Download to read offline





![CoreLinuxforRedHatandFedoralearningunderGNUFreeDocumentationLicense-Copyleft(c)AcácioOliveira2012
Everyoneispermittedtocopyanddistributeverbatimcopiesofthislicensedocument,changingisallowed
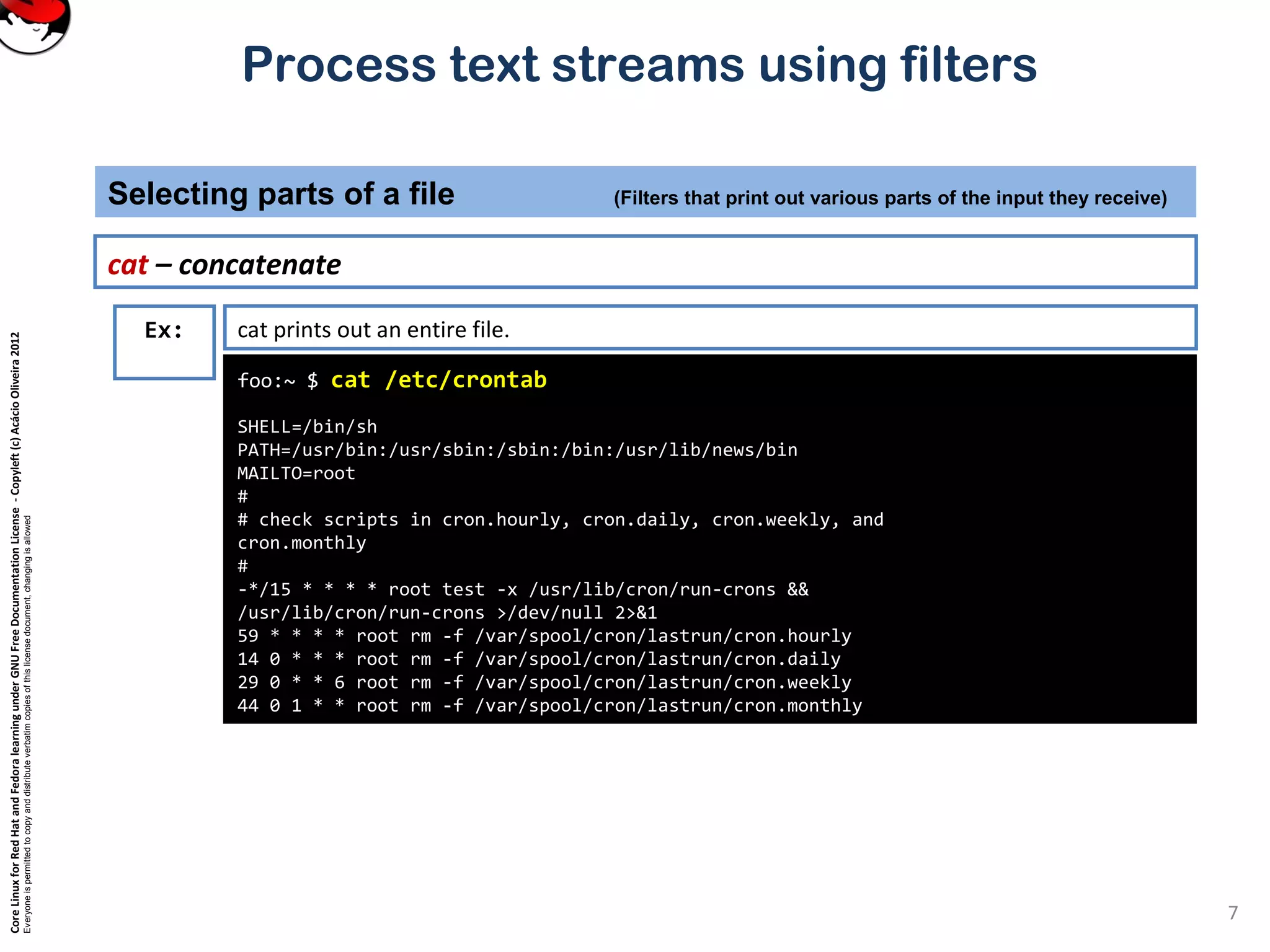
