Downloaded 68 times










![darklabs.bah.com
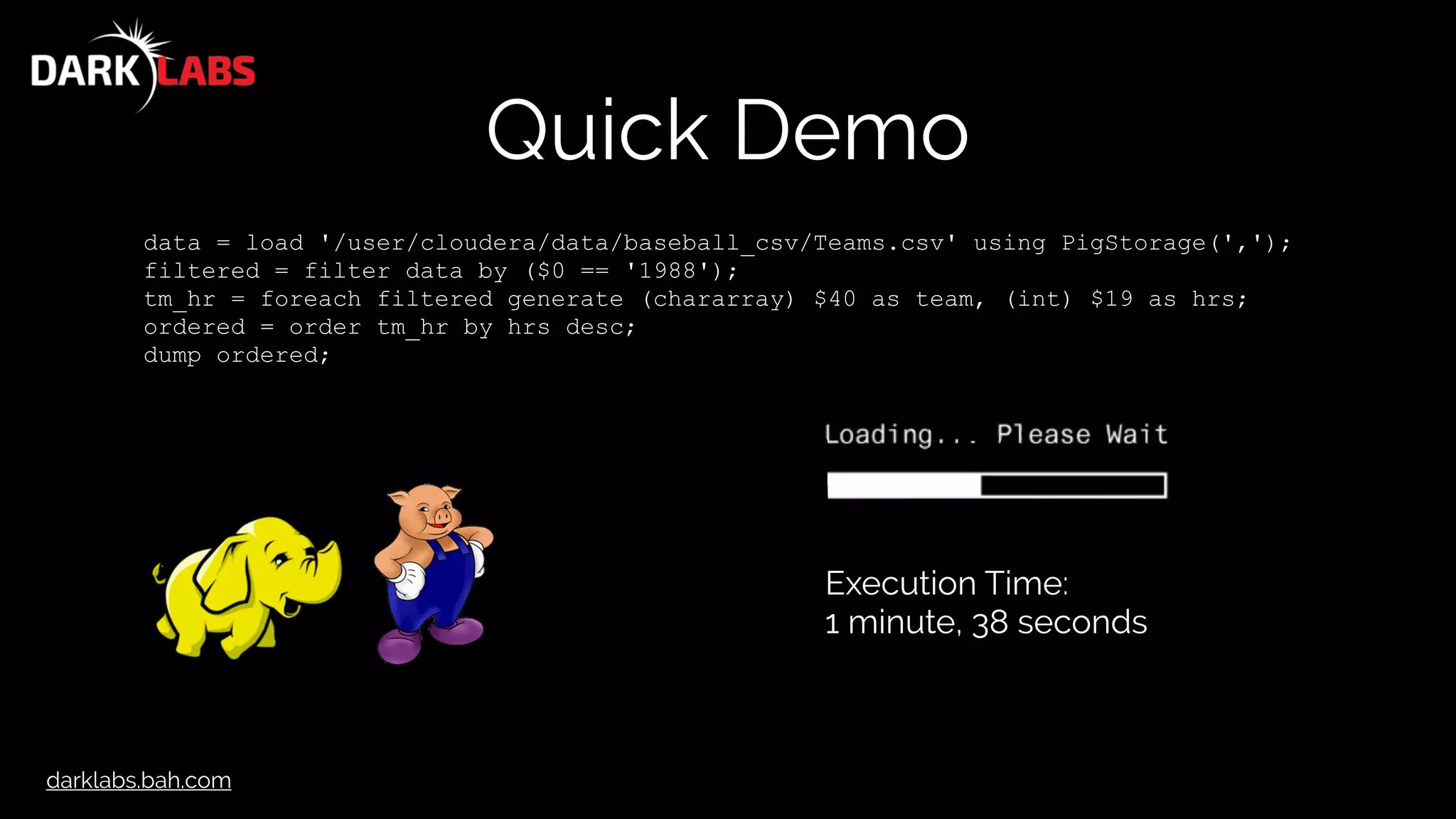
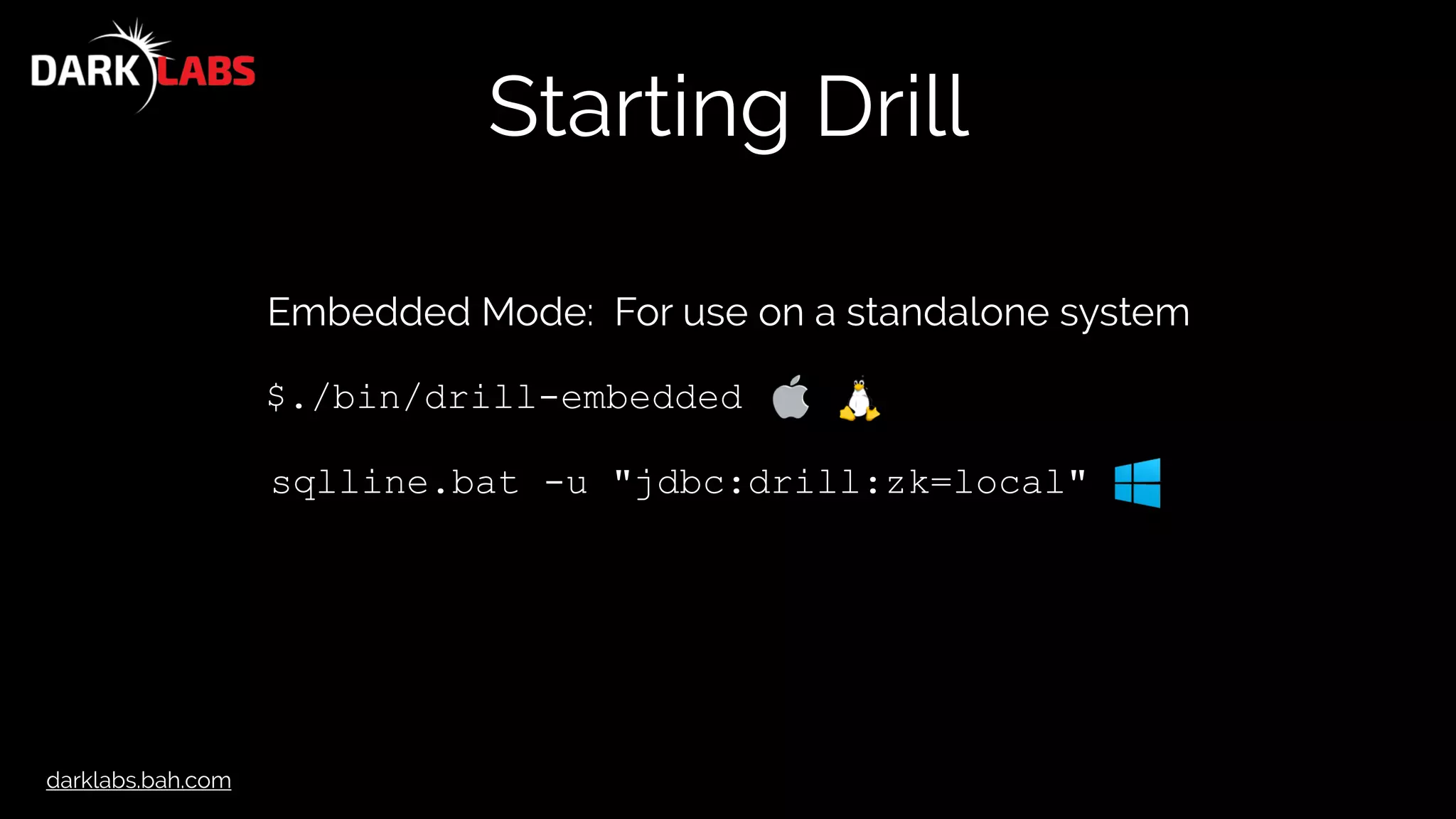
Quick Demo
SELECT columns[40], cast(columns[19] as int) AS HR
FROM `baseball_csv/Teams.csv`
WHERE columns[0] = '1988'
ORDER BY HR desc;
Execution Time:
0.89 seconds!!](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-13-2048.jpg)










