The document evaluates the performance of the Riak key-value database in handling big data clusters using the Basho-bench benchmarking tool. It discusses the challenges of managing large volumes of structured and unstructured data, the advantages of NoSQL databases over traditional relational databases, and the specifications for benchmarking. The study aims to measure throughput and latency across various workloads and data sizes, providing insights into the effectiveness of Riak in a distributed database environment.
![Intelligent Automation And Soft Computing, 201X
Copyright © 201X, TSI® Press
Vol.XX,no.X,1–9
CONTACT Corresponding Author correspondingauthor email
© 201X TSI® Press
Analysis andEvaluationof Riak KV Cluster Environment Using Basho-
bench
AimenMukhtar Rmis, Ahmet ErcanTopcu
Department of Computer Engineering, Ankara Yıldırım Beyazıt University
KEY WORDS: NoSQL database, Big data, Riak, Basho-bench, Cluster
1 INTRODUCTION
DATA is exploding at an alarming rate due to
increase in many fields of business, experimental
knowledge, social media and academics. Due to this
large size of dataو it is hard to make information
discovery and decision making in efficient time.
According to the international data corporation report,
it has been predicted that digitaldata could growby 40
times from 2012 to 2020, and it is of utmost
significance that we developtoolsto handle sucha huge
volume of evolving data [2,15].
Today,the amountsofbig datathatcan be managed
by NoSQL systems, like Riak, outstrip what can be
managed by the largest relationaldatabasemanagement
system (RDBMS). NoSQL databases are essentially
created fromthe ground upto require less management
like data distribution, automatic repair, also simpler
data models lead to lower administration [3]. NoSQL
databases essentially use clusters of cheap commodity
servers to handle the exploding data also transaction
volumes, while relational databases tend to rely on
expensive proprietary servers and storage systems.
When using NoSQL, the cost per gigabyte or
transaction persecond forNoSQL can be many times
less than the cost for RDBMS, permitting you to save
and the process more data at a much lower price [1].
NoSQL Key Value ( KV) stores, as well as
document databases, let the application to save
practically any structure it needs in a data element.And
rigidly determined BigTable-based NoSQL databases
(Cassandra,HBase)typically allownewcolumns to be
created withouttoomuch confusion.A large numberof
NoSQL offerings consequently lead to the problemof
differentiating between these offerings and their
suitability in different circumstances [7].
In this study, we test and evaluate the Riak key-
value database for big data clusters using the Basho-
bench benchmark, a benchmarking tool created to
conduct accurate and repeatable performance testsand
stress tests and produce performance graphs.
This paper aims to accomplish the following:
• To generate a fictitious workload and a data
access pattern on the clusterthat matchesthe
workloads of real-world applications and
monitor its performance.
• Observe the performance of Riak KV with
large data volumes and various workloads
(read, write, update, mixof read update).
ABSTRACT
Many institutions and companies with technological development have been
producing large size of structured and unstructured data. Therefore, we need
special databases to deal with these data and thus emerged NoSQL databases.
They are widely used in the cloud databases and the distributed systems. In the
era of big data, those databases provide a scalable high availability solution. So
we need new architectures to try to meet the need to store more and more
different kinds of different data. In order to arrive at a good structure of large
and diverse data, this structure must be tested and analyzed in depth with the
use of different benchmark tools. In this paper, we experiment theRiak key-value
database to measure their performance in terms of throughput and latency,
where huge amounts of data are stored and retrieved in different sizes in a
distributed database environment. Throughput and latency of the NoSQL
database over different types of experiments and different sizes of data are
compared and then results were discussed.](https://image.slidesharecdn.com/analysisandevaluationofriakkvclusterenvironmentusingbasho-bench-181205111821/75/Analysis-and-evaluation-of-riak-kv-cluster-environment-using-basho-bench-1-2048.jpg)
![2 AUTHOR (All CAPS)
• To monitor the performance of the Riak KV
(Throughput, Latency) when data is being
read, write and update operation.
The rest of this paper is organized as follows:
Section 2 we present background and basic concepts.
