This document discusses Apache Kylin, an OLAP engine for big data. It provides 3 key points:
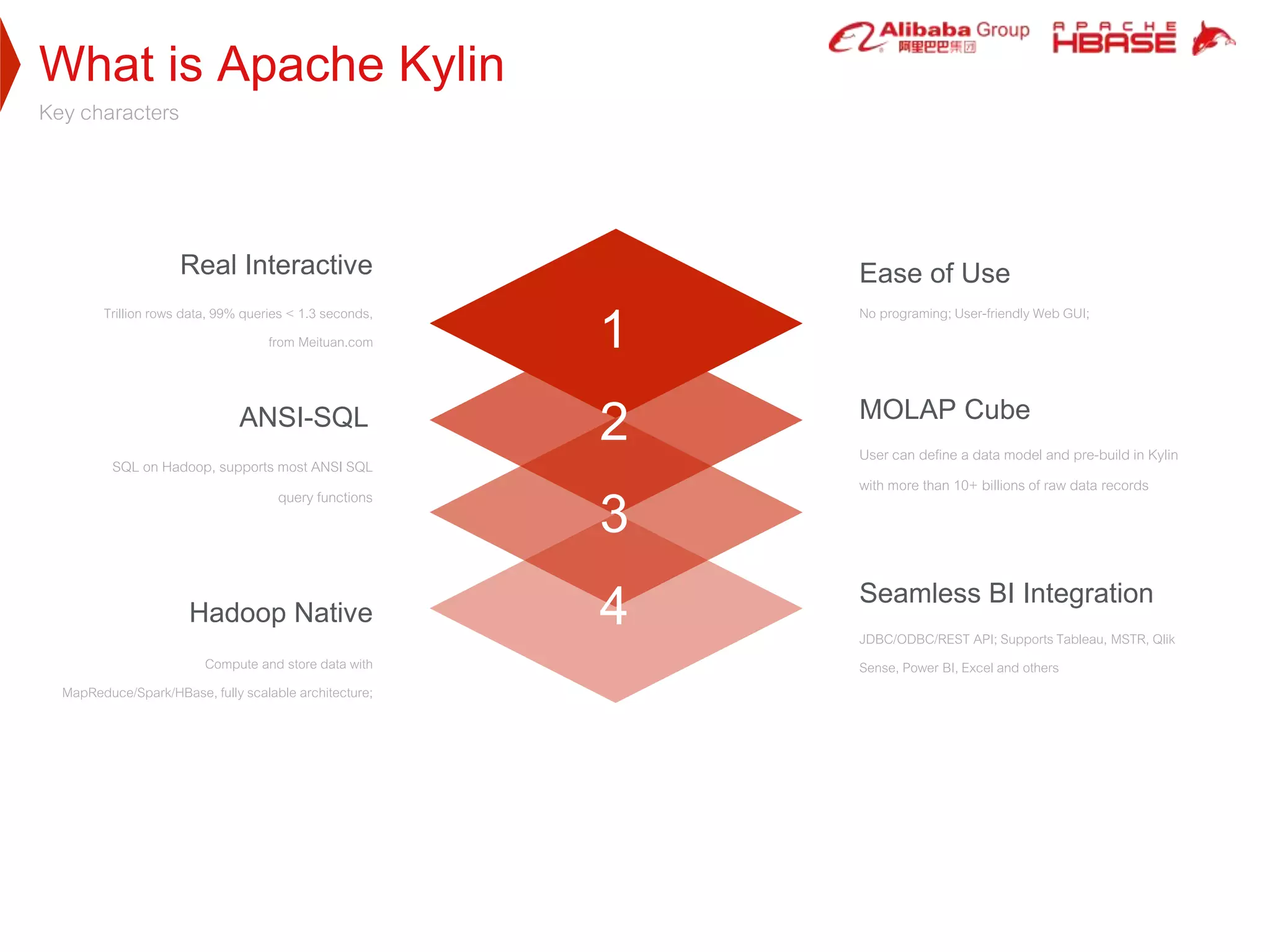
