More Related Content

PDF
Pythonによる機械学習入門 ~Deep Learningに挑戦~ 
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜 
PDF

PDF

PDF
ディープラーニングフレームワーク とChainerの実装 
PDF

PDF
「深層学習」勉強会LT資料 "Chainer使ってみた" 
PDF
What's hot

PDF
Python 機械学習プログラミング データ分析ライブラリー解説編 
PPTX

PDF
PythonによるDeep Learningの実装 
PPTX
Jupyter NotebookとChainerで楽々Deep Learning 
PDF
Python 機械学習プログラミング データ分析演習編 
PDF
Deep Learning Implementations: pylearn2 and torch7 (JNNS 2015) 
PDF

PDF
Chainerチュートリアル -v1.5向け- ViEW2015 
PDF
TensorFlowによるニューラルネットワーク入門 
PDF

PDF

PDF
Chainer の Trainer 解説と NStepLSTM について ![[第2版]Python機械学習プログラミング 第8章](https://cdn.slidesharecdn.com/ss_thumbnails/20181015-181029035714-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第8章 
PDF

PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用 
PDF

PDF

PDF
Introduction to Chainer (LL Ring Recursive) 
PDF

PDF
Practical recommendations for gradient-based training of deep architectures Similar to 2013.07.15 はじパタlt scikit-learnで始める機械学習

PDF
Pythonによる機械学習入門 ~SVMからDeep Learningまで~ ![[DSO] Machine Learning Seminar Vol.2 Chapter 3](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3slides-200226170409-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DSO] Machine Learning Seminar Vol.2 Chapter 3 ![[機械学習]文章のクラス分類](https://cdn.slidesharecdn.com/ss_thumbnails/ss-160218112331-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
![[第2版] Python機械学習プログラミング 第3章(~4節)](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-03-1-180905090110-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版] Python機械学習プログラミング 第3章(~4節) 
PDF
Jubatusにおける大規模分散オンライン機械学習 
PDF

PDF

PPTX

PDF

PDF

PDF

PDF
scikit-learnを用いた機械学習チュートリアル 
PPTX

PDF

PDF

PDF
![[第2版] Python機械学習プログラミング 第3章(5節~)](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-03-2-180905090111-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版] Python機械学習プログラミング 第3章(5節~) 
PPTX
0610 TECH & BRIDGE MEETING 
PDF

