Download to read offline



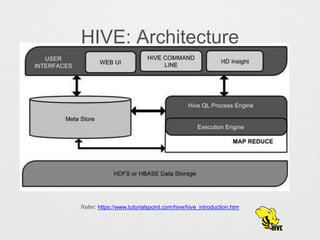
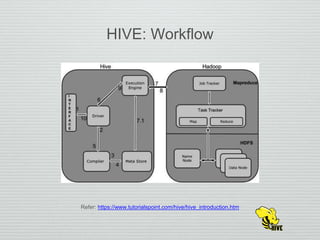







Hive allows querying and managing large datasets stored in distributed systems like HDFS. It uses a schema-on-read approach where the schema is not enforced until query time, allowing flexible data storage. Hive supports built-in, user-defined, and aggregate functions. It performs equi-joins and supports various join strategies like map-side joins, reduce-side joins, shuffle joins, and bucket joins. Map-side joins perform the join during the map phase by joining records with the same key from sorted and partitioned tables.


















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








