Download as PDF, PPTX

















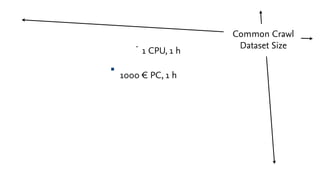

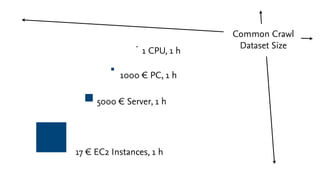





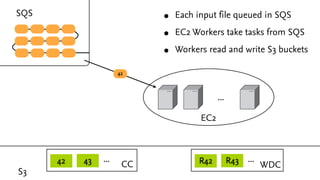

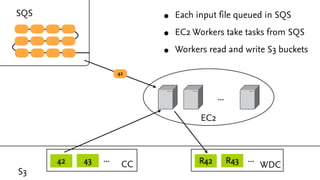


















This document discusses analyzing large amounts of web data on a startup budget using Amazon Web Services (AWS). It describes how the Common Crawl dataset provides HTML dumps of billions of URLs for free that can be accessed from AWS. Running analysis on this large dataset would be prohibitively expensive without AWS due to computing and storage costs. The document outlines how AWS services like EC2 instances, S3, SQS, and SDB can be used together to parallelize processing across many servers and coordinate the analysis in a cost effective manner of around $1700. Preliminary results of analyzing structured data embedded in web pages are presented.






















![JavaOne2016 - Microservices: Terabytes in Microseconds [CON4516]](https://cdn.slidesharecdn.com/ss_thumbnails/javaone2016microservicesfinal-160922163749-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[EN] 7 steps to a successful International PR Campaign](https://cdn.slidesharecdn.com/ss_thumbnails/enoliviabecomewidesalonmiempresa2015-150301125647-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)










