PDF
More from Motoya Wakiyama

PDF
はじめてのパターン認識 第8章 サポートベクトルマシン 
PDF
はじめてのパターン認識 第5章 k最近傍法(k_nn法) 
PDF
続分かりやすいパターン認識 4章後半(4.7以降) 
PDF
データ解析のための統計モデリング入門9章後半 
PDF
データ解析のための統計モデリング入門9章後半 ![[Rec sys2013勉強会]orthogonal query recommendation](https://cdn.slidesharecdn.com/ss_thumbnails/recsys2013orthogonalqueryrecommendation-131215221938-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Rec sys2013勉強会]orthogonal query recommendation ![[Rec sys2013勉強会]using maximum coverage to optimize recommendation systems in ...](https://cdn.slidesharecdn.com/ss_thumbnails/recsys2013usingmaximumcoveragetooptimizerecommendationsystemsine-commerce-131215222200-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Rec sys2013勉強会]using maximum coverage to optimize recommendation systems in ... 
PPTX
Repeat buyer prediction for e commerce, KDD2016 2013.07.15 はじパタlt scikit-learnで始める機械学習
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
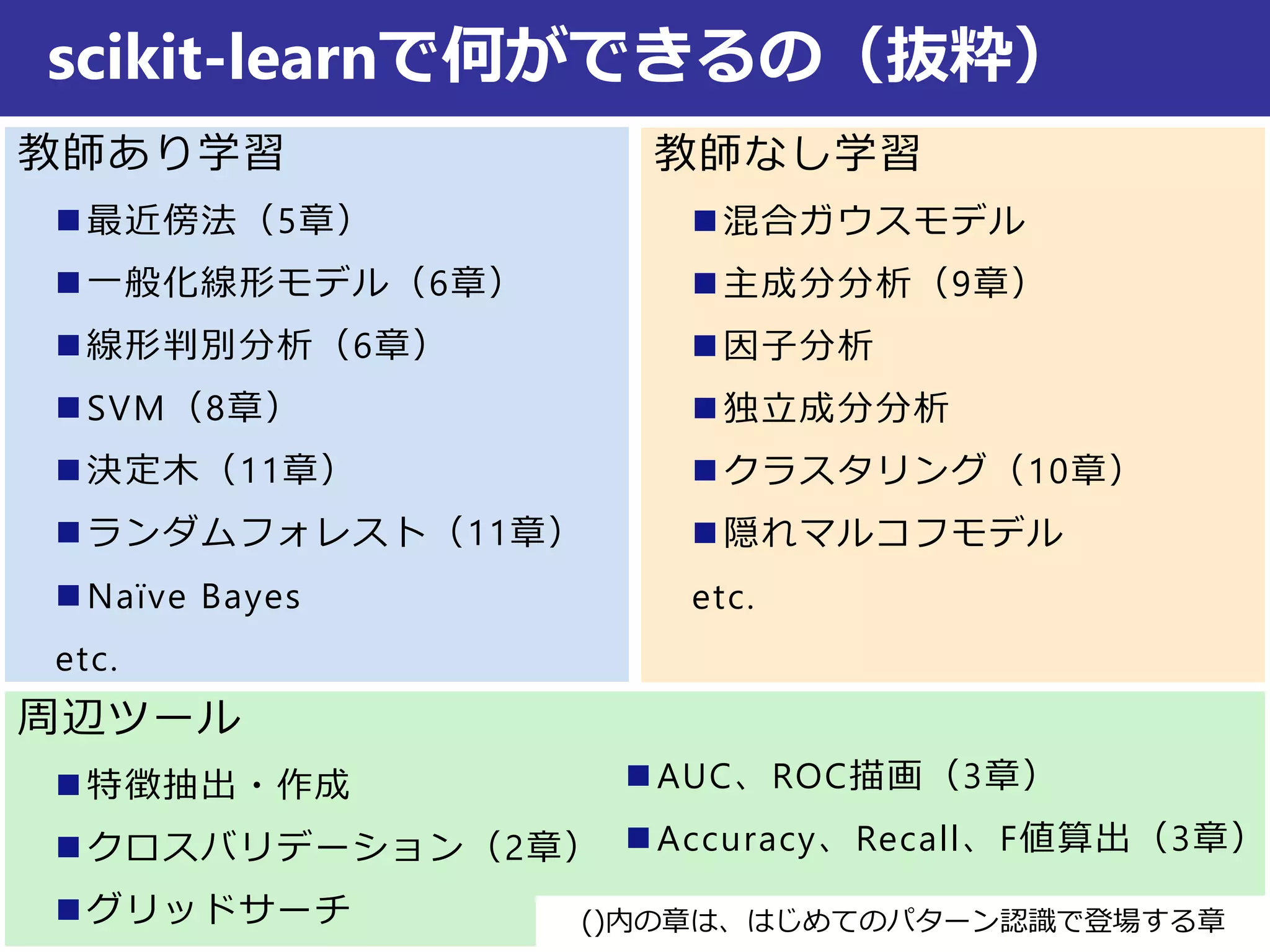
教師なし学習
混合ガウスモデル
主成分分析(9章)
因子分析
独立成分分析
クラスタリング(10章)
隠れマルコフモデル
etc.
教師あり学習
最近傍法(5章)
一般化線形モデル(6章)
線形判別分析(6章)
SVM(8章)
決定木(11章)
ランダムフォレスト(11章)
Naïve Bayes
etc.
scikit-learnで何ができるの(抜粋)
周辺ツール
特徴抽出・作成
クロスバリデーション(2章)
