Downloaded 39 times


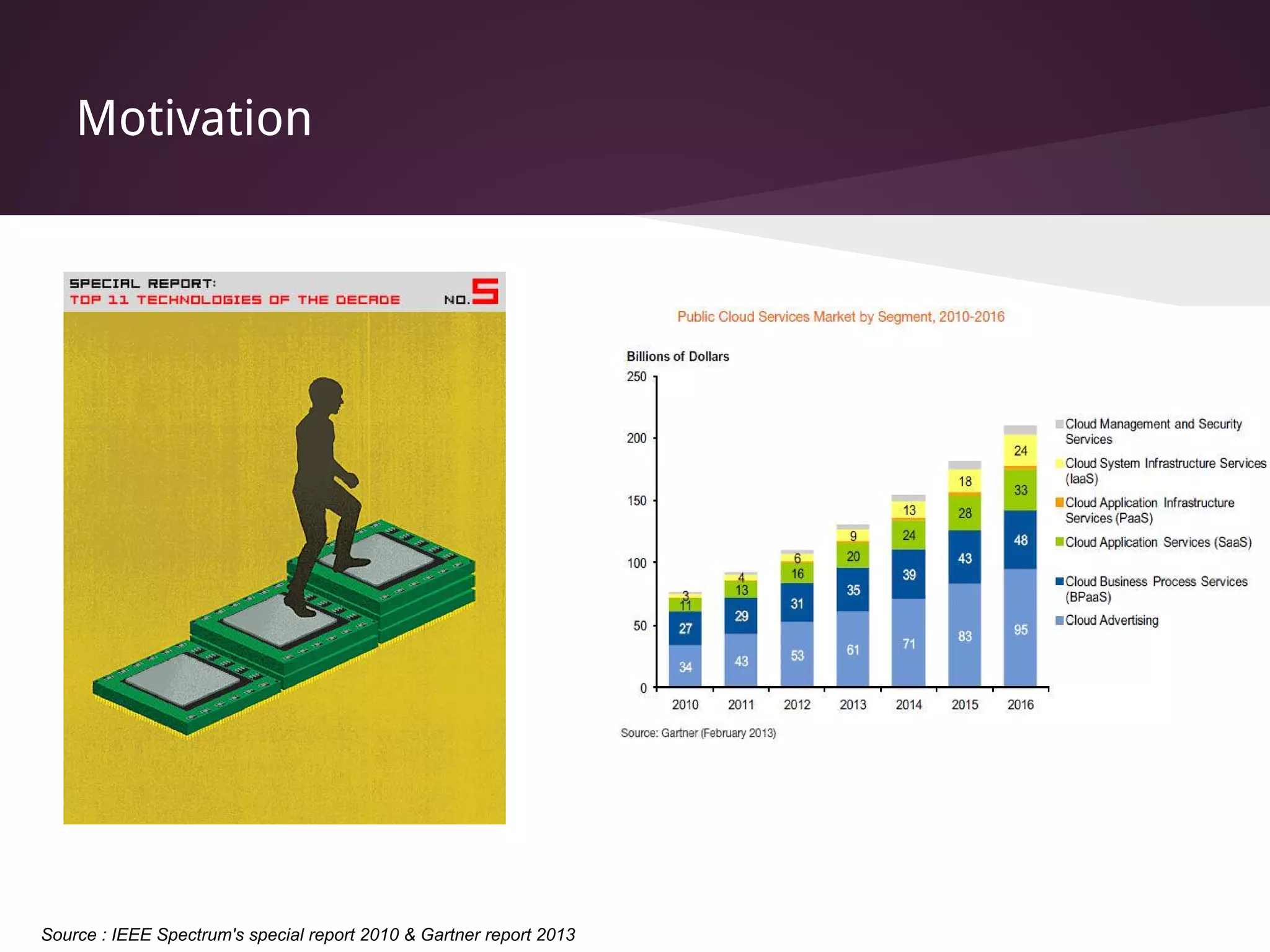








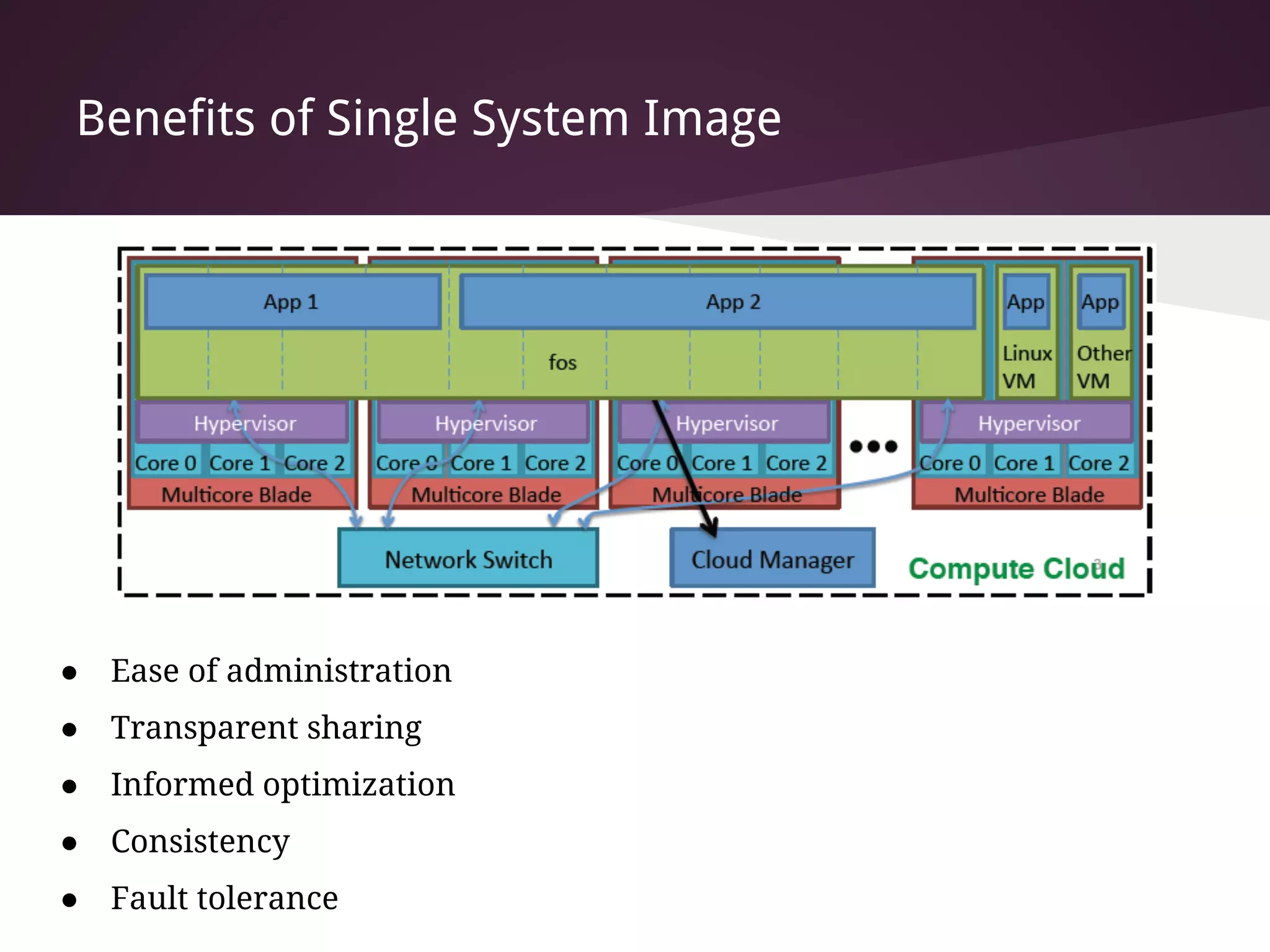
