Download as PDF, PPTX







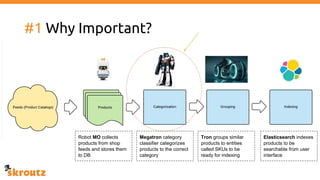








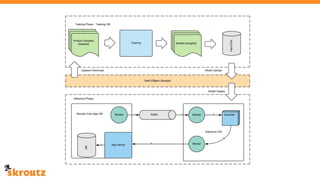
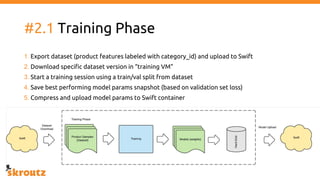
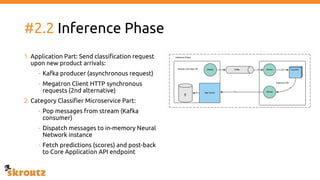








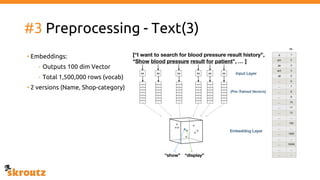

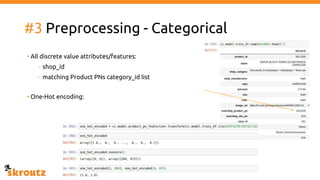




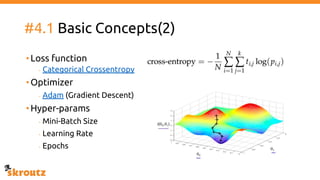

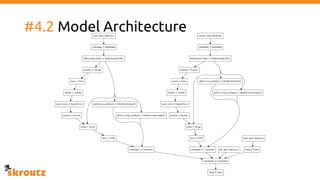

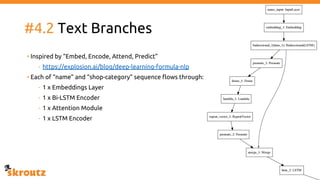
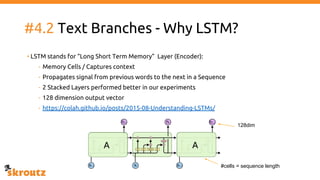

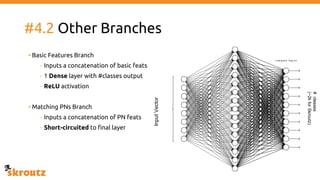
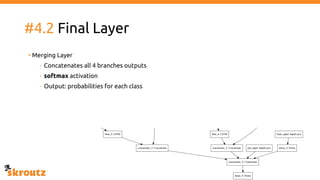
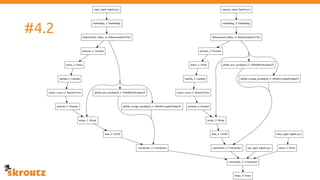




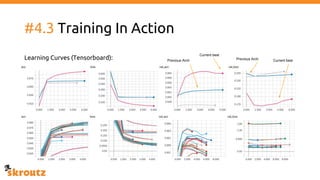


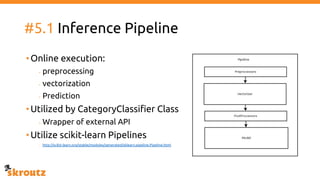




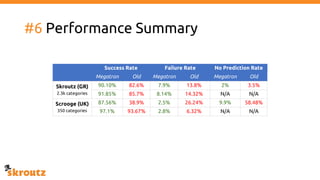
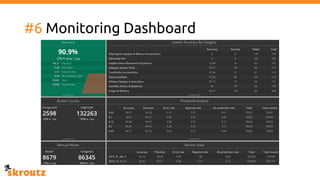



The document describes skroutz.gr, an online marketplace that categorizes over 11 million products from various e-shops using a machine learning-based classification system called 'megatron'. It outlines the architecture, training process, and evaluation of the model, highlighting significant improvements over the previous system, including a reduction in error rates and improved categorization efficiency. Additionally, future enhancements such as leveraging image features and entity recognition are discussed.















