グリッドサーチ
AUC、ROC描画(3章)
Accuracy、Recall、F値算出(3章)
()内の章は、はじめてのパターン認識で登場する章
- 8.
教師なし学習
混合ガウスモデル
主成分分析(9章)
因子分析
独立成分分析
クラスタリング(10章)
隠れマルコフモデル
etc.
教師あり学習
最近傍法(5章)
一般化線形モデル(6章)
線形判別分析(6章)
SVM(8章)
決定木(11章)
ランダムフォレスト(11章)
Naïve Bayes
etc.
scikit-learnで何ができるの(抜粋)
周辺ツール
特徴抽出・作成
クロスバリデーション(2章)
グリッドサーチ
AUC、ROC描画(3章)
Accuracy、Recall、F値算出(3章)
()内の章は、はじめてのパターン認識で登場する章
- 9.
- 10.
- 11.
データの中身
0.29940251144353242,-1.2266241875260637,・・・
-1.1741758544222554,0.33215734209952552,・・・
1.1922220828945145,-0.41437073477092423,・・・
1.573270119628208,-0.58031780024933788,・・・
-0.61307141665395515,-0.64420413382117836,・・・
:
1
0
0
1
0
:
ラベル
1000サンプル
特徴量
1000サンプル×40変数
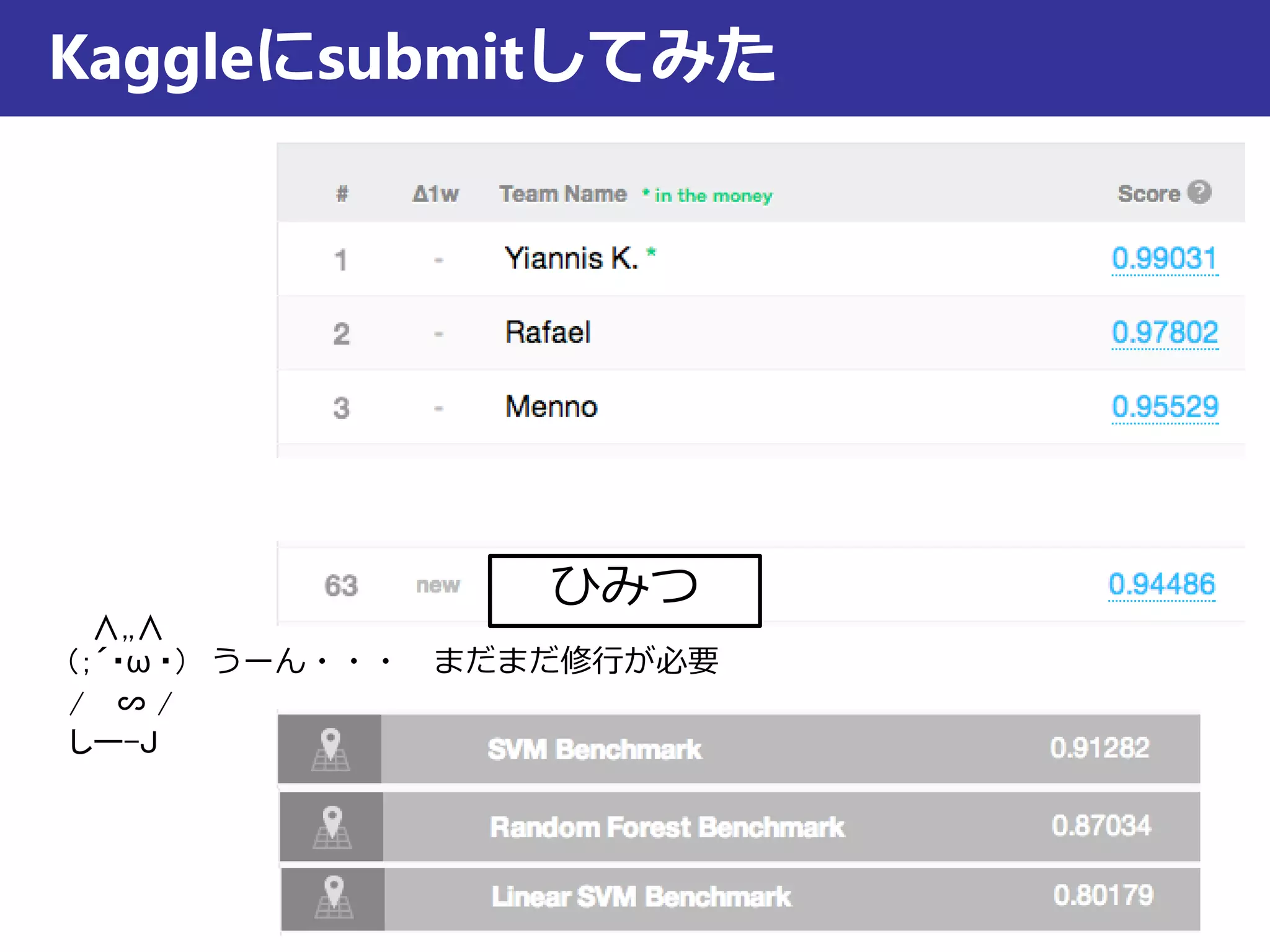
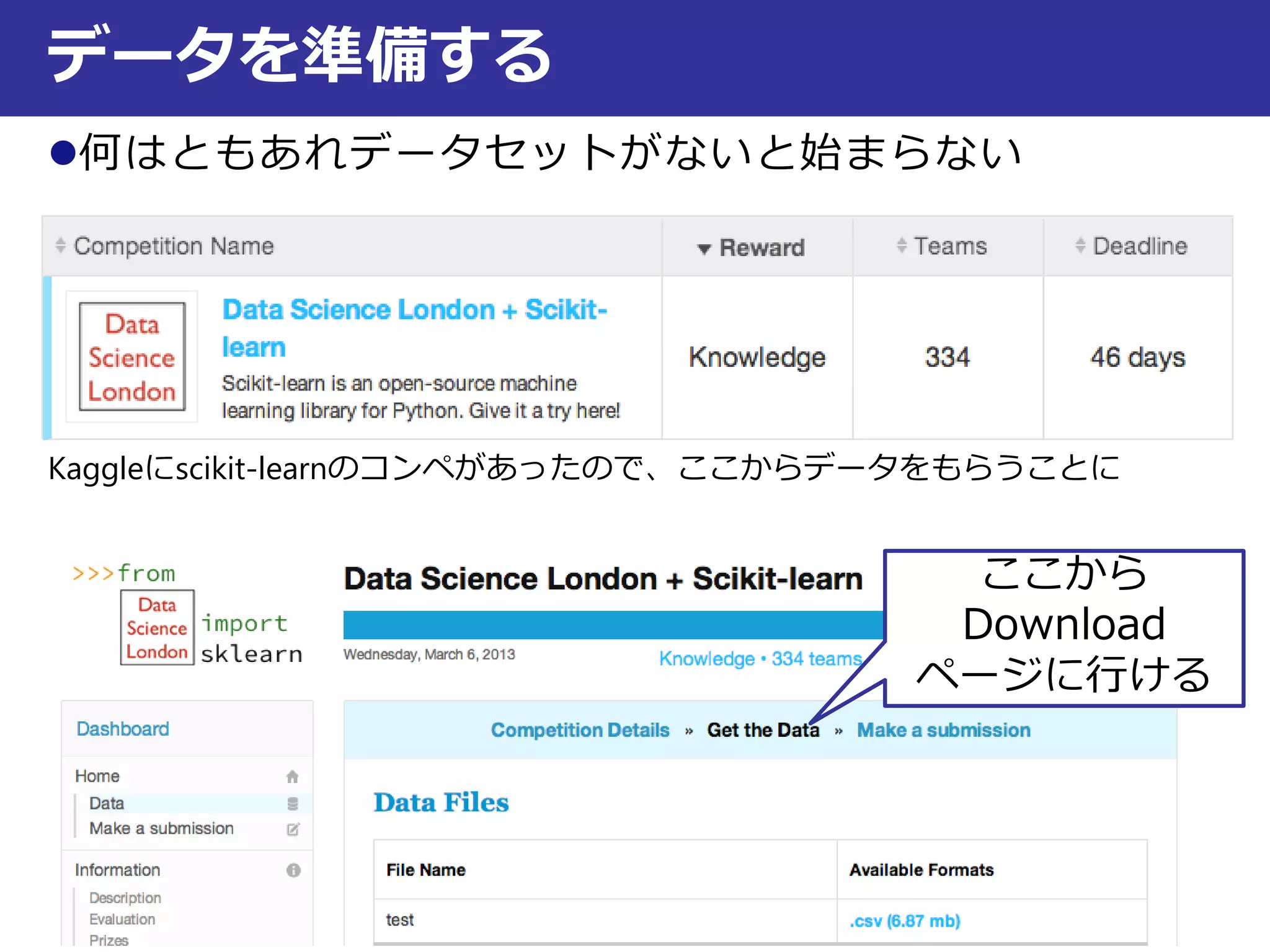
Kaggleにデータの説明がないのが残念(本当は背景情報も欲しいところ)
1000行
40変数
- 12.
Rと同じぐらいのコード量で動かせる
とりあえず動かす
import numpy asnp
from sklearn import svm
trainFeature = np.genfromtxt(open(train.csv', 'r'), delimiter = ',')
trainLabel = np.genfromtxt(open(trainLabels.csv', 'r'), delimiter = ',')
clf = svm.SVC(kernel='rbf', C=1)
clf.fit(trainFeature, trainLabel)
testFeature = np.genfromtxt(open('test.csv', 'r'), delimiter = ',')
result = clf.predict(testFeature)
- 13.