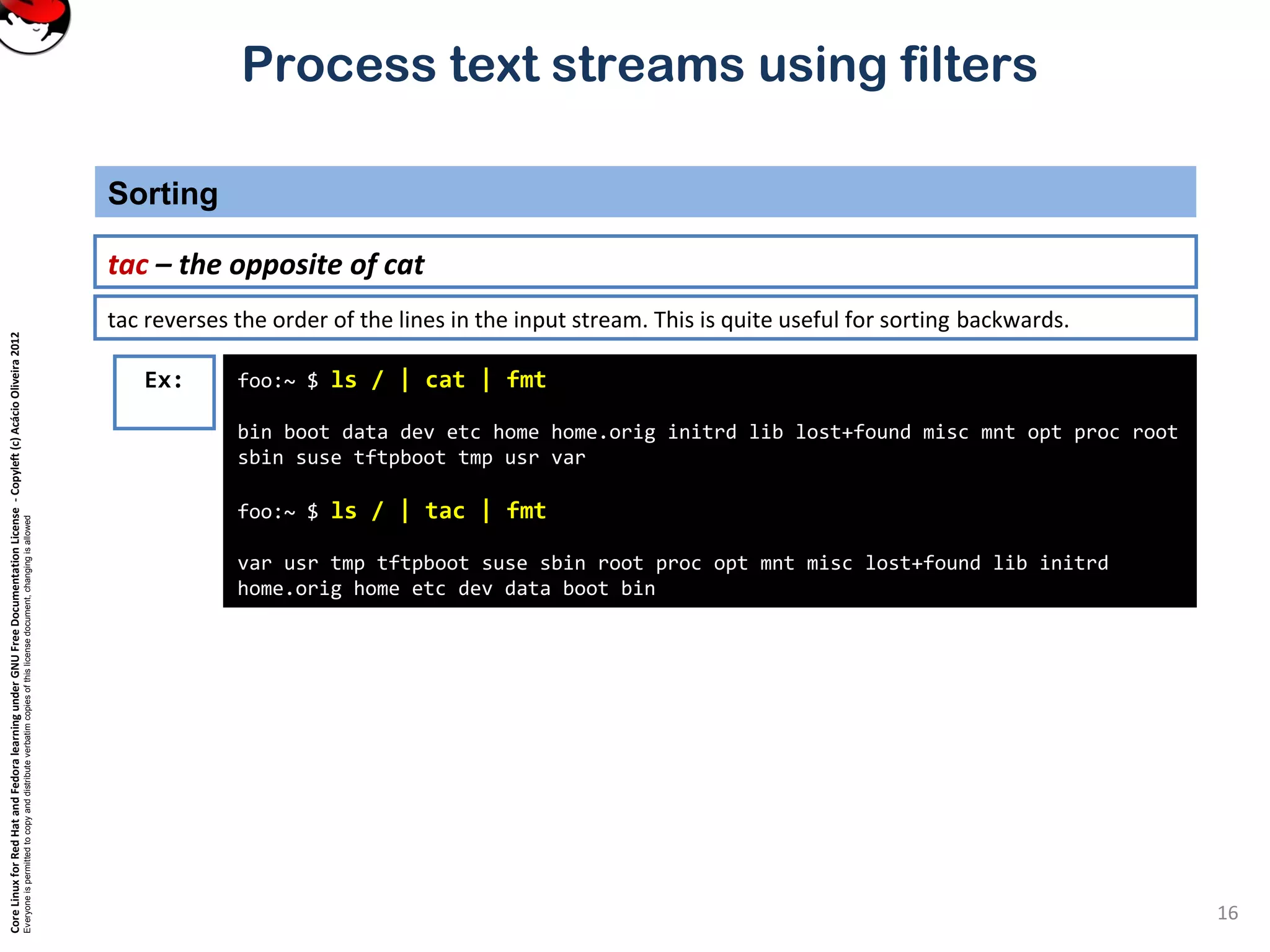
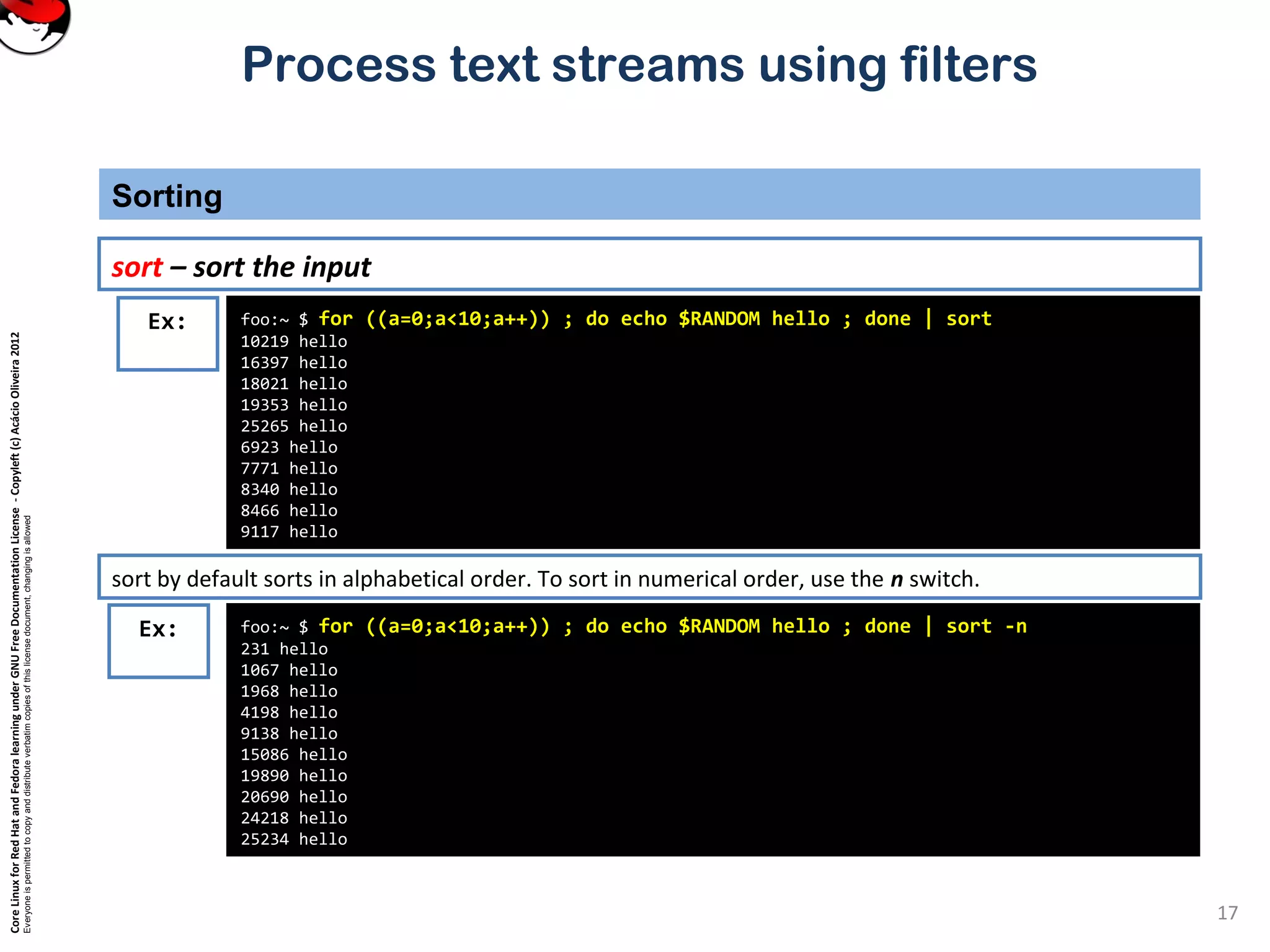