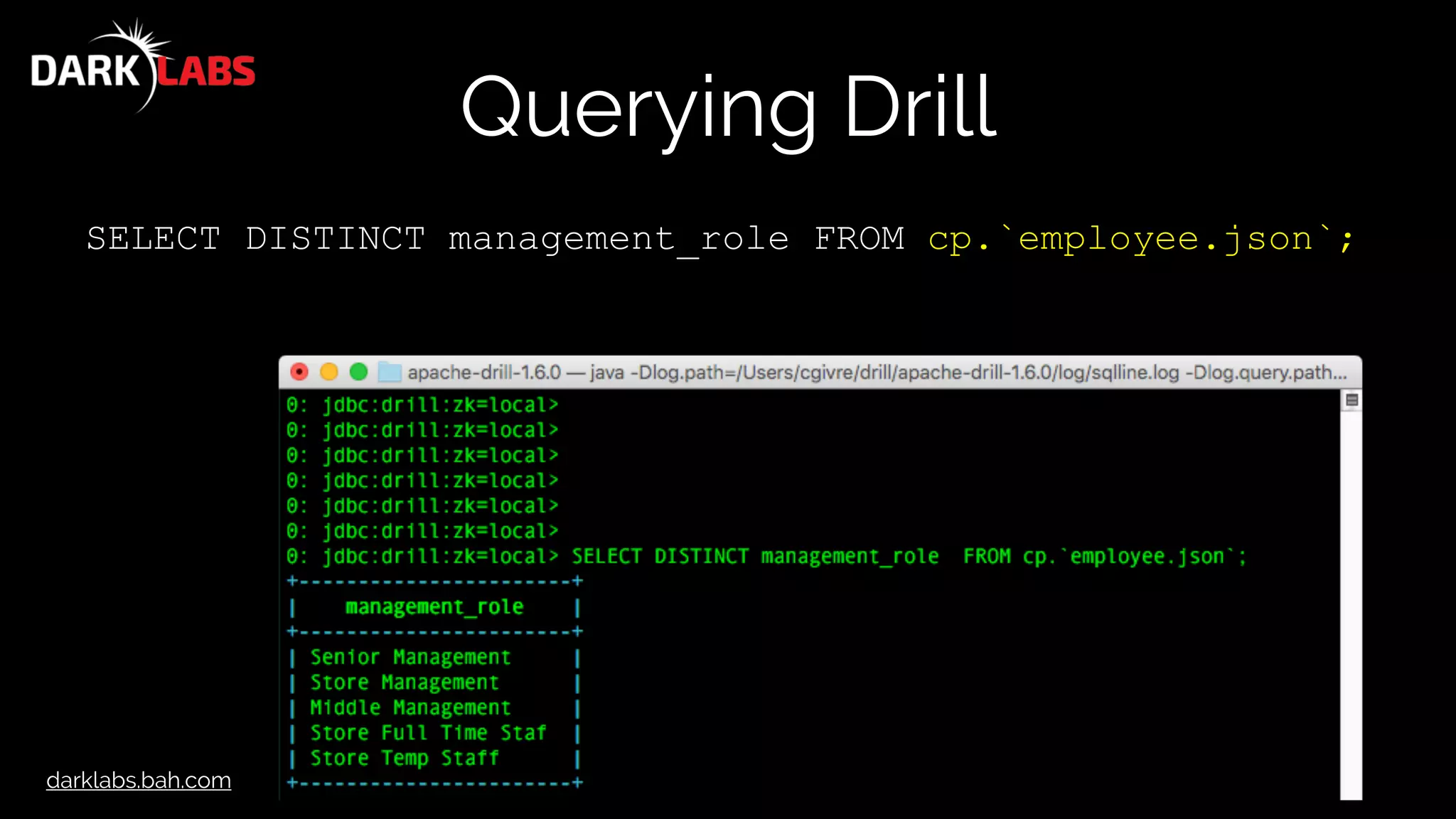

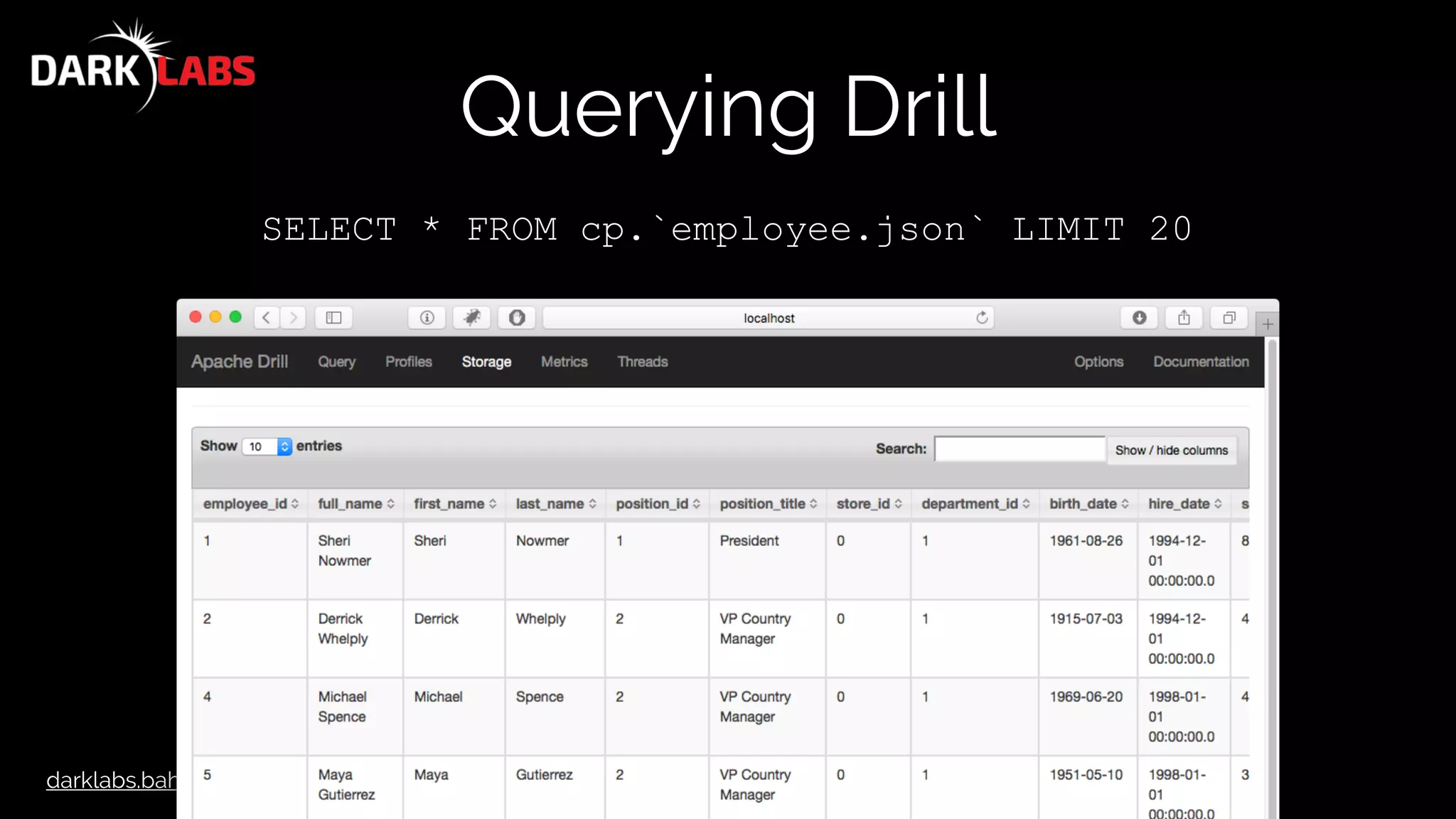




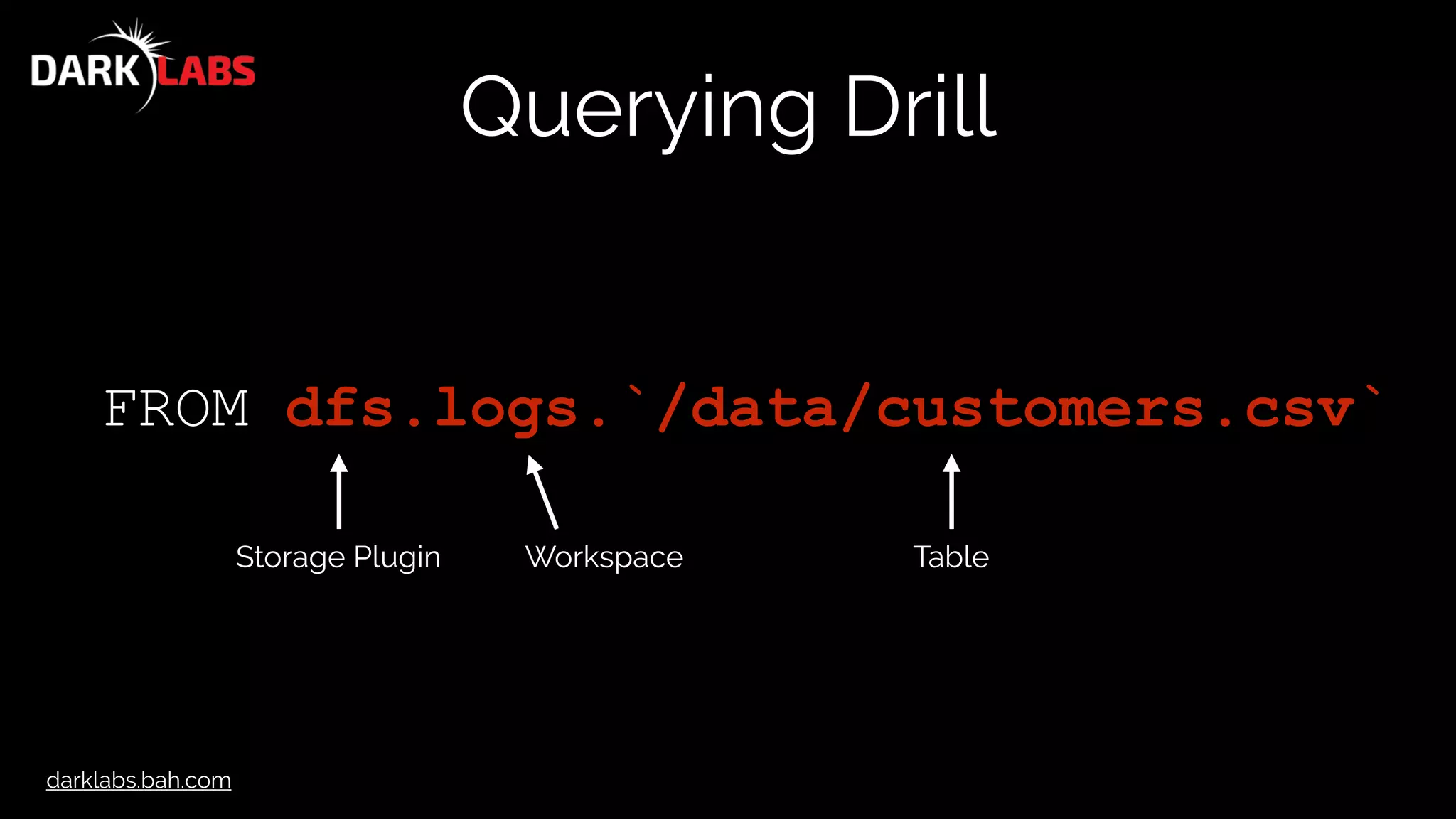


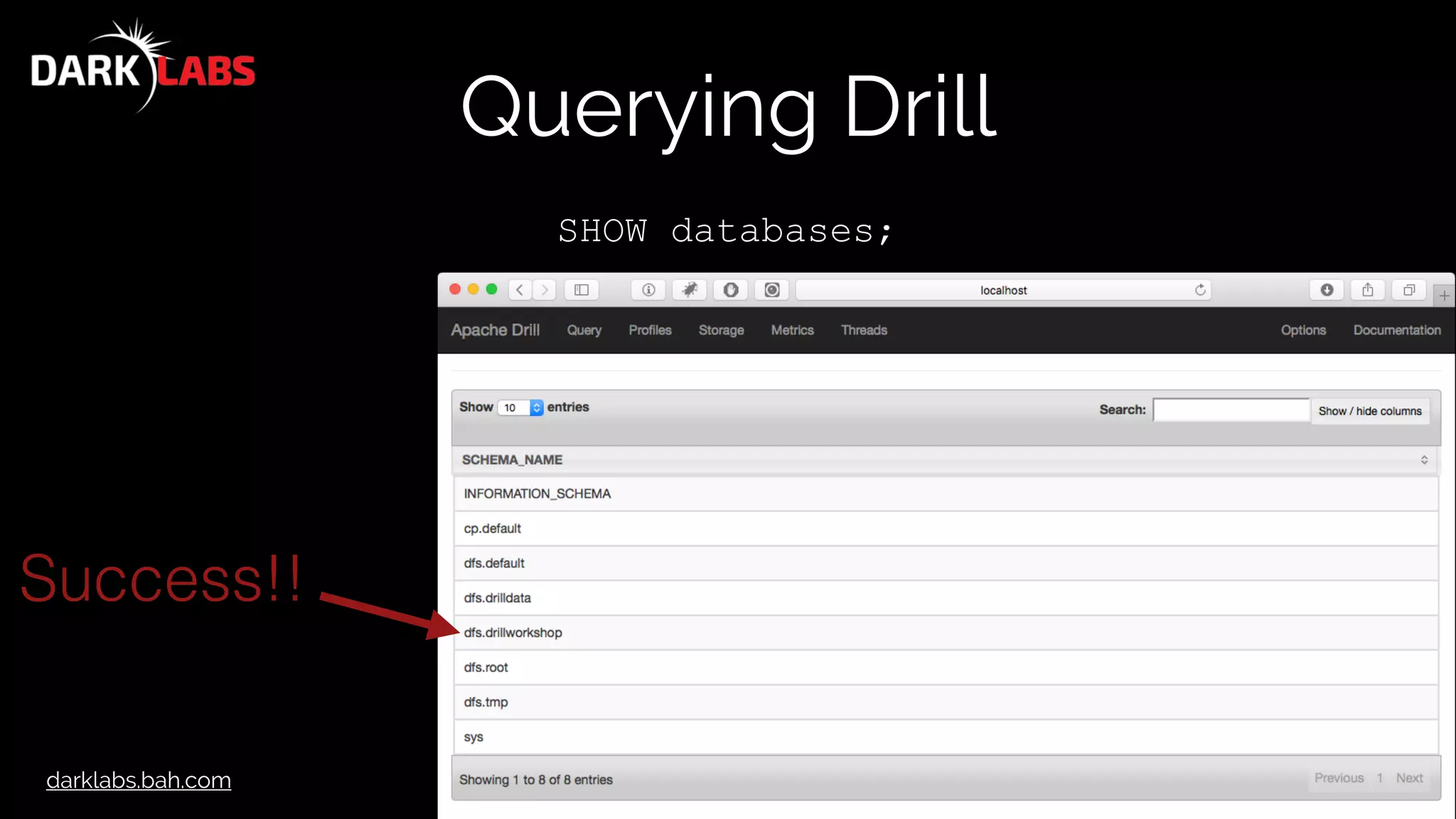
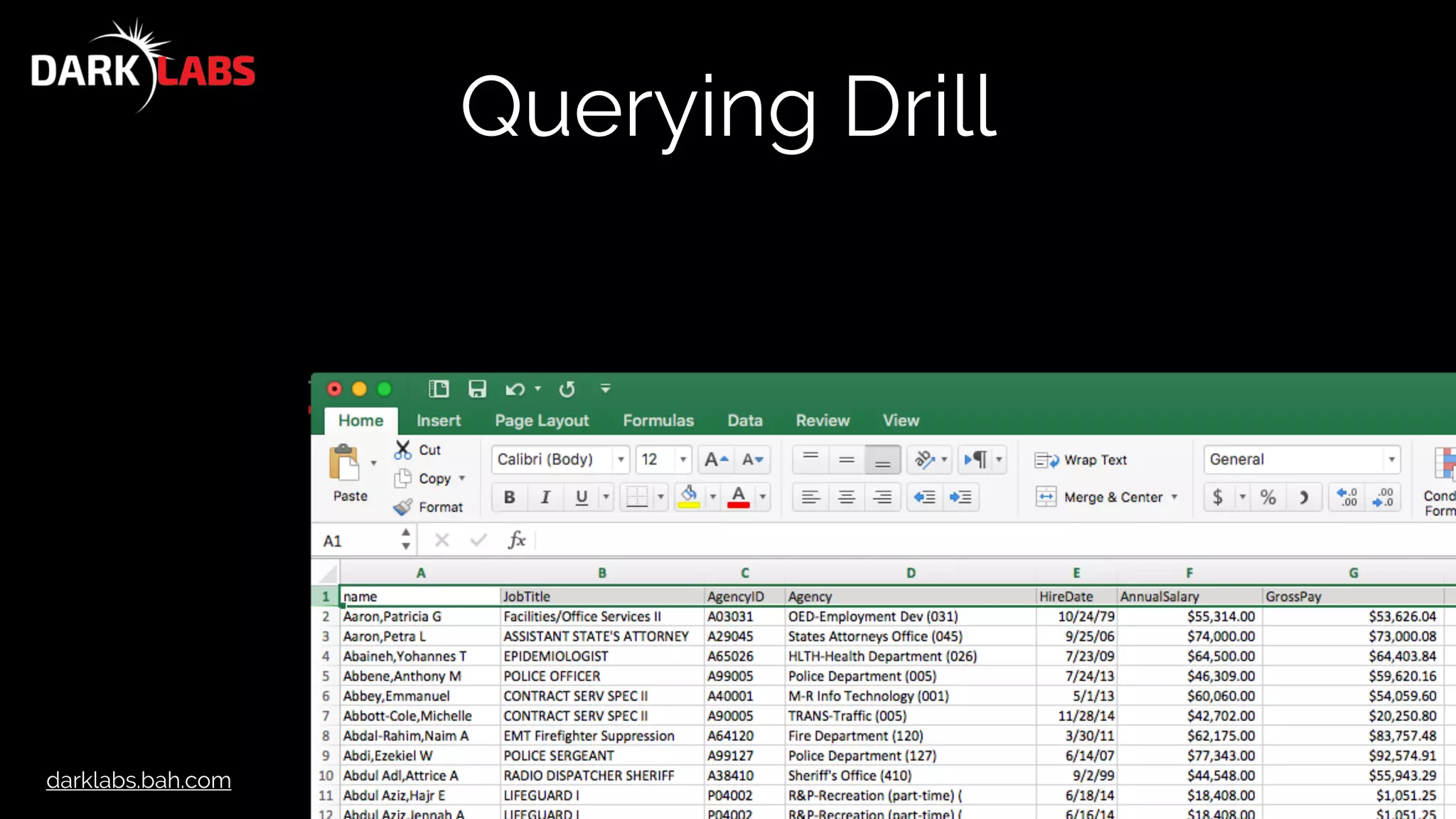

