Download to read offline


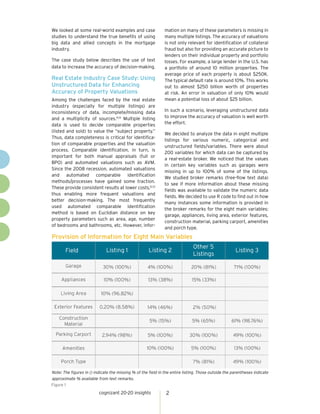





The document discusses the importance of a holistic approach to property valuations using text analytics, specifically to address issues of missing and inaccurate data in property listings that can affect valuation accuracy. It highlights insights from case studies and emphasizes the potential benefits of leveraging unstructured data to enhance the valuation models by filling gaps in missing information. The approach is particularly relevant in the context of automated comparable identification methods, which have gained traction post-2008 financial crisis.























































































