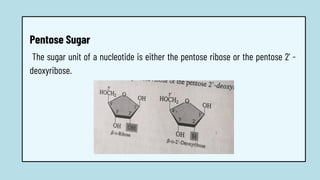
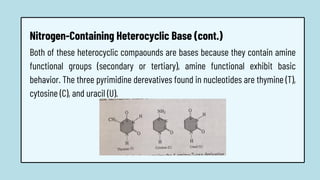
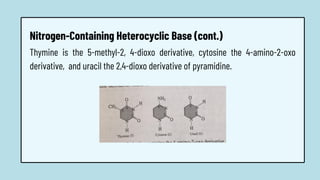
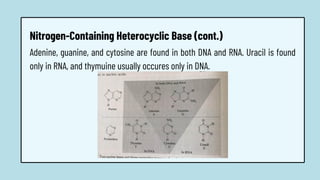
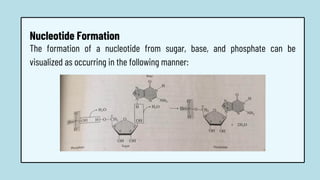
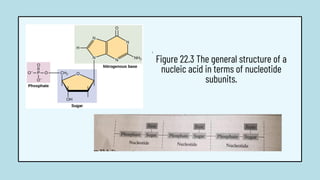
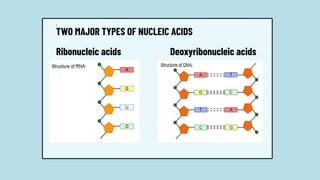
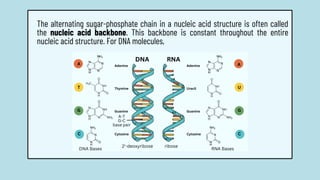
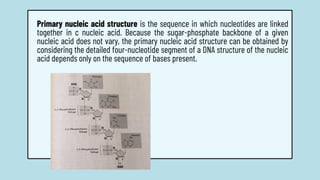
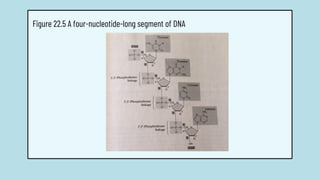
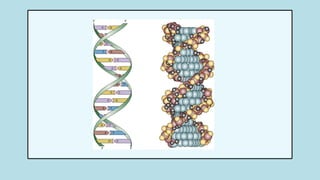
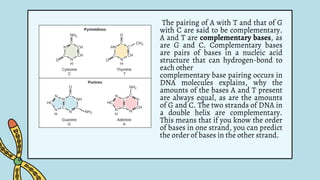
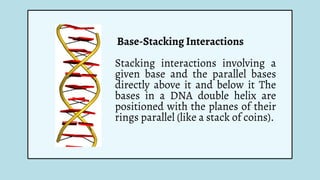
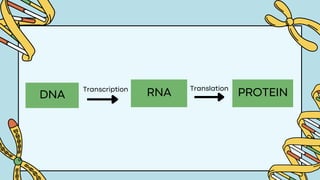
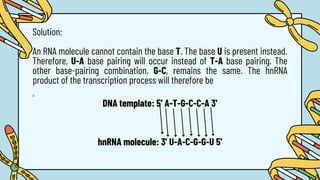
The document discusses the structure and functions of nucleic acids, primarily DNA and RNA, highlighting their roles in genetic information storage and transmission. It explains the composition of nucleotides, which are the building blocks of nucleic acids, including the differences between RNA and DNA in terms of their sugar types and nitrogenous bases. Additionally, the document covers the DNA double helix structure, replication processes, and the significance of complementary base pairing.