Downloaded 15 times








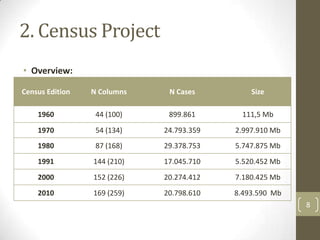

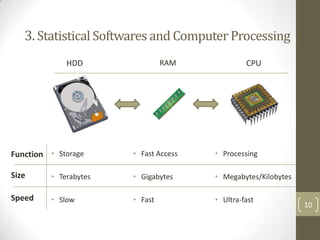

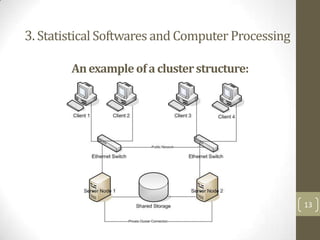






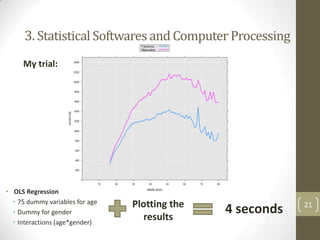












The document summarizes a presentation about analyzing large census databases using statistical software. It discusses the challenges of working with large census datasets containing over 20 million records and hundreds of variables. It describes using the R programming language to perform analyses more efficiently than other statistical packages like SPSS and Stata. Specifically, it discusses optimizing R code, using high-performance computing clusters, and improving hardware to handle big data analysis tasks that were previously too slow or memory-intensive. The presentation concludes by emphasizing the learning opportunities of the census data project and provides next steps like learning more R programming, linear algebra, and using advanced computing clusters.















































