Download as PDF, PPTX

























![ Add missing phenomena:
V [NP1] as [NP2] – not coreferential
[use [a diagonal linear gradient] as [the map]] – is not
coreferential
[elect [John Prescott] as [Prime Minister]], – is not coreferential
…if [[ an NTSC Ø ]i or [ PAL monitor ]j]k is being used…[ The
NTSC monitor ]l… - not coreferential
…[[the pixels’ luminance]i or [Ø Ø saturation]j ]k is important…
[The pixels’ saturation]j - coreferential](https://image.slidesharecdn.com/presentation-12831923934455-phpapp01/75/Annotation-of-anaphora-and-coreference-for-automatic-processing-26-2048.jpg)






![NP coreference annotation
Used the guidelines developed by (Mitkov et. al.
2000) as the starting point,
but adapted them for our goals and texts
All the mentions need to be annotated, both definite and
indefinte NPs
Introduced coref and ucoref tags to be able to deal with
uncertainties
The government] will argue that… [[McVeigh] and [Nichols]] were [the
masterminds of [the bombing plot]]
Types of relations between an NP and its antecedent:
identity, synonymy, generalisation, specialisation and
other, but we do not annotate indirect anaphora](https://image.slidesharecdn.com/presentation-12831923934455-phpapp01/75/Annotation-of-anaphora-and-coreference-for-automatic-processing-33-2048.jpg)
![NP coreference annotation (II)
Types of (coreference) relations we identify NP, copular, apposition,
bracketed text, speech pronoun and other
Link to the first element of the chain in most of the cases for type NP
