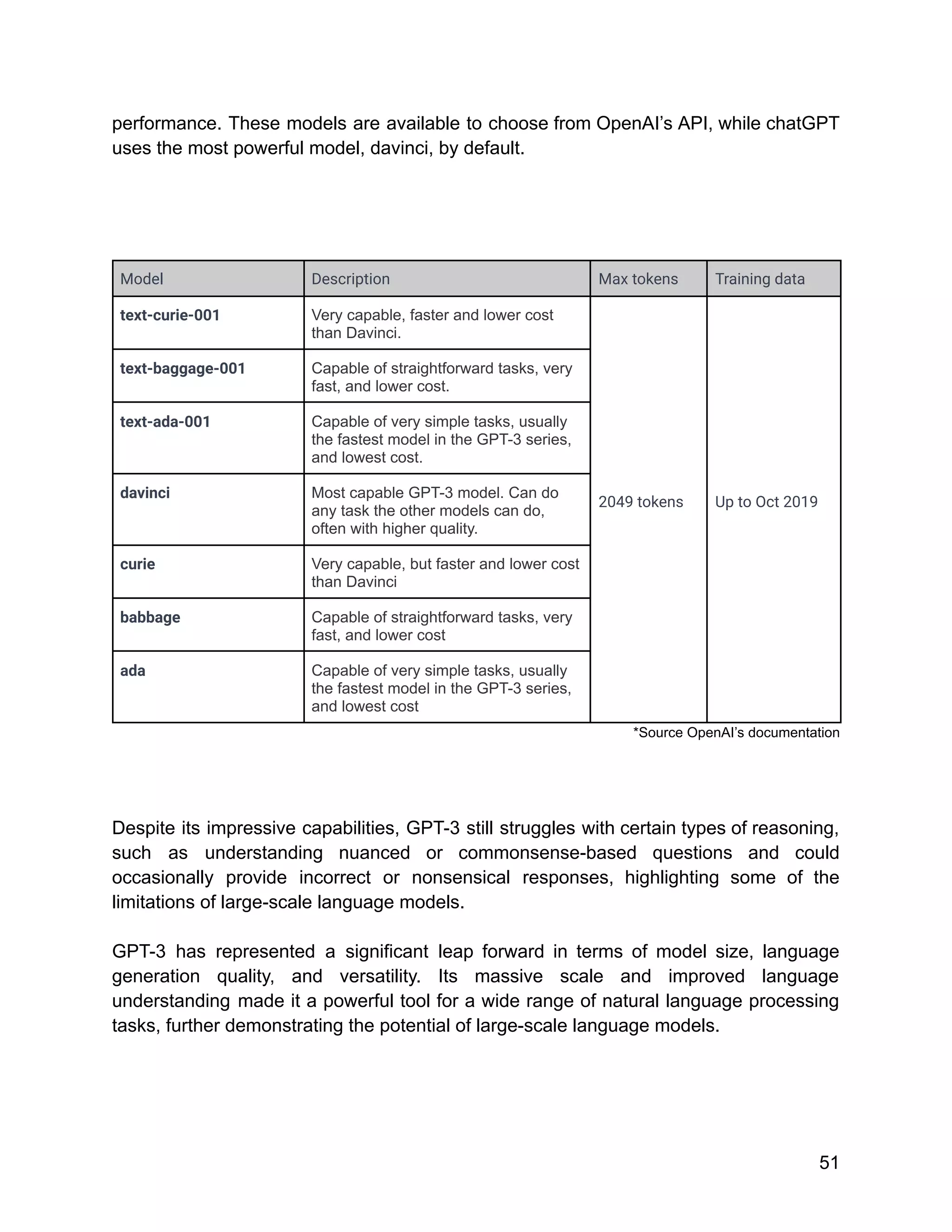
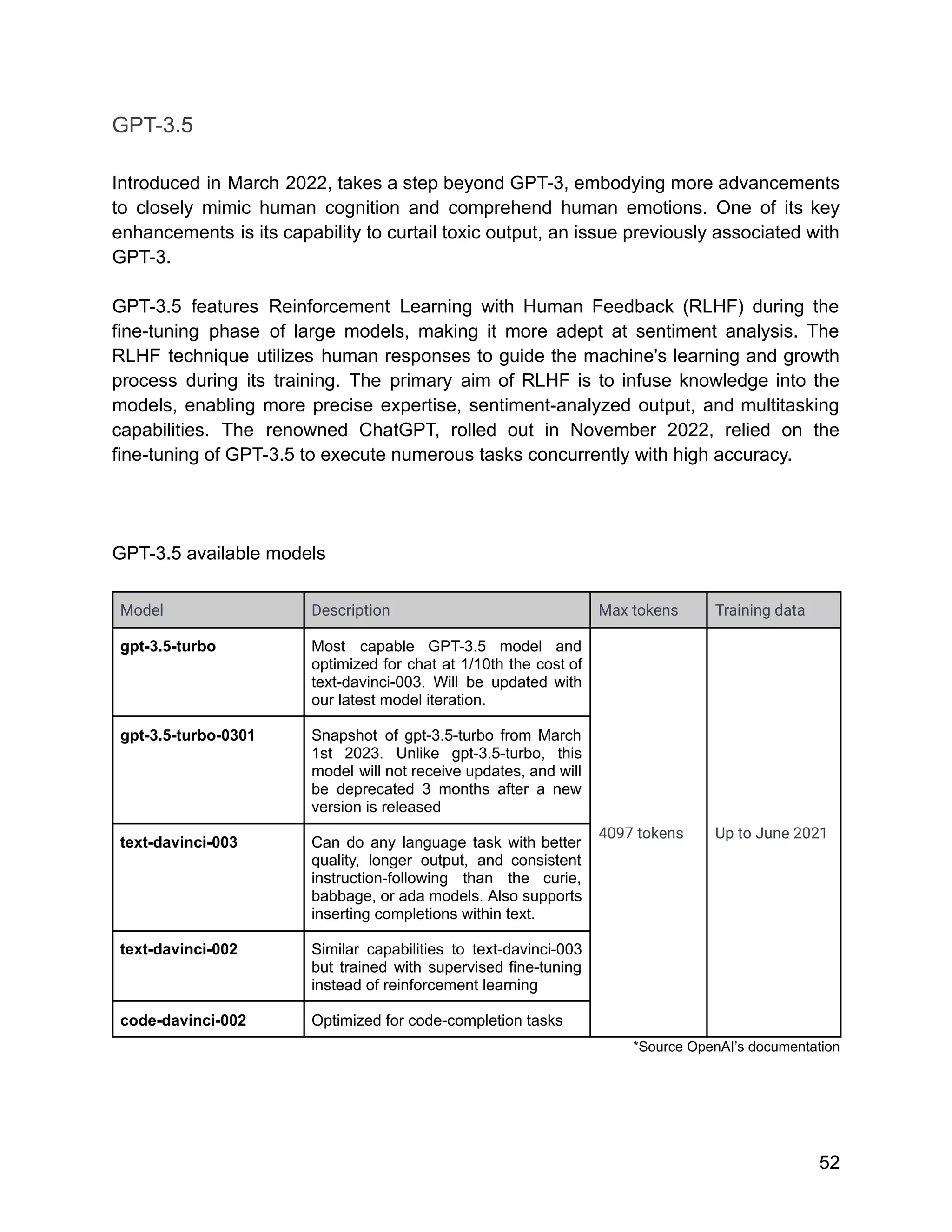
![Google uses TPUs extensively in their data centers and also makes them available to
external developers through their Google Cloud services.
Tokens
A token is a unit of text that the model reads, processes, and generates. It can
represent a word, a character, or even a subword depending on how the model has
been trained.
Imagine that you are reading a book word by word. Each word you read could be
considered a token. Now, instead of reading, imagine you're writing a story word by
word. Each word you write could also be a token.
In language models, tokens are typically chunks of text. For example, in the sentence
"ChatGPT is awesome!", the model might see each word and the punctuation mark at
the end as separate tokens: ["ChatGPT", "is", "awesome", "!"].
These models are often trained and operate within a maximum token limit due to
computational constraints. For instance, GPT-3 works with a maximum of 2048 tokens.
This means the model can consider and generate text up to 2048 tokens long, which
includes the input and output tokens.
In terms of tokens, GPT-4 has two context lengths which decide the limits of tokens
used in a single API request. The GPT-4-8K window allows tokens up to 8,192 tokens,
and the GPT-4-32K window has a limit of up to 32,768 tokens (up to 50 pages) at one
time.
So, tokens are the building blocks that AI models use to understand and generate text.
GPT-3 and similar models actually use a tokenization strategy that splits text into
chunks that can be as small as one character or as large as one word. This approach is
based on a method called Byte-Pair Encoding (BPE), which helps manage the tradeoff
between having too many tokens (like a character-based approach) and too few tokens