Section 3 takes a deeperlookat related works. Section
4 provides an overviewofRiak KV NoSQL databases
system and its infrastructure. Section 5 is about the
Basho bench benchmarking of Riak KV. Section 6
presents the experiment environment for testing the
Riak KV NoSQL database with the Basho bench.
Section 6 provides our experimental results and
discussion. Section 7 concludes the paper.
2 BACKGROUND AND BASIC CONCEPTS
IN this section,the basic conceptsrelated to the big
data, NoSQL database properties will be introduced.
The challengesassociatedwith big data and NoSQLare
also introduced.
2.1 Big data
In this part, we will describe the termbig data that is
very related with NoSQL database systems. Big data
can be defined as the capability of managing a huge
volume of data within the right time and properspeed.
Big data is an evolving term that describes any
voluminous amount of structured, semi structured and
unstructured data thathas the potentialto be mined for
information,which cannot be managedusing relational
database management systems (RDBMs). [6,8]
Every day, new data is created from a variety of
sources,includingsocialnetworks,photos,videos,and
more. Due to the rapid growth of data, it has become
very difficult to process this data through the available
database managementsystem.One ofthe solutions that
have beenproposedto overcome thefastgrowth ofdata
has been applying better hardware; however, this
approach has not been sufficient as the hardware
enhancement reached a point where the growth ofdata
volume outpacescomputerresources[5].Now,big data
could be found in three forms:
Structured-Anydata thatcan bestored,accessed
and processed in the form of fixed format is
termed as a 'structured'data.Overtime, talent in
computer science have achieved greater success
in developing techniques for working with such
kind of data (where the format is well known in
advance)and also derivingvalue out ofit.There
are two sourcesthat providestructureddata:data
generatedby human intervention suchas gaming
data and inputdata.The second sourceis the data
generated by machines such as sensor data, web
log data and financial data. [8,9]
Unstructured data-Before the current ubiquitous
of online and mobile applications, databases
processeddirect,structured data.The data forms
were almost simple and described a set of
relationships between various data types in the
database. In contrast, unstructured data refers to
data that is not fully suited to the traditional
column and row structure of a relational
database. In today's big data world, most of the
data createdare unstructured,and some estimates
that it is more than 95% ofalldata generated.[29]
Semi-structured data- This data combines
structured and unstructured data. Dealing with
this levelofdata complexity is not easy.Big data
and extensive records lead to long-running
queries; So, we need new methods and
techniques to overcome this challenge and
manage large amounts of data.[14]
2.2 Nosql
The term NoSQL ("Not only SQL") is the term that
describes the entire class of databases which do not
have the characteristics of traditional relational
databases and forwhich standard query SQL language
is not generally used.NoSQLdatabases are considered
to be the next generationdatabases andIt supportshuge
data storage, horizontally scalable, open source,
distributed databases and massive- parallel data
processing.Theyare characterized bya less strict static
data structure,simple support to replicationand simple
application programming interface. They are often
related to large data sets that need to be quickly and
efficiently accessed andchanged on the Web. [11,10]
NoSQL databases can be classified into four
categories.
Key-Value (KV)- In general, NoSQL
databases allow the use of various types of
relational data tools. These are becoming
common in new business plans and big data
analysis in which classified data should be
stored in a practicalandefficient manner[16].
Within this context,key-value store databases
are the simplest NoSQL databases. They can
help developers in the absenceofa predefined
schema.Different kinds ofobjects,datatypes,
and data containers and are used to
accommodate this [17,15].High query speed
with a simple structure,where KV is the data
model, supports benefits such as high
concurrency and mass storage. Data
modification and query operations are well
supportedthroughprimary keys,suchas Riak
KV [18] and Redis [19].
Column-oriented- A table in a column-
oriented database can be used for the data
model; however, This stores tables of
extensible records. It includes columns and
rows, which may be shared through being
divided overnodes. In general,the benefit of
this data model is a more appropriate
application on aggregation and data](https://image.slidesharecdn.com/analysisandevaluationofriakkvclusterenvironmentusingbasho-bench-181205111821/75/Analysis-and-evaluation-of-riak-kv-cluster-environment-using-basho-bench-2-2048.jpg)
![INTELLIGE NT AUTOMATIO N AND SOFT COMP UTING 3
warehouses, HBase [20] and Cassandra [21]
are an example of this kind of data store.
