This document discusses analyzing Titanic passenger data using Hadoop MapReduce. It performs two analyses:
1) Calculating the average age of males and females who died on the Titanic. The mapper emits gender as key and age as value. The reducer calculates the average age for each gender.
2) Counting the number of people who died or survived for each class and gender. The mapper creates a composite key of class, survived status, and gender. The reducer counts the occurrences for each unique key.
The document provides the code for the mapper and reducer classes used in each analysis, and explains how to run the job and view the output. It links to the source code and dataset.

![ACADGILDACADGILD
Column 5 : Sex
Column 6 : Age
Column 7 : SibSp
Column 8 : Parch
Column 9 : Ticket
Column 10 : Fare
Column 11 : Cabin
Column 12 : Embarked
You can download the data set from the below link
Titanic Data set
Problem statement 1:
In this problem statement we will find the average age of males and females who died in the Titanic
tragedy.
Source code
Now from the mapper we will derive:
•the gender as key
•age as values
These valus will be passed to the shuffle and sort phase and are further sent to the reducer phase where
the aggregation of the values is performed.
Mapper code:
public class Average_age {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text gender = new Text();
private IntWritable age = new IntWritable();
public void map(LongWritable key, Text value, Context context ) throws IOException,
InterruptedException {
String line = value.toString();
String str[]=line.split(",");
if(str.length>6){
https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/](https://image.slidesharecdn.com/mapreduceusecasetitanicdataanalysis-160708101632/85/ACADGILD-HADOOP-LESSON-2-320.jpg)
![ACADGILDACADGILD
gender.set(str[4]);
if((str[1].equals("0")) ){
if(str[5].matches("d+")){
int i=Integer.parseInt(str[5]);
age.set(i);
}
}
}
context.write(gender, age);
}
}
The explanation for the code in each line of the above Mapper is:
•line 1 we are taking a class by name Average_age,
•In line 2 the Mapper default class is extended to have the
arguments keyIn as LongWritable and ValueIn as Text and KeyOut as Text
and ValueOut as IntWritable.
•In line 3, the variables declared are: a private Text variable gender which will store the gender
of the person who died in the Titanic tragedy.
•In line 4 the variables declared are: a private IntWritable variable age which will store the age
of the MapReduce deals with Key and Value pairs.Here the key is set as gender and value
as age.
•In line 5 we are overriding the map method which will run one time for every line.
•In line 6 we are storing the line in a string variable
•In line 7 we are splitting the line by using comma “,” delimiter and storing the values in a
String Array so that all the columns in a row are stored in the string array.
•In line 8 we are taking a condition if we have the string array length greater than 6 which
means if the line or row has at least 7 columns then the do the rest this helps in eliminating
the ArrayIndexOutOfBoundsException in some cases if the data inside the data set is
incorrect.
•In line 9 we are storing the gender which is in 5th
•In line 10 we are including a condition whether the person is alive or not if he is not alive then
proceed.
•In line 11 we are checking whether the data in that index is numeric data or not by using a
regular expression which can be achieved by “matches function in java”,if it is numeric data
then it will proceed.
https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/](https://image.slidesharecdn.com/mapreduceusecasetitanicdataanalysis-160708101632/85/ACADGILD-HADOOP-LESSON-3-320.jpg)

![ACADGILDACADGILD
•Value iterated.
•In line 8 we are storing and calculating the sum of the values.
•Closing bracket.
•In line 10 perform the average of the obtained sum and writes the respected key and the
obtained sum as value to the context.
Configuration Code:
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
This two configuration classes are included in the main class whereas to clarify the Output key type of
mapper and the output value type of the Mapper.
You can download the whole discussed source code from the below link:
https://github.com/kiran0541/Map-Reduce/blob/master/Average%20age%20of%20male%20and
%20female%20people%20died%20in%20titanic
Way to to execute the Jar file to get the result of the first problem statement:
hadoop jar average.jar /TitanicData.txt /avg_out
Here ‘hadoop’ specifies we are running a Hadoop command and jar specifies which type of application
we are running and average.jar is the jar file which we have created which consists the above source
code and the path of the Input file name in our case it is TitanicData.txt and the output file where to
store the output here we have given it as avg_out.