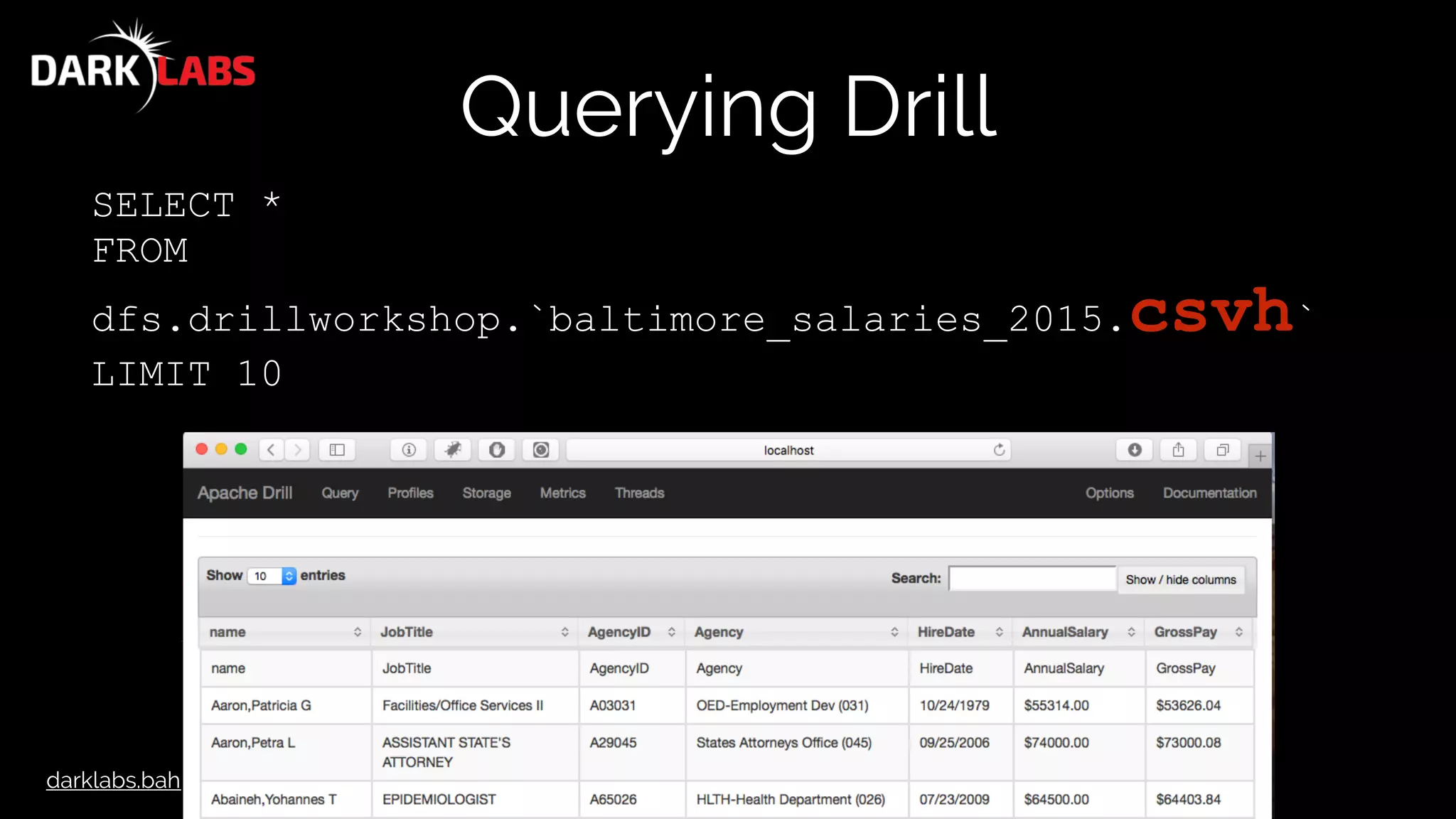
![darklabs.bah.com
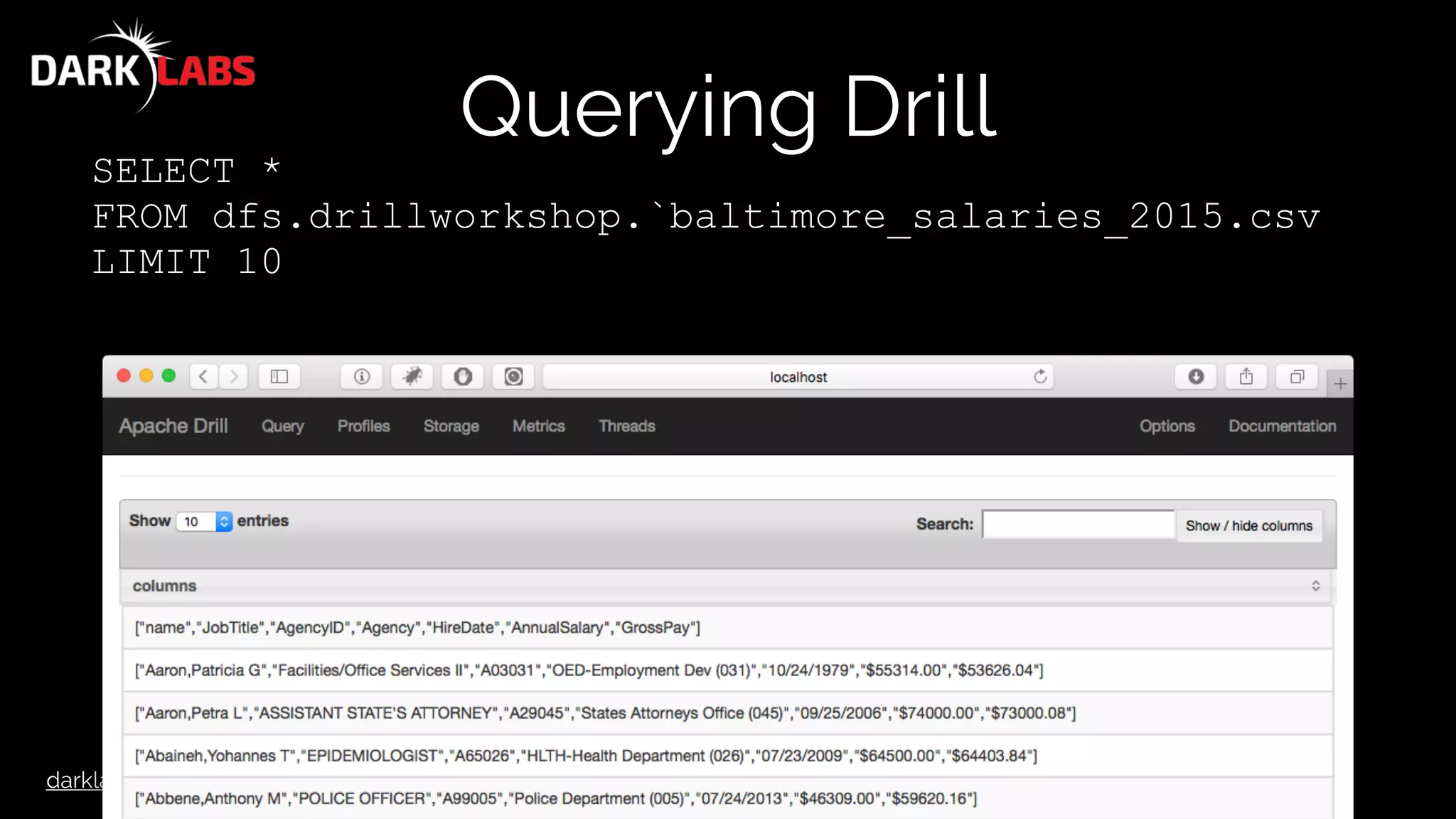
Querying Drill
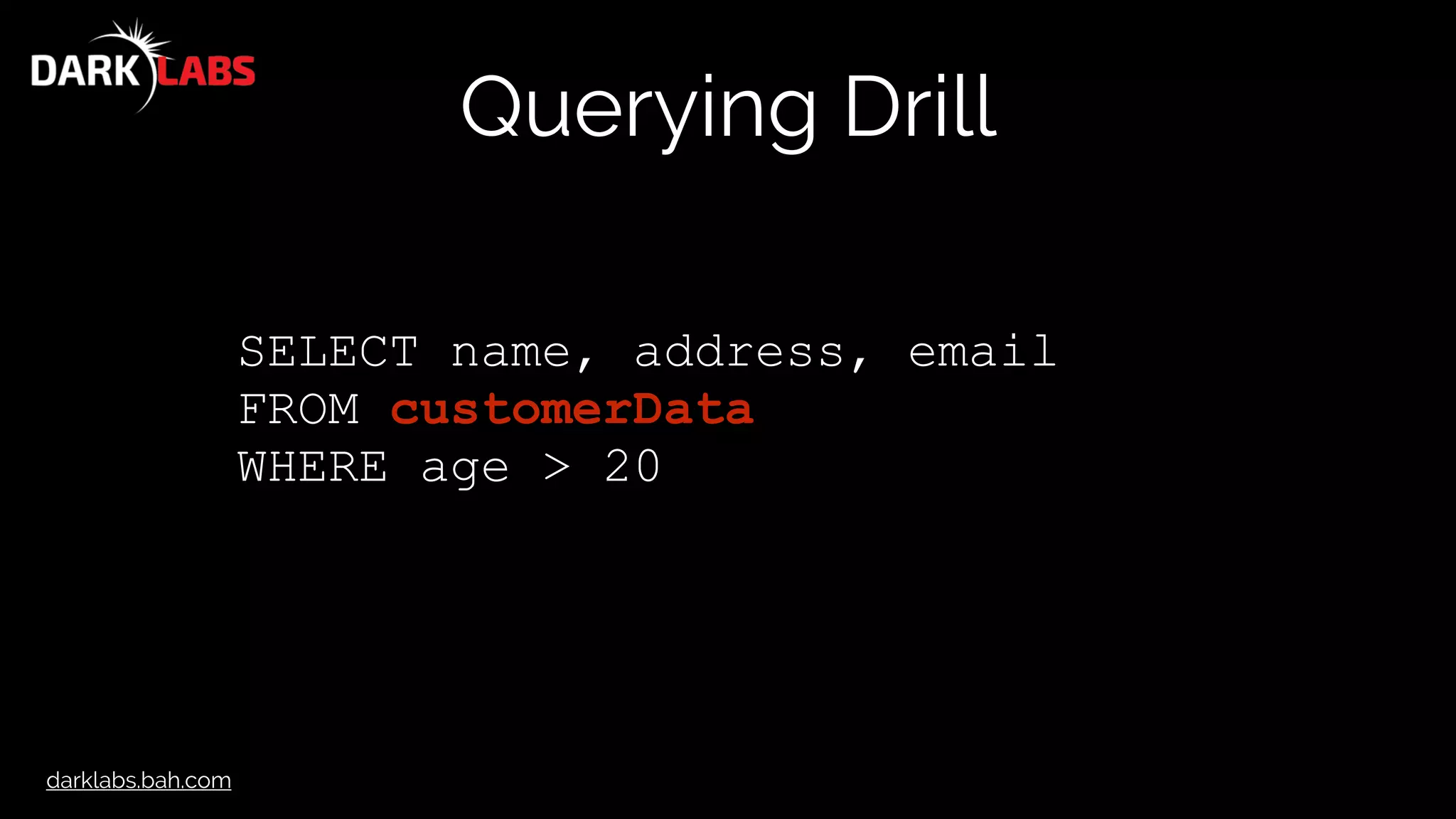
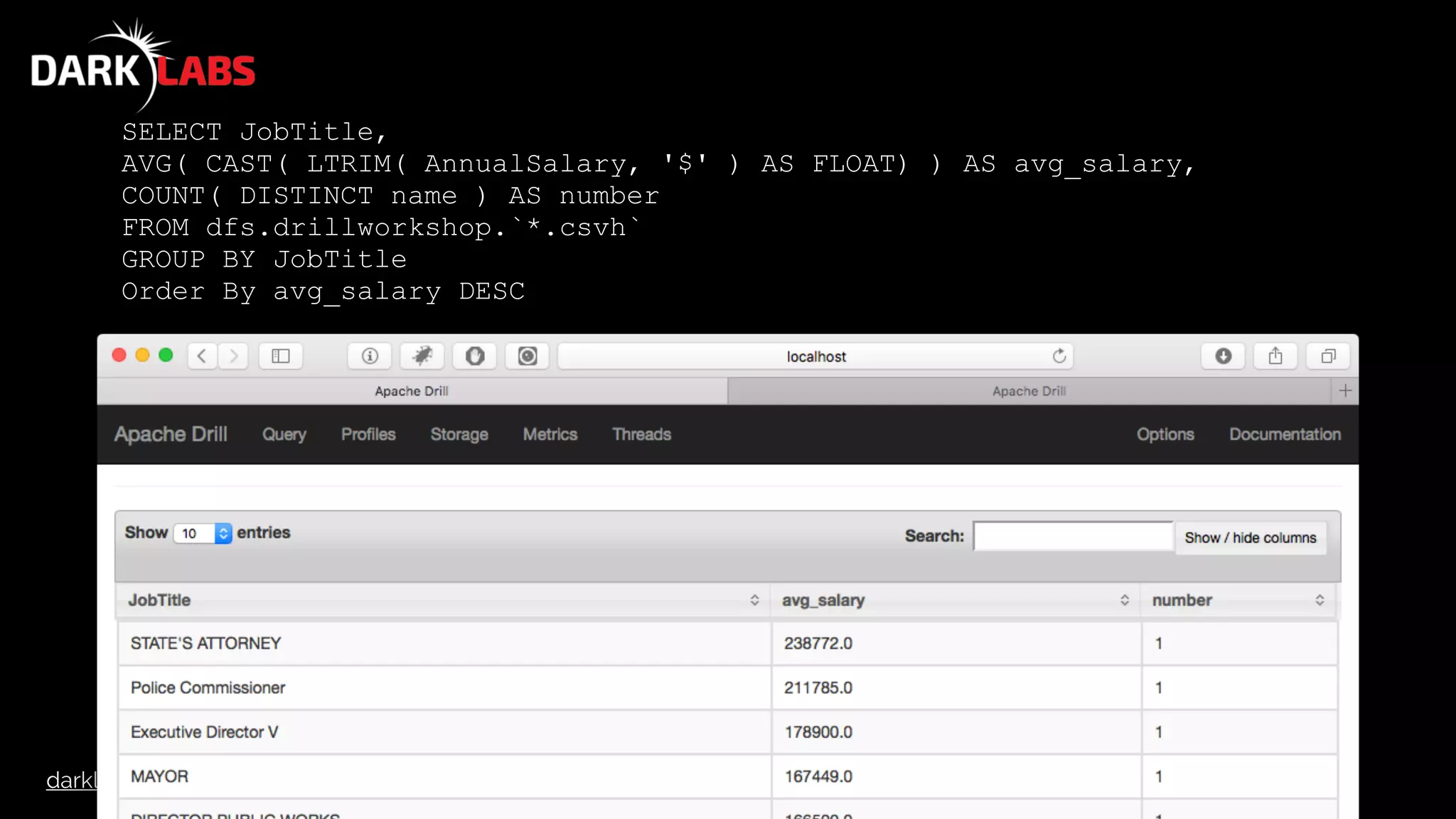
SELECT columns[0] AS name,
columns[1] AS JobTitle,
columns[2] AS AgencyID,
columns[3] AS Agency,
columns[4] AS HireDate,
columns[5] AS AnnualSalary,
columns[6] AS GrossPay
FROM dfs.drillworkshop.`baltimore_salaries_2015.csv`
LIMIT 10](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-45-2048.jpg)
![darklabs.bah.com
Querying Drill
SELECT columns[0] AS name,
columns[1] AS JobTitle,
. . .