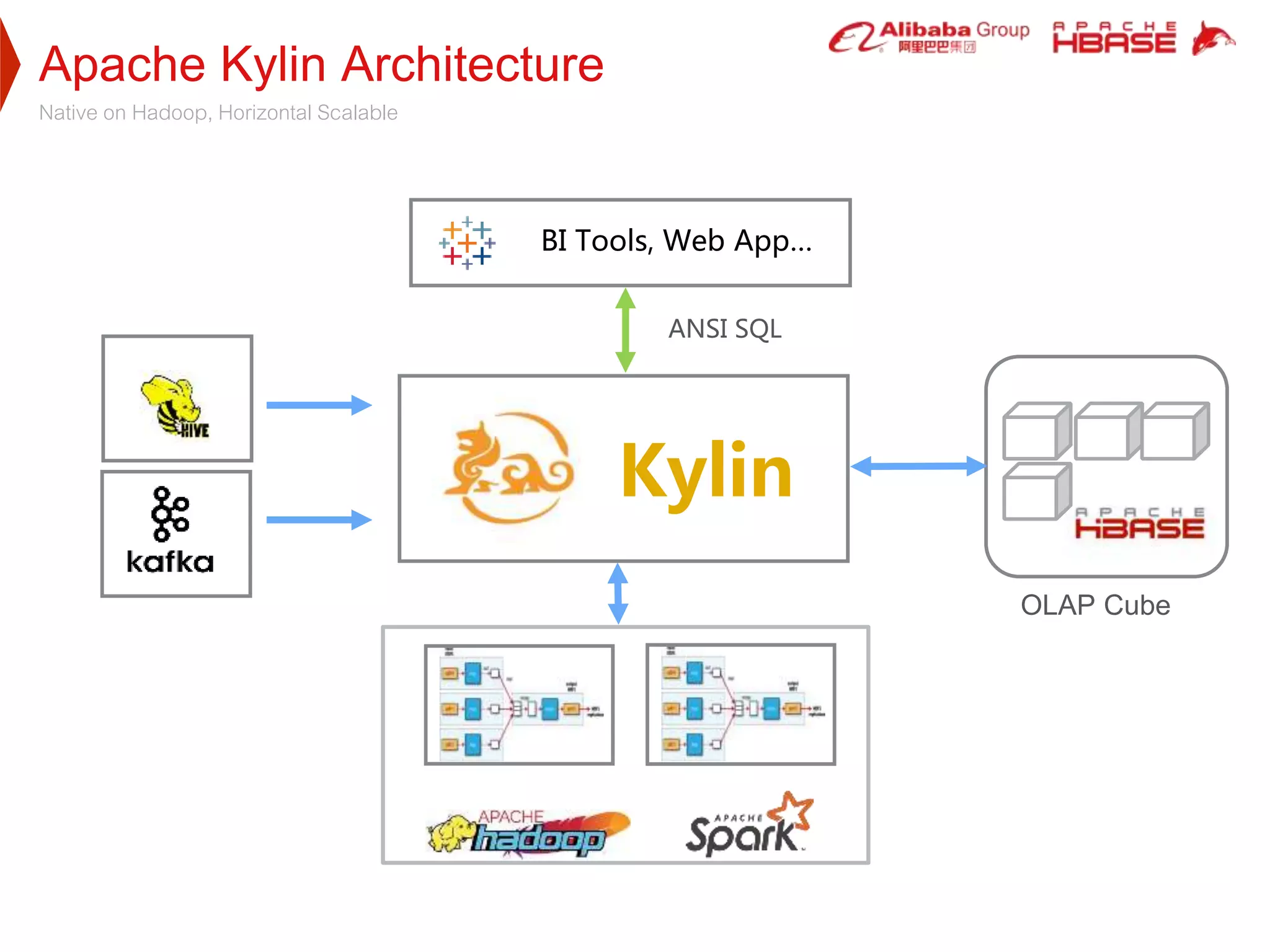
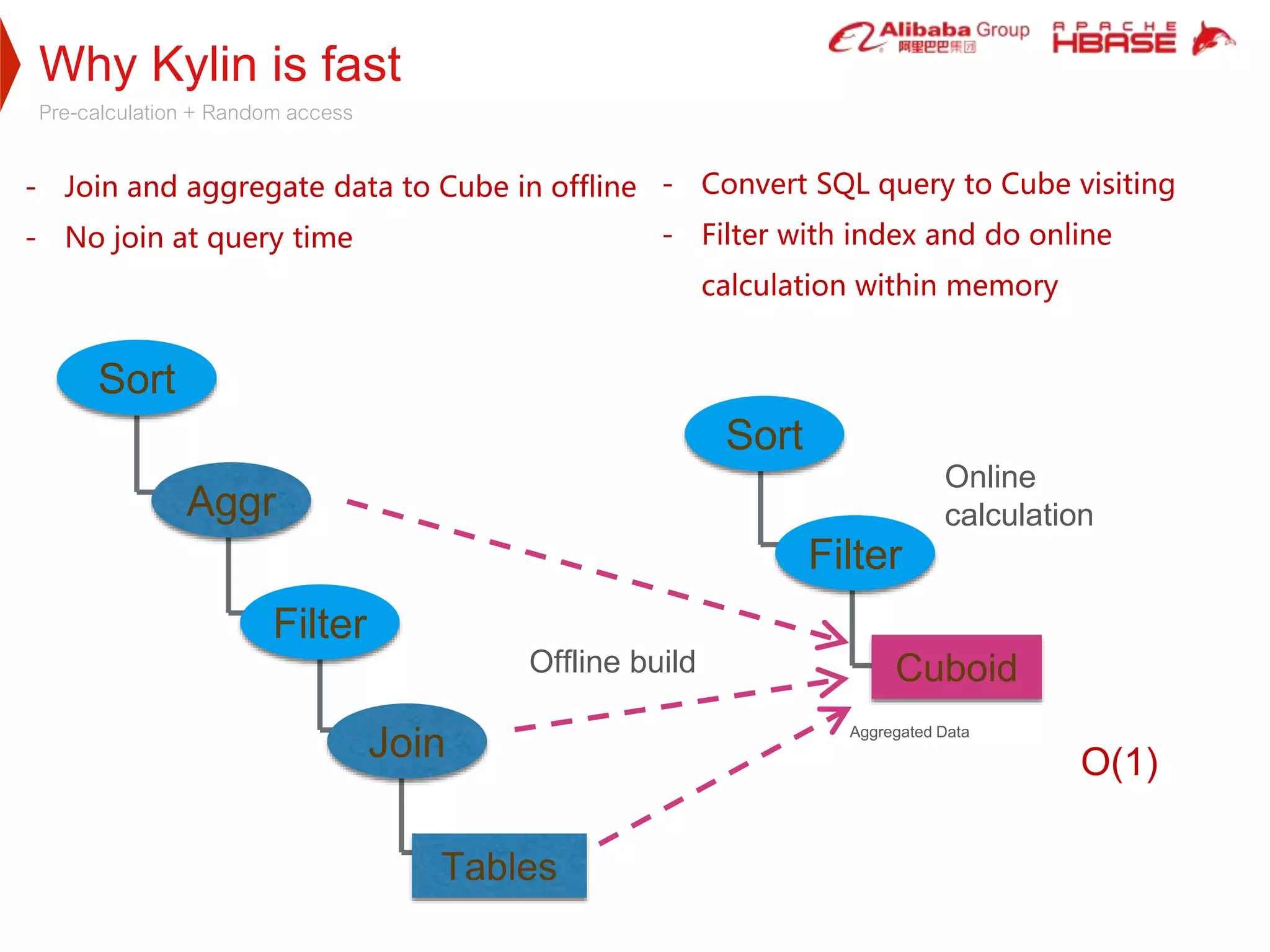
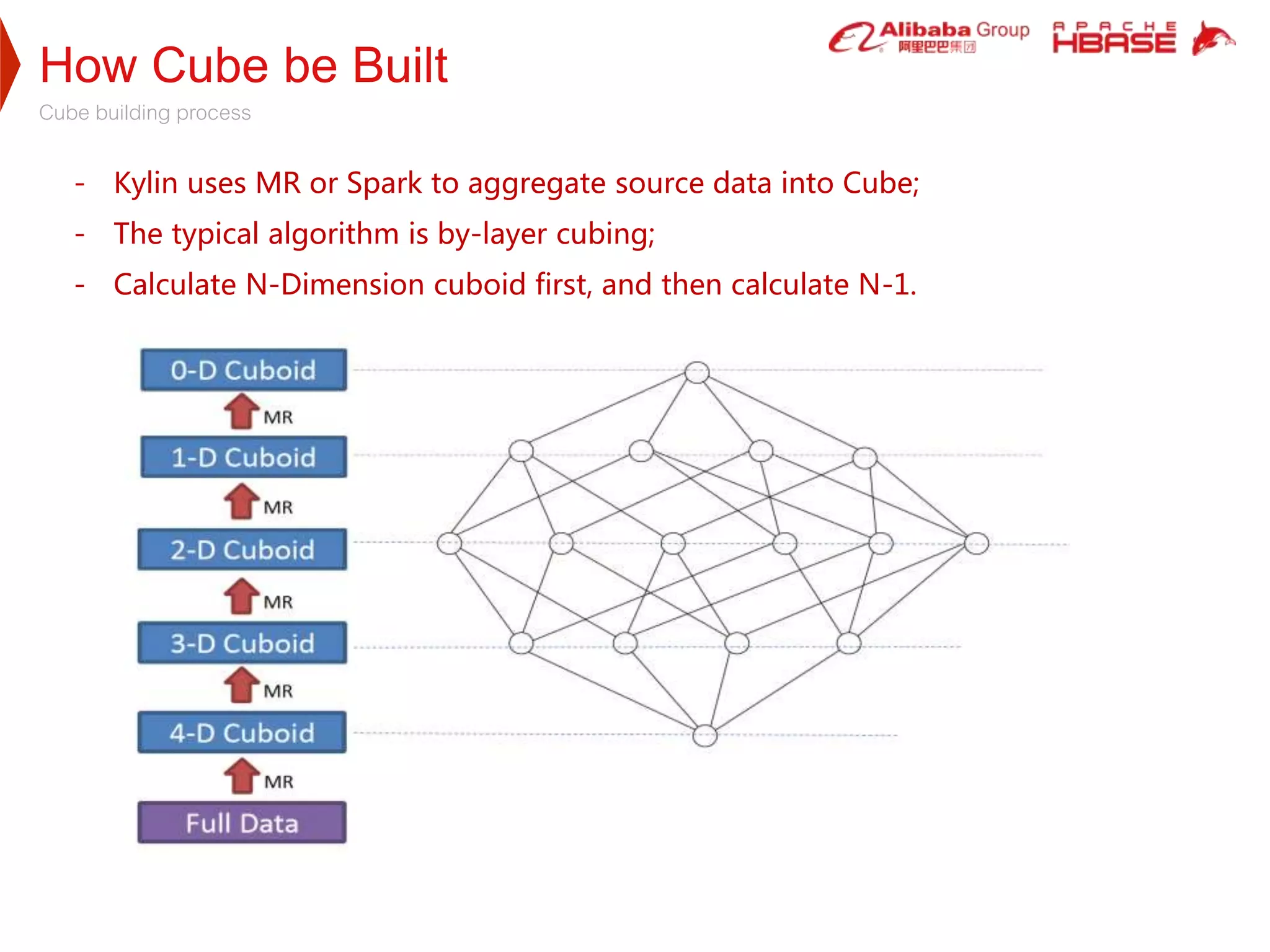