Way to view the output:
hadoop dfs –cat /avg_out/part-r-00000
Here ‘hadoop’ specifies that we are running a Hadoop command and dfs specifies that we are
performing an operation related to Hadoop Distributed File Sysytem and ‘- cat’ is used to view the
contents of a file and avg_out/part-r-00000 is the file where output is stored.Part file is created by
default by the TextInputFormat class of Hadoop.
[acadgild@localhost -]$ hadoop jar avgage.jar /TitanicData.txt /avg_out
15/10/23 06:25:37 WARN util.NativeCodeLoader: Unable to load native-hadoop libra ry for your
platform... using builtin-java classes where applicable
https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/](https://image.slidesharecdn.com/mapreduceusecasetitanicdataanalysis-160708101632/85/ACADGILD-HADOOP-LESSON-5-320.jpg)
![ACADGILDACADGILD
15/10/23 06:25:40 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0 :8032
15/10/23 06:25:43 WARN mapreduce.JobSubmitter: Hadoop command-line option parsin g not
performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
15/10/23 06:25:44 INFO input.FileInputFormat: Total input paths to process : 1
15/10/23 06:25:44 INFO mapreduce.JobSubmitter: number of splits:1
15/10/23 06:25:45 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_14 45558139946
0012
15/10/23 06:25:46 INFO impl.YarnClientlmpl: Submitted application application 14
45558139946_0012
15/10/23 06:25:46 INFO mapreduce.Job: The url to track the job: http://localhost
.localdomain:8088/proxy/application 1445558139946_0012/
15/10/23 06:25:46 INFO mapreduce.Job: Running job: job 1445558139946_0012
15/10/23 06:26:06 INFO mapreduce.Job: Job job_1445558139946_0012 running in uber mode : false
15/10/23 06:26:06 INFO mapreduce.Job: map 0% reduce 0%
15/10/23 06:26:21 INFO mapreduce.Job: map 100% reduce 0%
15/10/23 06:26:39 INFO mapreduce.Job: map 100% reduce 100%
15/10/23 06:26:40 INFO mapreduce.Job: Job job_1445558139946_0012 completed successfully
Output:
[acadgild@localhost -]$ hadoop dfs -cat /avg_out/part-r-00000 DEPRECATED: Use of this script to
execute hdfs command is deprecated. Instead use the hdfs command for it.
15/10/23 06:27:29 WARN util.NativeCodeLoader: Unable to load native-hadoop libra ry for your
platform... using builtin-java classes where applicable
Sex 0
female 28
male 30
https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/](https://image.slidesharecdn.com/mapreduceusecasetitanicdataanalysis-160708101632/85/ACADGILD-HADOOP-LESSON-6-320.jpg)
![ACADGILDACADGILD
Problem statement 2:
In this problem statement we will find the number of people died or survived in each class with their
genders and ages.
Source code:
Now from the mapper we want to get the composite key which is the combination of Passenger class
and gender and their age and final int value ‘1’ as values which will be passed to the shuffle and sort
phase and are further sent to the reducer phase where the aggregation of the values is performed.
Mapper code:
public class Female_survived {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {‘
private Text people = new Text();
private final static IntWritable one = new IntWritable(1);
public void map(LongWritable key, Text value, Context context ) throws IOException,
InterruptedException {
String line = value.toString();
String str[]=line.split(",");
if(str.length>6){
String survived=str[1]+" "+str[4]+" "+str[5];
people.set(survived);
context.write(people, one);
}
}
}
Explanation of the above Mapper code
•In line 1 we are taking a class by name survived
•In line 2 extending the Mapper default class having the arguments keyIn as LongWritable
and ValueIn as Text and KeyOut as Text and ValueOut as IntWritable.
•In line 3 declaring a private Text variable ‘people’ which will store the Text value as
•In line 4 declaring a private static final IntWritable variable ‘one’ which will be one and can
not be modified.MapReduce deals with Key and Value pairs.Here we can set the key
as pclass and value as one.
•In line 5 we are overriding the map method which will run one time for every line.
