Download as PDF, PPTX




















![Async Services with Ginkgo
import gevent
from gevent.pywsgi import WSGIServer
from gevent.server import StreamServer
from ginkgo.core import Service
def handle_http(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
print 'new http request!'
return ["hello world"]
def handle_tcp(socket, address):
print 'new tcp connection!'
while True:
socket.send('hellon')
gevent.sleep(1)
app = Service()
app.add_service(StreamServer(('127.0.0.1', 1234),
handle_tcp))
app.add_service(WSGIServer(('127.0.0.1', 8080), handle_http))
app.serve_forever()](https://image.slidesharecdn.com/2012-05-gluecon-async-public-120609173210-phpapp02/75/Asynchronous-Architectures-for-Implementing-Scalable-Cloud-Services-Evan-Cooke-Gluecon-2012-28-2048.jpg)
![Async Services with Ginkgo
import gevent
from gevent.pywsgi import WSGIServer
from gevent.server import StreamServer
Import WSGI/TCP
Servers
from ginkgo.core import Service
def handle_http(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
print 'new http request!'
return ["hello world"]
def handle_tcp(socket, address):
print 'new tcp connection!'
while True:
socket.send('hellon')
gevent.sleep(1)
app = Service()
app.add_service(StreamServer(('127.0.0.1', 1234),
handle_tcp))