(like a word-based approach).
Here's a simplified explanation: Let's say you're reading a book, and you come across
the word "unhappiness". Instead of treating "unhappiness" as a single token, the BPE
method might split it into smaller tokens like ["un", "happiness"] or even ["un", "happy",
"ness"], depending on what token divisions it has learned are most useful. This is
31](https://image.slidesharecdn.com/unleashinginnovationexploringgenerativeaiintheenterprise-230902054044-64bcf15c/75/UNLEASHING-INNOVATION-Exploring-Generative-AI-in-the-Enterprise-pdf-32-2048.jpg)













































































































































The document provides an overview of generative AI, including its key concepts and applications. It discusses transformer models versus neural networks, explaining that transformer models use self-attention to capture long-range dependencies in sequential data like text. Large language models (LLMs) based on the transformer architecture have shown strong performance in natural language generation tasks. The document outlines the evolution of generative AI techniques from early machine learning to modern large pretrained models. It also surveys some commercial generative AI applications in industries like healthcare, finance, and gaming.







![[DSC Europe 23] Ivan Petrovic - Approach to Architecting Generative AI Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/ivanpetrovic-approachtoarchitectinggenerativeaisolutions-231129100808-16df2918-thumbnail.jpg?width=640&height=640&fit=bounds)


























































![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)












