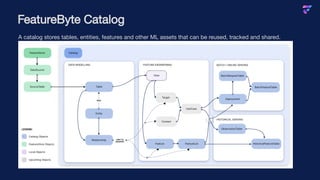
The document discusses FeatureByte, a feature engineering platform that simplifies the process of creating machine learning features from raw data in data warehouses. It elaborates on the challenges of feature engineering, such as training versus serving consistency, and introduces how FeatureByte's architecture and central catalog assist in managing, sharing, and tracking features efficiently. Additionally, it highlights upcoming features like user-defined functions and automated feature discovery to enhance the platform's capabilities.









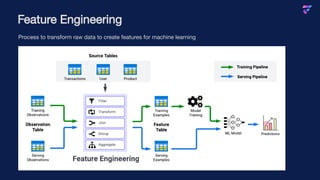

![Feature formulation and materialization
Data wrangling tools not tailored for feature engineering
Time-awareness handling needs to be implemented
Easy to introduce bugs and target leakage
Can be computationally / memory expensive if not
optimized
Transfering large datasets for experimentation
Feature Engineering Challenges
1 # read observations and transactions table
2 transactions_df = pd.read_parquet("transactions.parquet")
3 observation_df = pd.read_parquet("observations.parquet")
4
5 df = observation_df.drop_duplicates(
6 ["AccountID", "POINT_IN_TIME"]
7 ).merge(
8 transactions_df, on="AccountID", how="inner"
9 )
10 mask = (
11 (df.POINT_IN_TIME - df.Timestamp) < pd.Timedelta("7d") &
12 (df.POINT_IN_TIME > df.Timestamp)
13 )
14 features_df = df[mask].groupby(
15 ["AccountID", "POINT_IN_TIME"]
16 )["Amount"].sum()
17
18 observation_df = observation_df.merge(
19 features_df,
20 on=["AccountID", "POINT_IN_TIME"],
21 how="left",
22 )](https://image.slidesharecdn.com/slides-export-230711153642-f2dd3bcb/85/Simplify-Feature-Engineering-in-Your-Data-Warehouse-11-320.jpg)





![Python SDK for feature creation
Built-in time-awareness for lookups and joins
Windowed aggregations based on request point-in-time
Automatically emulate serving time behavior in historical
features to minimize train / test inconsistency
Scalable compute in warehouse with optimized SQL
Feature Engineering with FeatureByte
1 # get table views
2 credit_card = catalog.get_view("CREDITCARD")
3 card_transactions = catalog.get_view("CARDTRANSACTIONS")
4
5 # join tables
6 card_transactions = card_transactions.join(credit_card)
7
8 # define spending features
9 cust_spend_features = card_transactions.groupby(
10 "BankCustomerID"
11 ).aggregate_over(
12 value_column="Amount",
13 method=fb.AggFunc.SUM,
14 windows=["7d"],
15 feature_names=["total_spend_7d"]
16 )
17
18 # preview features
19 cust_spend_features.preview(observation_set=observation_set)](https://image.slidesharecdn.com/slides-export-230711153642-f2dd3bcb/85/Simplify-Feature-Engineering-in-Your-Data-Warehouse-17-320.jpg)






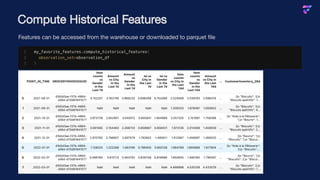
![Serving Features
Deploy a featurelist for serving
Retrieve features using REST-API request
Track feature job status
1 # Create and enable new deployment
2 deployment = my_favorite_features.deploy()
3 deployment.enable()
1 curl -X POST
2 -H 'Content-Type: application/json'
3 -H 'active-catalog-id: 64708919ea4c4876a77d2b80'
4 -d '{"entity_serving_names": [{"GROCERYINVOICEGUID": "d1b5d3ae-f37b-4864-a56d-d70d81641577"}]}'
5 http://featurebyte_service/api/v1/deployment/6478b57bb68c91fb84f1e156/online_features](https://image.slidesharecdn.com/slides-export-230711153642-f2dd3bcb/85/Simplify-Feature-Engineering-in-Your-Data-Warehouse-26-320.jpg)

















