app.add_service(WSGIServer(('127.0.0.1', 8080), handle_http))
app.serve_forever()](https://image.slidesharecdn.com/2012-05-gluecon-async-public-120609173210-phpapp02/75/Asynchronous-Architectures-for-Implementing-Scalable-Cloud-Services-Evan-Cooke-Gluecon-2012-29-2048.jpg)
![Async Services with Ginkgo
import gevent
from gevent.pywsgi import WSGIServer
from gevent.server import StreamServer
from ginkgo.core import Service
HTTP Handler
def handle_http(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
print 'new http request!'
return ["hello world"]
def handle_tcp(socket, address):
print 'new tcp connection!'
while True:
socket.send('hellon')
gevent.sleep(1)
app = Service()
app.add_service(StreamServer(('127.0.0.1', 1234),
handle_tcp))
app.add_service(WSGIServer(('127.0.0.1', 8080), handle_http))
app.serve_forever()](https://image.slidesharecdn.com/2012-05-gluecon-async-public-120609173210-phpapp02/75/Asynchronous-Architectures-for-Implementing-Scalable-Cloud-Services-Evan-Cooke-Gluecon-2012-30-2048.jpg)
![Async Services with Ginkgo
import gevent
from gevent.pywsgi import WSGIServer
from gevent.server import StreamServer
from ginkgo.core import Service
def handle_http(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
print 'new http request!'
return ["hello world"]
