Download as PDF, PPTX





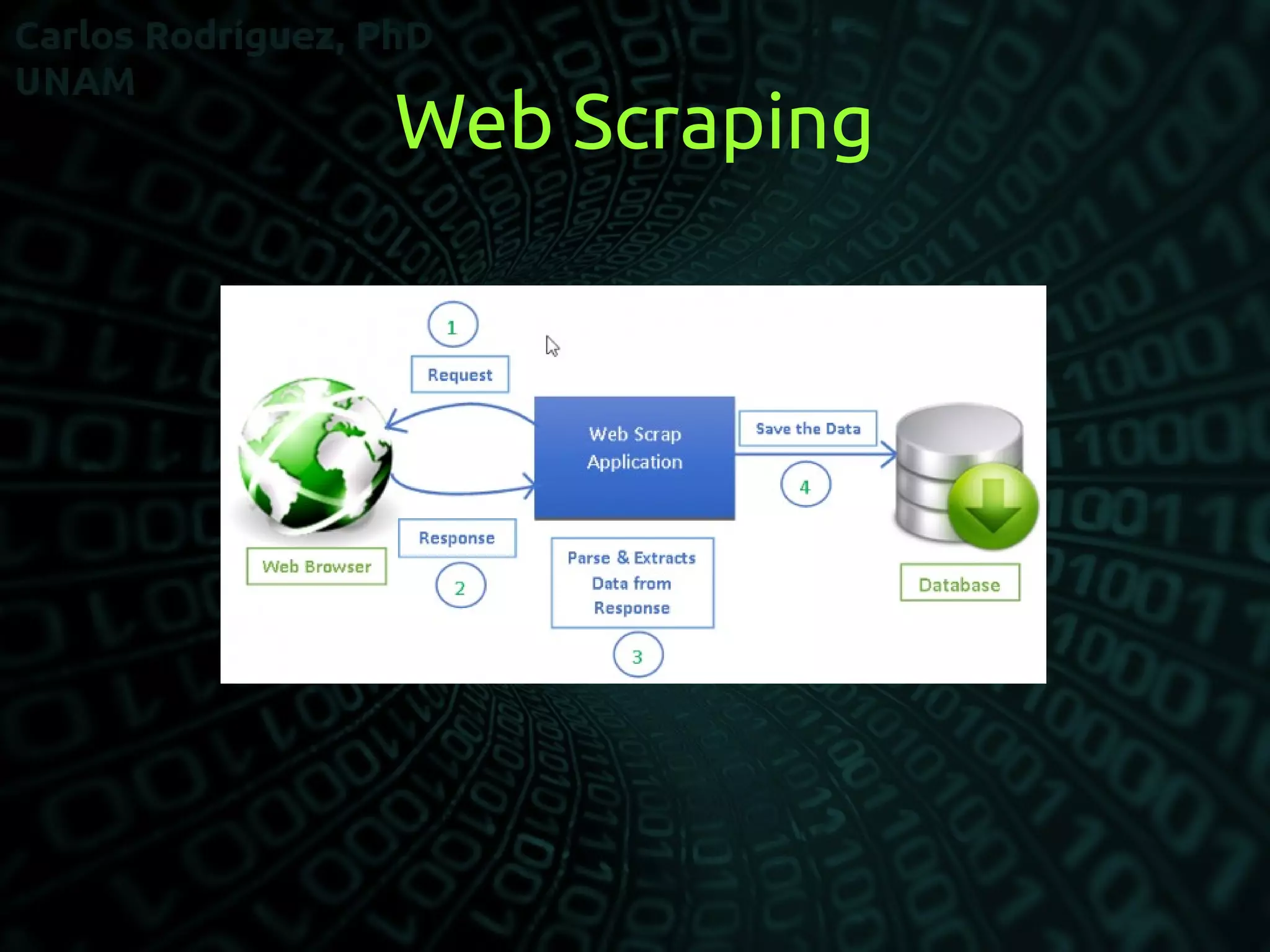








Web scraping involves extracting data from websites in an automated manner, typically using bots and crawlers. It involves fetching web pages and then parsing and extracting the desired data, which can then be stored in a local database or spreadsheet for later analysis. Common uses of web scraping include extracting contact information, product details, or other structured data from websites to use for purposes like monitoring prices, reviewing competition, or data mining. Newer forms of scraping may also listen to data feeds from servers using formats like JSON.



































































