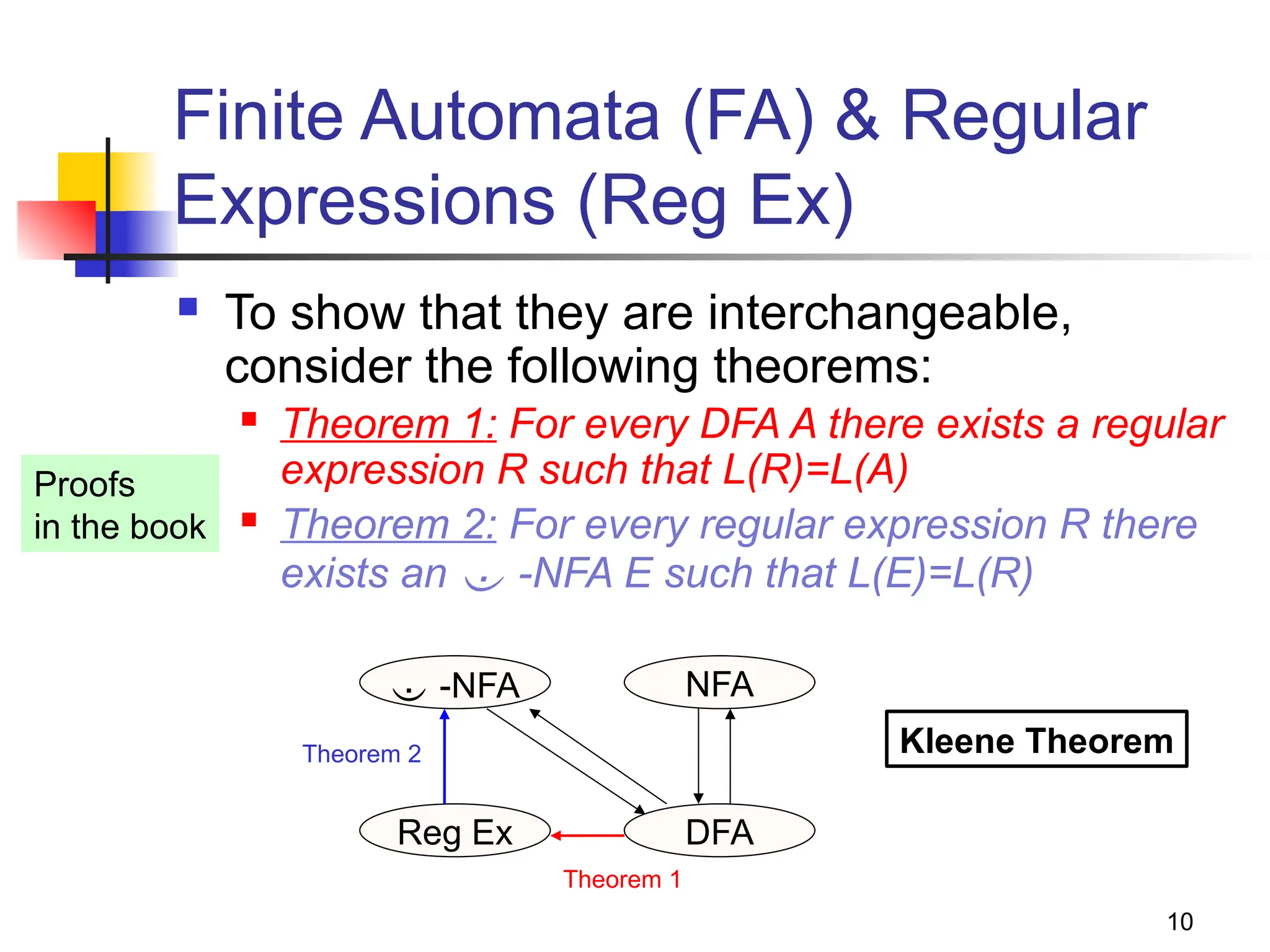
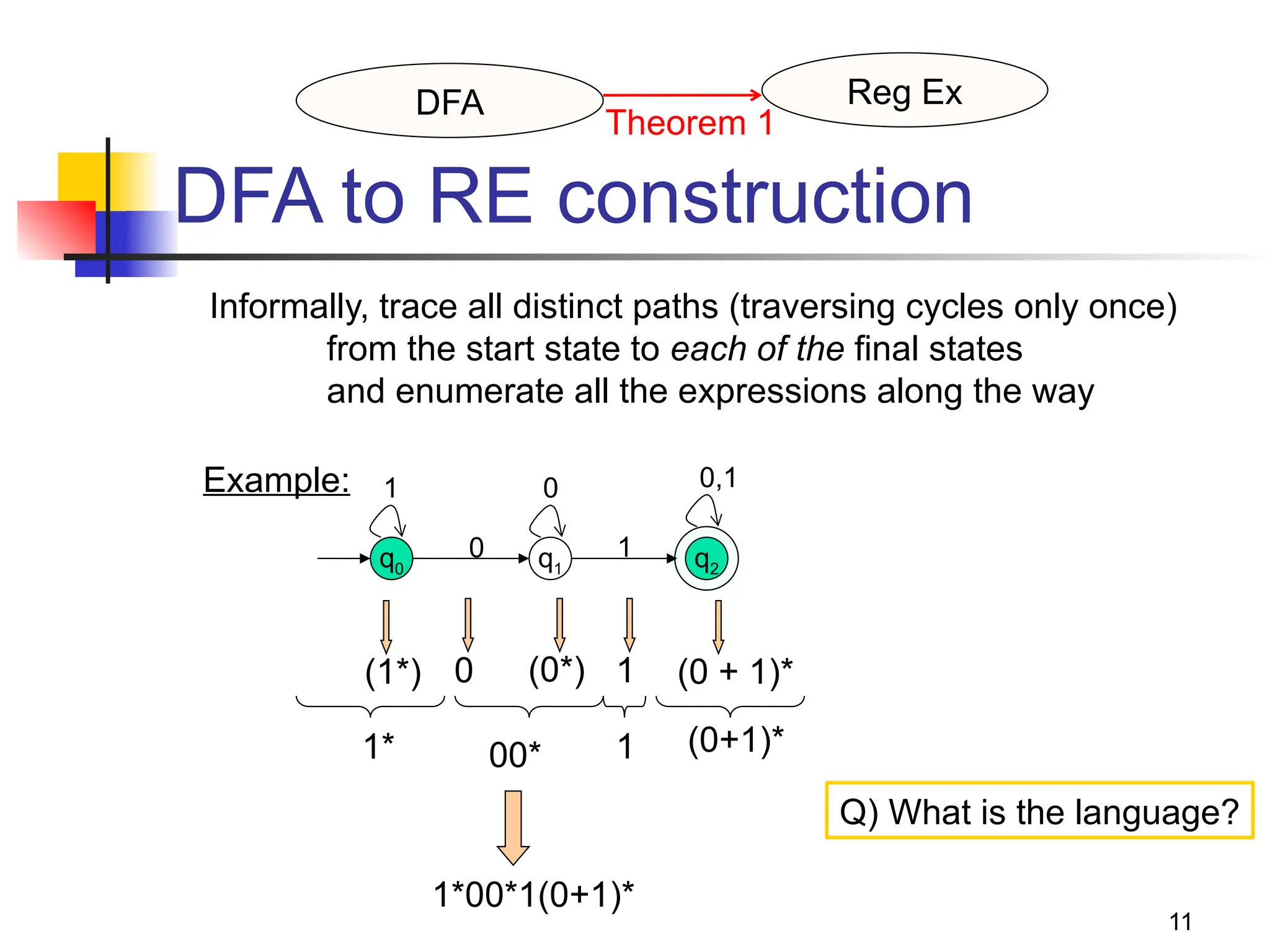
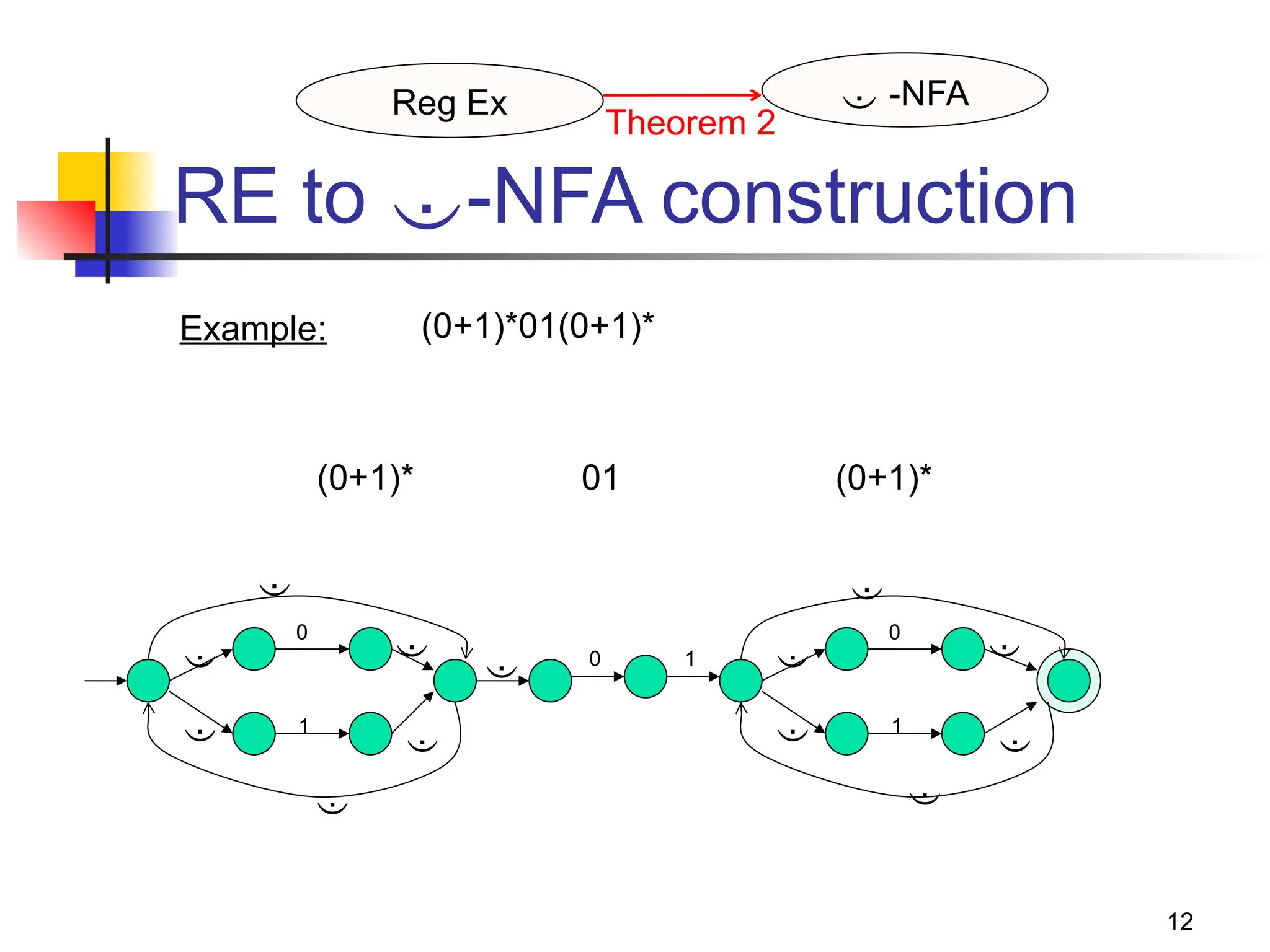
The document discusses regular expressions and their relationship with finite automata, highlighting their declarative syntax for string patterns used in various environments like Unix. It covers operators, Kleene closure, and examples of building regular expressions, as well as the algebraic laws governing them. The document also notes the equivalence between DFAs and regular expressions, including conversion techniques.

