Download to read offline







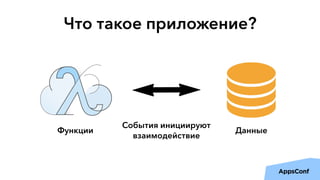





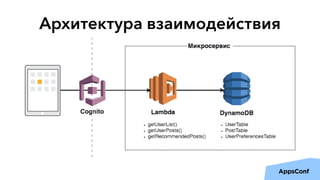





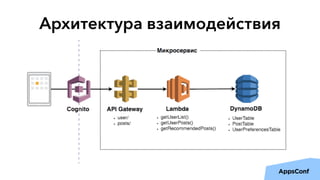



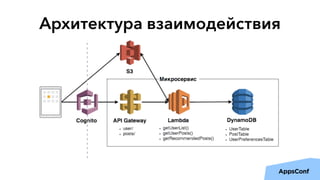





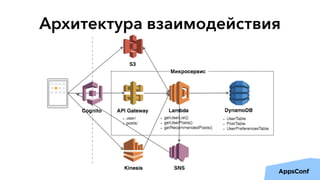





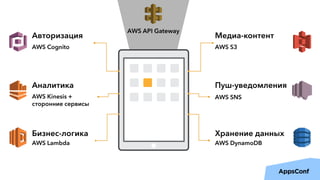


Документ описывает реализацию бессерверного бэкенда мобильного приложения с использованием AWS, включая тенденции, администрирование и безопасность. Основные темы включают разработку логики приложения, управление данными, масштабирование и отказоустойчивость. Также рассматривается опыт компании Upmind в создании эффективной архитектуры, которая снизила затраты на инфраструктуру и ускорила процесс разработки.



































































