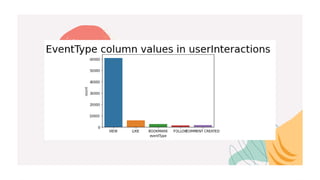
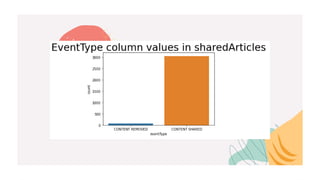
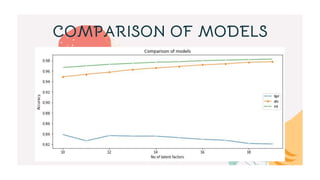
This document describes a recommender system project done by Lakshya Karwa and Tarun Kumar I.S. guided by Dr. J. Shana. It used user interaction data from an internal communications platform from 2016-2017 to build and compare three recommender models: Alternating Least Squares (ALS), Bayesian Personalized Ranking (BPR), and Logistic Matrix Factorization (LMF). ALS had the highest accuracy at 98.1% while BPR and LMF also performed well at 82.6% and 97.89% respectively. ALS was the fastest to train while BPR was the slowest. The models provided personalized article recommendations to users based on their interactions.