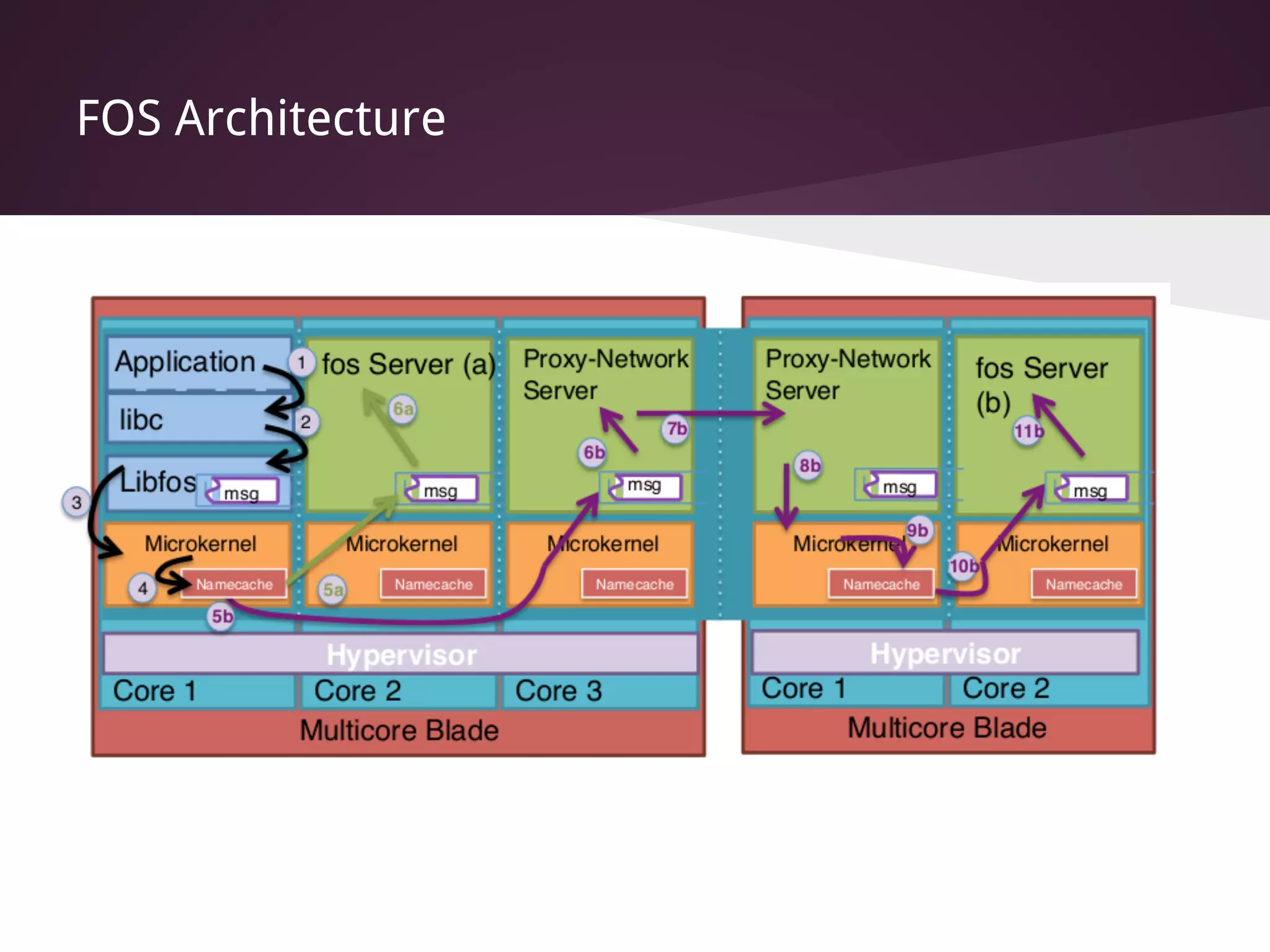





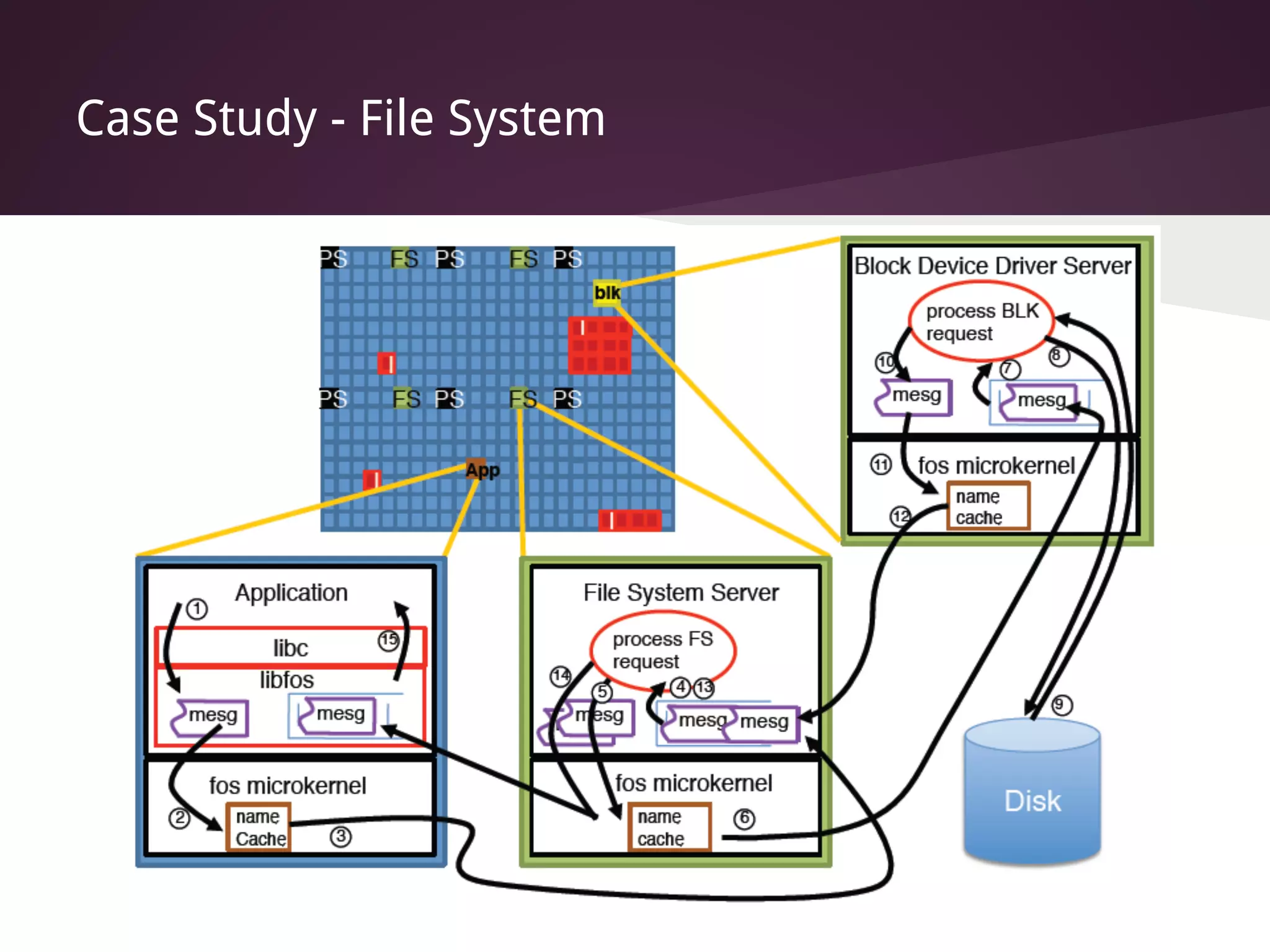
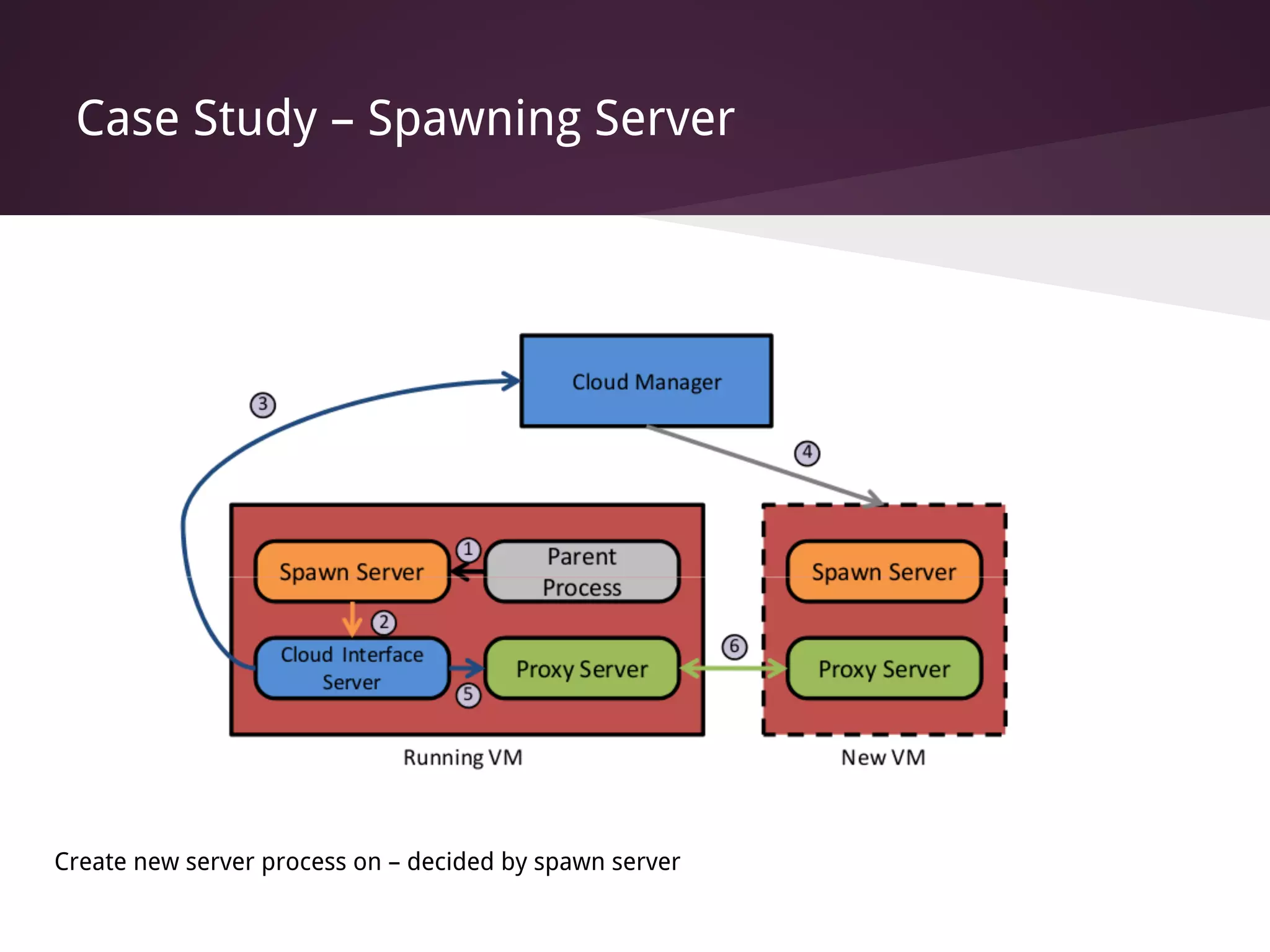