Documents data stores- Also known as a document-
oriented database, this programis used to retrieve, store
and manage information. The data is semi-structured
data. The documents database can usually use the
secondary index to facilitate the value of the upper
application; however. The Key Value and document
database structures are very similar, they differ in how
they processdata.It was named by that name fr from the
manner of storing. So that the data is stored documents
in XML or JSON format [22,23]. Couch and MongoDB
dB [24] are examples of documents data.
GraphDatabases-A graphdatabase comprises nodesthat
are connected by edges. Data can be stored in edges and
nodes. One advantage of a graph database is that it can
traverse relationships very quickly. Similar to the other
three types ofNoSQL databases mentioned above,graph
databases have some problems with horizontal scaling.
This is why every node can connect to any other node.
Traversing nodeson variousphysicalmachines can have
a negative effect on performance. Another difference
from the above three is that most graphics databases
support ACID (atomicity, consistency, isolation, and
durability)transactions.Graph databases are oftenusedto
dealwith complexissuessuch associalnetworks orpath-
finding problems [25], such as Neo4j [26].
3 RELATED WORK
THERE have been numerous papers, researches, blogs, that
test and evaluate NoSQL database to discuss various features
such as their benefits, and find the suitable NoSQL database,
such as that by Ali Hammood et al. [9], this research examines
the more recent versionsofthesystems.Forthis purpose,was set
up a testing environment for each workload and monitor the
responses for the Cassandra, HBase, and MongoDB database
systems.accordingto the resultsobtained,HBase andCassandra
worked very well under heavy loads. MongoDB worked very
well with low throughput,but not as well with high throughput.
In the read operation, HBase has lower performance. And the
latency for them is lower than before for all operations,
particularly in MongoDB. Lazar J. Krstić et al. [11], was used
YCSB tool fortesting the performanceoffive NoSQLdatabases:
BrightstarDB,LevelDB, HamsterDB,RavenDB and STSdb
4.0.Database benchmark, a tool that was used to perform the
measurement itself, was selected to manage the NoSQL
databases running in various ways at approximately the same
level, so that the obtained measurement results could be almost
realistically compared.The authors reported that HamsterDBhas
the best performance, while the worst is BrightstarDB. This
conclusion was expected before the start of the actual
performance measurement.In the study by Kuldeep Singh [12],
compared Riak, HBase,Cassandra andmongo dBfromdifferent
views.the experiments to compare andevaluatethe performance
of different NoSQL datastores on a distributed clusterusedycsb
to test theperformances ofthesefoursystems usingthesame test
environment andapplying different workloads on thesesystems.
A summary of the results of this thesis concluded that each
systemhas a different response whenapplyinga workload due to
the differences in designs.
Abramova et al. [13], tested the performance of
Cassandra based on a numberof factors,including the
number of nodes, workload characteristics, number of
threads,and data size,and analyzed whether it provides
the desired acceleration and scalability attributes.
Scaling nodes and the number of data-sets do not
guarantee performance. However, Cassandra handles
concurrent request threads well and extends well with
concurrent threads. A summary of the results of that
paper concluded that when the number of nodes in a
cluster has increased from 1, or 3 to 6, even for
relatively large data sets,this trendcannot guarantee an
improvement in performance.
The authors of[29] showed a method and the results ofa
research that selected between three NoSQL databases
systems for a large, distributed healthcare society. The
performance assessment methods andresults are displayed
to the following databases: MongoDB, Cassandra and
Riak. The test was based on the YCSB benchmark for
evaluating NoSQLdatabases.The paper's summary ofthe
results concludes that theCassandradatabase providesthe
best throughput performance with the highest latency.
4 RIAK KEY-VALUE (KV)
RIAK is an open-source enterprise version of Riak
Enterprise DS. It is a KV database developedby Bashoin
2007 and written in Erlang and C. The enterprise version
adds multi-data center replication, monitoring, and
additional support [22].
