Download to read offline






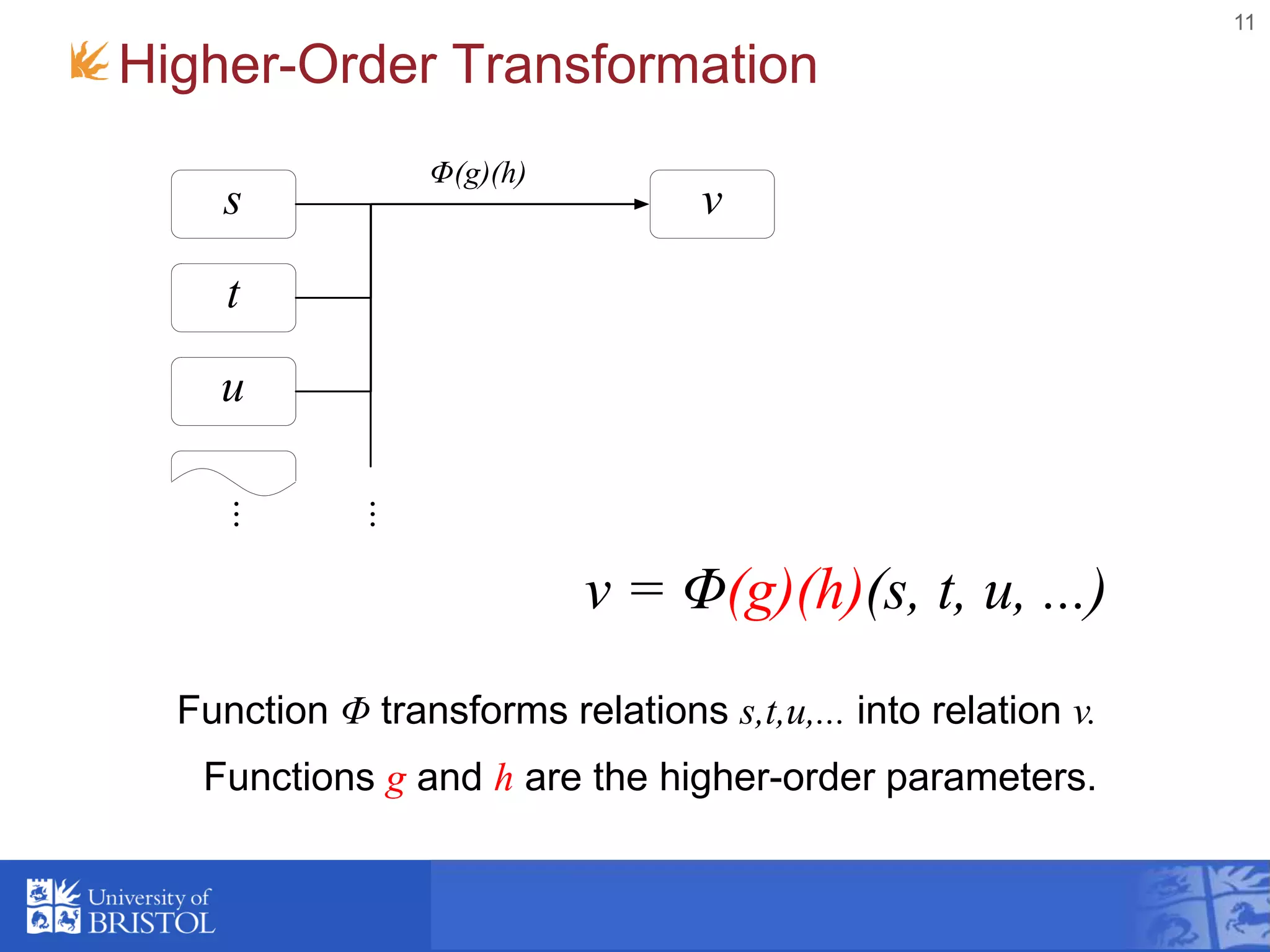

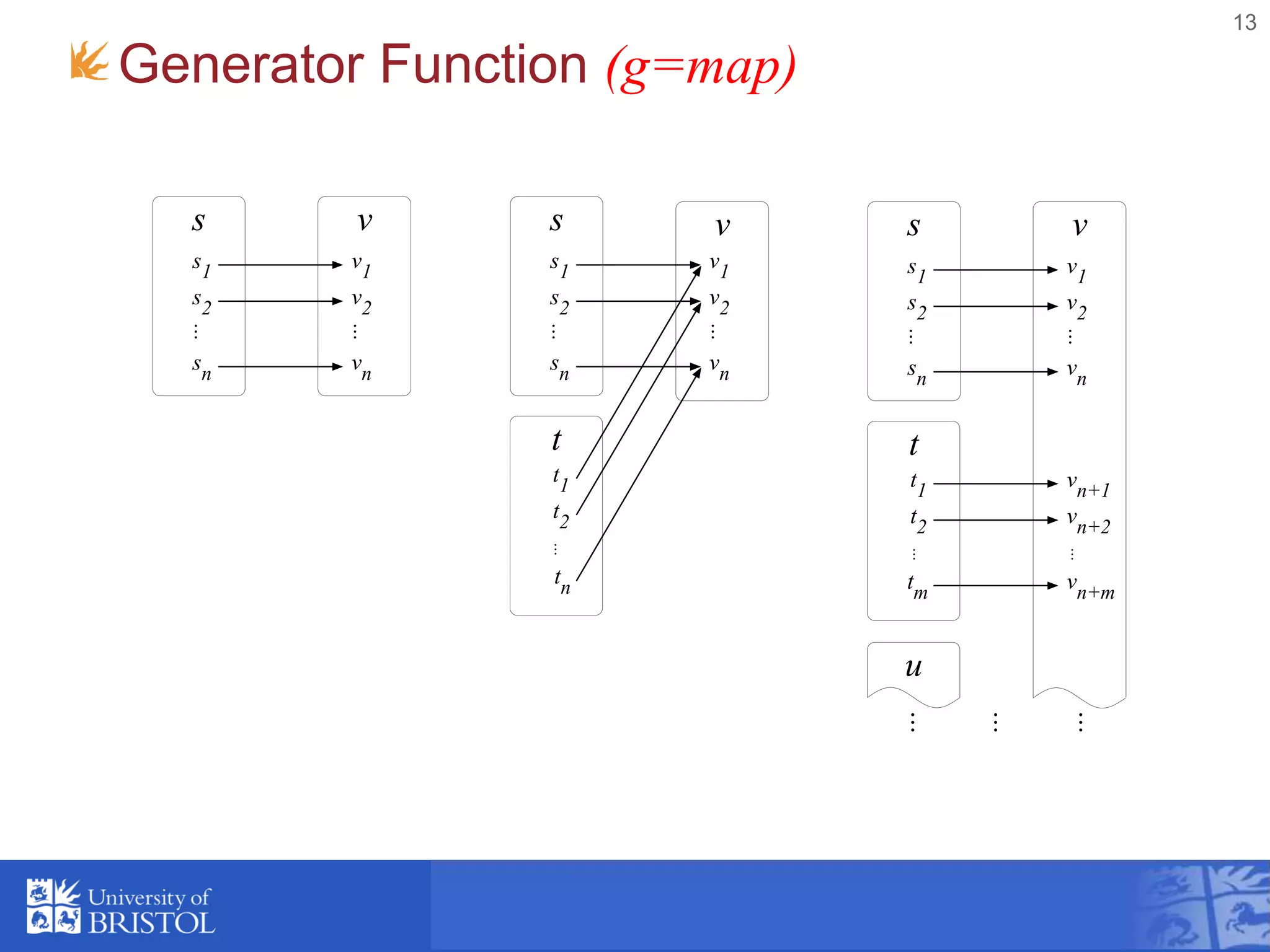
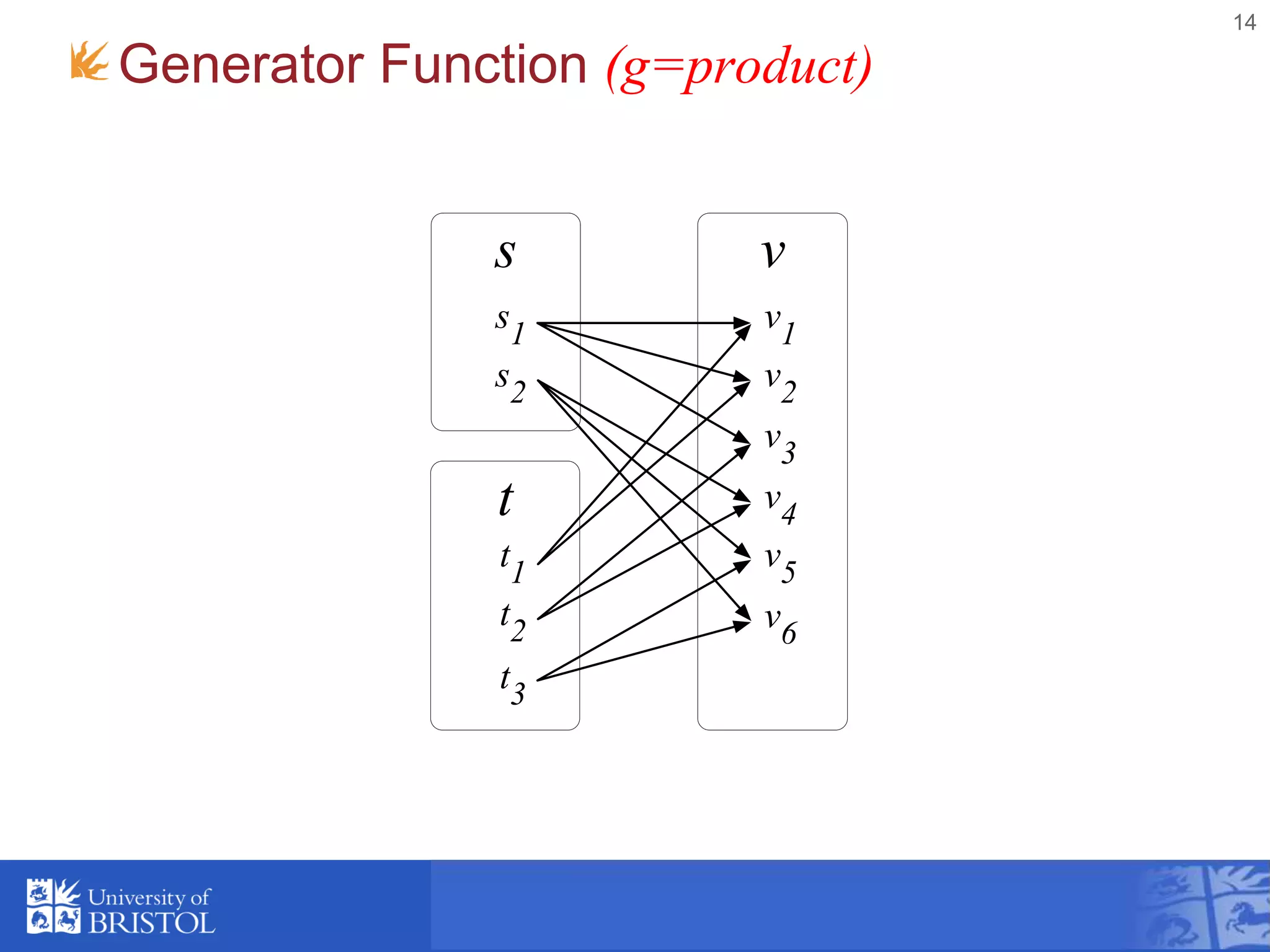
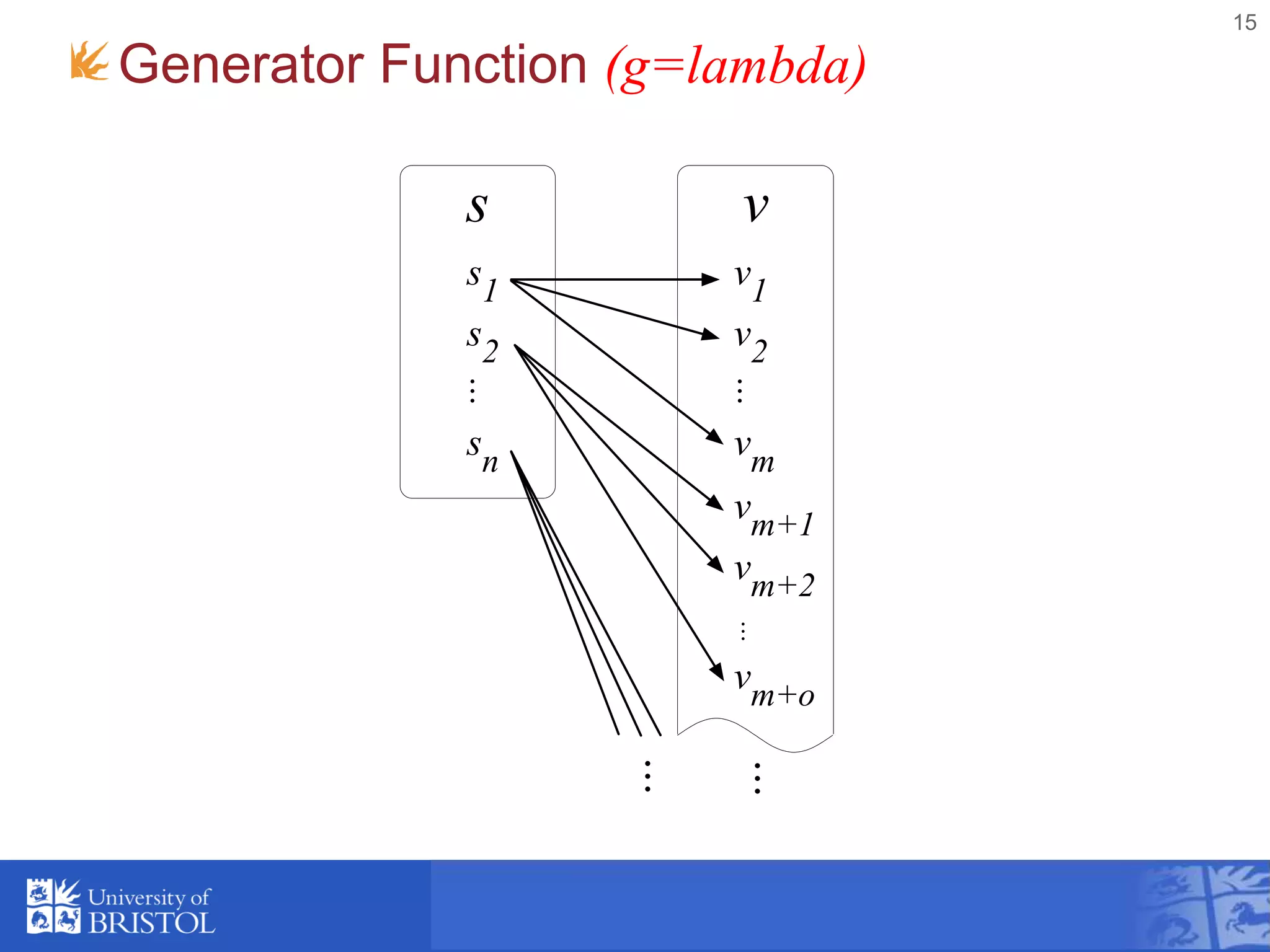
![Template Function (h)
• Template data item with embedded functions
that are expanded by Φ to produce an output item.
• The embedded functions have access to the
"current" items from the input relations. i.e. items
selected by g.
• The embedded functions use JSONPath
expressions (i.e. simplified XPath for JSON) to
access sub-parts of the input items.
