Download to read offline


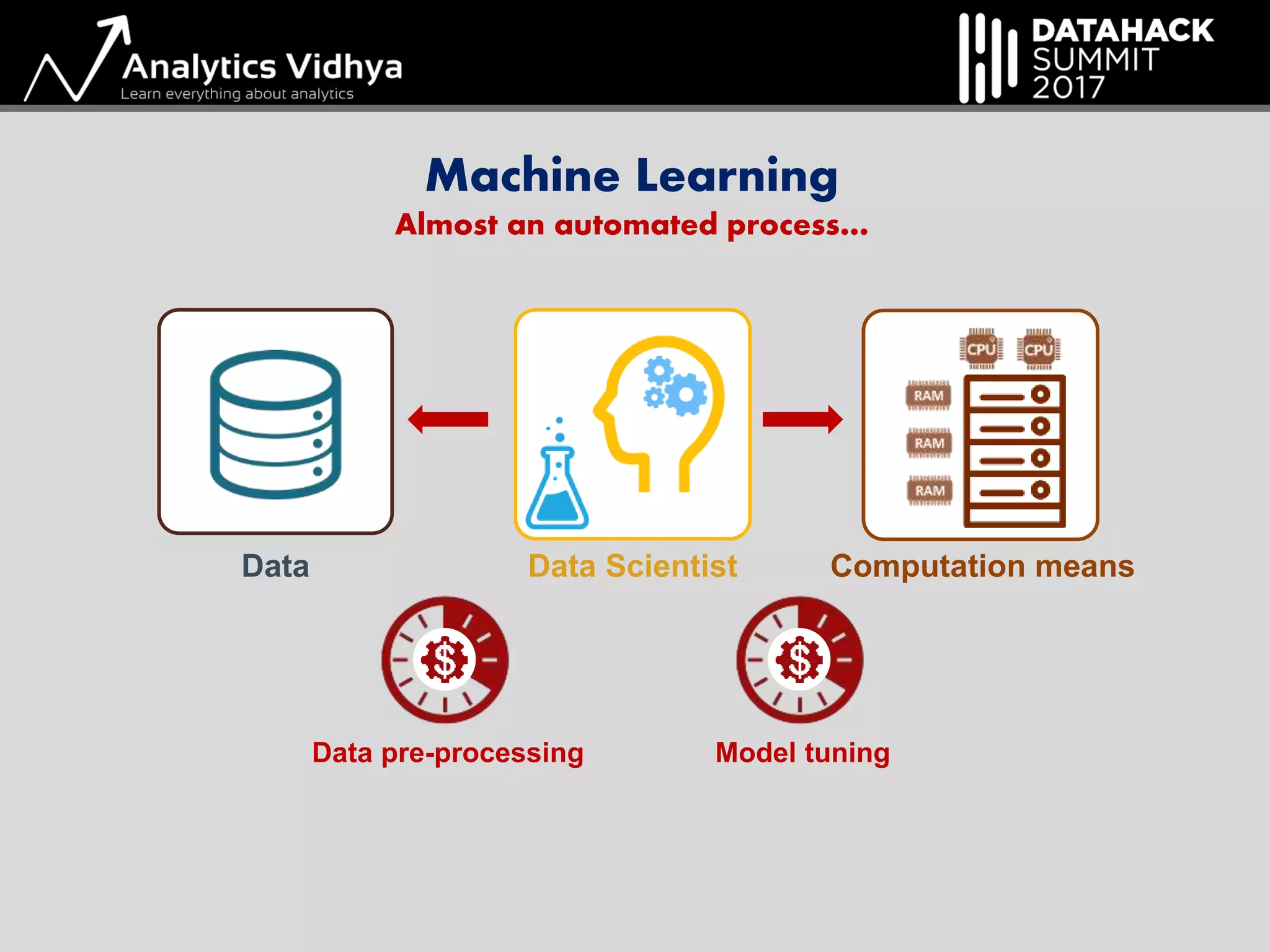
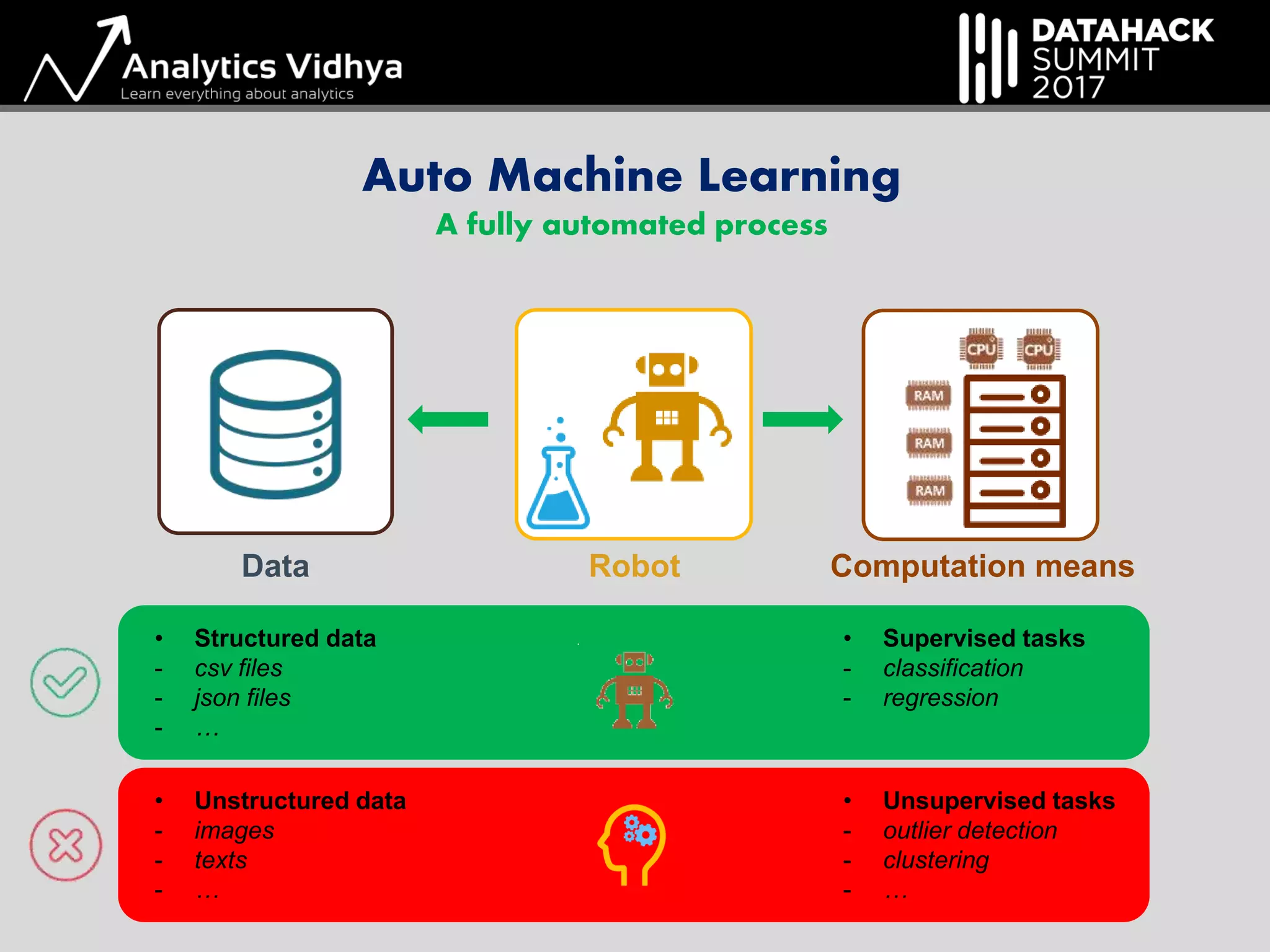


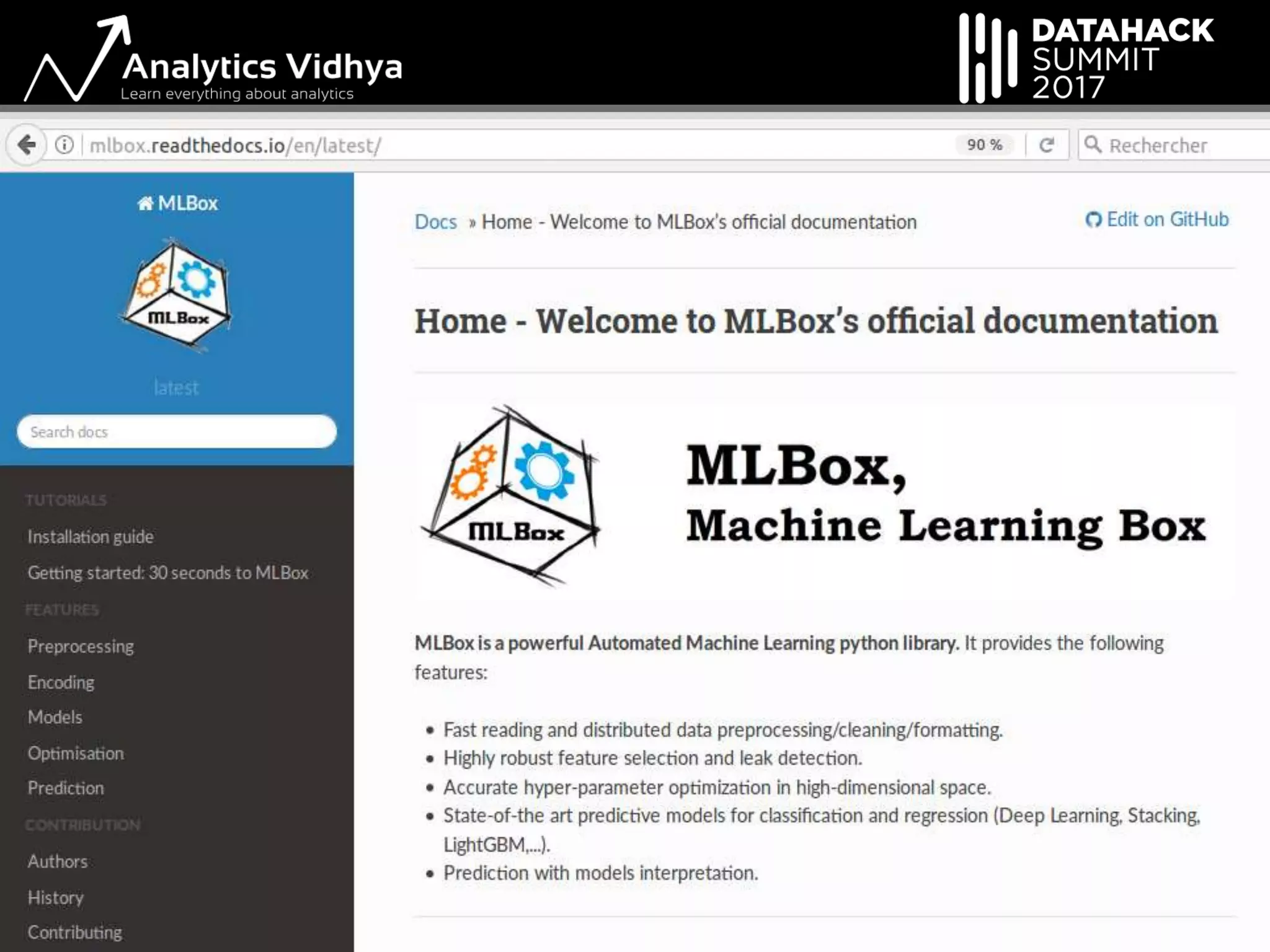
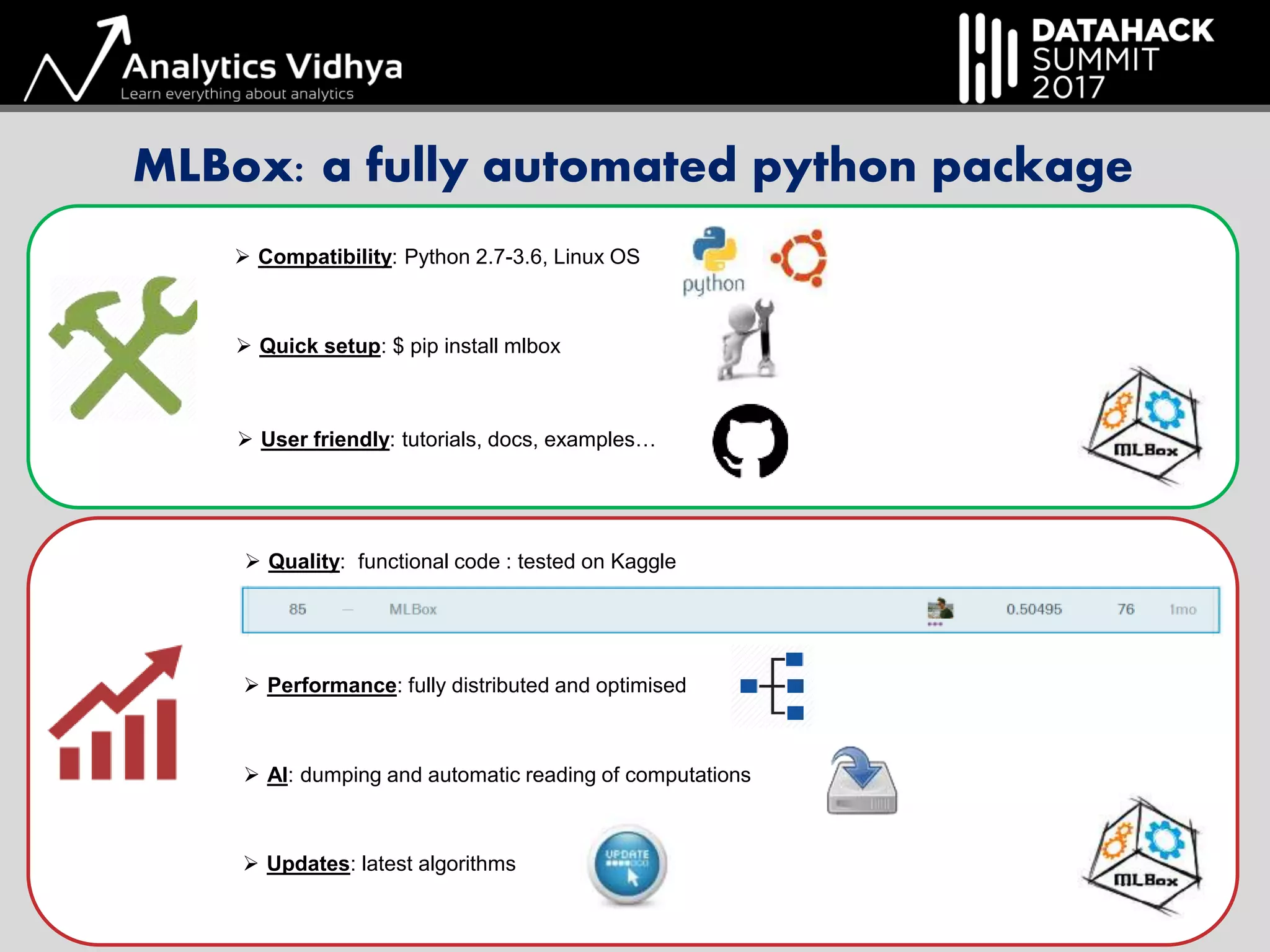



The document outlines a hack session led by Axel de Romblay focusing on Automated Machine Learning (Auto-ML) using the MLBox package. It discusses the steps involved in the Auto-ML process including data pre-processing, model tuning, and the automation of a machine learning pipeline aimed at minimizing human intervention while maintaining high performance. It also highlights MLBox's compatibility, ease of installation, and availability of tutorials for users.



































































