Downloaded 43 times





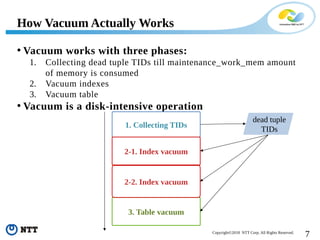
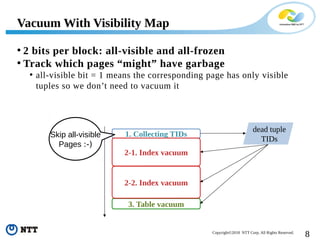
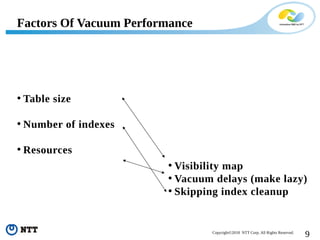
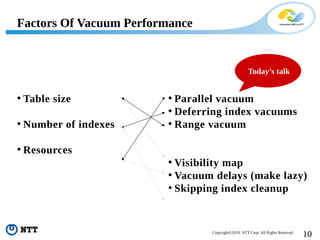
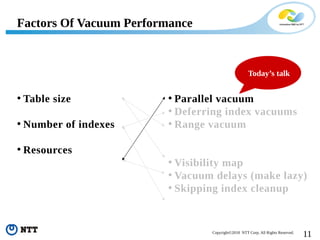




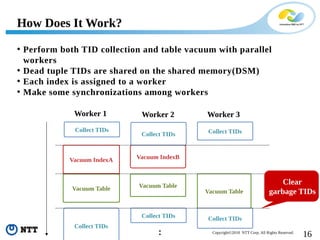
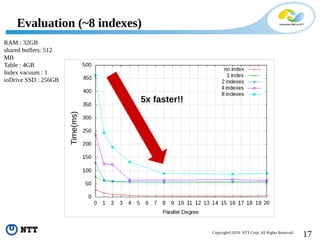


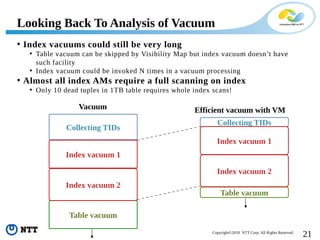


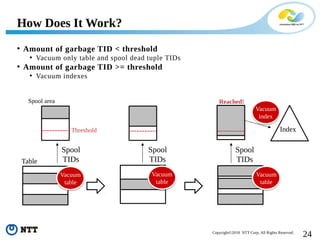


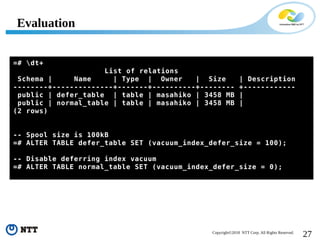

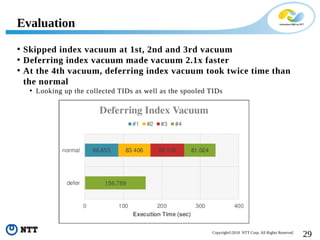





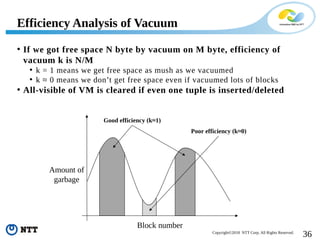
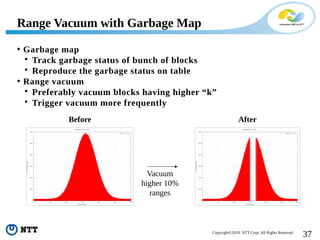

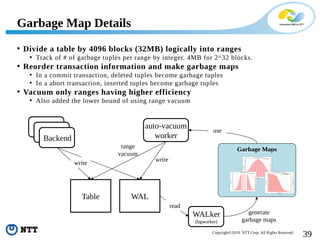

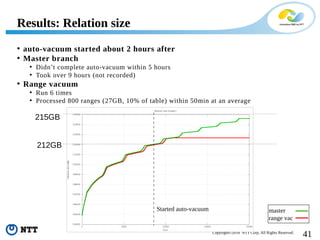
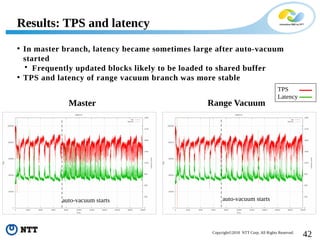





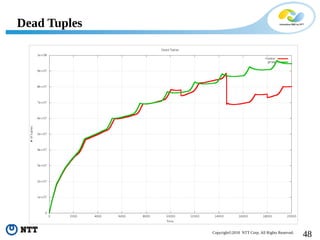

The document discusses improving the efficiency of PostgreSQL vacuums. It proposes performing vacuums in parallel using multiple worker processes to shorten execution time. It also suggests deferring index vacuums by spoiling dead tuple IDs to a threshold to reduce the number of expensive index vacuum operations. Range vacuums are proposed to vacuum specific blocks to minimize disruption to transactions while still making progress.



















































