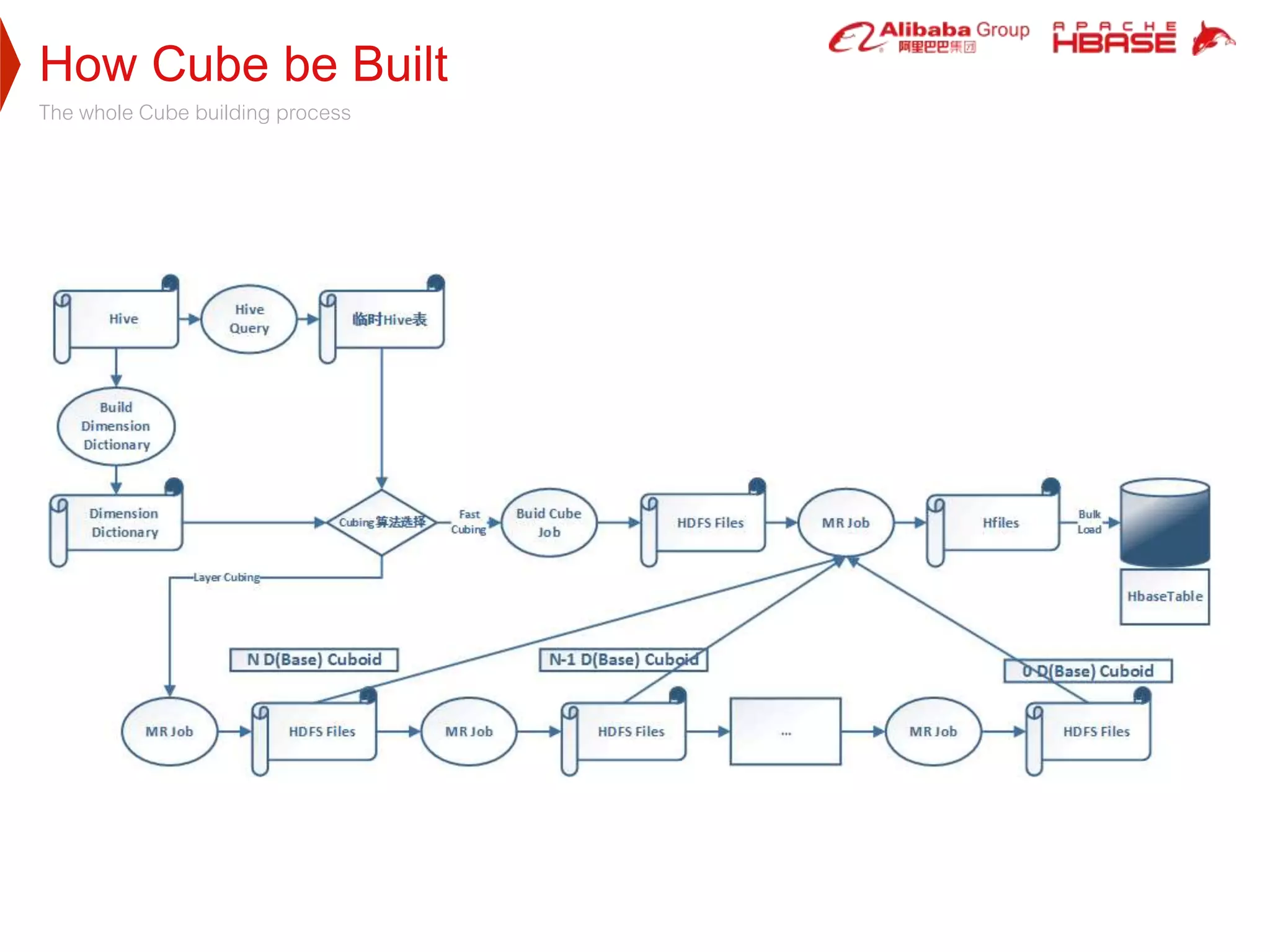
1. Apache Kylin is designed to provide fast, interactive queries on large datasets stored in Hadoop. It uses pre-calculated cube structures stored in HBase to enable sub-second query performance on trillion row datasets.