Rと同じぐらいのコード量で動かせる
とりあえず動かす
import numpy asnp
from sklearn import svm
trainFeature = np.genfromtxt(open(train.csv', 'r'), delimiter = ',')
trainLabel = np.genfromtxt(open(trainLabels.csv', 'r'), delimiter = ',')
clf = svm.SVC(kernel='rbf', C=1)
clf.fit(trainFeature, trainLabel)
testFeature = np.genfromtxt(open('test.csv', 'r'), delimiter = ',')
result = clf.predict(testFeature)
ライブラリの読み込み
- 14.
Rと同じぐらいのコード量で動かせる
とりあえず動かす
import numpy asnp
from sklearn import svm
trainFeature = np.genfromtxt(open(train.csv', 'r'), delimiter = ',')
trainLabel = np.genfromtxt(open(trainLabels.csv', 'r'), delimiter = ',')
clf = svm.SVC(kernel='rbf', C=1)
clf.fit(trainFeature, trainLabel)
testFeature = np.genfromtxt(open('test.csv', 'r'), delimiter = ',')
result = clf.predict(testFeature)
ファイルからデータを読み込む。
numpyのデータ形式に変換。
- 15.
Rと同じぐらいのコード量で動かせる
とりあえず動かす
import numpy asnp
from sklearn import svm
trainFeature = np.genfromtxt(open(train.csv', 'r'), delimiter = ',')
trainLabel = np.genfromtxt(open(trainLabels.csv', 'r'), delimiter = ',')
clf = svm.SVC(kernel='rbf', C=1)
clf.fit(trainFeature, trainLabel)
testFeature = np.genfromtxt(open('test.csv', 'r'), delimiter = ',')
result = clf.predict(testFeature)
