Download as PDF, PPTX







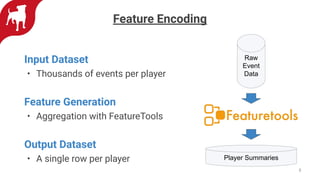
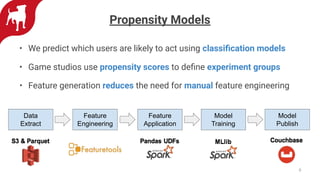
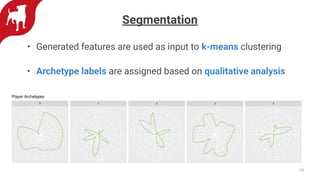
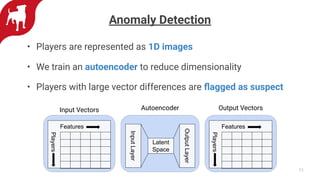
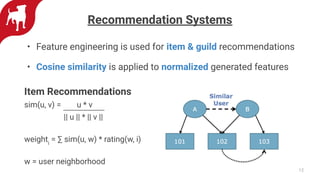



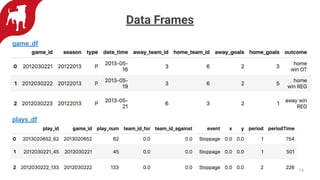







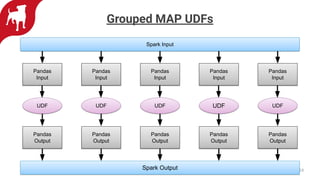

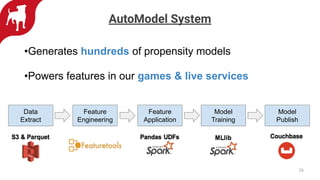





Zynga uses automated feature engineering to build machine learning models at scale for personalizing gameplay experiences across its many games and millions of players. It leverages libraries like FeatureTools to generate features from raw event data, representing each player with a single row. This reduces manual feature engineering work. Models powered by these features include propensity models, segmentation, anomaly detection, and recommendations. Zynga deploys these models using a Databricks/PySpark stack to handle the large data volumes from its many players. Automated feature engineering has enabled Zynga to build portfolio-scale data products that power personalization across its games.







































![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)




