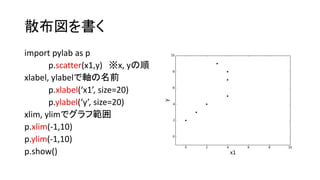
NumPyで分析
• 単回帰分析(YとX1)
次に決定係数を求める푅 = 1 −
1
푁
푁 푦푛− 푎 푥푛+푏
푛=1
2
1
푁
푁 푦푛−푦 2
푛=1
Y2temp = Y-Y.mean()
Y2 = numpy.average([float(Y2temp[i]**2) for i in range(7)])
Y1temp = [f.y[i] - (a*x1[i] + b) for i in range(7)]
Y1 = numpy.average([Y1temp[i]**2 for i in range(7)])
R = 1 – Y1/Y2 表示:
>>> R
0.62777085927770859
26.
NumPyで分析
• 重回帰分析(YとX)
핐 = 핏Βより、Β = 핏−1핐なので、
print X.I * Y
StatsModelsで求めたものと比較しても、正しいことが分かる
A = float((X.I * Y)[0])
B = float((X.I * Y)[1])
C = float((X.I * Y)[2])
と代入して進める
表示:
matrix([[ 1.40758392],
[ 0.17343556],
[ 1.61085785]])
27.
NumPyで分析
• 重回帰分析(YとX)
次に決定係数を求める푅 = 1 −
1
푁
푁 푦푛− 푎 푥1푛+푏 푥2푛+푐
푛=1
2
1
푁
푁 푦푛−푦 2
푛=1
Y2temp = Y-Y.mean()
Y2 = numpy.average([float(Y2temp[i]**2) for i in range(7)])
Y1temp = [f.y[i] - (A*x1[i] + B*x2[i] + C) for i in range(7)]
Y1 = numpy.average([Y1temp[i]**2 for i in range(7)])
R = 1 – Y1/Y2 表示:
>>> R
0.69104351997456703




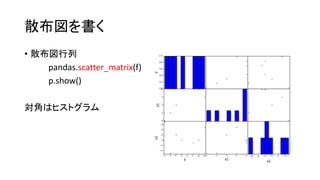
![分析する前に
• 列を代入
定数yに列yを代入するには、
y = f[‘y’] もしくは、y = f.y
とする。
print y
0 3
1 4
2 8
3 5
4 7
5 2
6 9
Name: y, dtype: int64](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-5-320.jpg)


![基本の分析
• 平均
print y.mean() 5.4285714285714288
• 合計
print y.sum() 38
• 最頻値
print y.mode() []
• 中央値
print y.median() 5.0
• 分散
print y.var() 6.9523809523809534](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-8-320.jpg)



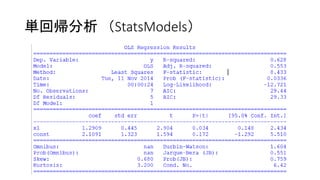
![単回帰分析(StatsModels)
• 決定係数
上段のR-squaredというのが決定係数
サマリを表示させずとも、print result.rsquaredで表示可能
• 回帰係数
中段のcoefと言う部分が回帰係数
この例でいうと、푦 = 1.2909푥1 + 2.1091ということ
サマリを表示させずとも、print result.paramsで表示可能
例) print 'y = {0}x1 + {1}'.format(result.params[0], result.params[1])
表示: y = 1.29090909091x1 + 2.10909090909](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-15-320.jpg)
![単回帰分析(StatsModels)
• 回帰係数を使って、散布図に回帰直線を書く
前の「散布図を書く」スライドで、p.show()をする前に以下をつけたす
p.plot(x1, result.params[0]*x1+result.params[2])
p.text(0,0,'y = {0:.4f}x1 + {1:.4f}'.format(result.params[0],
result.params[1]), size=20)
そしてp.show()をすると右のようになる](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-16-320.jpg)
![重回帰分析(StatsModels)
• StatsModelsではなく、Pandasのみで相関係数行列を表示できる
print f.corr()
• 分析するデータを指定する
X = f[[‘x1’,’x2’]]
Y = f.y
• 単回帰分析時と同様に定数項を追加する
X = sm.add_constant(X, False)](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-17-320.jpg)

