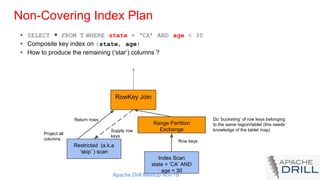
The document presents a talk from the Apache Drill Meetup in November 2018, focusing on accelerating SQL queries in NoSQL databases using Apache Drill and secondary indexes. It covers the architecture of Apache Drill, the relevance of secondary indexes in NoSQL databases, and outlines the implementation and query handling methods utilizing these indexes. Additionally, it discusses the forthcoming features in the Drill 1.15 release aimed at enhancing index planning and execution.