For copular, apposition, bracketed text and speech pronouns (pronouns
which occur in direct speech), the anaphor should be linked back to the
nearest mention of the antecedent in the text
Do not annotate coreferential different readings of an NP as
coreferential
[A jobless Taiwanese journalist who commandeered [a Taiwan airliner] to [China]]…
[China] ordered [[its] airports] to beef up [security]…](https://image.slidesharecdn.com/presentation-12831923934455-phpapp01/75/Annotation-of-anaphora-and-coreference-for-automatic-processing-34-2048.jpg)
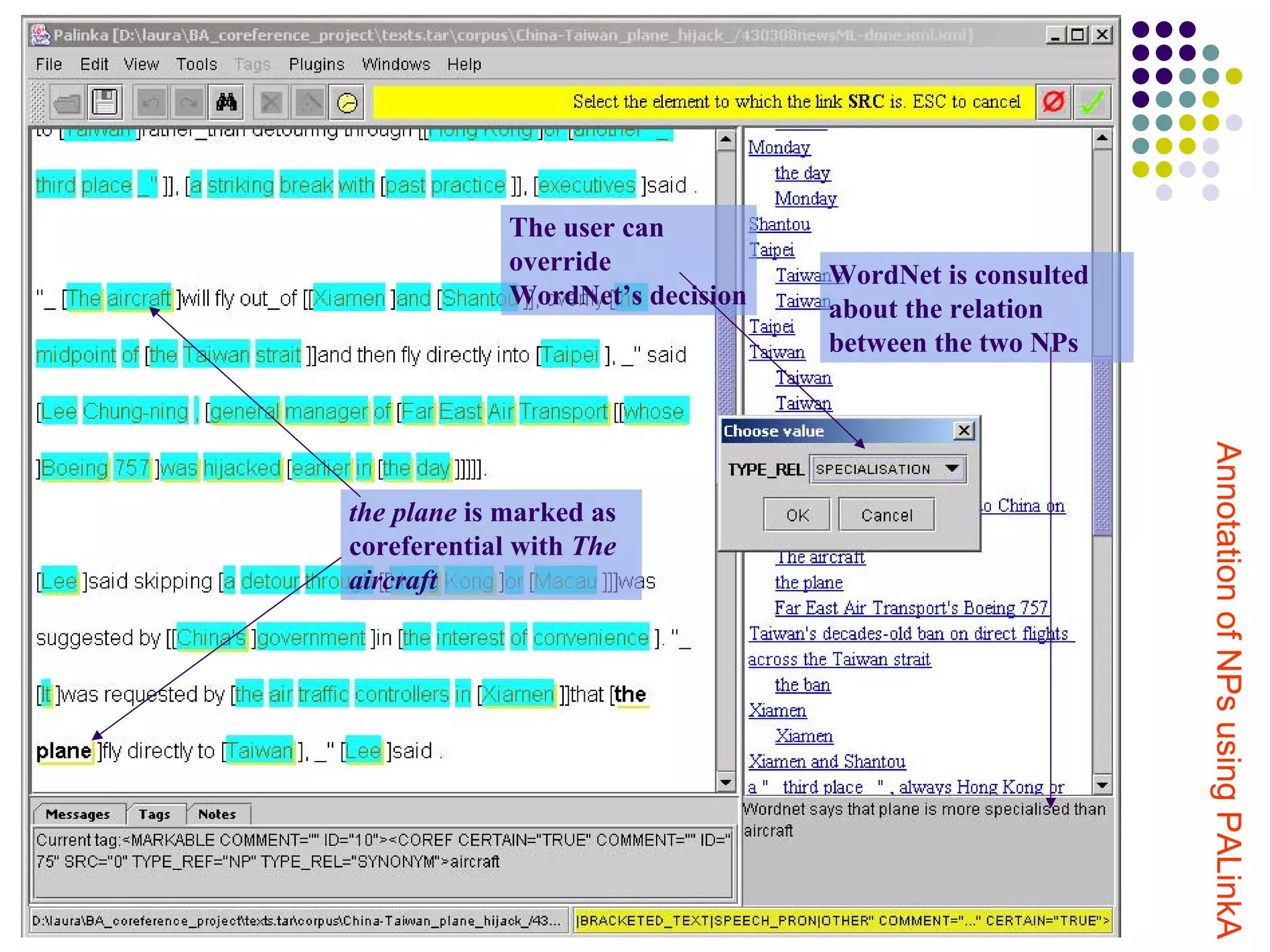
![Issues arising during the NP
annotation
The antecedent of pronoun we in direct speech can
be linked to: the individual speaker, a group
represented by the speaker or nothing
General concepts such as violence, terror, terrorism,
police, etc are sometimes used in a general sense
so it is difficult to know whether to annotate and how
Sometimes difficult to decide the best indefinite NP
as an antecedent
…the man detained for hijacking [a Taiwanese airliner]… Liu
forced [a Far East Air Transport domestic plane]… Beijing
returned [the Boeing 757]…](https://image.slidesharecdn.com/presentation-12831923934455-phpapp01/75/Annotation-of-anaphora-and-coreference-for-automatic-processing-36-2048.jpg)
![Issues arising during the NP
annotation (II)
Mark relative pronouns/clauses and link them
to the nearest mention
Chinese officials were tightlipped whether [Liu Shan-chung,
45, [who] is in custody in China's southeastern city of
Xiamen], would be prosecuted or repatriated to Taiwan.