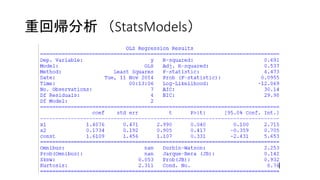
![重回帰分析(StatsModels)
• 決定係数
上段のR-squaredというのが決定係数
サマリを表示させずとも、print result.rsquaredで表示可能
• 回帰係数
中段のcoefと言う部分が回帰係数
この例でいうと、푦 = 1.4076푥1 + 0.1734푥2 + 1.6109ということ
サマリを表示させずとも、print result.paramsで表示可能
例) print 'y = {0}x1 + {1}x2 + {2}'.format(result.params[0], result.params[1],
result.params[2])
表示: y = 1.40758392043x1 + 0.173435557397x2 + 1.61085785329](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-20-320.jpg)
![NumPyで分析
• こちらは、StatsModelsとは違ってパッと計算できない
(宿題で分析手順を追うなら、こちらの方が適している)
• NumPyのメソッド
• numpy.matrix(list) リストを行列に変換する
Y = numpy.matrix(y)
X1 = numpy.matrix([[x1,[1]*7]])
X = numpy.matrix([[x1,x2,[1]*7]])
X1とXの後ろの[1]*7は定数項
(x1,x2のデータ数が7だから)
>>> Y
matrix([3, 4, 8, 5, 7, 2, 9], dtype=int64)
>>> X1
matrix([[1, 2, 4, 4, 4, 0, 3],
[1, 1, 1, 1, 1, 1, 1]], dtype=int64)
>>> X
matrix([[ 1, 2, 4, 4, 4, 0, 3],
[-5, 2, 0, 0, -1, 7, 5],
[ 1, 1, 1, 1, 1, 1, 1]], dtype=int64)](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-21-320.jpg)

![NumPyで分析
>>> Y
matrix([[3],
[4],
[8],
[5],
[7],
[2],
[9]], dtype=int64)
>>> X1
matrix([[1, 1],
[2, 1],
[4, 1],
[4, 1],
[4, 1],
[0, 1],
[3, 1]], dtype=int64)
>>> X
matrix([[ 1, -5, 1],
[ 2, 2, 1],
[ 4, 0, 1],
[ 4, 0, 1],
[ 4, -1, 1],
[ 0, 7, 1],
[ 3, 5, 1]], dtype=int64)](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-23-320.jpg)
![NumPyで分析
• 単回帰分析(YとX1)
푦 = 푎푥1 + 푏 =
푎
푏
푥1
1
より、
푎
푏
=
푥1
1
−1
푦なので、
逆行列を求めるメソッドIを用いて、
print X1.I * Y
StatsModelsで求めたものと比較しても、正しいことが分かる
a = float((X1.I * Y)[0])
b = float((X1.I * Y)[1])
と代入して進める
表示:[[ 1.29090909]
[ 2.10909091]]](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-24-320.jpg)
![NumPyで分析
• 単回帰分析(YとX1)
次に決定係数を求める푅 = 1 −
1
푁
푁 푦푛− 푎 푥푛+푏
푛=1
2
1
푁
푁 푦푛−푦 2
푛=1
Y2temp = Y-Y.mean()
Y2 = numpy.average([float(Y2temp[i]**2) for i in range(7)])
Y1temp = [f.y[i] - (a*x1[i] + b) for i in range(7)]
Y1 = numpy.average([Y1temp[i]**2 for i in range(7)])
R = 1 – Y1/Y2 表示:
>>> R
0.62777085927770859](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-25-320.jpg)
![NumPyで分析
• 重回帰分析(YとX)
핐 = 핏Βより、Β = 핏−1핐なので、
print X.I * Y
StatsModelsで求めたものと比較しても、正しいことが分かる
A = float((X.I * Y)[0])
B = float((X.I * Y)[1])
C = float((X.I * Y)[2])
と代入して進める
表示:
matrix([[ 1.40758392],
[ 0.17343556],
[ 1.61085785]])](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-26-320.jpg)
![NumPyで分析
• 重回帰分析(YとX)
次に決定係数を求める푅 = 1 −
1
푁
푁 푦푛− 푎 푥1푛+푏 푥2푛+푐
푛=1
2
1
푁
푁 푦푛−푦 2
푛=1
Y2temp = Y-Y.mean()
Y2 = numpy.average([float(Y2temp[i]**2) for i in range(7)])
Y1temp = [f.y[i] - (A*x1[i] + B*x2[i] + C) for i in range(7)]
Y1 = numpy.average([Y1temp[i]**2 for i in range(7)])
R = 1 – Y1/Y2 表示:
>>> R
0.69104351997456703](https://image.slidesharecdn.com/r-141112110410-conversion-gate01/85/Analyze-by-StatsModels-or-Numpy-27-320.jpg)























































![[第2版]Python機械学習プログラミング 第10章](https://cdn.slidesharecdn.com/ss_thumbnails/10-181212011917-thumbnail.jpg?width=640&height=640&fit=bounds)


