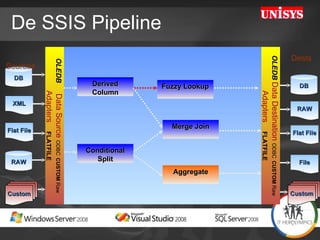
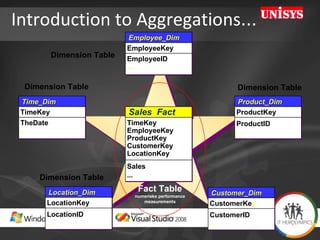
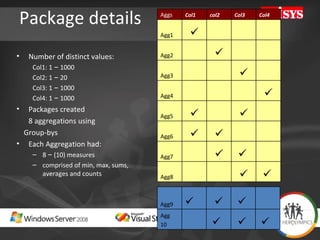
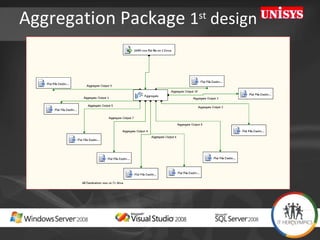
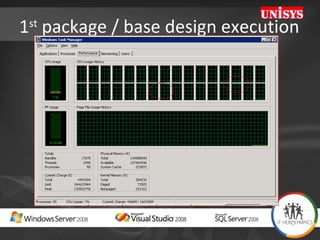
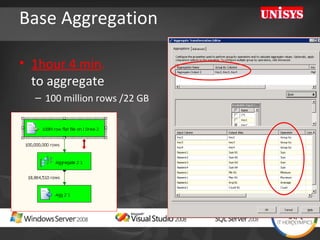
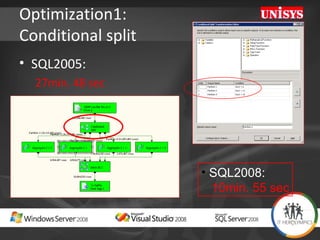
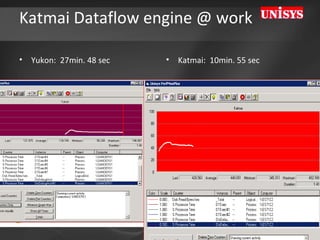
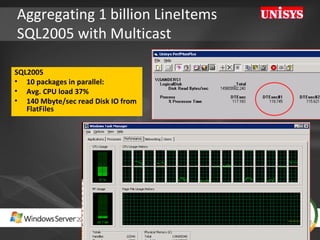
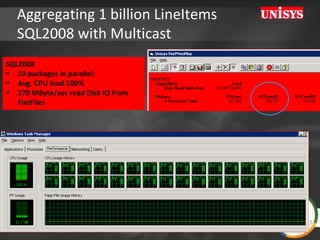
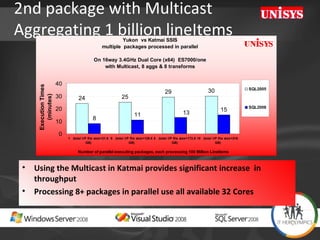
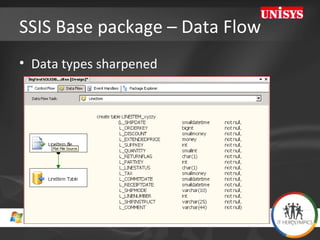
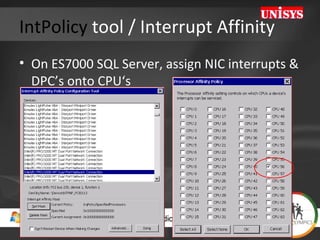
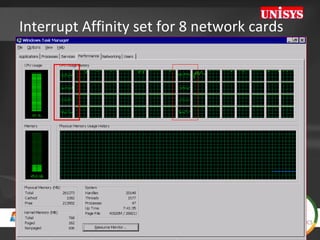
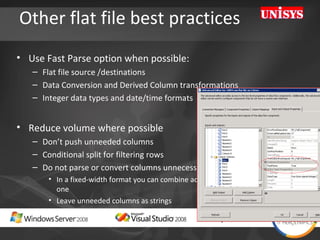
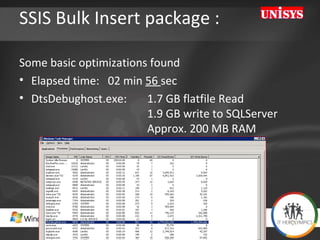
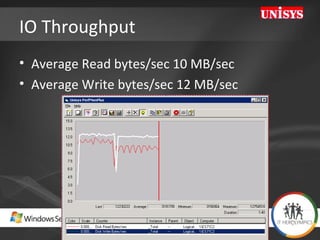
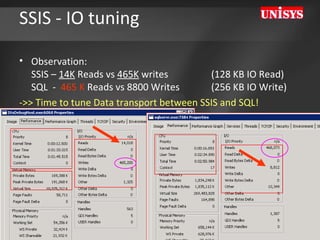
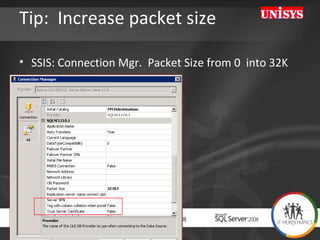
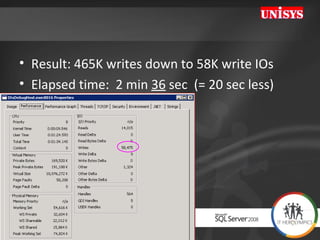
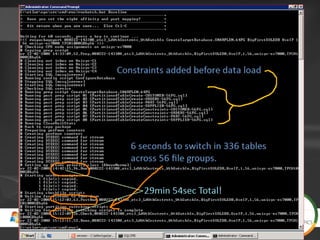
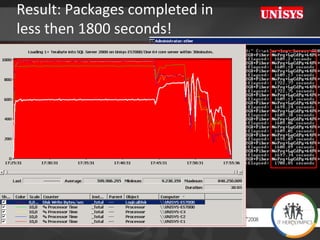
The document compares the performance of SQL Server Integration Services (SSIS) packages between SQL Server 2005 and 2008. It describes a study that loaded and aggregated over 1 billion rows of data from flat files using SSIS packages on high-end Unisys servers. The study found that SSIS 2008 packages with the optimized dataflow engine were over 3 times faster than equivalent SSIS 2005 packages for the same workload. Hardware upgrades, SQL Server 2008 configuration changes, and SSIS package optimizations all contributed to improved performance.