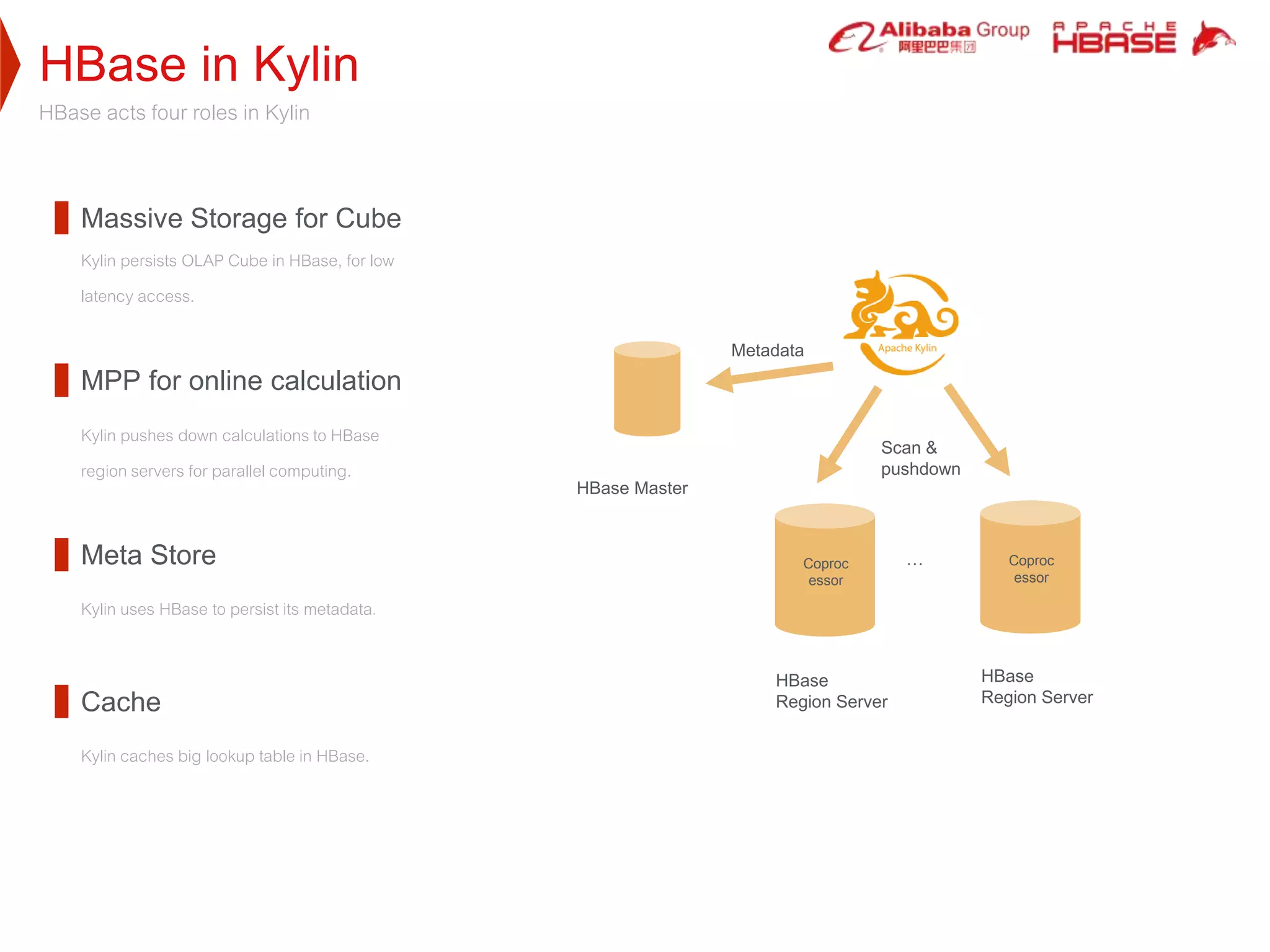
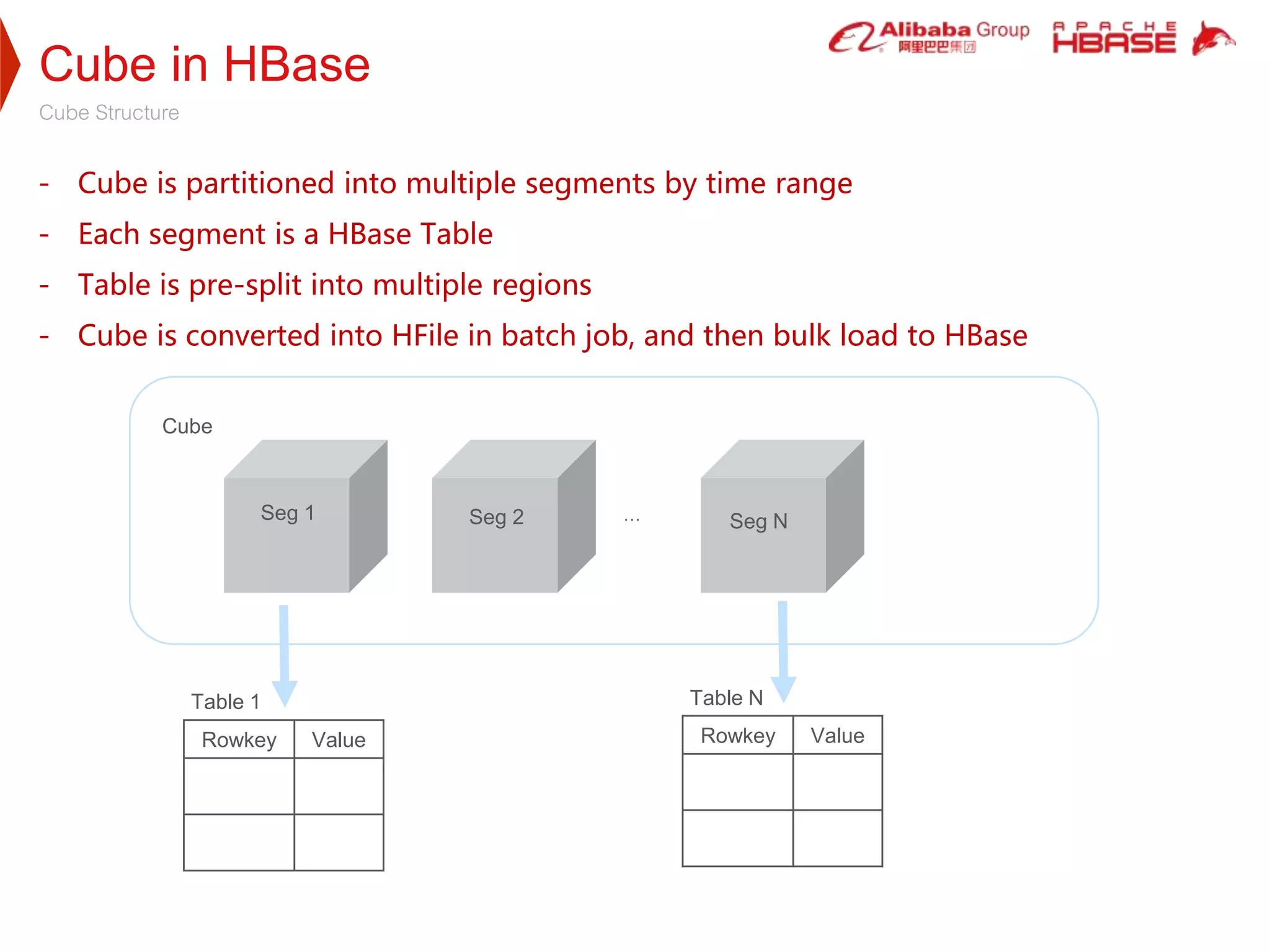
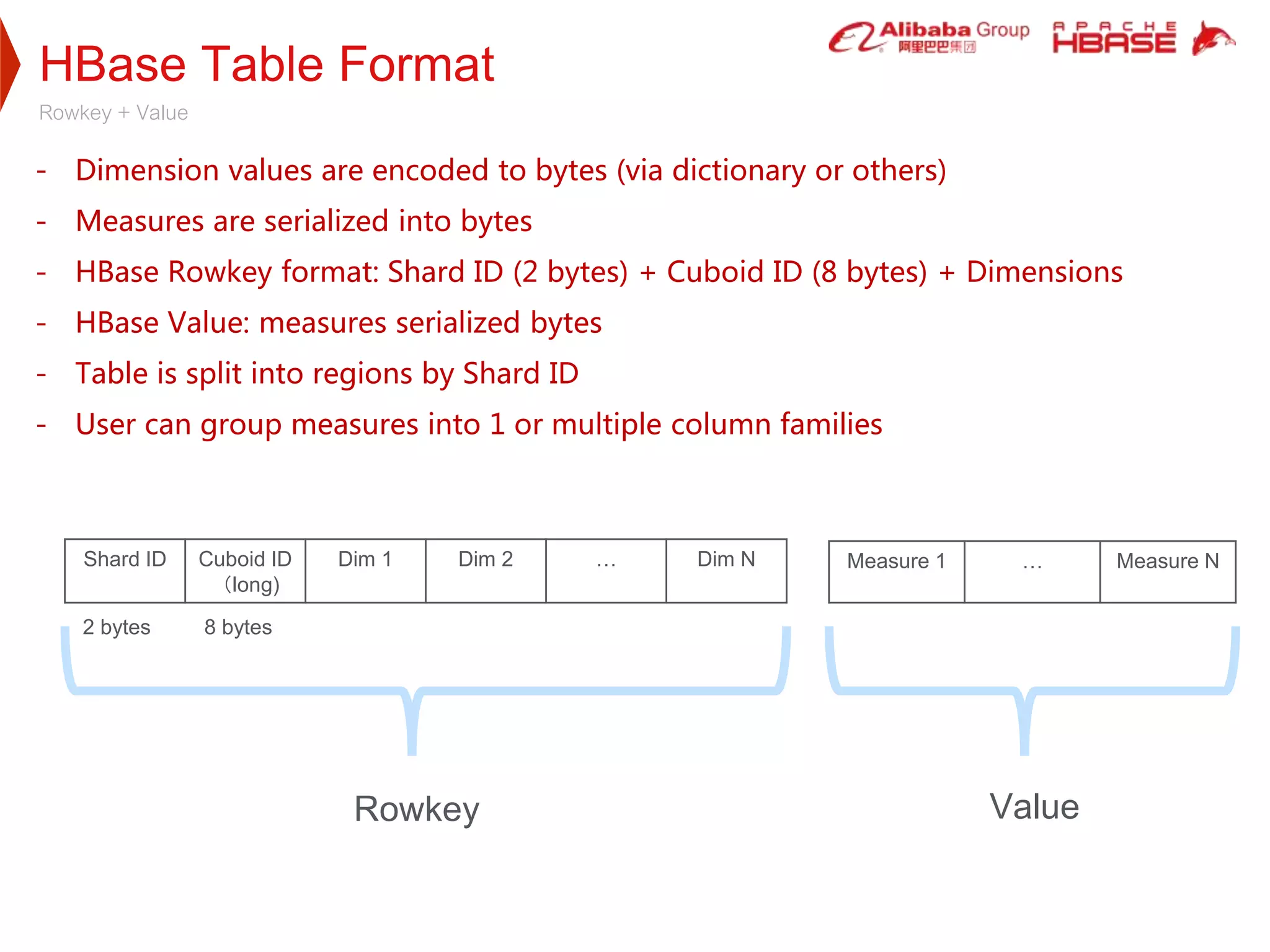
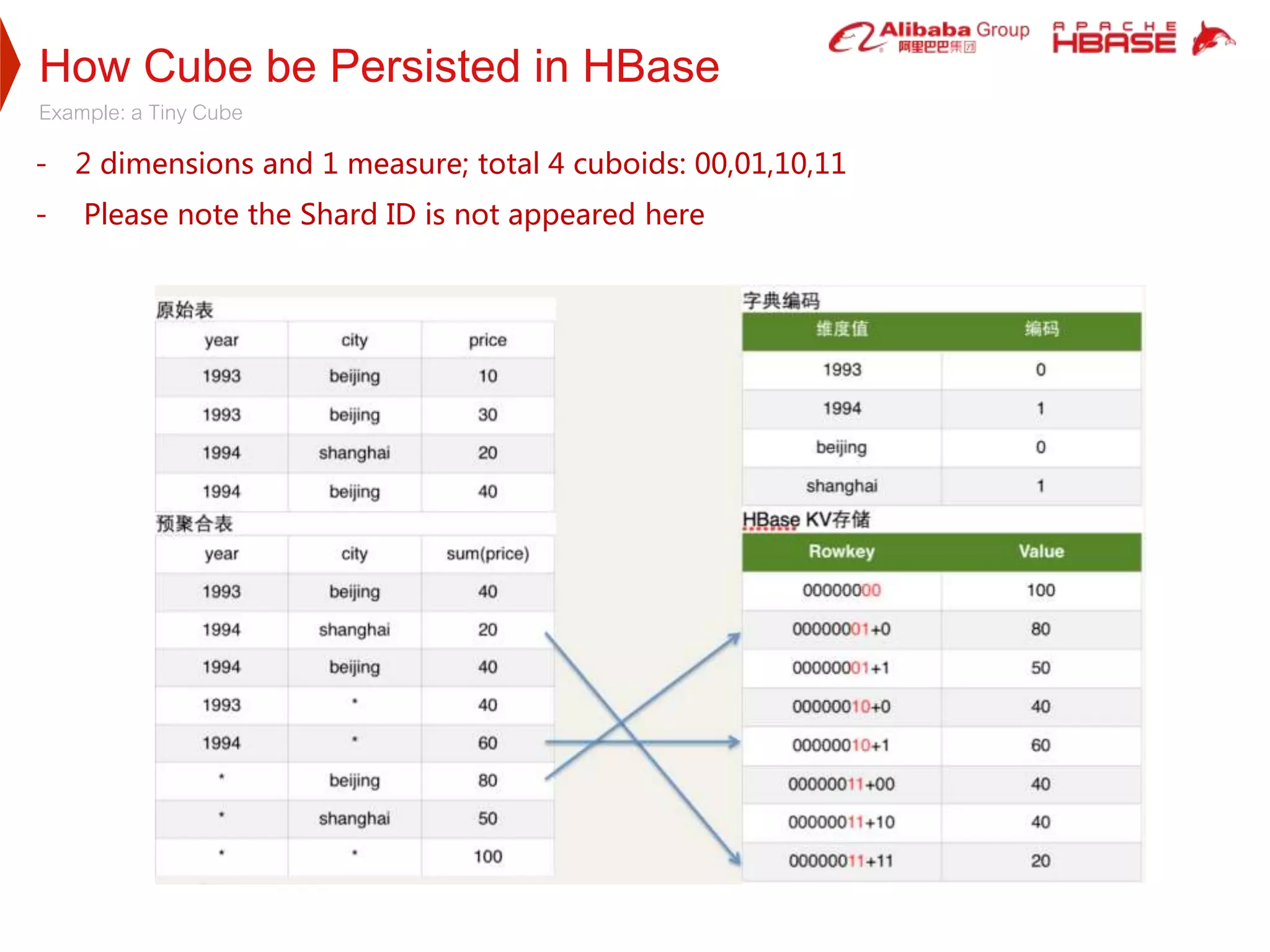
2. HBase was selected as the storage engine because it is natively integrated with Hadoop, supports high throughput and low-latency queries, and can store very large datasets. Kylin leverages HBase's capabilities for cube storage, metadata storage, online calculation pushing, and caching.