FROM dfs.drillworkshop.`baltimore_salaries_2015.csv`
LIMIT 10](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-46-2048.jpg)
![darklabs.bah.com
Querying Drill
SELECT columns[0] AS name,
columns[1] AS JobTitle,
. . .
FROM dfs.drillworkshop.`baltimore_salaries_2015.csv`
LIMIT 10](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-47-2048.jpg)
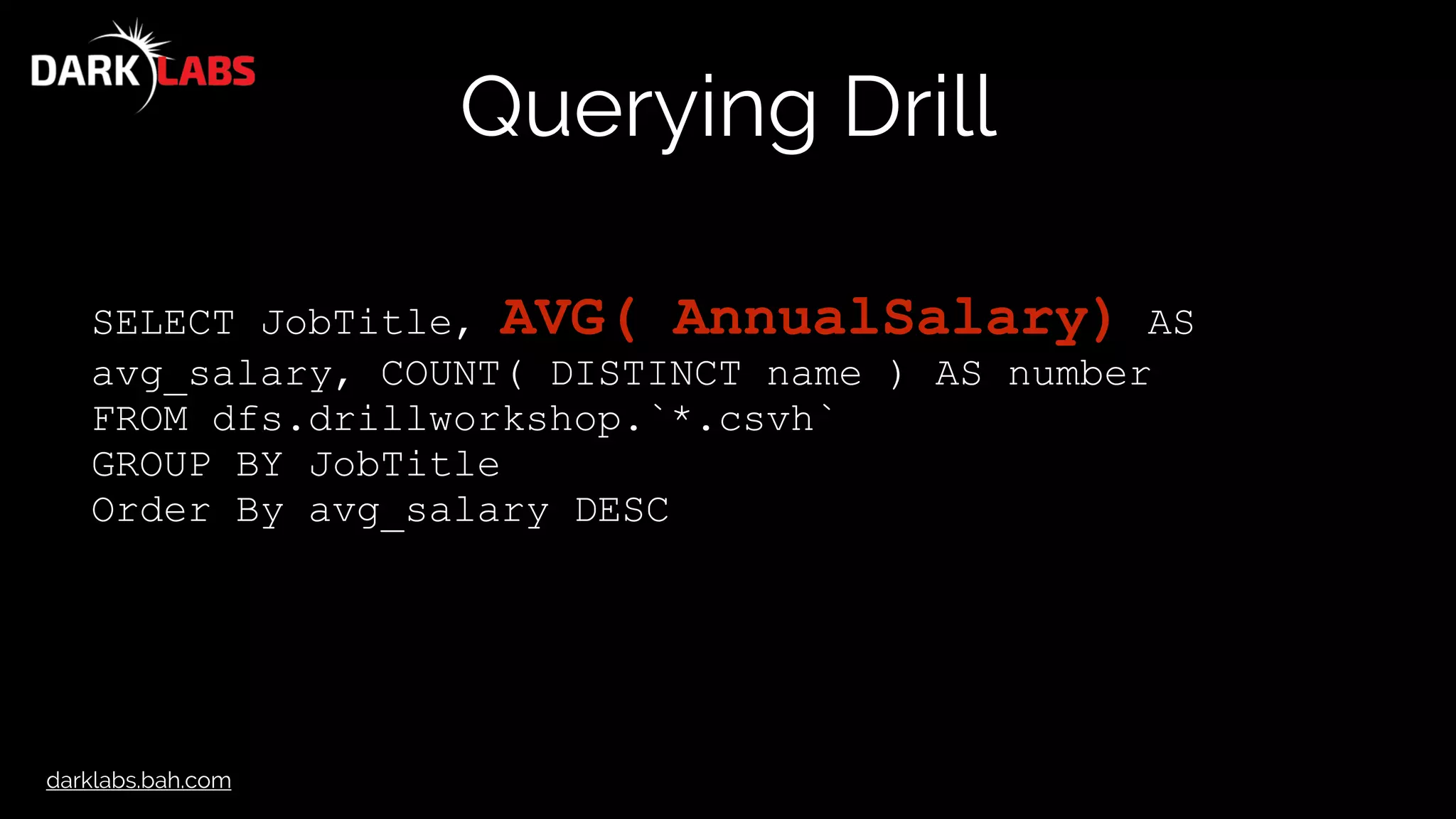
![darklabs.bah.com
Querying Drill
"csvh": {
"type": "text",
"extensions": [
"csvh"
],
"extractHeader": true,
"delimiter": ","
}](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-48-2048.jpg)
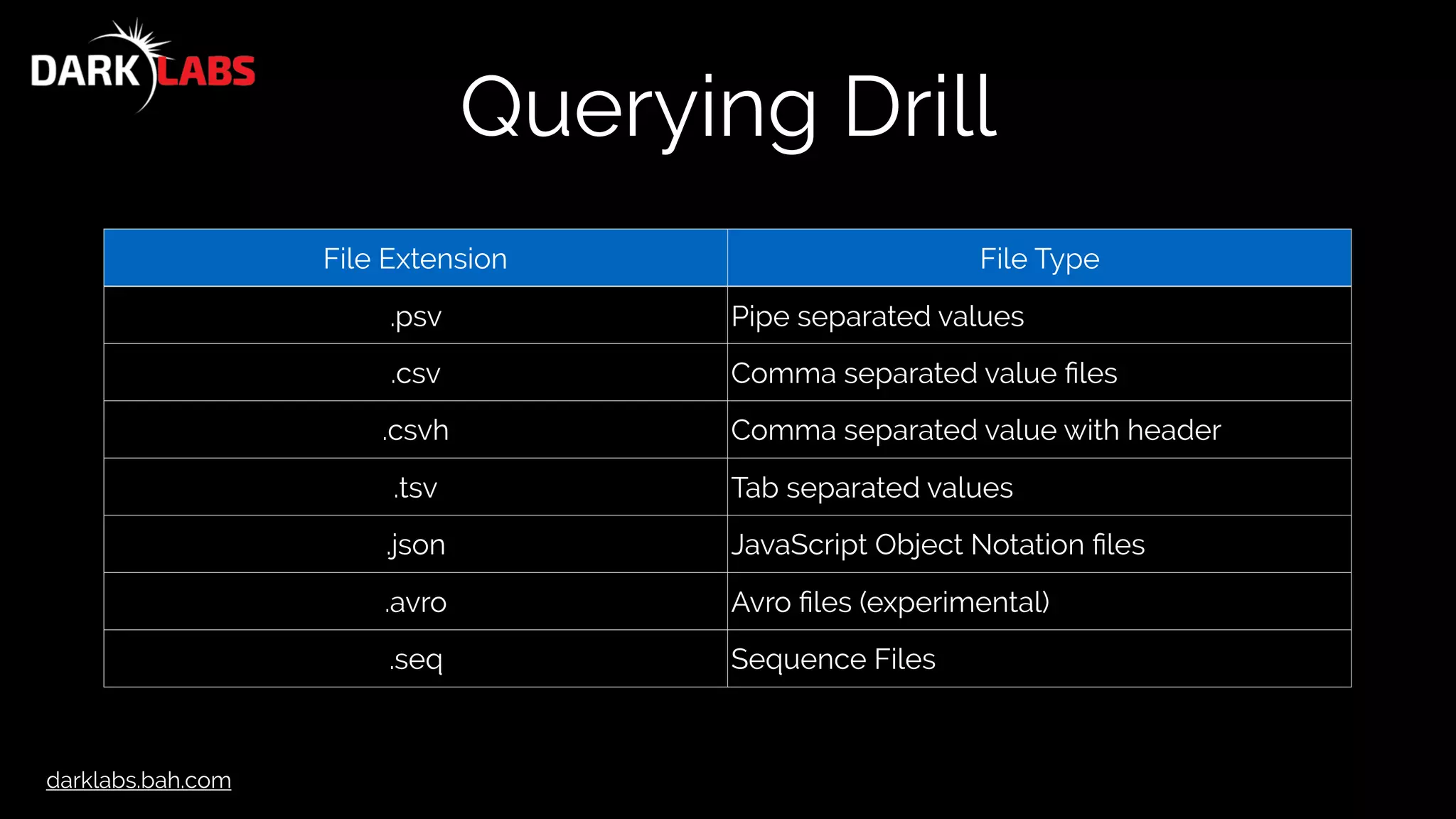