Riak KV is a distributed NoSQL database that is
extremely scalable,available,and straightforwardto work
with.It automatically assigns the data in a clustertoensure
quick performance and fault tolerance. Riak Enterprise
includes multi-cluster replication that guarantees low
latency and strong business continuity. Riak KV is an
appropriateddistributedNoSQLKV databasethatensures
read and write functions even in cases ofhardware failure
or network partitions by supporting both local and multi-
clusterreplication.Riak KV is designed to workand deal
with an assortment of difficulties confronting big data
applications that incorporate following client or session
data,storing data fromconnected devices,and replicating
data aroundthe world.It is designedwith KVto provide a
powerful, simple data model to store large amounts of
unstructured data [22,18].
Riak KV achieves fastperformance androbustbusiness
continuity by automating data distribution across the
cluster, where there is easily added capacity without a
large operationalburdenwith a masterless architecture that
guarantees high availability and scales that are nearly
linear using commodity hardware [18]. Nodes in Riak
form a cluster. This cluster is isolated into partitions and](https://image.slidesharecdn.com/analysisandevaluationofriakkvclusterenvironmentusingbasho-bench-181205111821/75/Analysis-and-evaluation-of-riak-kv-cluster-environment-using-basho-bench-3-2048.jpg)
![4 AUTHOR (All CAPS)
virtual nodes (Vnodes) to form a ring to obtain all the
benefits of Riak. The ring is a 160 bit integer space
separated into a similarly sized partitions, as shown in
Figure 1.
Figure 1. Architectureofthe Riak cluster.
Each node (also called a physicalnode)in the ring runs
a certain number of virtual nodes (Vnodes). Each
Vnode occupies one partition in the ring.It defines the
partition size of the ring when configuring Riak or
when the cluster is initialized [27].
5 BENCHMARKING OF NOSQL
THE Basho-bench is a benchmarking tool was
created to conduct accurateandrepeatable performance
tests and stress tests and produce performance graphs.
Originally developed to benchmark Riak, it exposes a
pluggable driver interface and has been extended to
serve as a benchmarking tool across a variety of
projects. Basho-bench focuses on two metrics of
performance throughput and latency [28].
How Does the Benchmark Work?
Each node can be either a traffic generator or a Riak
node.A traffic generatorrunsonecopyofBasho-bench
that generates and sends commands to Riak nodes. A
Riak node contains a complete and independent copy
of the Riak package which is identified by an Internet
Protocol (IP) address and a port number. Figure 2
shows how traffic generators and Riak nodes are
organized inside a cluster.There is one traffic generator
for every three Riak nodes [4].
Figure 2. Riak Nodesand Traffic Generatorsin Basho-bench.
Appendix
6 EXPERIMENT ENVIRONMENT
6.1 Experimental Setup
IN this part, we will introduce the results of
experiments realized by the testing of the Riak KV
NoSQL database with the Basho-bench. The
benchmark is specifically designed for Riak
performance test andanalysis. Riakbenchmarkis done
using the Basho ́s measurement software that defines
the number of transactions per seconds executed per
second. The benchmark needs a configuration file,
which contains the required parameter to begin the
benchmark. It executes the given number of workers
that togetherperformthe given task.The test was done
with a different number of keys (10 K,100 K,1000 K,
10,000 K, and 200,000 K), and the fixed size of 10000
KB every key.
The experiments were performed in the following
environment using 5 nodes of the cluster with 16 GB
RAM,Intel®-Xeon(R)-CPU E3 1241 v3-@ 3.50 GHz
× 8 processor speed and 1TB of ephemeral storage in
each unit.Ubuntu 14.0.4 LTS (64-bit) was installed on
each unit.Figure 3illustrates the experimentalstructure
containing details of the primary components.](https://image.slidesharecdn.com/analysisandevaluationofriakkvclusterenvironmentusingbasho-bench-181205111821/75/Analysis-and-evaluation-of-riak-kv-cluster-environment-using-basho-bench-4-2048.jpg)
![5 AUTHOR (All CAPS)
Figure 3. Experimental structure.
6.2 Performance Configuration
THE Basho-benchis a test toolto performreads,updates and
writes based on workload and measure performance. The
possible operations that the driver will run, such as
[{get,4},{put,4},{delete, 1}], which means that out of every 9
operations, get will be called four times, put will be called four
times,and delete will be called once,on average.The benchmark
package gives a set of predetermined experiment s that can be
executed as follows:
Experiment#A-Updatesare heavy.It consists ofa 1/1
proportion of reads and updates.