The type of relation is sometimes difficult to
establish without the help of WordNet (have
ident, non-ident)](https://image.slidesharecdn.com/presentation-12831923934455-phpapp01/75/Annotation-of-anaphora-and-coreference-for-automatic-processing-37-2048.jpg)



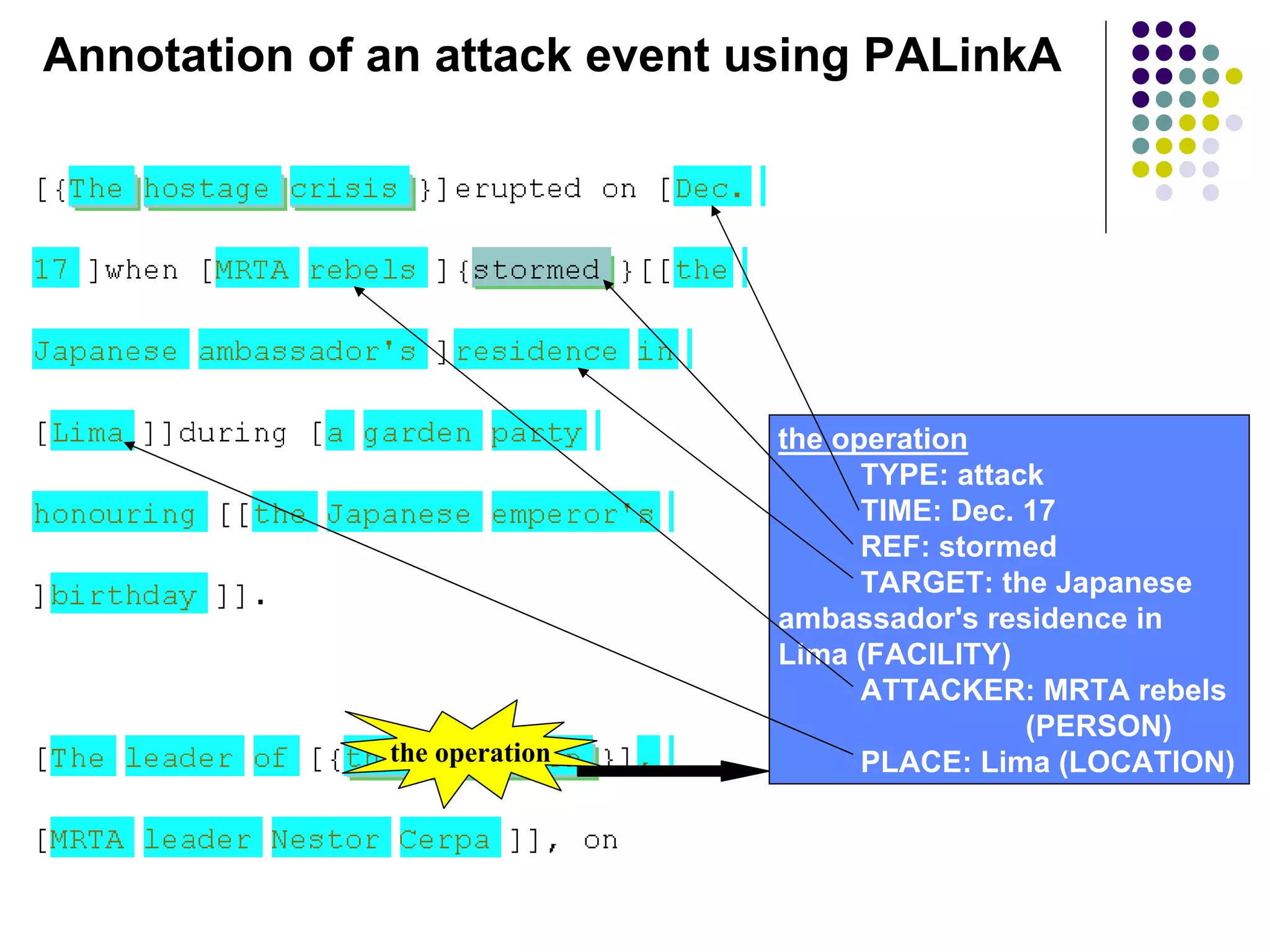












This document discusses annotation of anaphora and coreference in corpora for computational linguistics. It covers several annotation schemes including MUC, which aimed to achieve high inter-annotator agreement by focusing on coreference between noun phrases. The NP4E corpus aimed to develop guidelines for annotating both noun phrase and event coreference in newspaper articles. Annotation is a time-consuming process that requires concentration to identify mentions and relations accurately. Guidelines must be clear and consistent to help annotators agree on how to mark up texts.






















