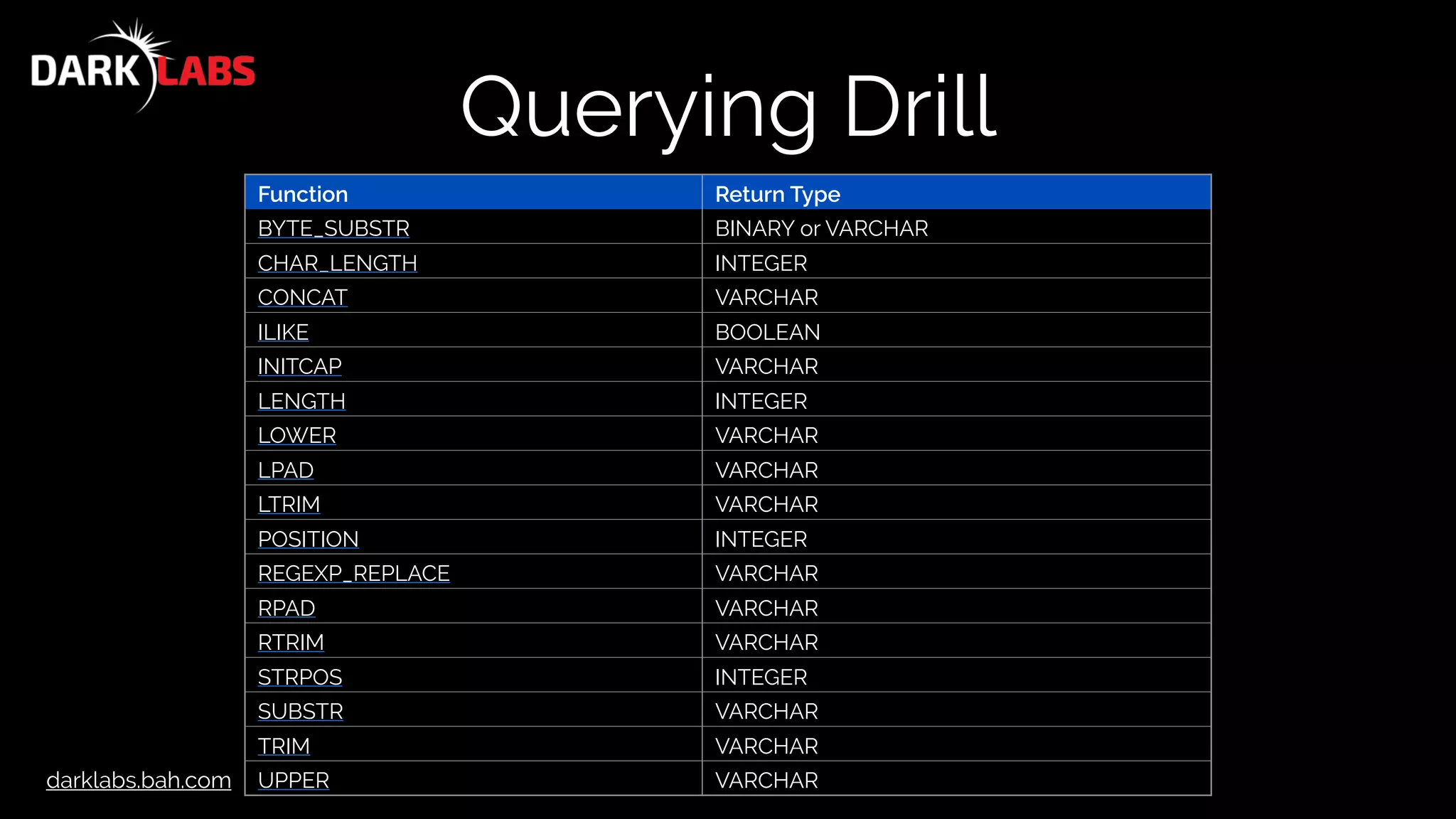
![darklabs.bah.com
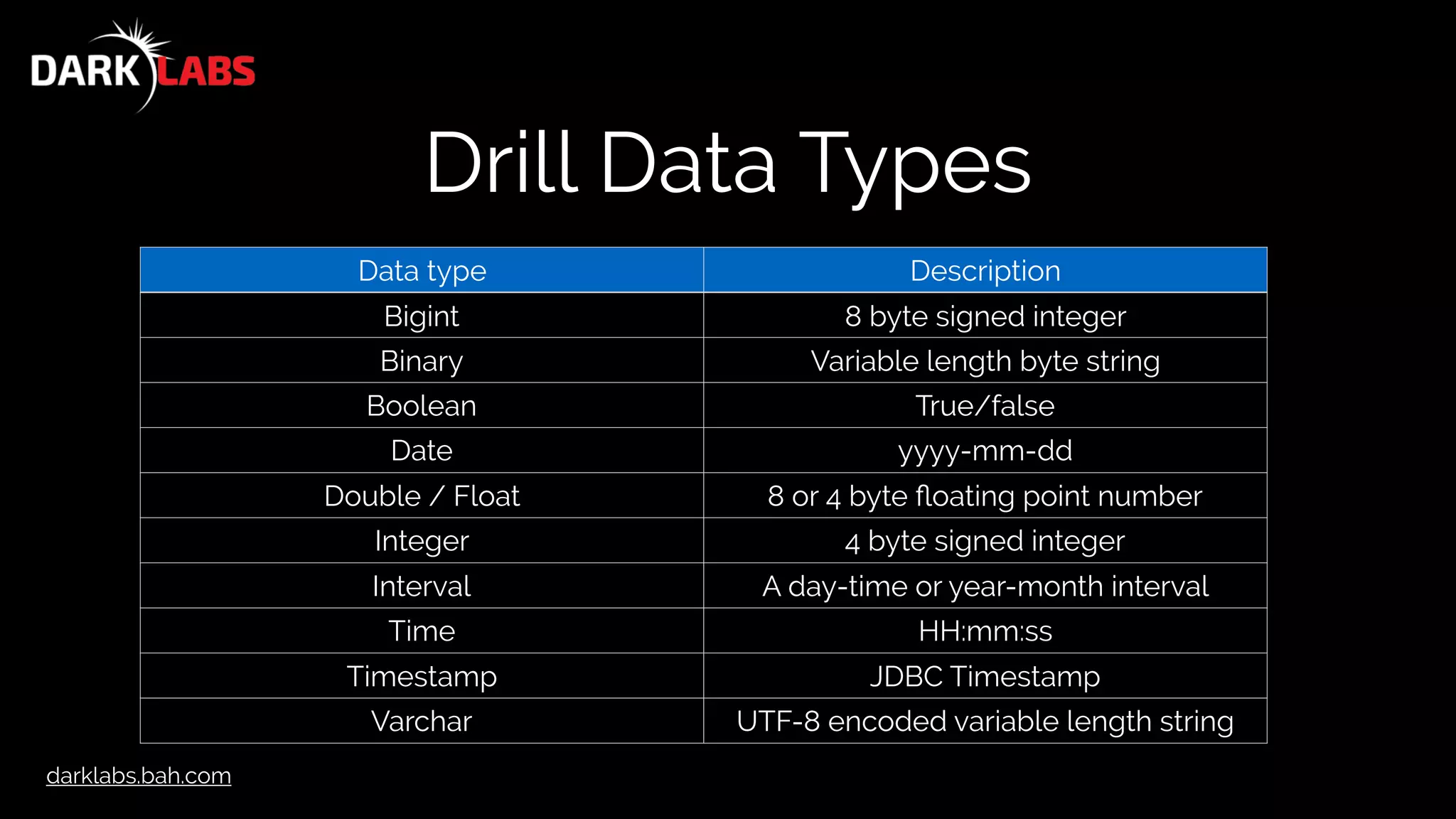
Aggregate Functions
Function Argument Type Return Type
AVG( expression ) Integer or Floating point Floating point
COUNT( * ) BIGINT
COUNT( [DISTINCT]
<expression> )
any BIGINT
MIN/MAX( <expression> ) Any numeric or date same as argument
SUM( <expression> ) Any numeric or interval same as argument](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-53-2048.jpg)