![2
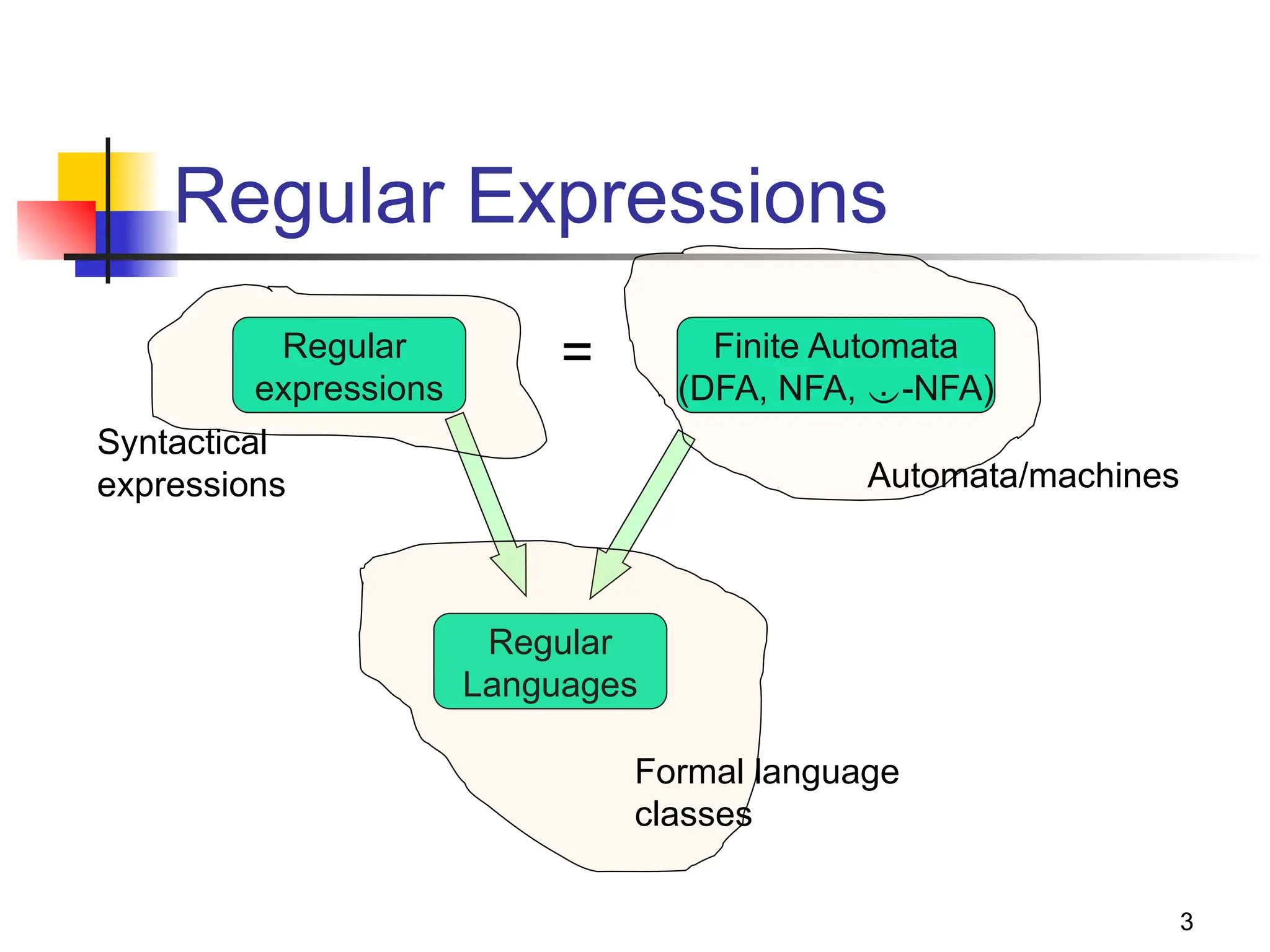
Regular Expressions vs. Finite
Automata
Offers a declarative way to express the pattern of any
string we want to accept
E.g., 01*+ 10*
Automata => more machine-like
< input: string , output: [accept/reject] >
Regular expressions => more program syntax-like
Unix environments heavily use regular expressions
E.g., bash shell, grep, vi & other editors, sed
Perl scripting – good for string processing
Lexical analyzers such as Lex or Flex](https://image.slidesharecdn.com/automata4chapter3-240811031843-3fb8ff06/75/AUTOMATA-AUTOMATA-Automata4Chapter3-pptx-2-2048.jpg)