Experiment #B- Reads mostly. It consists of a 9/1
proportion of reads/updates.
Experiment#C-Reads only.The workload is 1/ read.
To evaluate theloadingtime,we generated a different numberof
keys (10 K,100 K,1000 K, 10,000 K, and 200,000 K), and a
varying number of threads (4, 8, and 12).
7 EXPERIMENTAL RESULTS AND DISCUSSION
In the following, we assign a section to each experiment,
which describesthe differentscenario experiments between read
and an update, also the results are illustrated in that.
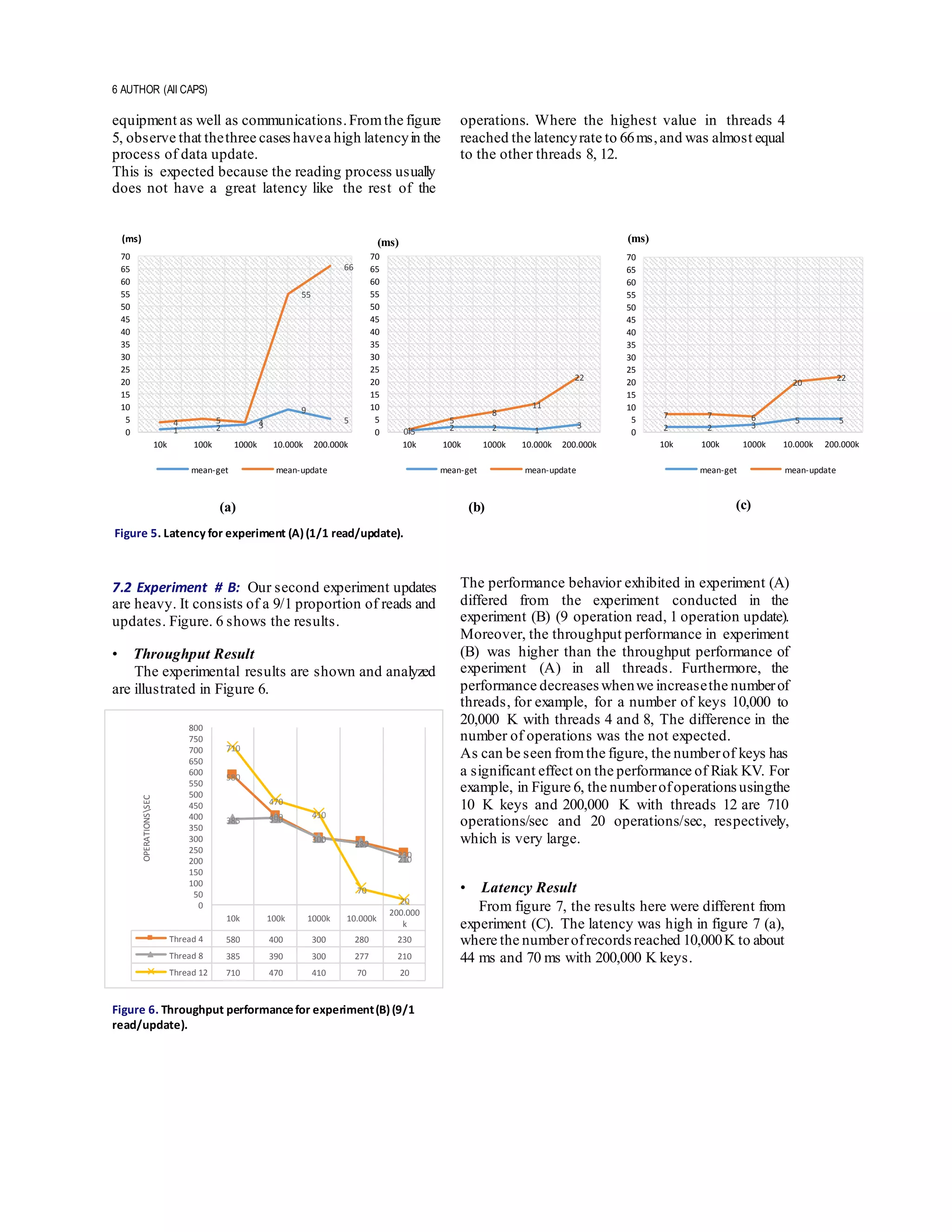
7.1 Experiment #A: Updates are heavy. It consists of a 1/1
proportion of reads and updates. Figure. 3 shows the results.