モデルを定義(ここではSupport Vector Classifier)
fit関数を使って教師データからパラメータを推定
- 16.
Rと同じぐらいのコード量で動かせる
とりあえず動かす
import numpy asnp
from sklearn import svm
trainFeature = np.genfromtxt(open(train.csv', 'r'), delimiter = ',')
trainLabel = np.genfromtxt(open(trainLabels.csv', 'r'), delimiter = ',')
clf = svm.SVC(kernel='rbf', C=1)
clf.fit(trainFeature, trainLabel)
testFeature = np.genfromtxt(open('test.csv', 'r'), delimiter = ',')
result = clf.predict(testFeature) 判別したいデータの特徴量を読み込んで、
predict関数を使って判別
- 17.
- 18.
クロスバリデーション、パラメータのグリッドサーチも簡単
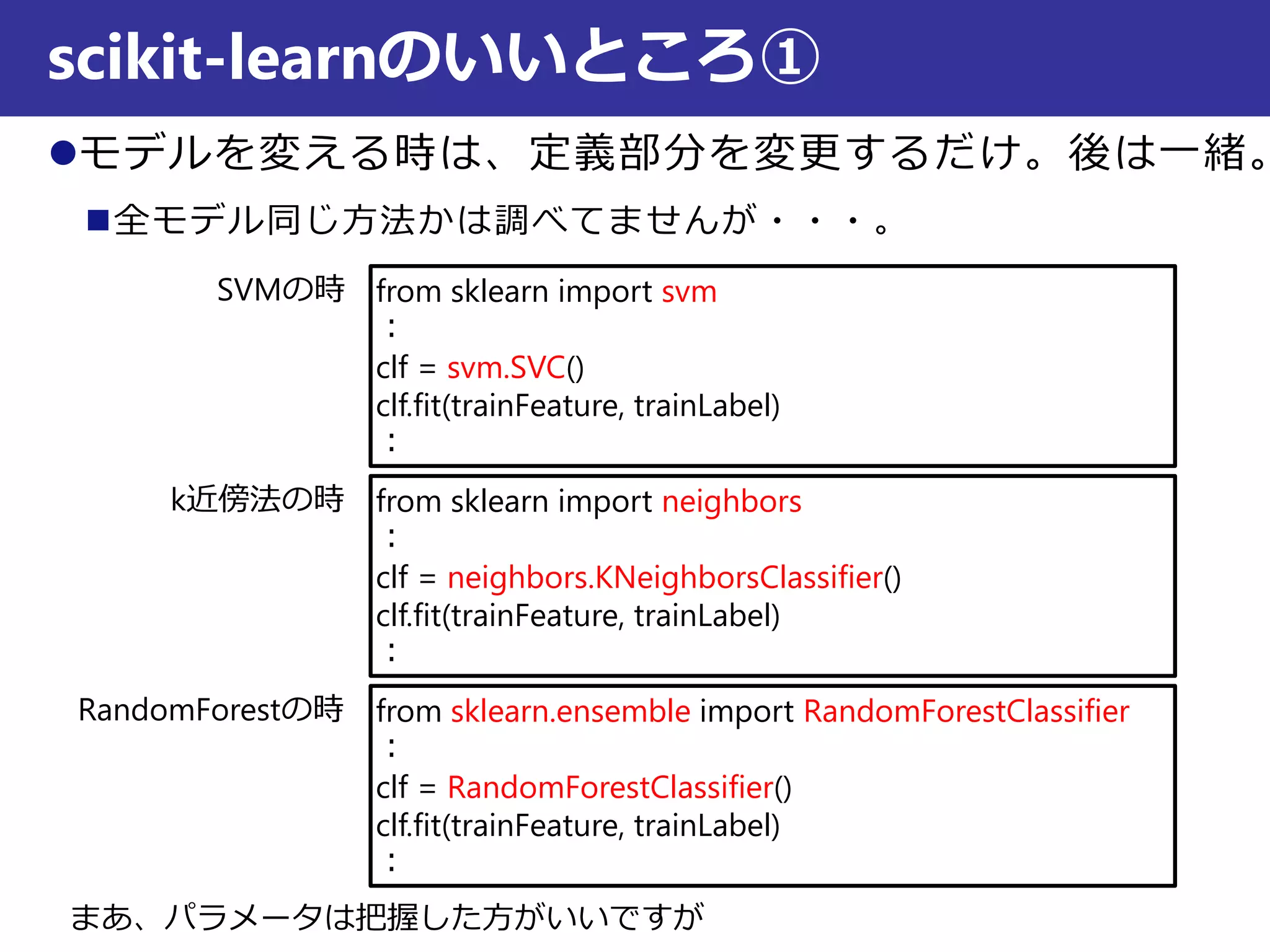
scikit-learnのいいところ②
from sklearn importcross_validation
clf = svm.SVC()
scores = cross_validation.cross_val_score(clf, trainFeature, trainLabel, cv=5, n_jobs=-1)
print scores #結果表示
from sklearn.grid_search import GridSearchCV
tuned_parameters = [ #グリッドサーチの探索範囲設定
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]
clf = GridSearchCV(svm.SVC(C=1), tuned_parameters, n_jobs = -1) #設定
clf.fit(trainFeature, trainLabel, cv=5) #グリッドサーチに使うデータの入力
print clf.best_estimator_ #パラメータが一番よかったモデルを表示
パラメータのグリッドサーチ
クロスバリデーション
クロスバリデーション、グリッドサーチは特徴量とラベルをnumpyの配列にしておかないとエラーになるので注意
- 19.
- 20.