Process text streams using filters
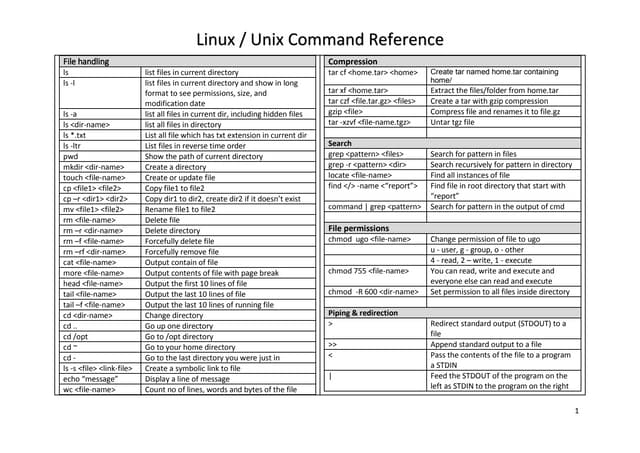
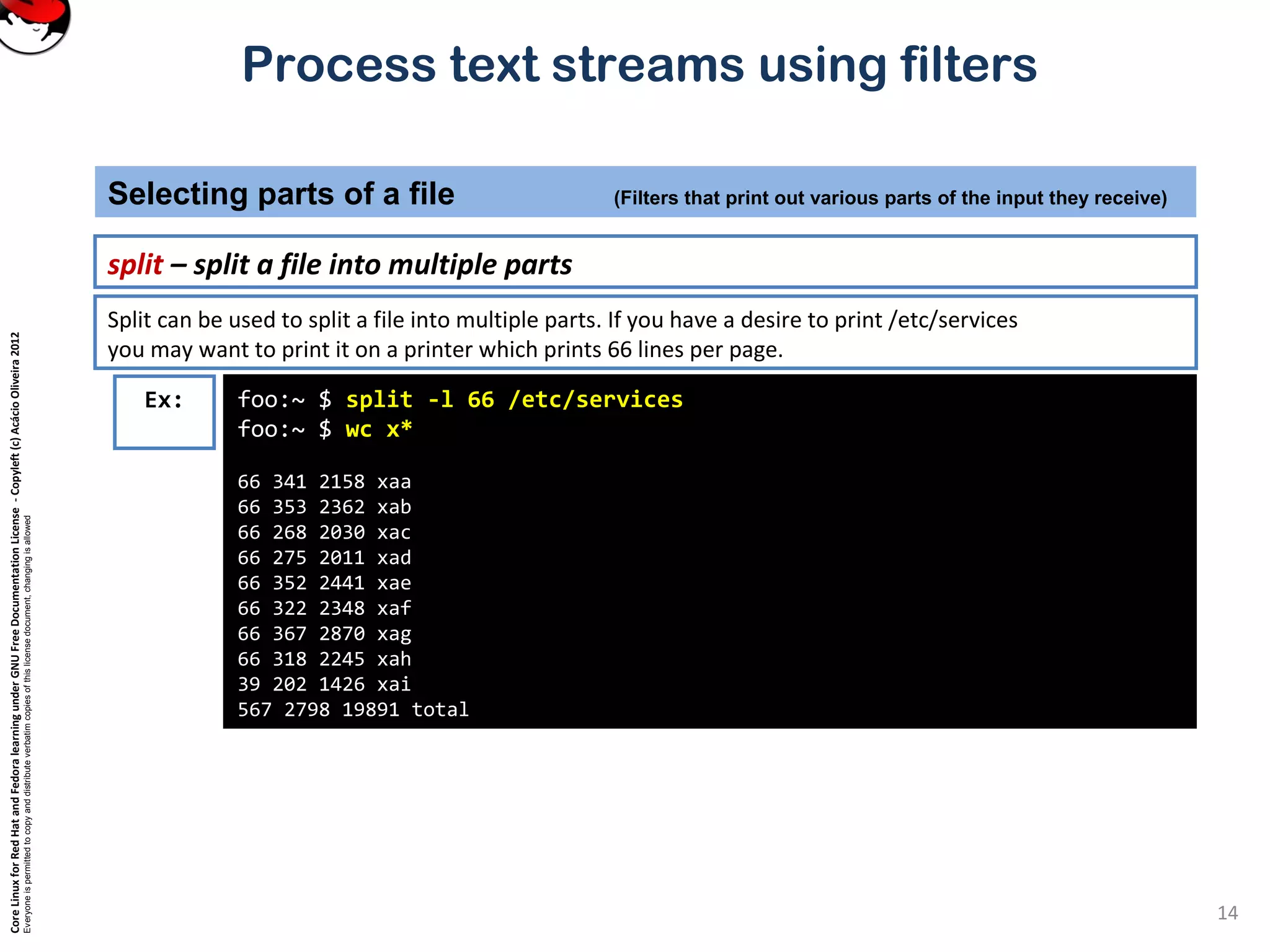
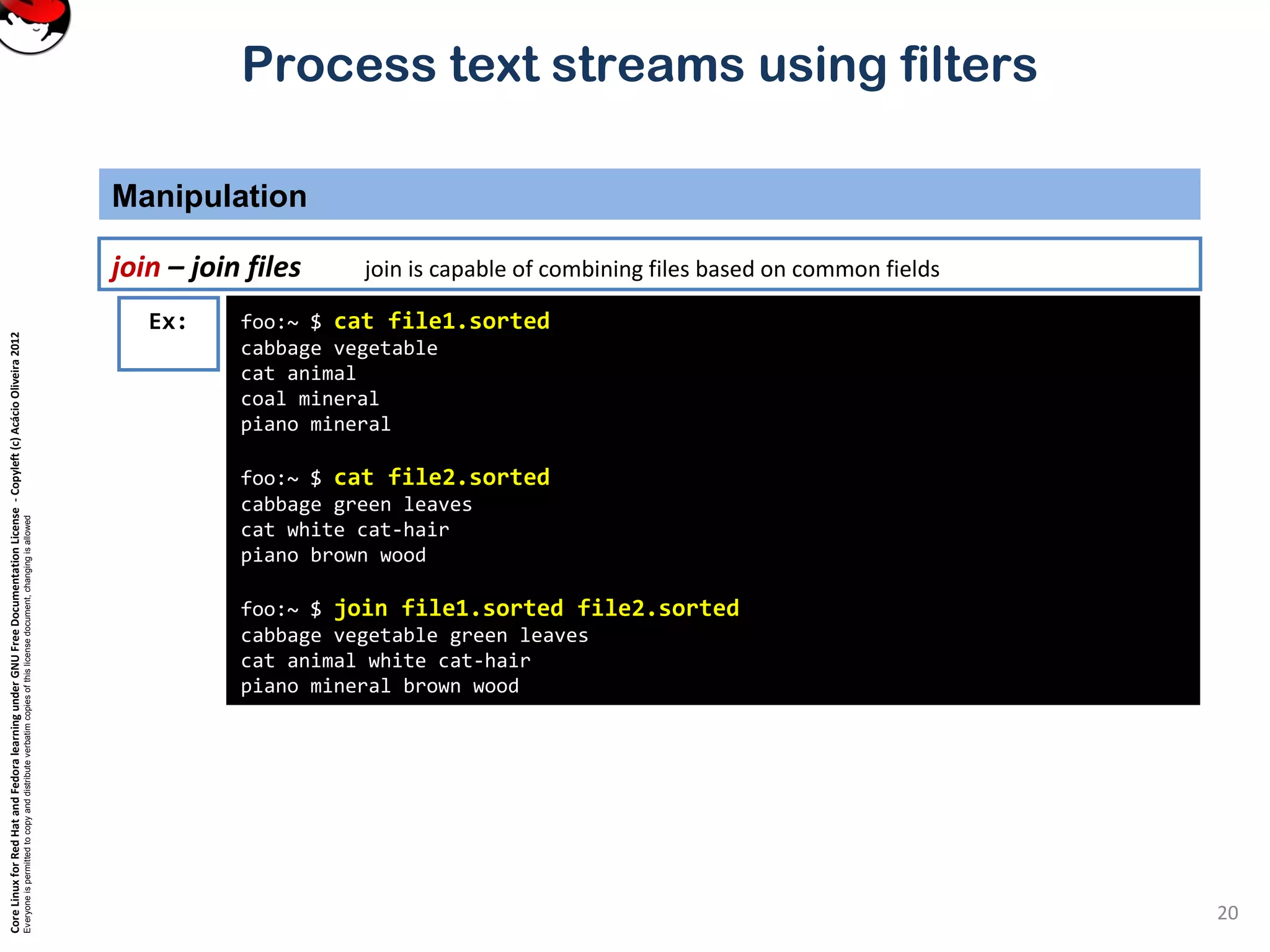
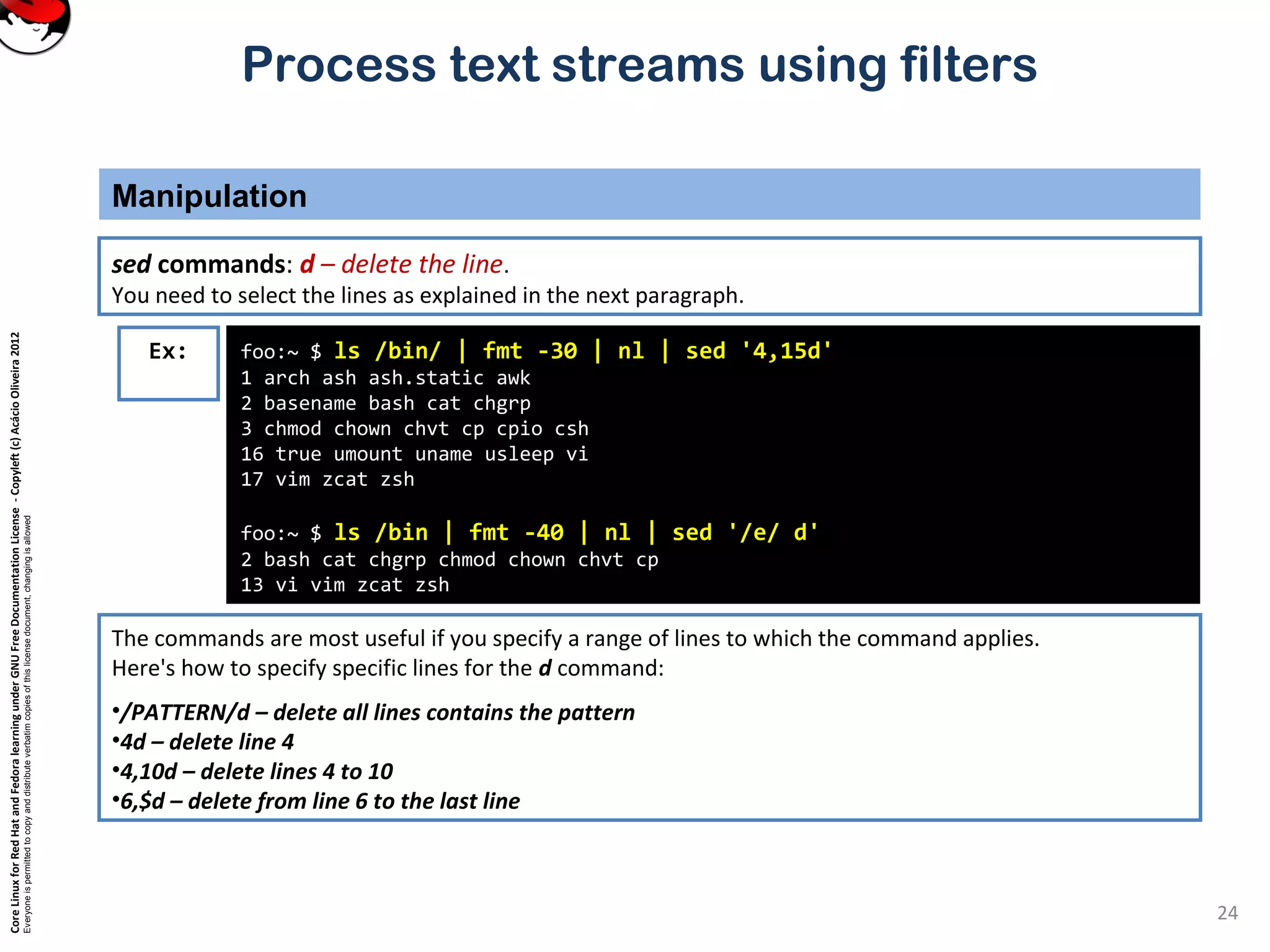