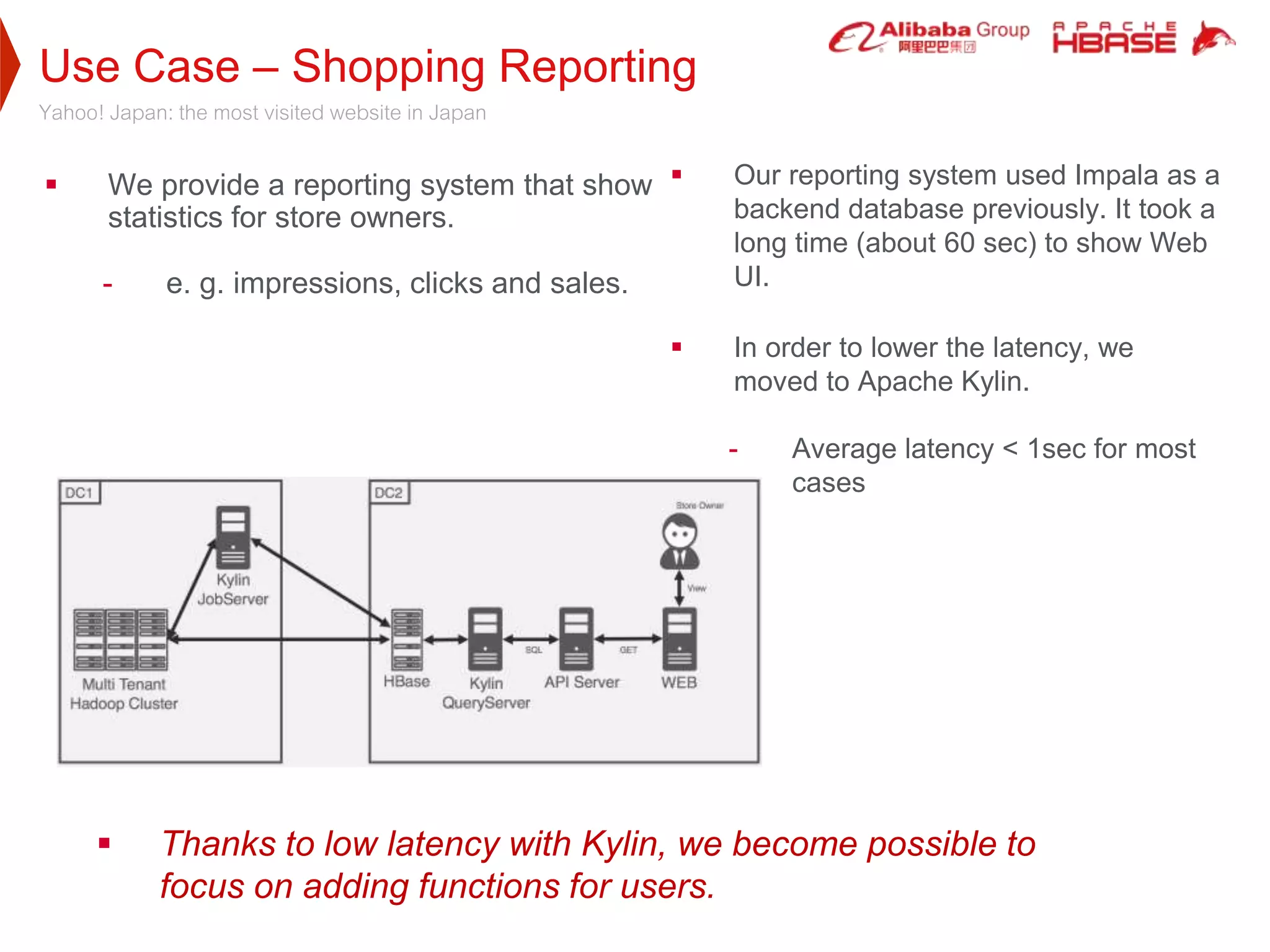
3. Apache Kylin is used by over 1000 global companies across






















































































![Automating ISP Networks Using Ansible and IPAM as a Source of Truth [SoT]](https://cdn.slidesharecdn.com/ss_thumbnails/automatingispnetworksusingansibleandipamasasourceoftruthsot-v25-1-251124105117-d7d4ca24-thumbnail.jpg?width=640&height=640&fit=bounds)









