Download to read offline




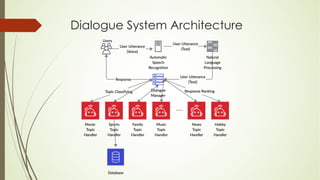




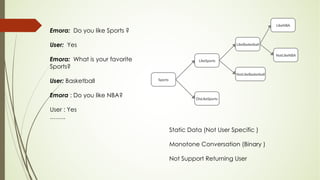

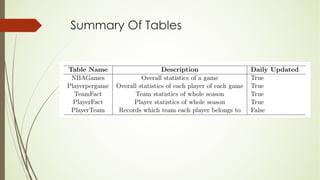






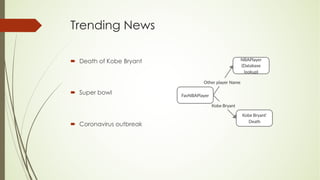
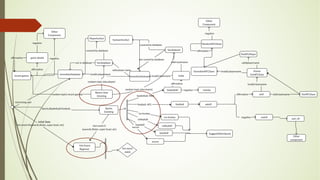













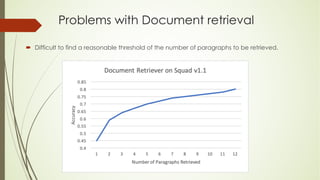





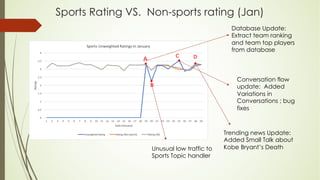
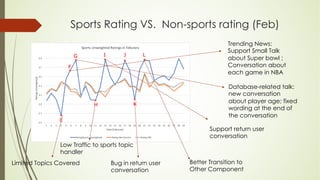
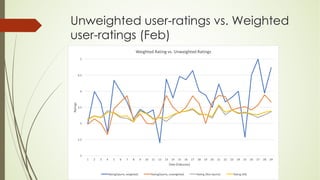
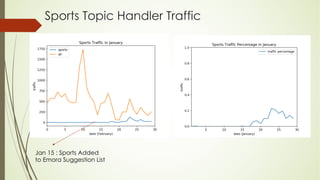
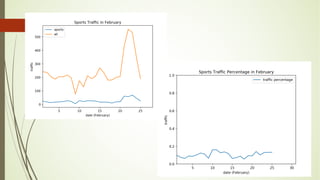
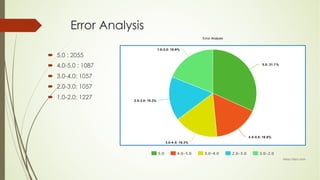







This document analyzes a state machine-based dialogue management system for a conversational agent. It discusses using state machines to control conversation flow, with a sports-focused database to enable real-time fact-based discussions. Quantitative analysis showed updates to the sports component's database and conversation logic correlated with higher user ratings, while bugs correlated with lower ratings. Qualitative analysis found errors occurred from uncovered topics, bugs, and ignoring user responses. The study concludes associating state machines with databases can improve dialogue quality but requires effort, while open-domain question answering is not suitable due to latency issues.













![[IJET-V2I2P5] Authors:Mr. Veer Karan Bharat1, Miss. Dethe Pratima Vilas2, Mis...](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v2i2p5-160427184225-thumbnail.jpg?width=640&height=640&fit=bounds)





















