def handle_tcp(socket, address): TCP Handler
print 'new tcp connection!'
while True:
socket.send('hellon')
gevent.sleep(1)
app = Service()
app.add_service(StreamServer(('127.0.0.1', 1234),
handle_tcp))
app.add_service(WSGIServer(('127.0.0.1', 8080), handle_http))
app.serve_forever()](https://image.slidesharecdn.com/2012-05-gluecon-async-public-120609173210-phpapp02/75/Asynchronous-Architectures-for-Implementing-Scalable-Cloud-Services-Evan-Cooke-Gluecon-2012-31-2048.jpg)
![Async Services with Ginkgo
import gevent
from gevent.pywsgi import WSGIServer
from gevent.server import StreamServer
from ginkgo.core import Service
def handle_http(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
print 'new http request!'
return ["hello world"]
def handle_tcp(socket, address):
print 'new tcp connection!'
while True:
socket.send('hellon') Service
gevent.sleep(1)
Composition
app = Service()
app.add_service(StreamServer(('127.0.0.1', 1234),
handle_tcp))
app.add_service(WSGIServer(('127.0.0.1', 8080), handle_http))
app.serve_forever()](https://image.slidesharecdn.com/2012-05-gluecon-async-public-120609173210-phpapp02/75/Asynchronous-Architectures-for-Implementing-Scalable-Cloud-Services-Evan-Cooke-Gluecon-2012-32-2048.jpg)
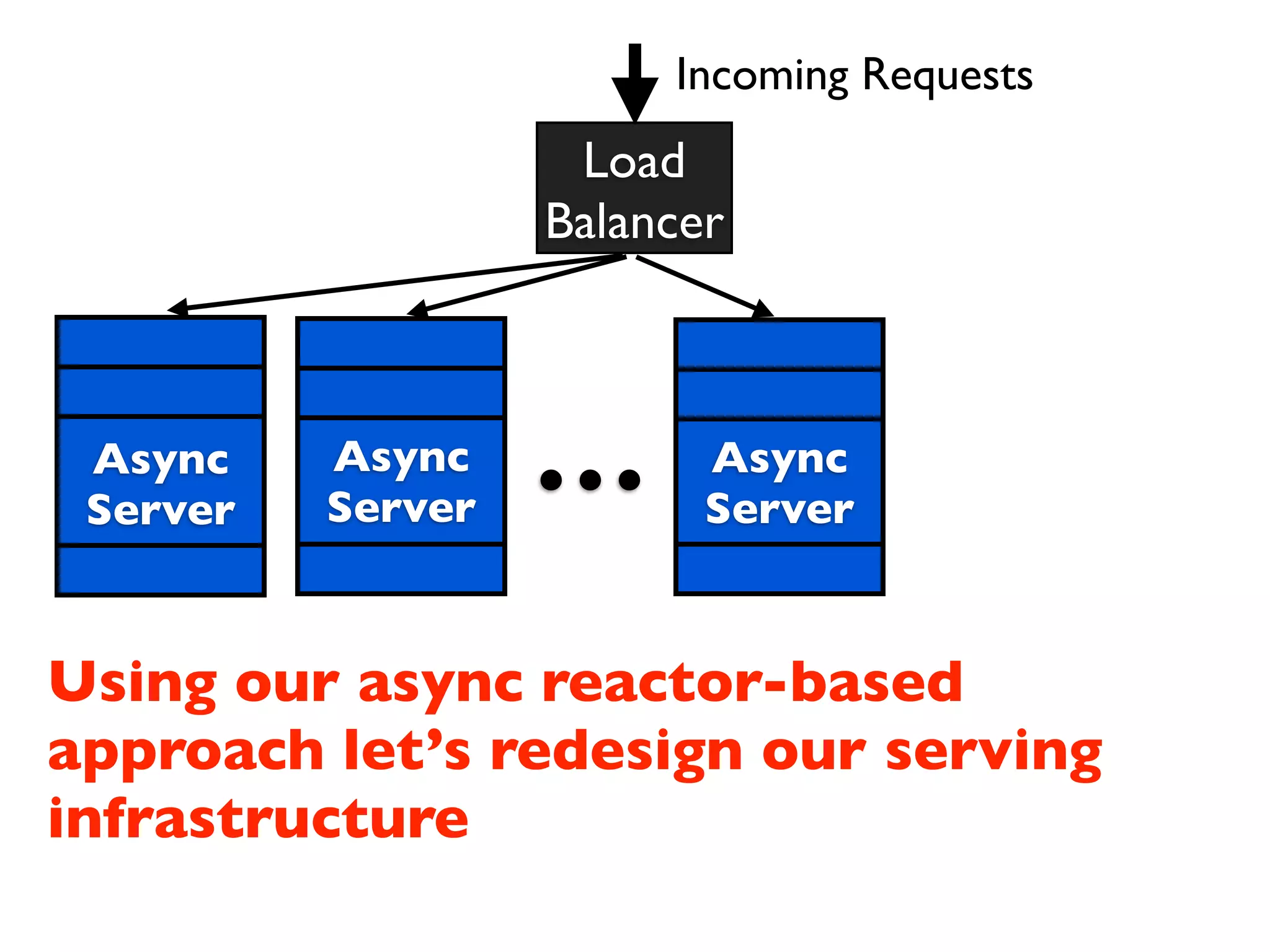