•In line 6 we are storing the line in a string variable ‘line’ .
•In line 7 we are splitting the line by using comma “,” delimiter and storing the values in a
https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/](https://image.slidesharecdn.com/mapreduceusecasetitanicdataanalysis-160708101632/85/ACADGILD-HADOOP-LESSON-7-320.jpg)

![ACADGILDACADGILD
•In line 8 writes the respected key and the obtained sum as value to the context.
In the above example use of composite key made the complicated program simple.
Conf code
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
This two configuration classes are included in the main class whereas to clarify the Output key type of
mapper and the output value type of the Mapper.
You can download the whole source code from the below link
https://github.com/kiran0541/Map-Reduce/blob/master/Number%20of%20people%20died
%20or%20survived%20in%20each%20class%20their%20genders%20and%20their%20ages
%20in%20tatnic
Way to to execute the Jar file to get the result of the fourth problem statement:
hadoop jar peope_survived.jar /TitanicData.txt /people_out
Here ‘hadoop’ specifies we are running a Hadoop command and jar specifies which type of application
we are running and people_survived.jar is the jar file which we have created which consists the above
source code and the path of the Input file name in our case it is TitanicData.txt and the output file
where to store the output here we have given it as people_out.
Way to view the output
hadoop dfs –cat /people_out/part-r-00000
Here ‘hadoop’ specifies that we are running a Hadoop command and dfs specifies that we are
performing an operation related to Hadoop Distributed File Sysytem and ‘- cat’ is used to view the
contents of a file and people_out/part-r-00000 is the file where output is stored.Part file is created by
default by the TextInputFormat class of Hadoop.
[acadgild@localhost -]$ hadoop jar peope_survived.jar /TitanicData.txt /people_o ut
15/10/23 03:11:21 WARN util.NativeCodeLoader: Unable to load native-hadoop libra ry for your
platform... using builtin-java classes where applicable
15/10/23 03:11:26 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0 :8032
https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/](https://image.slidesharecdn.com/mapreduceusecasetitanicdataanalysis-160708101632/85/ACADGILD-HADOOP-LESSON-9-320.jpg)
![ACADGILDACADGILD
15/10/23 03:11:28 WARN mapreduce.JobSubmitter: Hadoop command-line option parsin g not
performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
15/10/23 03:11:28 INFO input.FileInputFormat: Total input paths to process : 1
15/10/23 03:11:28 INFO mapreduce.JobSubmitter: number of splits:1
15/10/23 03:11:29 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_14 45558139946
0005
15/10/23 03:11:29 INFO impl.YarnClientImpl: Submitted application application 14
45558139946_0005
15/10/23 03:11:30 INFO mapreduce.Job: The url to track the job: http://localhost
.localdomain:8088/proxy/application 1445558139946_0005/
15/10/23 03:11:30 INFO mapreduce.Job: Running job: job_1445558139946 0005 1
Output:
[acadgild@localhost -]$ hadoop dfs -cat /people_out/part-r-00000 DEPRECATED: Use of this script
to execute hdfs command is deprecated. Instead use the hdfs command for it.
15/10/23 03:08:58 WARN util.NativeCodeLoader: Unable to load native-hadoop libra ry for your
platform... using builtin-java classes where applicable
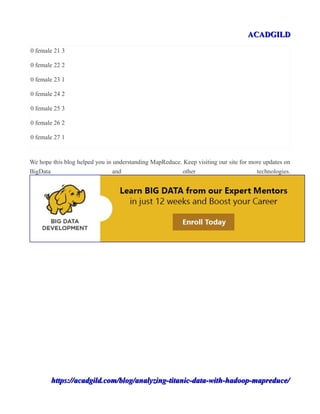
0 female 10 1
0 female 11 1
0 female 14 1
0 female 14.5 1
0 female 16 1
0 female 17 1
0 female 18 5
0 female 2 4
0 female 20 2
https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/https://acadgild.com/blog/analyzing-titanic-data-with-hadoop-mapreduce/](https://image.slidesharecdn.com/mapreduceusecasetitanicdataanalysis-160708101632/85/ACADGILD-HADOOP-LESSON-10-320.jpg)