![darklabs.bah.com
Querying Drill
Query Failed: An Error Occurred
org.apache.drill.common.exceptions.UserRemoteException: SYSTEM ERROR:
SchemaChangeException: Failure while trying to materialize incoming schema.
Errors: Error in expression at index -1. Error: Missing function implementation:
[castINT(BIT-OPTIONAL)]. Full expression: --UNKNOWN EXPRESSION--..
Fragment 0:0 [Error Id: af88883b-f10a-4ea5-821d-5ff065628375 on
10.251.255.146:31010]](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-55-2048.jpg)






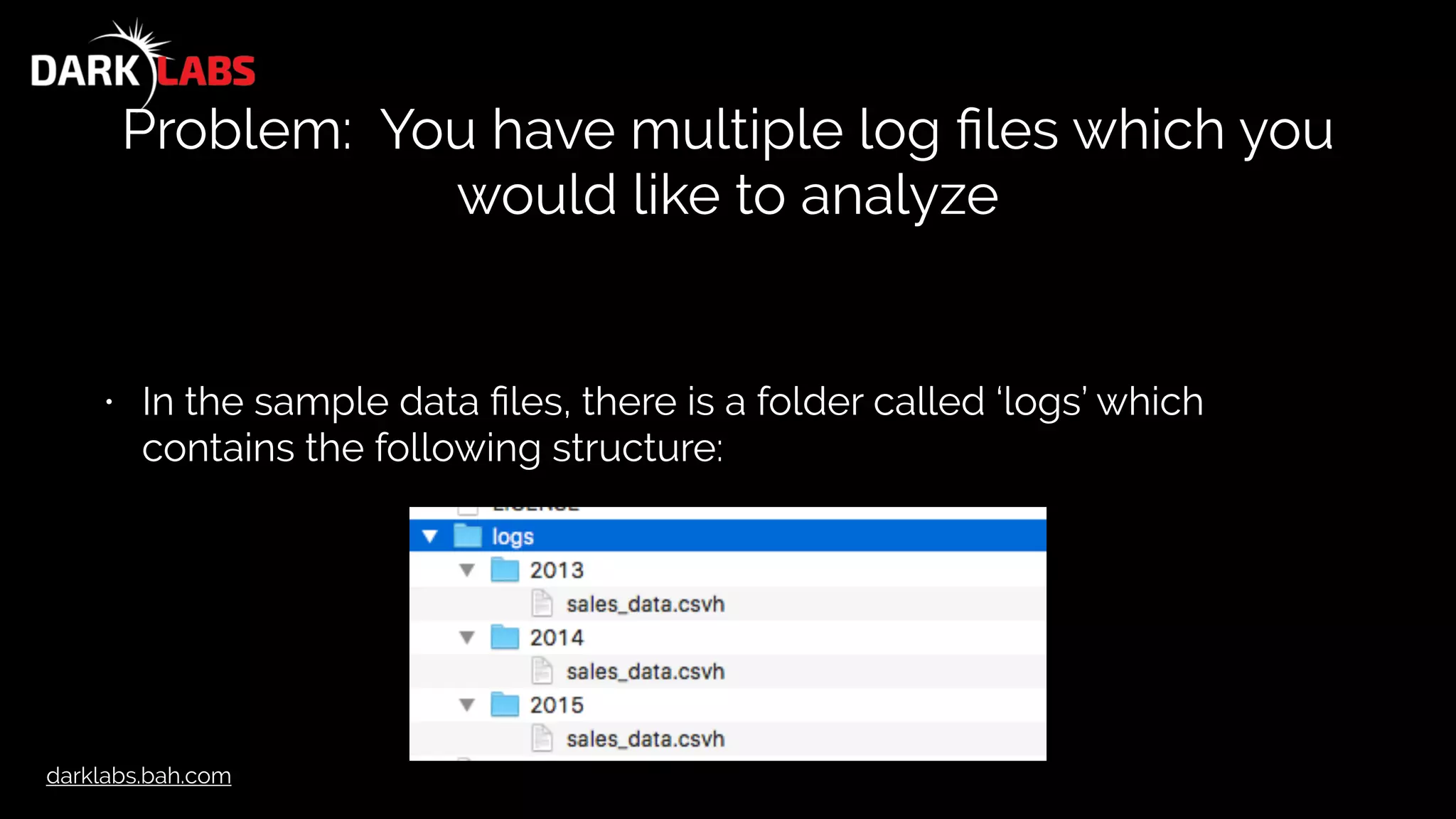






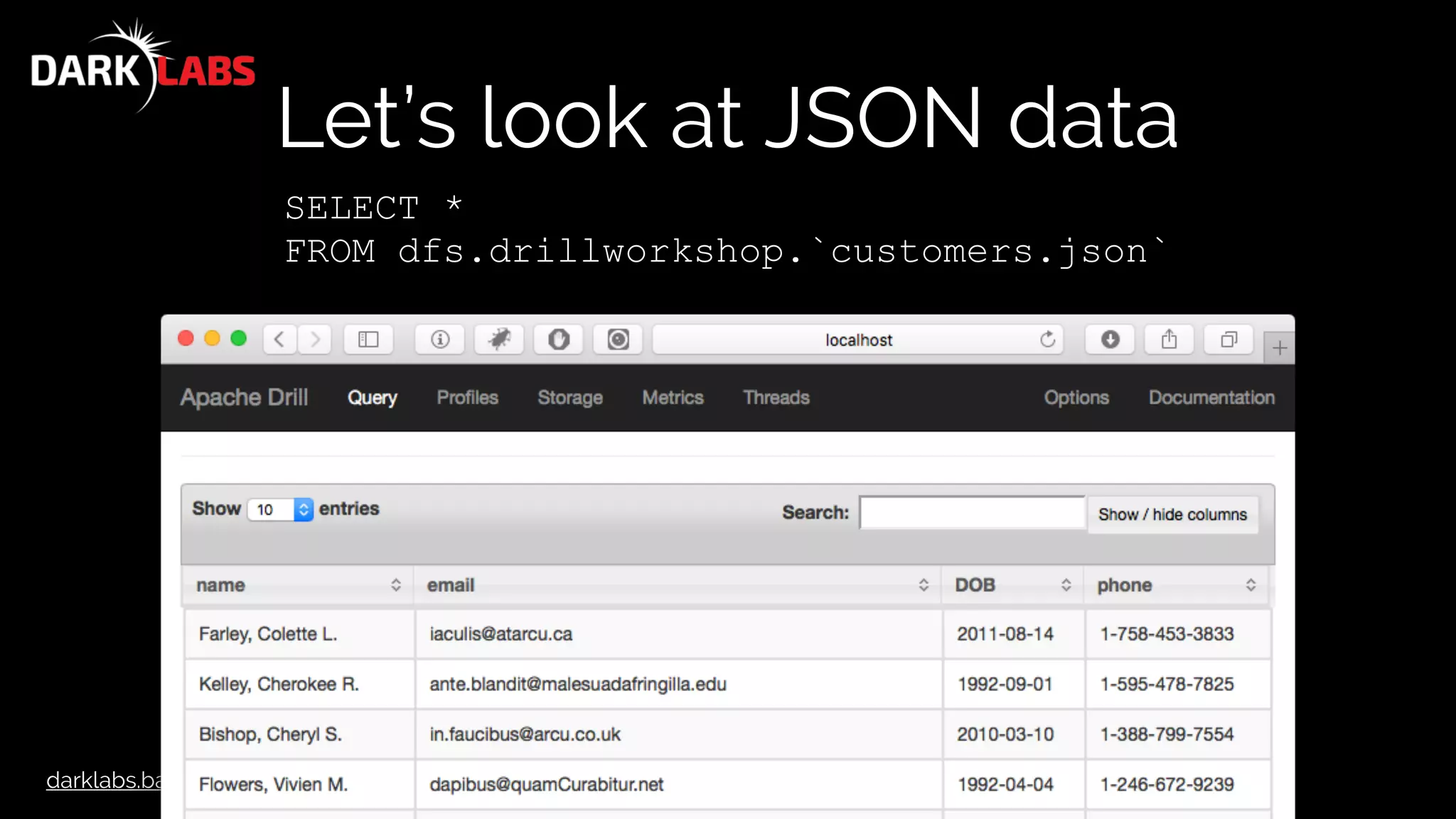
![darklabs.bah.com
Let’s look at JSON data
[
{
"name": "Farley, Colette L.",
"email": "iaculis@atarcu.ca",
"DOB": "2011-08-14",
"phone": "1-758-453-3833"
},
{
"name": "Kelley, Cherokee R.",
"email": "ante.blandit@malesuadafringilla.edu",
"DOB": "1992-09-01",
"phone": "1-595-478-7825"
}
…
]](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-75-2048.jpg)