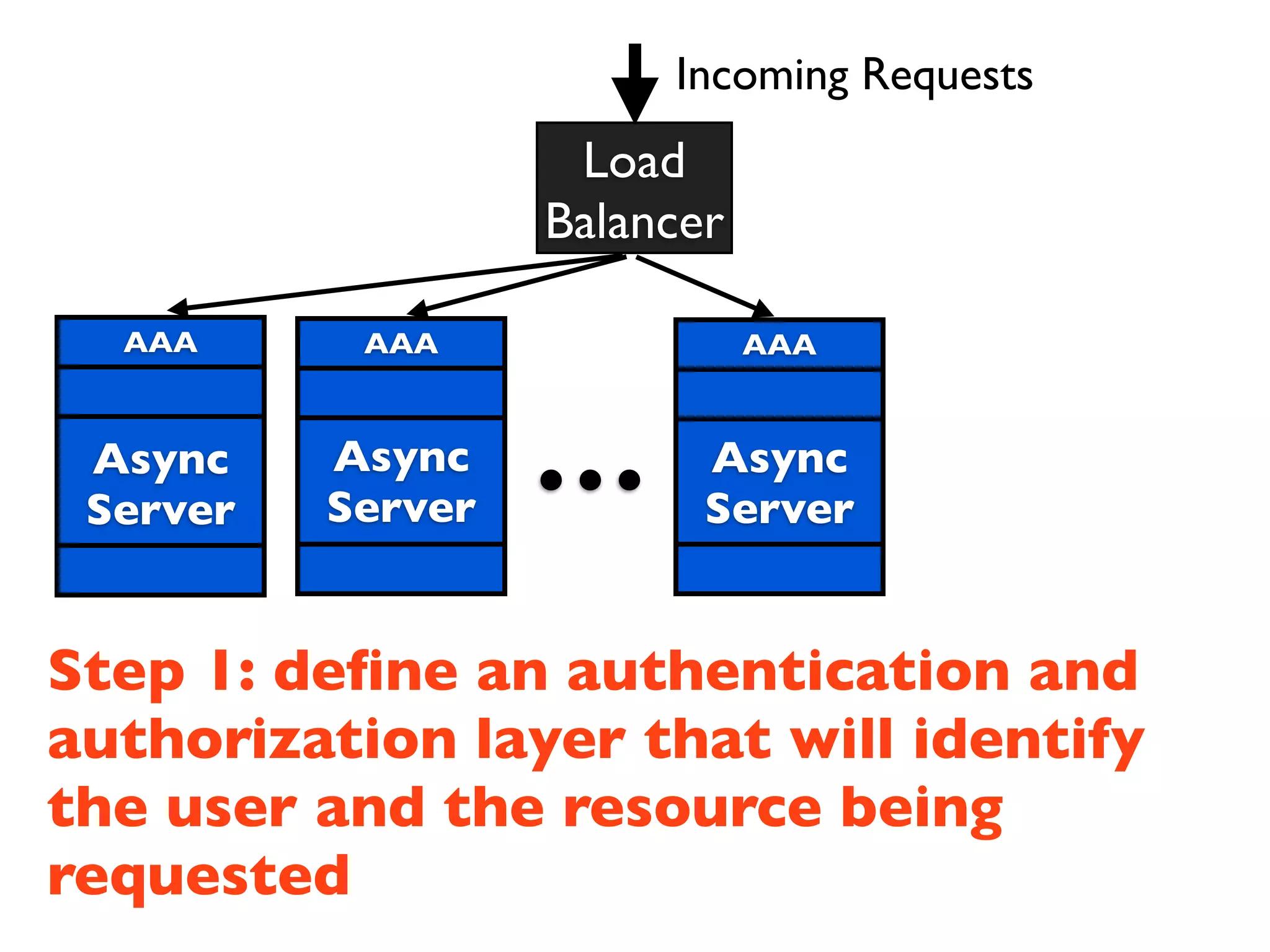
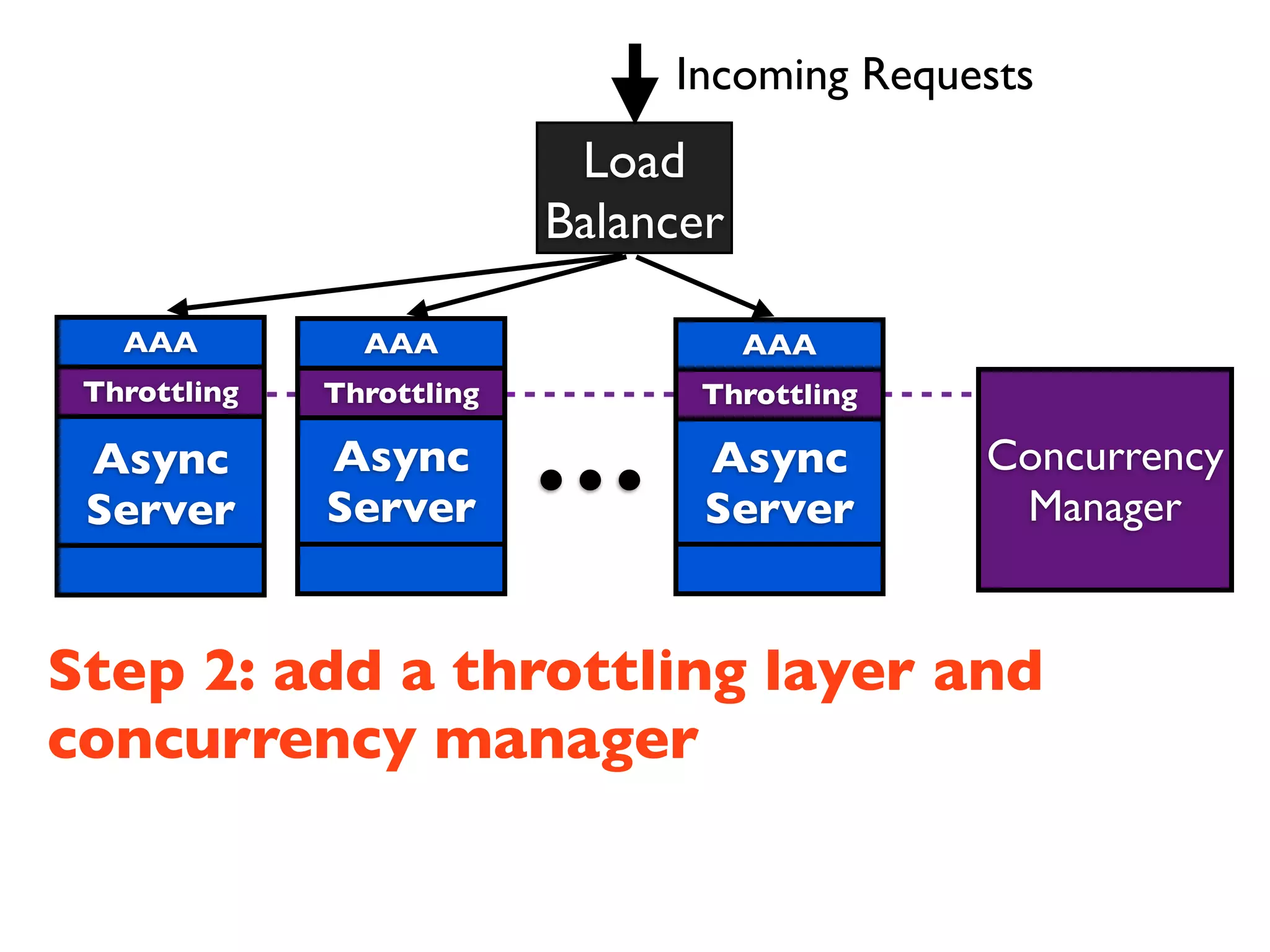


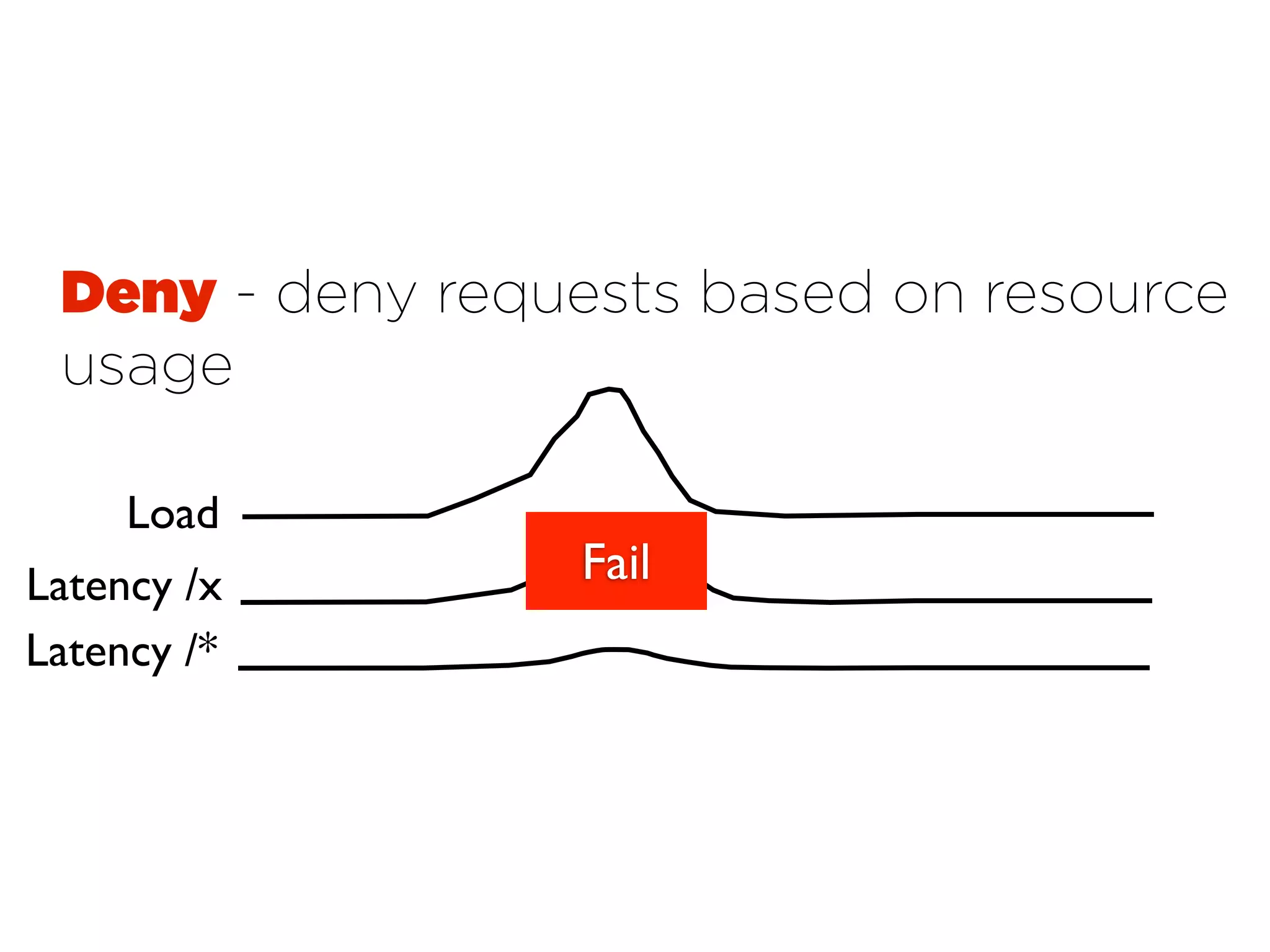
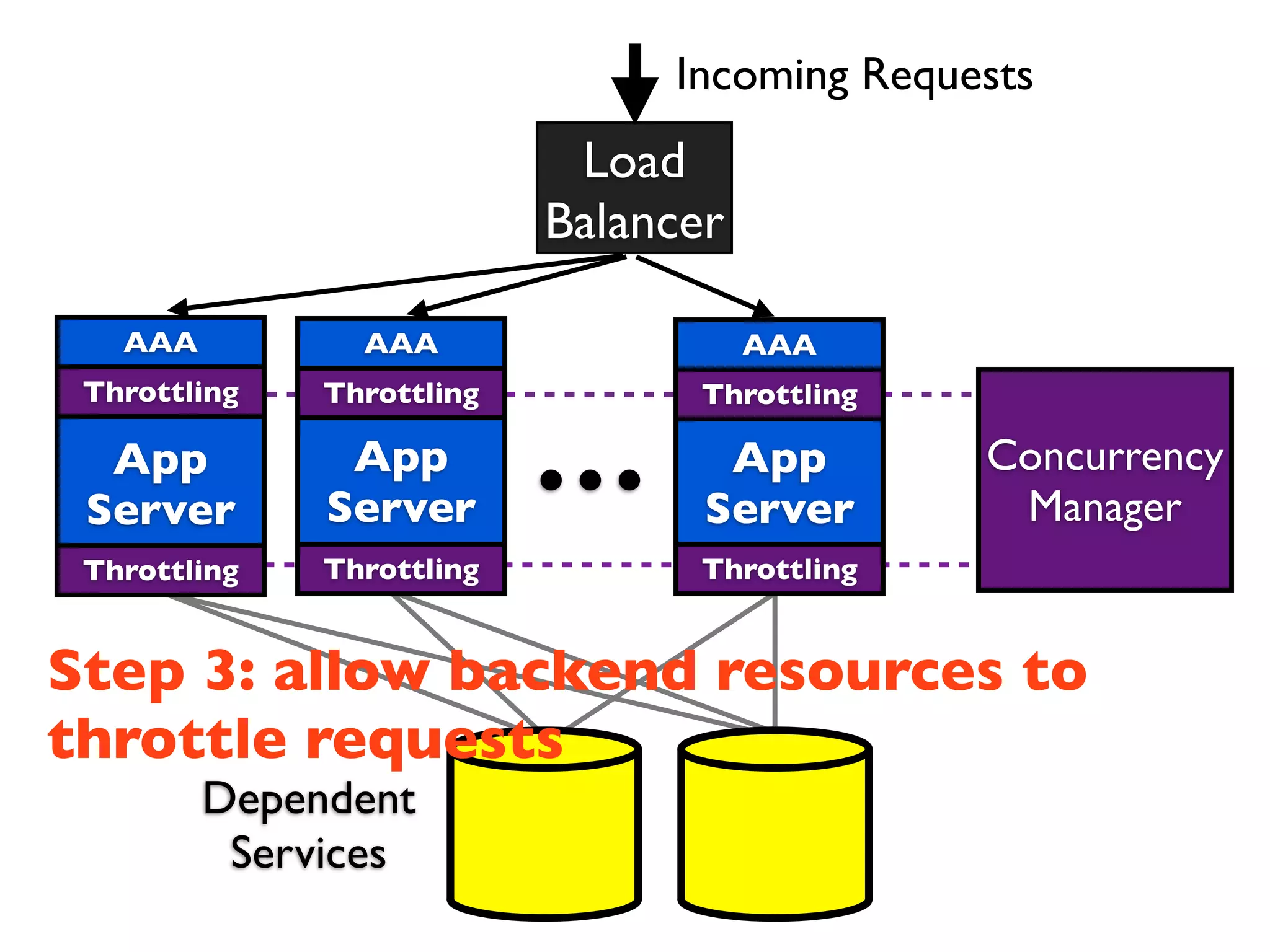
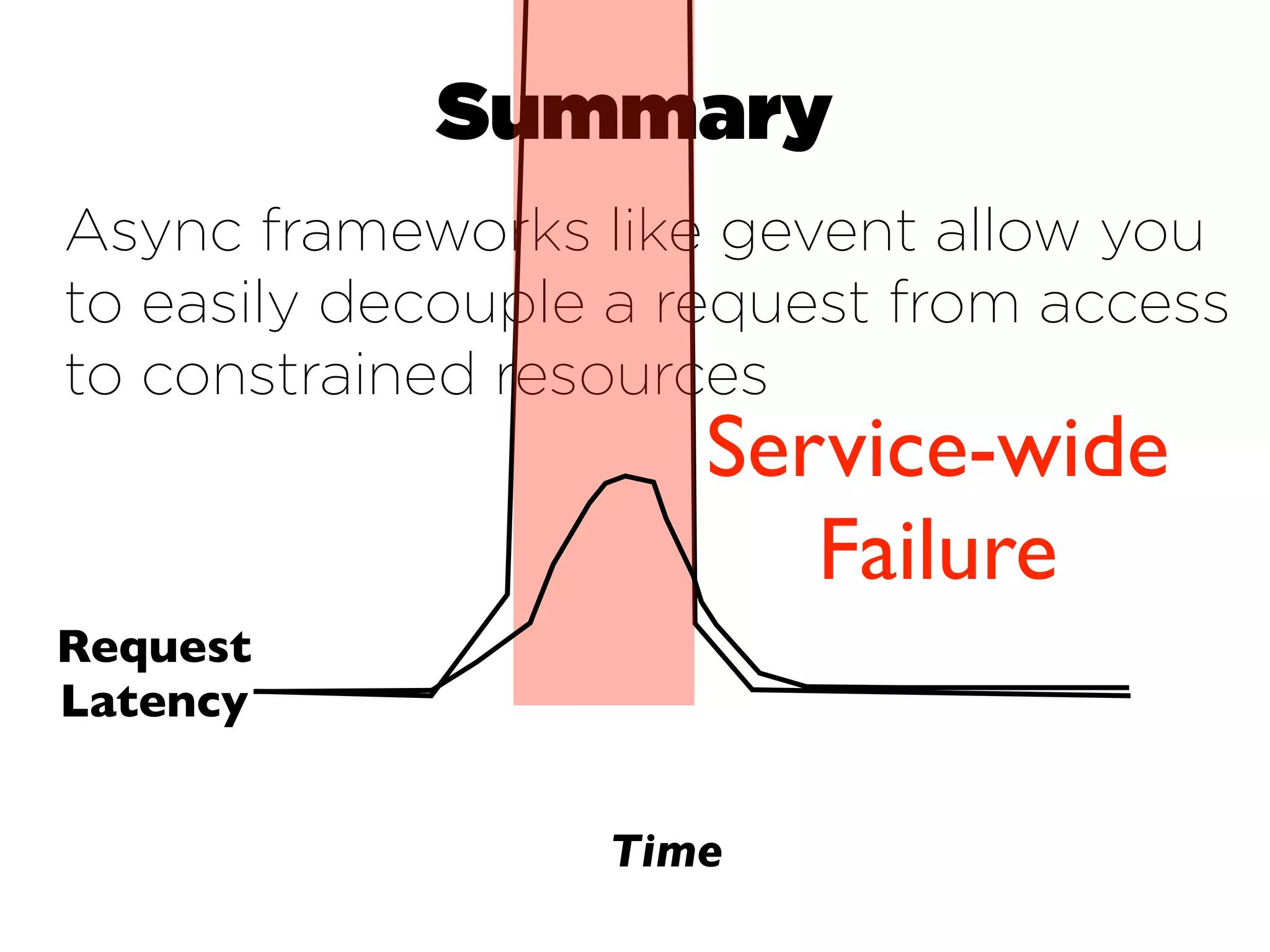




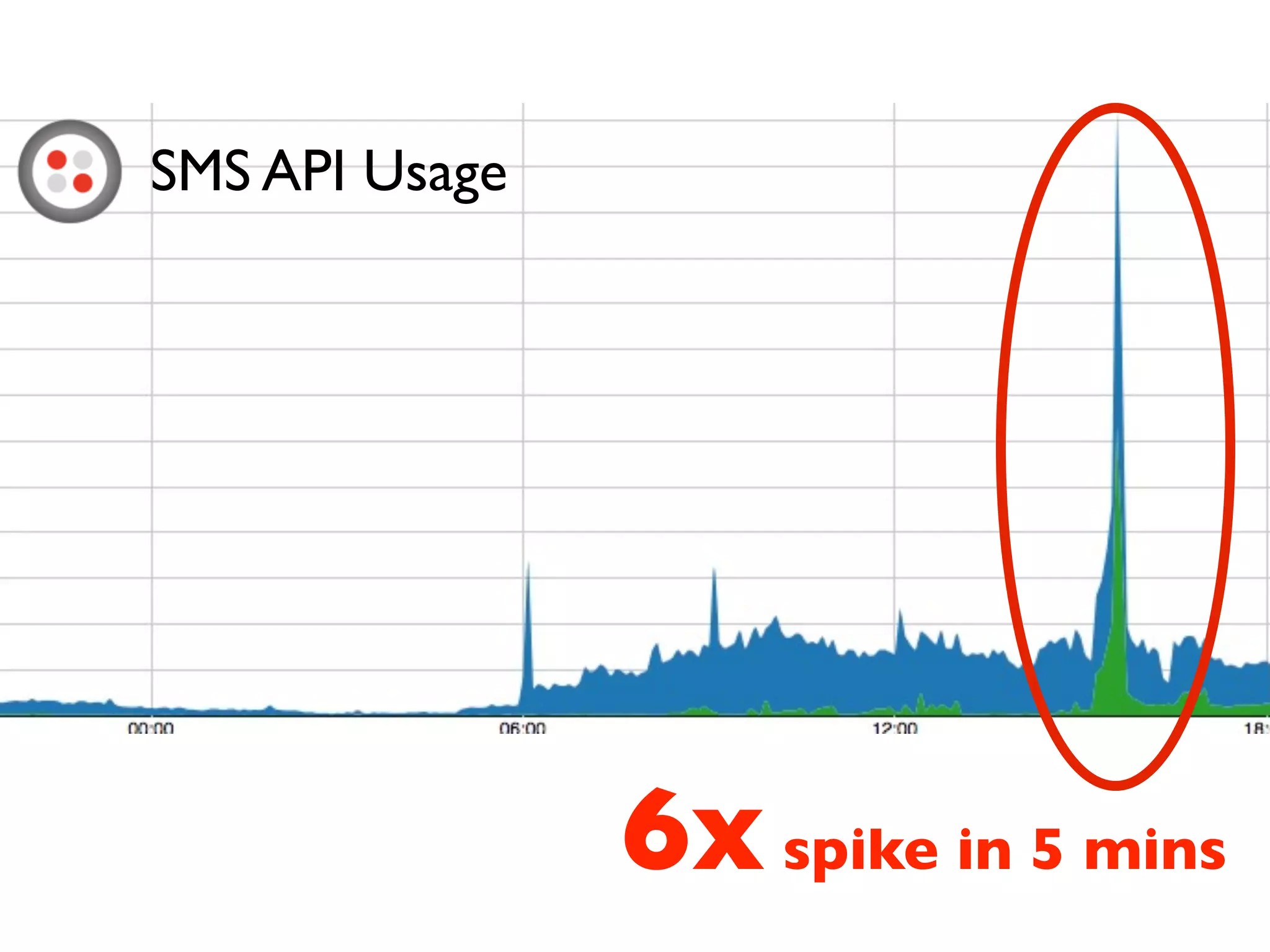
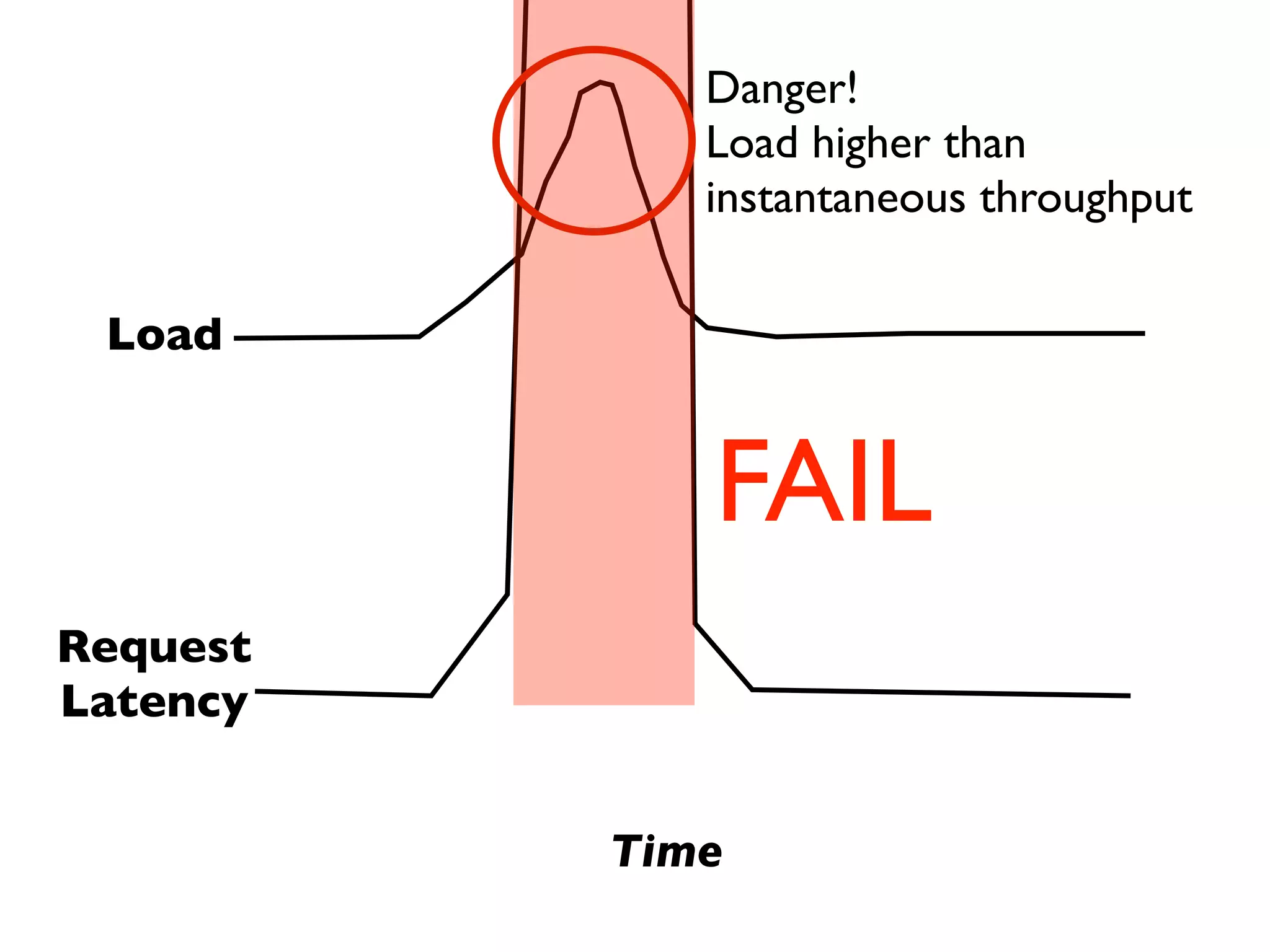
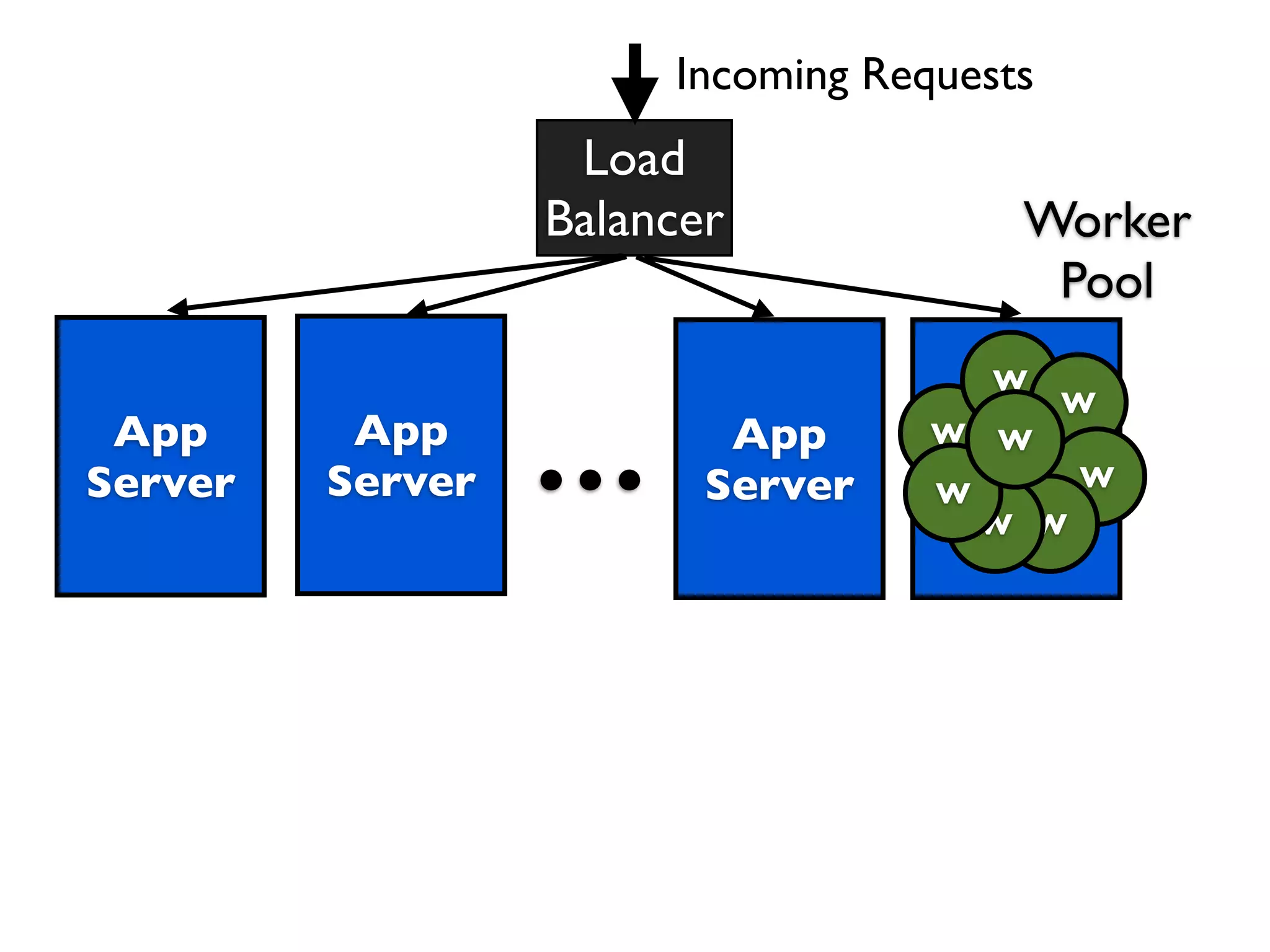
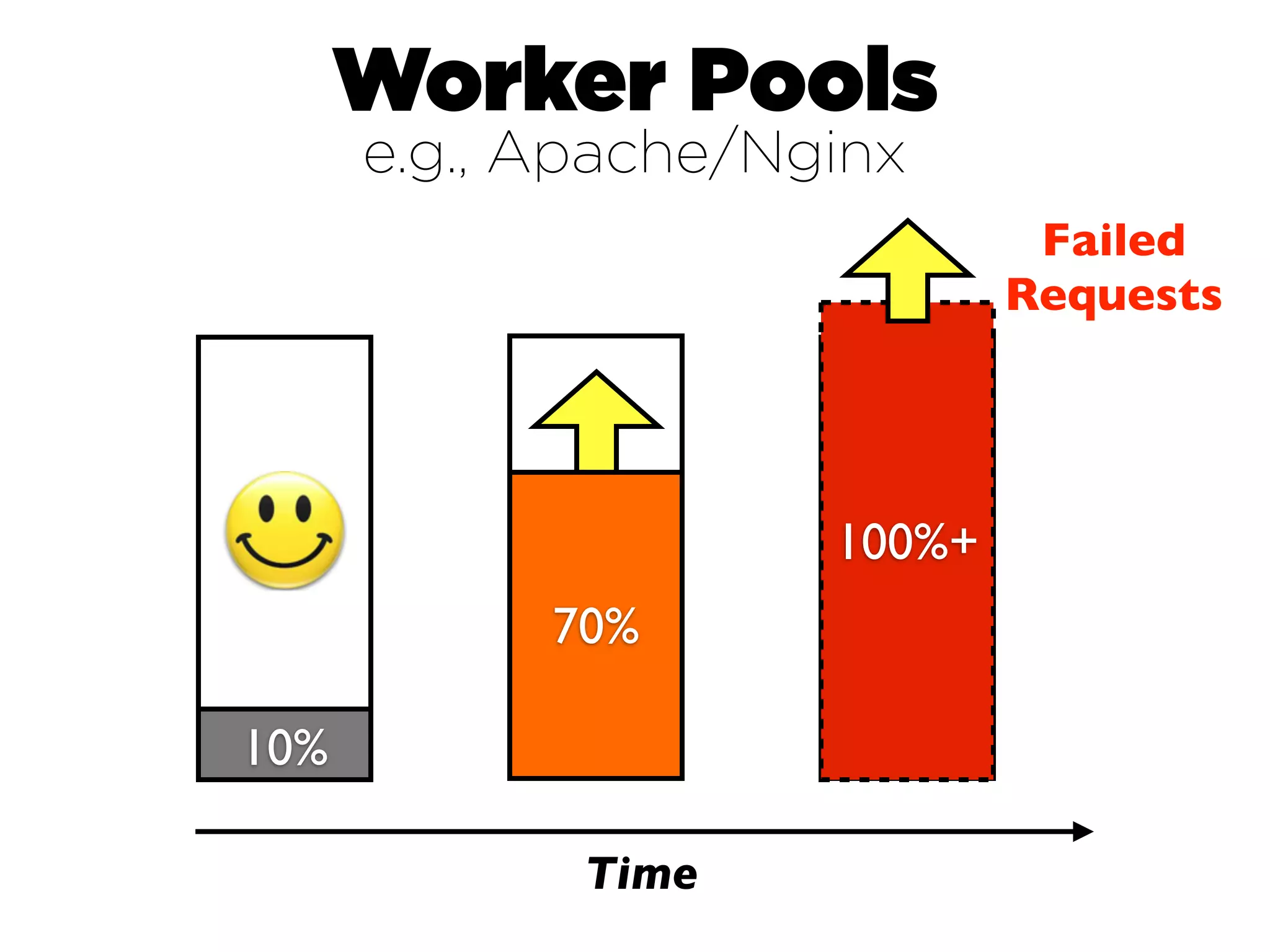
This document discusses designing cloud services to gracefully degrade under heavy loads. It proposes using asynchronous architectures and event-driven programming to implement scalable cloud services. This allows requests to be serviced concurrently without blocking workers. Frameworks like gevent make asynchronous programming easy using greenlets. The document presents an architecture that uses load balancers, authentication, throttling, and concurrency management layers to queue requests when backend resources are overloaded. This allows requests to be delayed instead of failed to avoid service failures.
![[AWS Dev Day] 이머징 테크 | Libra 소스코드분석 및 AWS에서 블록체인 기반 지불 시스템 최적화 방법 - 박혜영 AWS 솔...](https://cdn.slidesharecdn.com/ss_thumbnails/code-190930055302-thumbnail.jpg?width=640&height=640&fit=bounds)













































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)