• Throughput Result
Figure 4. Throughput performancefor experiment(A)(1/1
read/update).
We notice fromthe figure 4 with thread 8that when
the numberofkeys in the clusterincreased from100 K
to 1000 K, the throughput performance was similar
(190 operation).However,whenthe numberof keys is
10 K, the performance was high (250 operations).The
overallcase if thread 12, performance was very high in
all records compared to other threads.
• Latency Results
Latency is the delay from the input systemto the
desired result; in each case, the term is understood
slightly differently,andthe latencyproblems varyfrom
system to different. Latency greatly affects the
enjoyable and usable of electronic and mechanical
10k 100k 1000k 10,000k 200,000k
Thread 4 340 320 200 30 20
Thread 8 250 190 190 60 10
Thread 12 590 400 420 80 100
340
320
200
30 20
250
190 190
60
10
590
400
420
80
100
0
50
100
150
200
250
300
350
400
450
500
550
600OPERATIONSSEC](https://image.slidesharecdn.com/analysisandevaluationofriakkvclusterenvironmentusingbasho-bench-181205111821/75/Analysis-and-evaluation-of-riak-kv-cluster-environment-using-basho-bench-5-2048.jpg)
![8 AUTHOR (All CAPS)
Figure 10. Comparing thethroughput of three experiment A, B and C.
8 CONCLUSION
IN this paper, we tackle analysis and evaluation of
the read/update throughput aswellas the latency ofRiak
KV NoSQL database management systems cluster
environment.To achieve this goal,Basho-bench is used.
Benchmarking the NoSQL data stores in the perspective
of the cluster environment and monitor factors such as
throughput, latency are important requirements as there
exists a difference of NoSQL databases and its utility
differs from one application to another. In addition,
system performance is still an important factor when
processing large amountsofdata.We did measurements
on three experiments ofa different numberofoperations;
experiment A,B and C.We measuredthe readthroughput
and latency of each of the experiments, and the update
throughput and latency. We found that the performance
is affected significantly by increased data size. We also
found that with the increasein the numberofthreads,the
throughput performance is better and the latency factor
reduced.
REFERENCES
[1] Rakesh Kumar, Shilpi Charu, Somya
Bansal.”Effective Way to Handling Big Data Problems
using NoSQL Database (MongoDB)”. Journal of
Advanced Database Management & Systems ISSN:
2393-8730 (online) Volume 2, Issue 2 .2015.
[2] Rakesh K. Lenka and et al.,”Comparative
Analysis ofSpatialHadoopandGeoSparkforGeospatial
Big Data Analytics”, Published in: 2016 2nd
International Conference on Contemporary Computing
and Informatics (IC3I). Date of Conference: 14-17 Dec.
2016.
[3] Anasuya N Jadagerimath1 and Dr. Prakash. S.
“Efficient IoT Data ManagementforCloud Environment
using MongoDB”.Proc. ofInt. Conf.on Current Trends
in Eng., Science and Technology, ICCTEST .2017
[4] Amir Ghaffari ,Natalia Chechina,PhilTrinder,Jon
Meredith (Sep 2013) Scalable Persistent Storage for
Erlang: Theory and Practice, Twelfth ACM SIGPLAN
Workshop on Erlang, Boston, MA, USA.
[5] “Challenges and Opportunities with Big Data”.
CRA.org. Retrieved Jan 2016.
[6]. "Big data fordummies",Dr. Fern Halper,Marcia
Kaufman, Judith Hurwitz, Alan Nugent 2013.