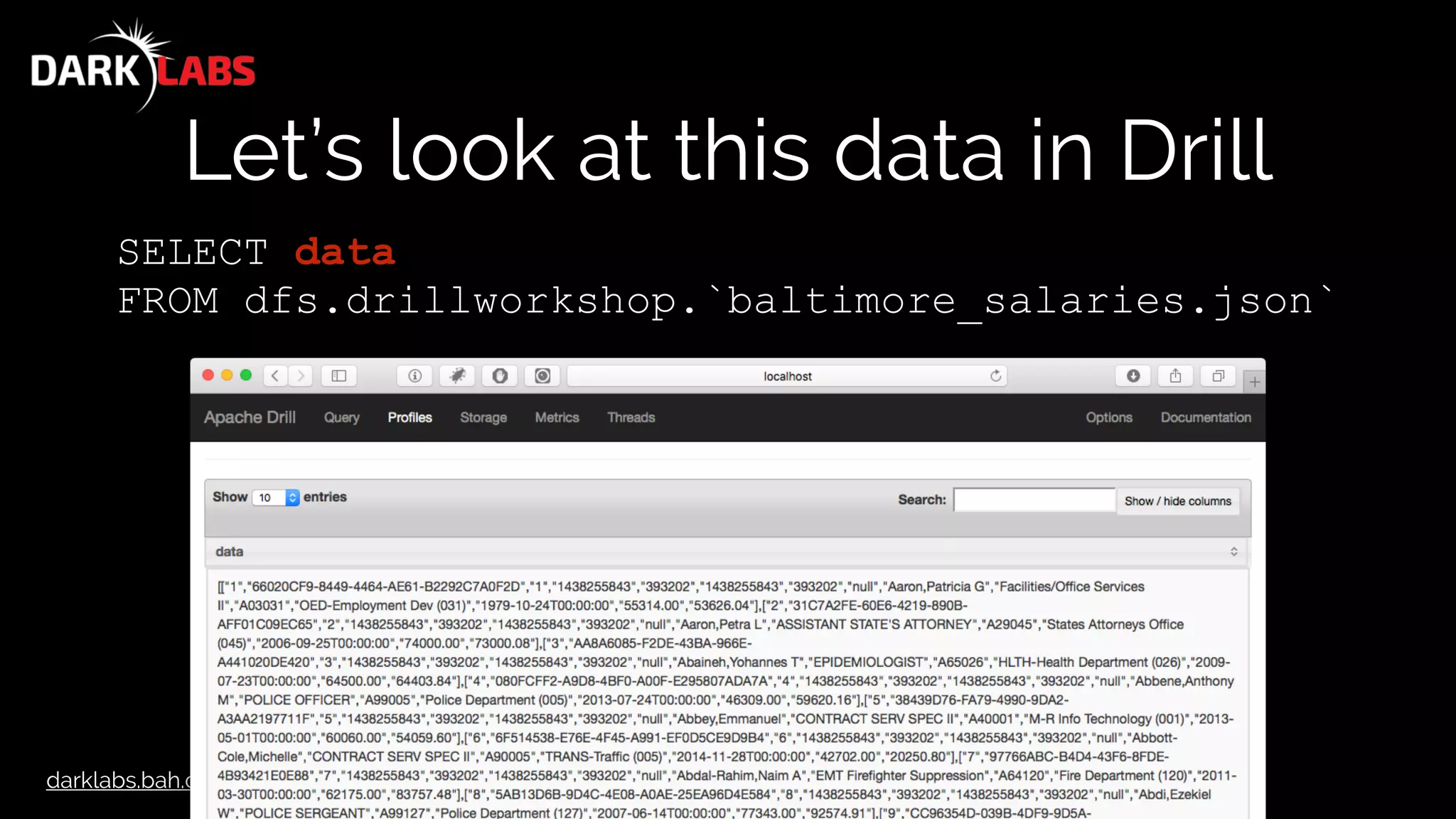
![darklabs.bah.com
{
"meta" : {
"view" : {
"id" : "nsfe-bg53",
"name" : "Baltimore City Employee Salaries FY2015",
"attribution" : "Mayor's Office",
"averageRating" : 0,
"category" : "City Government",
…
" "format" : { }
},
},
"data" : [ [ 1, "66020CF9-8449-4464-AE61-B2292C7A0F2D", 1, 1438255843, "393202",
1438255843, "393202", null, "Aaron,Patricia G", "Facilities/Office Services II",
"A03031", "OED-Employment Dev (031)", "1979-10-24T00:00:00", "55314.00", "53626.04" ]
, [ 2, "31C7A2FE-60E6-4219-890B-AFF01C09EC65", 2, 1438255843, "393202", 1438255843,
"393202", null, "Aaron,Petra L", "ASSISTANT STATE'S ATTORNEY", "A29045", "States
Attorneys Office (045)", "2006-09-25T00:00:00", "74000.00", "73000.08" ]](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-81-2048.jpg)
![darklabs.bah.com
{
"meta" : {
"view" : {
"id" : "nsfe-bg53",
"name" : "Baltimore City Employee Salaries FY2015",
"attribution" : "Mayor's Office",
"averageRating" : 0,
"category" : "City Government",
…
" "format" : { }
},
},
"data" : [ [ 1, "66020CF9-8449-4464-AE61-B2292C7A0F2D", 1, 1438255843, "393202",
1438255843, "393202", null, "Aaron,Patricia G", "Facilities/Office Services II",
"A03031", "OED-Employment Dev (031)", "1979-10-24T00:00:00", "55314.00", "53626.04" ]
, [ 2, "31C7A2FE-60E6-4219-890B-AFF01C09EC65", 2, 1438255843, "393202", 1438255843,
"393202", null, "Aaron,Petra L", "ASSISTANT STATE'S ATTORNEY", "A29045", "States
Attorneys Office (045)", "2006-09-25T00:00:00", "74000.00", "73000.08" ]](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-82-2048.jpg)
![darklabs.bah.com
{
"meta" : {
"view" : {
"id" : "nsfe-bg53",
"name" : "Baltimore City Employee Salaries FY2015",
"attribution" : "Mayor's Office",
"averageRating" : 0,
"category" : "City Government",
…
" "format" : { }
},
},
"data" : [ [ 1, "66020CF9-8449-4464-AE61-B2292C7A0F2D", 1,
1438255843, "393202", 1438255843, "393202", null,
"Aaron,Patricia G", "Facilities/Office Services II", "A03031",
"OED-Employment Dev (031)", "1979-10-24T00:00:00", "55314.00",
"53626.04" ]
, [ 2, "31C7A2FE-60E6-4219-890B-AFF01C09EC65", 2, 1438255843,
"393202", 1438255843, "393202", null, "Aaron,Petra L",
"ASSISTANT STATE'S ATTORNEY", "A29045", "States Attorneys
Office (045)", "2006-09-25T00:00:00", "74000.00", "73000.08" ]](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-83-2048.jpg)
![darklabs.bah.com
"data" : [
[ 1,
"66020CF9-8449-4464-AE61-B2292C7A0F2D",
1,
1438255843,
"393202",
1438255843,
“393202",
null,
"Aaron,Patricia G",
"Facilities/Office Services II",
"A03031",
"OED-Employment Dev (031)",
"1979-10-24T00:00:00",
“55314.00",
“53626.04"
]](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-84-2048.jpg)