• $.person.title
• $.person.paper[*].author[0].name
• $[0][3][1].foo
16](https://image.slidesharecdn.com/bigdata2013-170318105230/75/A-Higher-Order-Data-Flow-Model-for-Heterogeneous-Big-Data-16-2048.jpg)
![• One input relation S. Each item si is an array like this.
• g=map and h is:
• Output relation V has items si like this.
17
Example JSONMatch template data item (h)
[ "Ad Feelders",
"http://dblp.uni-trier.de/pers/hd/f/Feelders:Ad.html.",
"Rankings_and_Partial_Orders",
"Active_Learning; Bioinformatics; ..." ]
{ "name": "$.items[0][0]",
"url": "$.items[0][1]",
"text": ["jm:http_get", "$.items[0][1]"],
"primary": "$.items[0][2]",
"keywords": ["jm:split", ";", "$.items[0][3]"] }
{ "name": "Ad Feelders",
"url": "http://dblp.uni-trier.de/...",
"text": "<html><title>A. J. Feeld...</html>",
"primary": "Rankings_and_Partial_Orders",
"keywords": [ "Active_Learning", "Bioinformatics", ... ] }](https://image.slidesharecdn.com/bigdata2013-170318105230/75/A-Higher-Order-Data-Flow-Model-for-Heterogeneous-Big-Data-17-2048.jpg)





The document presents a higher-order data flow model for heterogeneous big data through a web service called jsonmatch, which analyzes and integrates various data formats. It highlights the architecture's focus on processing JSON documents dynamically via a REST API, optimizing for both small and large datasets. A specific application example, subsift, demonstrates how jsonmatch can assist in academic peer review by matching papers to reviewers based on similarity to published works.










































































![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