![クロスバリデーション、パラメータのグリッドサーチも簡単
scikit-learnのいいところ②
from sklearn import cross_validation
clf = svm.SVC()
scores = cross_validation.cross_val_score(clf, trainFeature, trainLabel, cv=5, n_jobs=-1)
print scores #結果表示
from sklearn.grid_search import GridSearchCV
tuned_parameters = [ #グリッドサーチの探索範囲設定
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]
clf = GridSearchCV(svm.SVC(C=1), tuned_parameters, n_jobs = -1) #設定
clf.fit(trainFeature, trainLabel, cv=5) #グリッドサーチに使うデータの入力
print clf.best_estimator_ #パラメータが一番よかったモデルを表示
パラメータのグリッドサーチ
クロスバリデーション
クロスバリデーション、グリッドサーチは特徴量とラベルをnumpyの配列にしておかないとエラーになるので注意](https://image.slidesharecdn.com/2013-130716221637-phpapp01/75/2013-07-15-lt-scikit-learn-18-2048.jpg)
![0:00:00
0:01:26
0:02:53
0:04:19
0:05:46
0:07:12
0:08:38
指定なし 1 2 3 4 -1
処理時間[hh:mm:ss]
n_jobs
n_jobsを指定するだけで並列計算できるようになる
クロスバリデーション、グリッドサーチ以外にもランダムフォレ
ストにも使える優れもの
-1だとPCのコア数が自動設定される
並列計算も簡単、そうscikit-learnならね
4コアのMac Book Proで計測](https://image.slidesharecdn.com/2013-130716221637-phpapp01/75/2013-07-15-lt-scikit-learn-19-2048.jpg)