Download to read offline















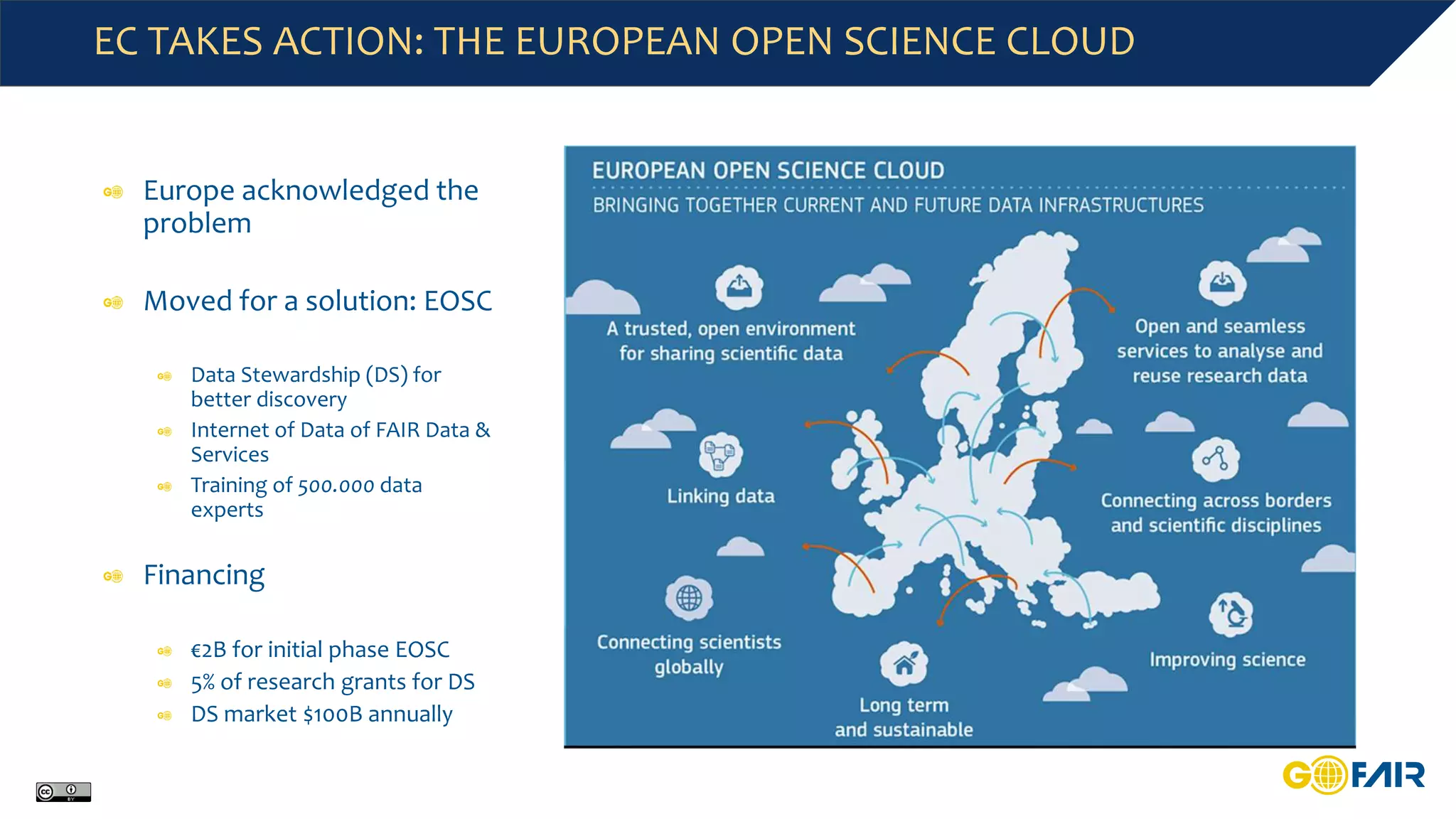




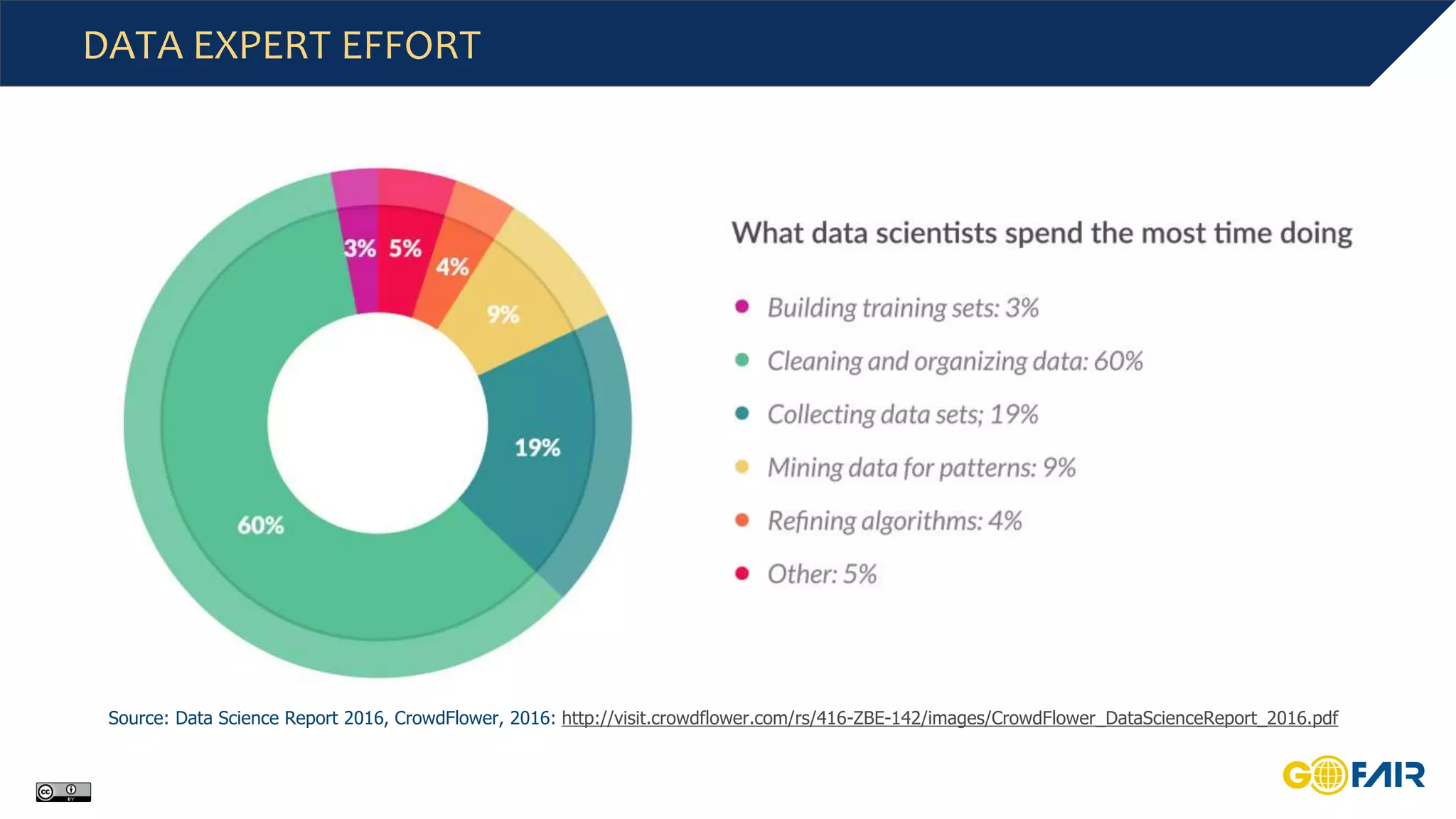





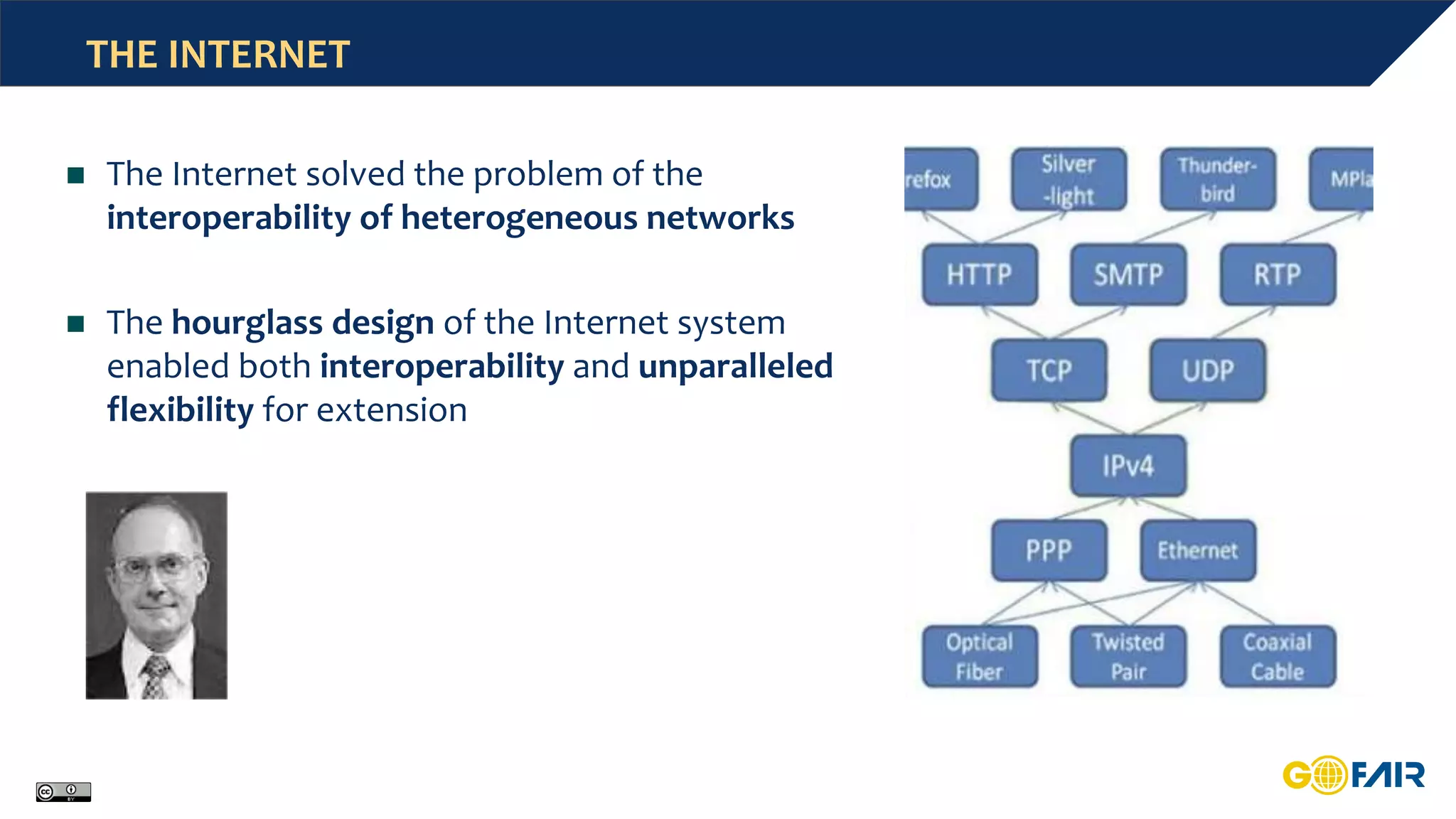


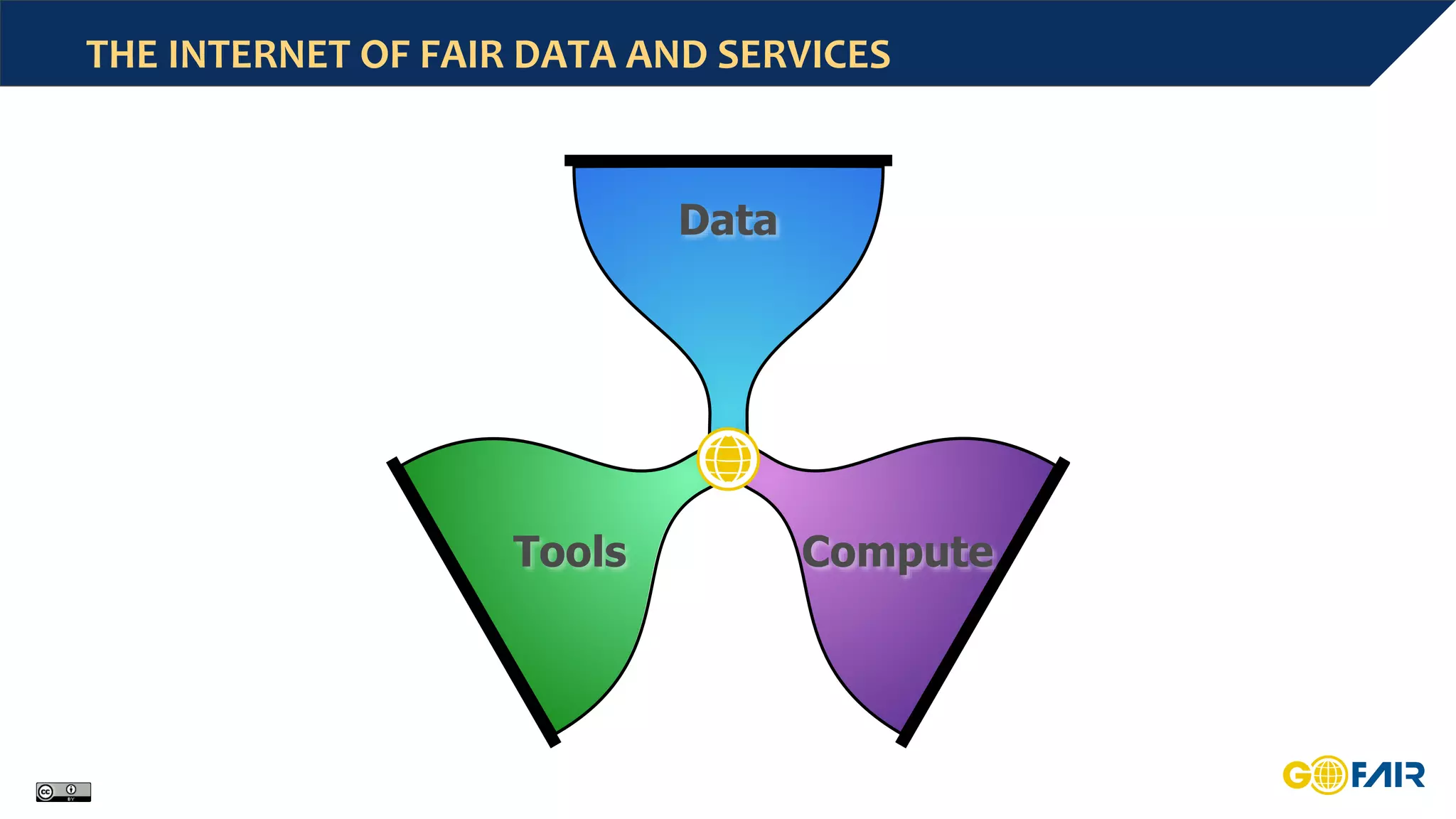










This document discusses challenges around big data and the need for cross-domain interoperability in the Internet of Fair Data and Services (IFDS). It introduces the FAIR data principles which aim to make data findable, accessible, interoperable and reusable. The principles address metadata, identifiers, vocabularies and licensing. Adopting FAIR could reduce costs associated with data preparation and management. The IFDS builds on these principles to enable control and negotiation over digital resources across heterogeneous systems through an "hourglass" design. Communities are encouraged to define shared standards and services to improve interoperability according to FAIR.










































