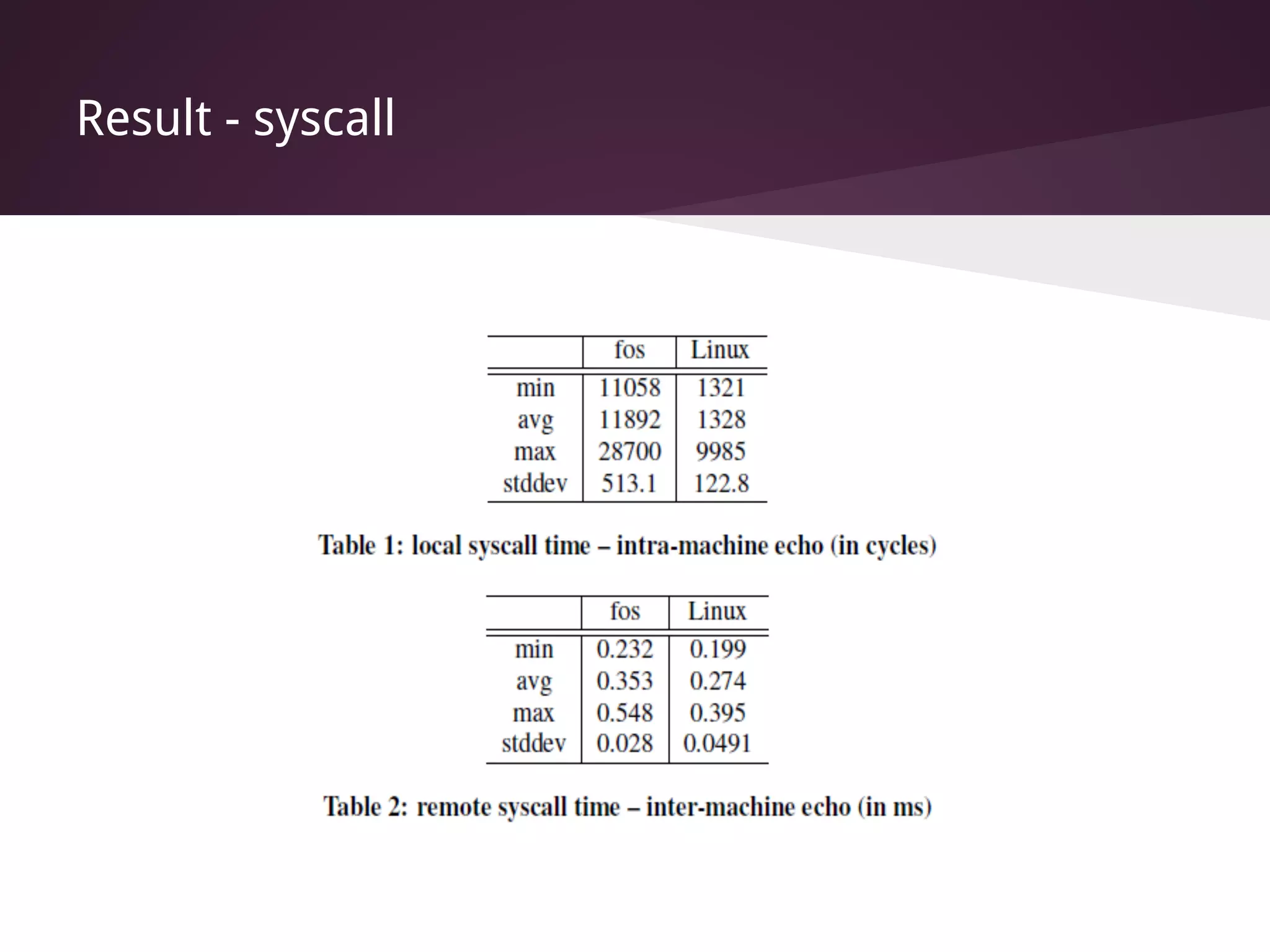
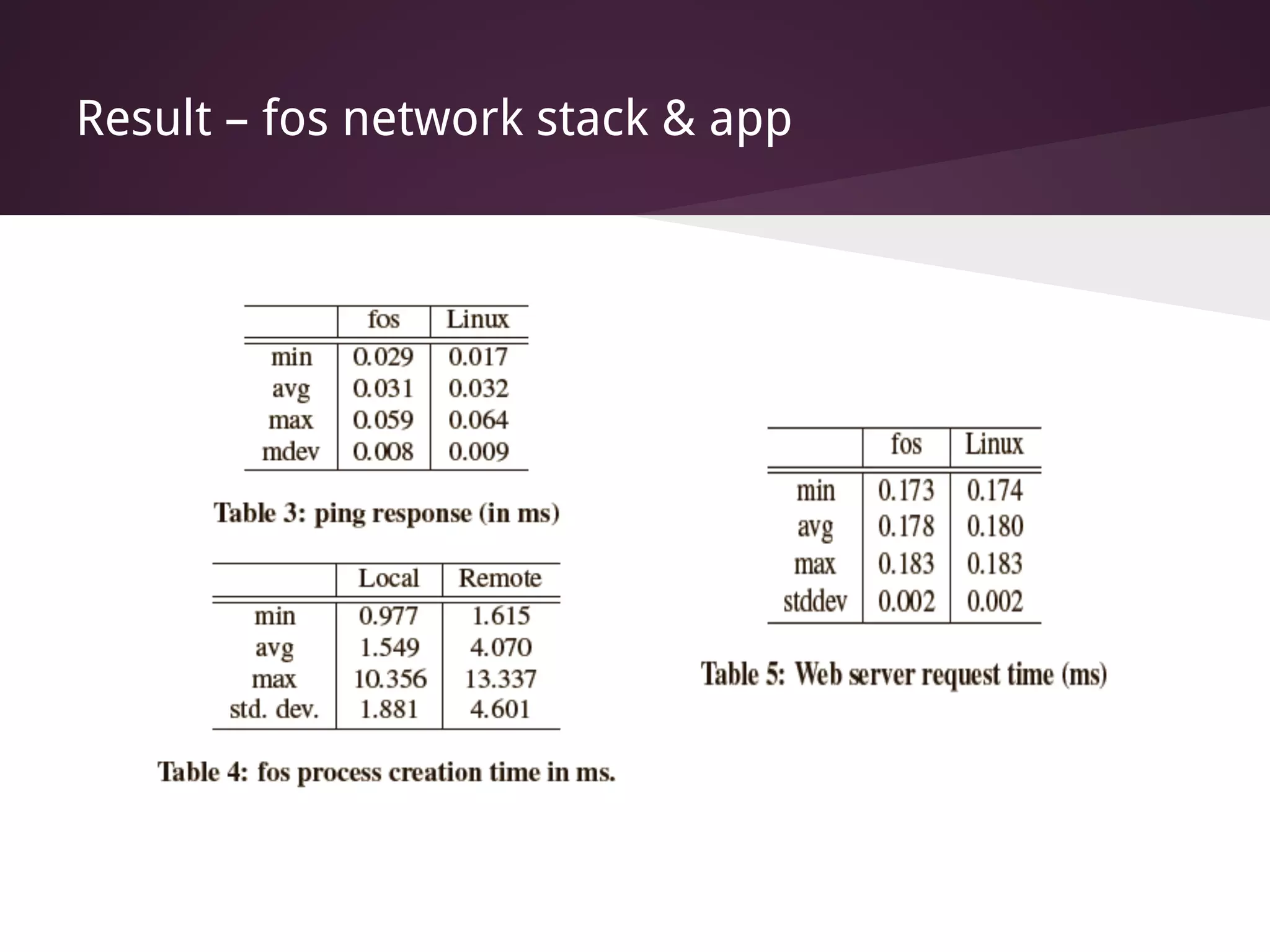
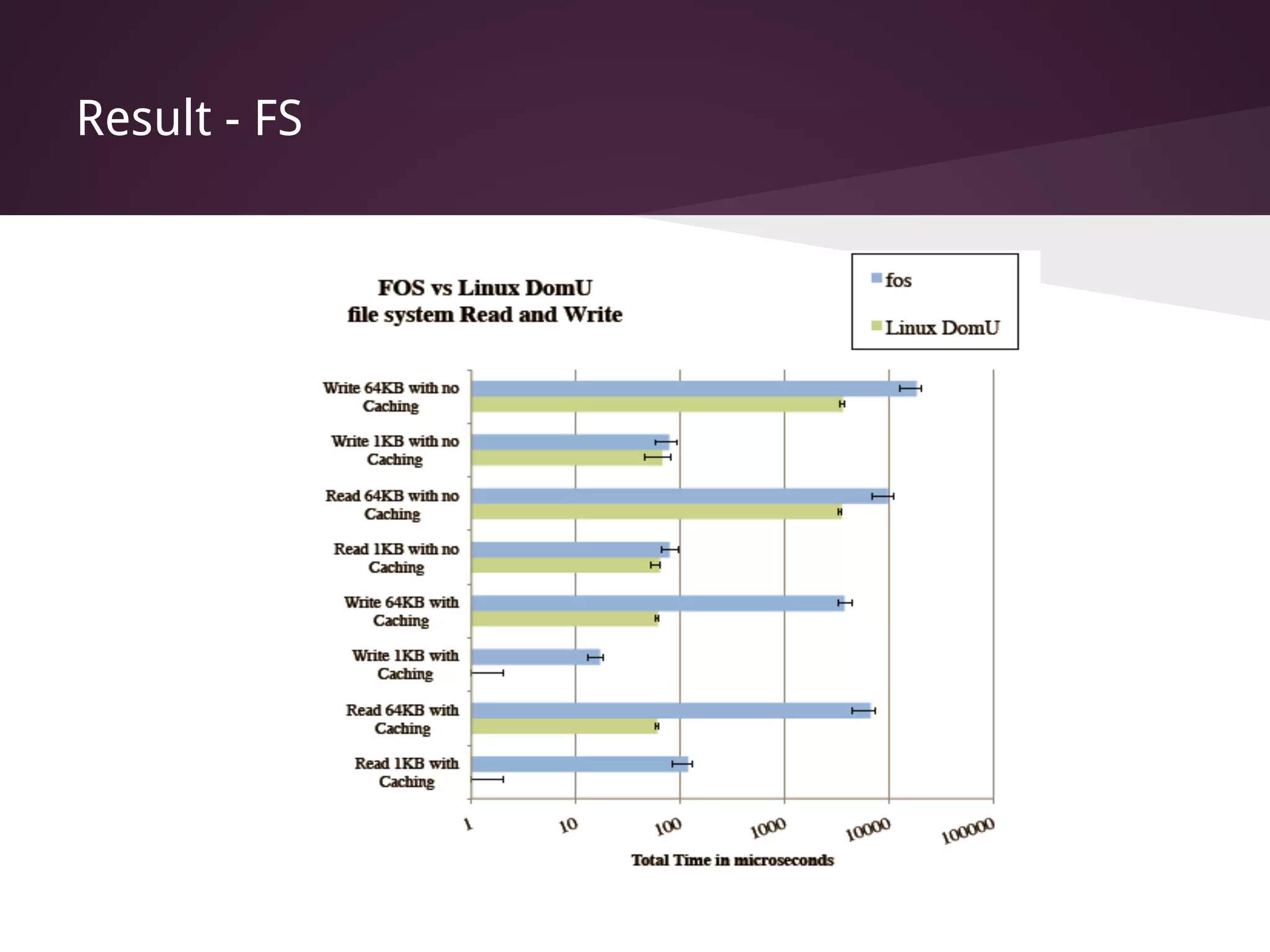




The document presents Factored Operating Systems (FOS), a new operating system designed for multicore and cloud systems. FOS addresses the scalability and fault tolerance challenges of these environments by factoring the OS into distributed, message-passing services like file system, scheduling, and memory management. It provides a single system image across cores and machines using naming and messaging. Evaluation shows FOS improves performance and scalability over traditional OSes for applications and filesystem operations in multicore and cloud deployments.












































