![SQL Server 2005 vs 2008 Integration Services World Record Performance! Henk van der Valk Workload Performance Architect Unisys ES7000 Performance Centers [email_address]](https://image.slidesharecdn.com/HeroLympicsEngV03HenkvdValk-123090904479-phpapp01/85/HeroLympics-Eng-V03-Henk-Vd-Valk-2-320.jpg)















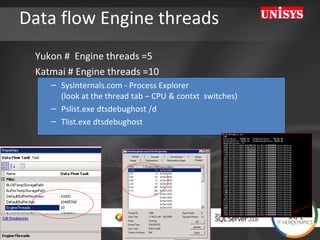


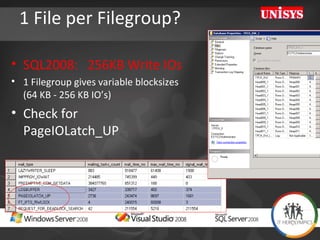
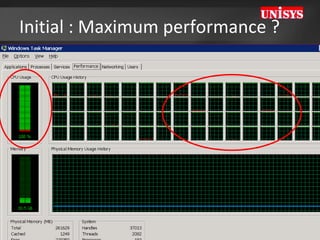
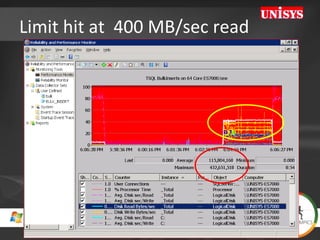

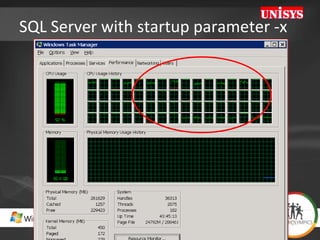
![Tip: Soft Numa on 64 cores Assign BULK INSERT Tasks to dedicated CPU’s (both SQL2005/2008) [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\100\NodeConfiguration\Node63] "CpuMask"=hex:00,00,00,00,00,00,00,80 [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQLServer\SuperSocketNetLib\Tcp] "ListenOnAllIPs"=dword:00000001 [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQLServer\SuperSocketNetLib\Tcp\IPAll] "TcpPort"="2000[0x00000001],2001[0x00000002],](https://image.slidesharecdn.com/HeroLympicsEngV03HenkvdValk-123090904479-phpapp01/85/HeroLympics-Eng-V03-Henk-Vd-Valk-37-320.jpg)






![Seeing Today - Securing tomorrow [email_address]](https://image.slidesharecdn.com/HeroLympicsEngV03HenkvdValk-123090904479-phpapp01/85/HeroLympics-Eng-V03-Henk-Vd-Valk-61-320.jpg)
























![[db tech showcase Tokyo 2017] A11: SQLite - The most used yet least appreciat...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-keynote-20170905-170911071000-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[DBA]_HiramFleitas_SQL_PASS_Summit_2017_Summary](https://cdn.slidesharecdn.com/ss_thumbnails/dbahiramfleitassqlpasssummit2017summary-180202201153-thumbnail.jpg?width=640&height=640&fit=bounds)















![[Uruguay] DB2 for i: 7.1 Overview - Hernando Bedoya](https://cdn.slidesharecdn.com/ss_thumbnails/db271overview-111121133335-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