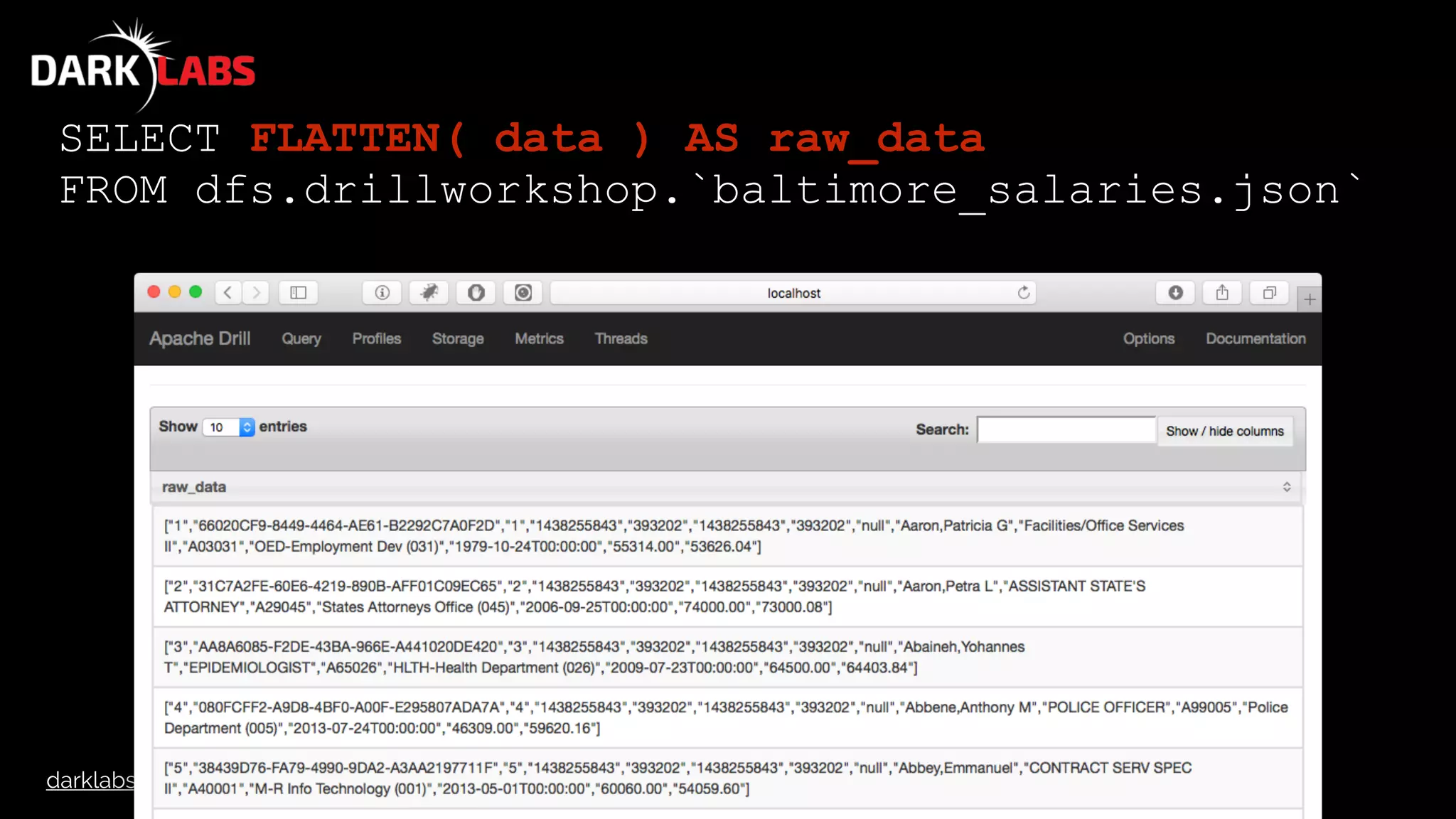

![darklabs.bah.com
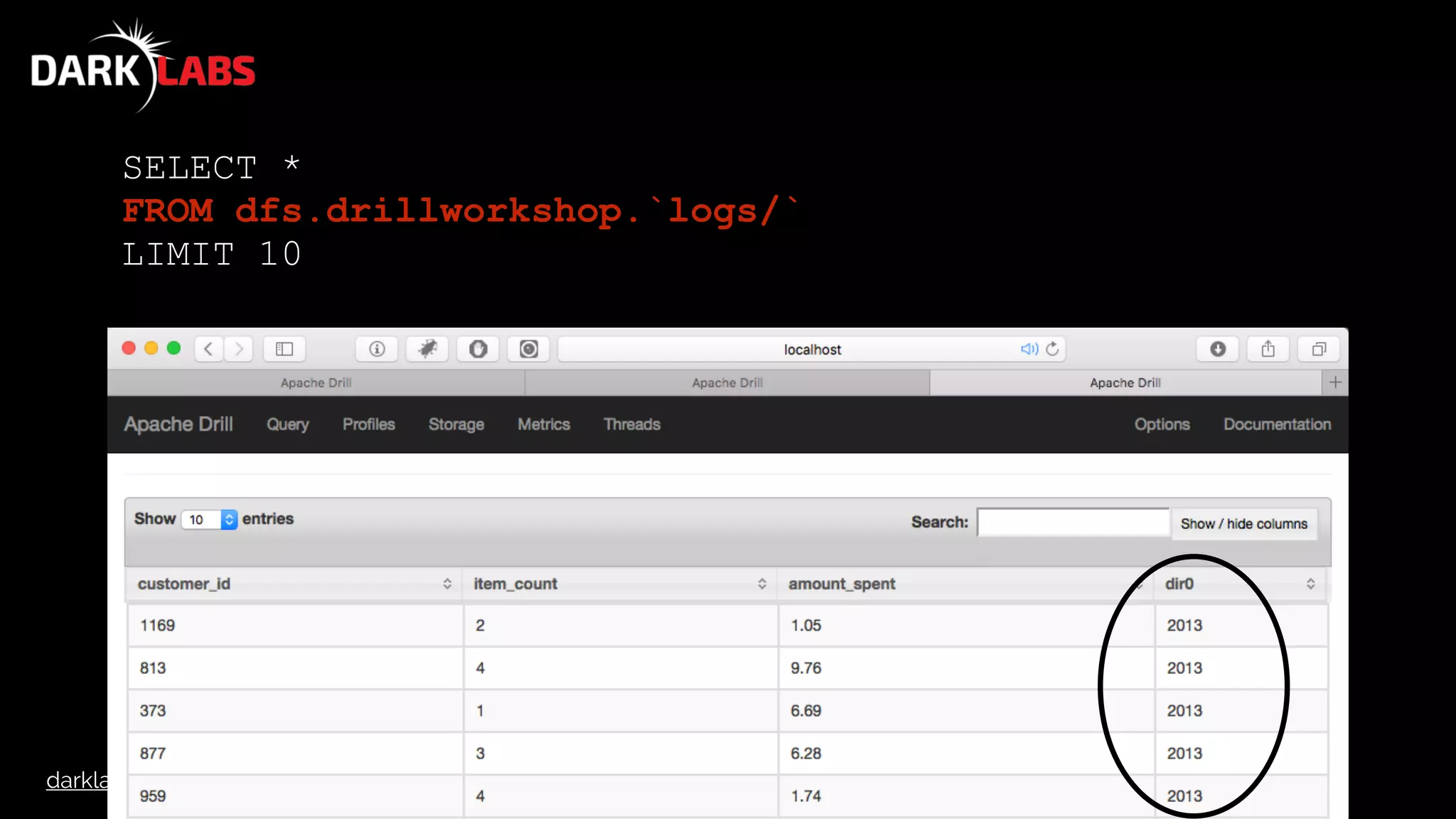
SELECT raw_data[8] AS name …
FROM
(
SELECT FLATTEN( data ) AS raw_data
FROM dfs.drillworkshop.`baltimore_salaries.json`
)](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-95-2048.jpg)
![darklabs.bah.com
SELECT raw_data[8] AS name, raw_data[9] AS job_title
FROM
(
SELECT FLATTEN( data ) AS raw_data
FROM dfs.drillworkshop.`baltimore_salaries.json`
)](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-96-2048.jpg)

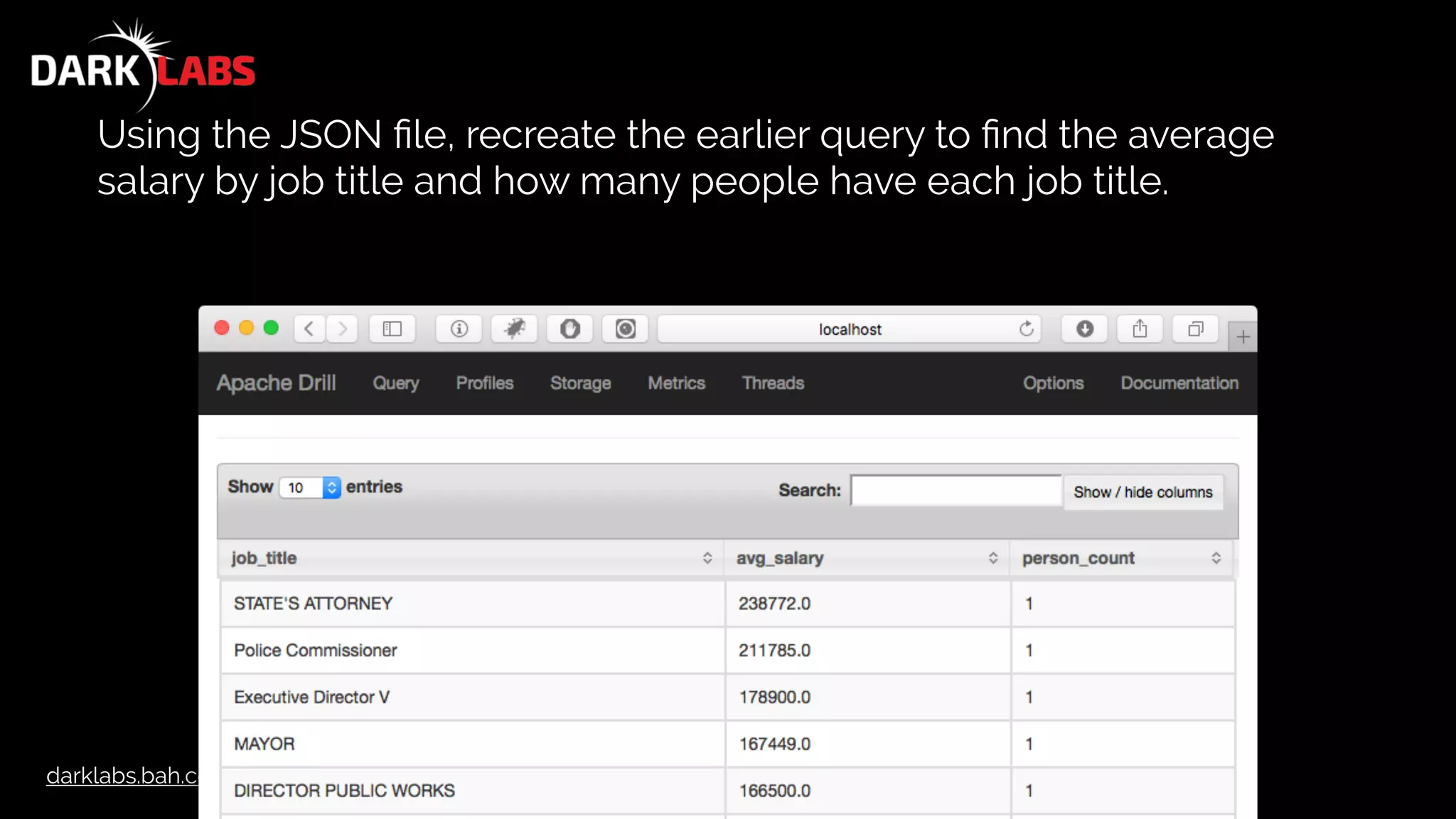
![darklabs.bah.com
In Class Exercise
Using the JSON file, recreate the earlier query to find the average
salary by job title and how many people have each job title.
SELECT raw_data[9] AS job_title,
AVG( CAST( raw_data[13] AS DOUBLE ) ) AS avg_salary,
COUNT( DISTINCT raw_data[8] ) AS person_count
FROM
(
SELECT FLATTEN( data ) AS raw_data
FROM dfs.drillworkshop.`baltimore_salaries.json`
)
GROUP BY raw_data[9]
ORDER BY avg_salary DESC](https://image.slidesharecdn.com/apachedrillworkshop-160606173002/75/Apache-Drill-Workshop-98-2048.jpg)



















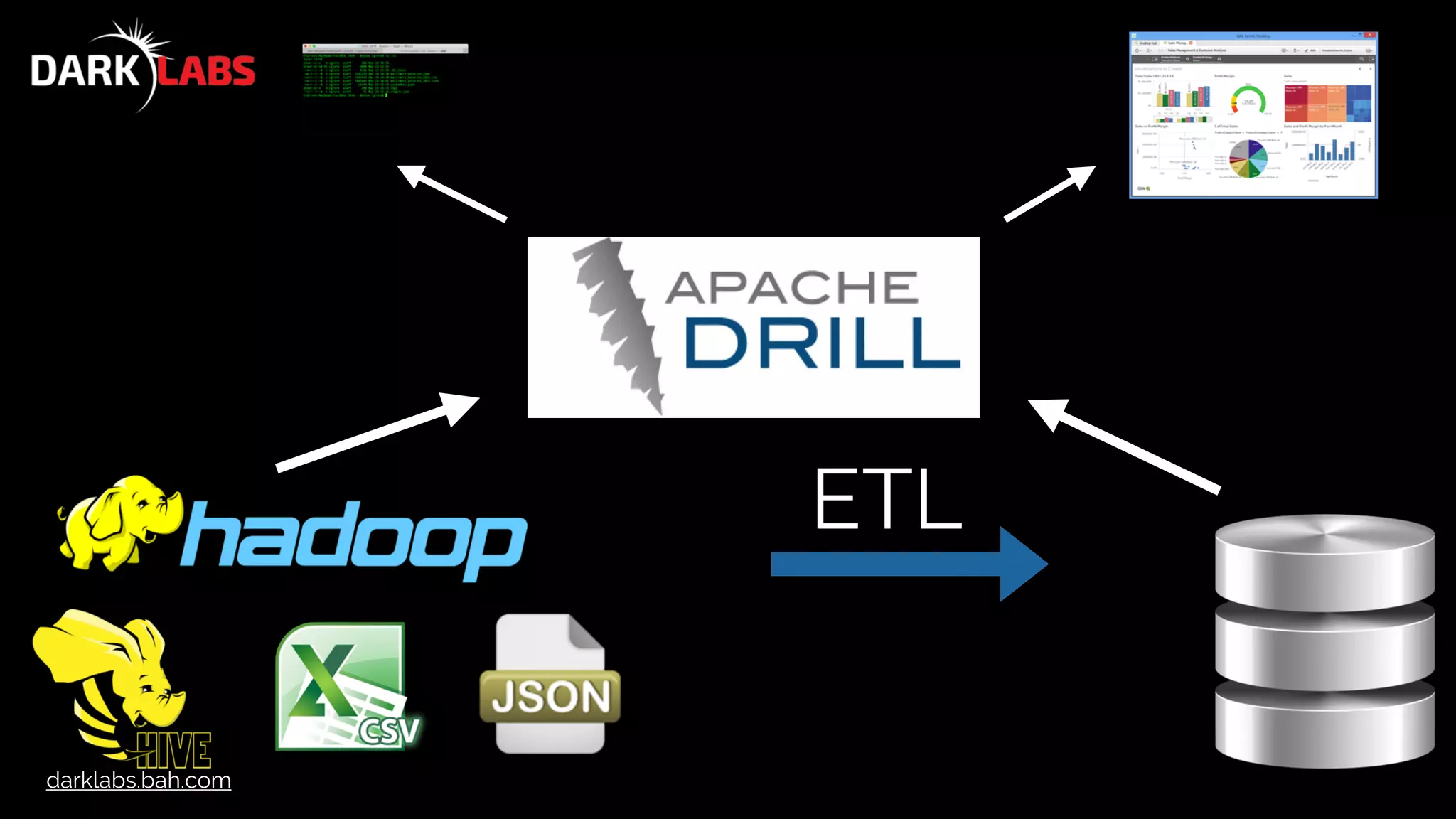
The document provides a comprehensive overview of an Apache Drill workshop led by Charles Givre, outlining its capabilities for ad-hoc data analysis without predefined schema, and demonstrating its use through practical SQL queries. It covers installation instructions, demo examples, and various queries on different data formats, including CSV and JSON, as well as exercises on data manipulation and aggregation. Additionally, it highlights functions for querying and transforming datasets, and includes code snippets for exploring both local and remote data sources.


































































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