[7] Raj R. Parmar and Sudipta Roy.”MongoDBas an
Efficient Graph Database: An Application of Document
Oriented NOSQL Database”. Data Intensive Computing
Applications for Big Data.2018
[8]
https://www.webopedia.com/TERM/B/big_data.html
[9] A Comparison of NoSQL Database Systems: A
Study on MongoDB, Apache Hbase, and Apache
Cassandra
[10] NoSQL Databases: Critical Analysis and
Comparison
0
200
400
600
800
1000
1200
1400
1600
1800
2000
operationssec
NUMBER Of KEYS
12 Thread
8 Thread
4 Thread
A B C
10 K
A B C
100 K
A B C
1000 K
A B C
10,000 K
A B C
200,000K](https://image.slidesharecdn.com/analysisandevaluationofriakkvclusterenvironmentusingbasho-bench-181205111821/75/Analysis-and-evaluation-of-riak-kv-cluster-environment-using-basho-bench-8-2048.jpg)
![INTELLIGE NT AUTOMATIO N AND SOFT COMP UTING 9
[11] TESTING THE PERFORMANCE OF NoSQL
DATABASES VIA THE DATABASE BENCHMARK
TOOL
[12] Survey ofNoSQLDatabase Engines forBig Data
[13] V. Abramova,J. Bernardino,P. Furtado.(2014).
Which NOSQL database? A performance overview. In
Paper presented at Open Journal Databases, Volume 1,
Issue 2, pp. 17-24.
[14]
https://www.techopedia.com/definition/28802/semi-
structured-data
[15] Jing Han, Haihong E, Guan Le,Jian Du. Survey
on NoSQL Database. (2011). In IEEE 6th International
Conference on Pervasive Computing and Applications
(ICPCA).
[16] Asadulla Khan Zaki. (2014). NoSQL databases:
new millennium database for big data, big users, cloud
computing and its security challenges. IJRET:
International Journal of Research in Engineering and
Technology. Volume: 03 Special Issue.
[17] Techopedia [Online]. 2018, Retrieved from:
https://www.techopedia.com/definition/26284/key-
value-store.
[18] Riak-kv database[Online].2018,Retrieved from:
http://basho.com/products/riak-kv/
[19] Redis database [[Online]. 2018, Retrieved from:
https://redis.io/ .
[20] Hbase database [Online]. 2018, Retrieved from:
http://hbase.apache.org/.
[21] Cassandra database [Online]. 2018, Retrieved
from: http://cassandra.apache.org/.
[22] Man Qi. Digital Forensics and NoSQL
Databases. (2014). In IEEE 11th International
Conference on Fuzzy Systems and Knowledge
Discovery.
[23] Jing Han, Haihong E, Guan Le,Jian Du. Survey
on NoSQL Database. (2011). In IEEE 6th International
Conference on Pervasive Computing and Applications
(ICPCA).
[24] MongodB database [Online]. 2018, Retrieved
from: https://www.mongodb.com/.
[25] Man Qi. Digital Forensics and NoSQL
Databases. (2014). In IEEE 11th International
Conference on Fuzzy Systems and Knowledge
Discovery.
[26] Neo4j database [Online].2018, Retrieved from:
https://neo4j.com/
[27]Yousaf Muhammad. (2011). Evaluation and
Implementation of Distributed NoSQL Database for
MMO Gaming Environment. Uppsala University,
Retrieved from:
http://uu.divaportal.org/smash/get/diva2:447210/FUL
LTEXT01.pdf.
[28] https://github.com/basho/basho_bench.
[29] John Klein, Ian Gorton, Neil Ernst, Patrick
Donohoe, Kim Pham, and Chrisjan Matser. (2015).
Performance Evaluation of NoSQL Databases: A Case
Study. In Proceedings of the 1st Workshop on
Performance Analysis ofBig Data Systems (PABS ’15).
ACM, New York, NY, USA, pp. 5-10.](https://image.slidesharecdn.com/analysisandevaluationofriakkvclusterenvironmentusingbasho-bench-181205111821/75/Analysis-and-evaluation-of-riak-kv-cluster-environment-using-basho-bench-9-2048.jpg)
































