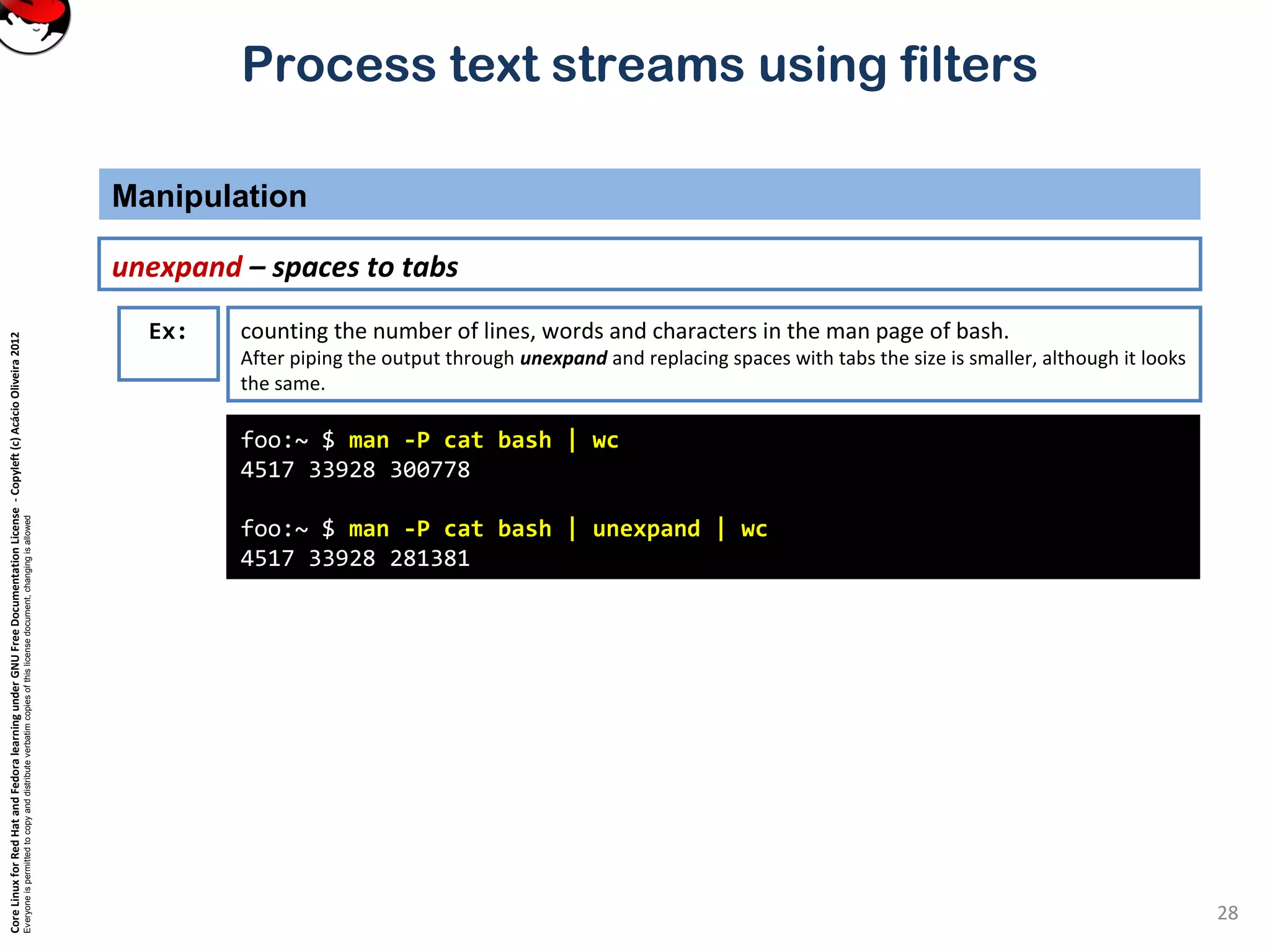
tail – show the end of a file
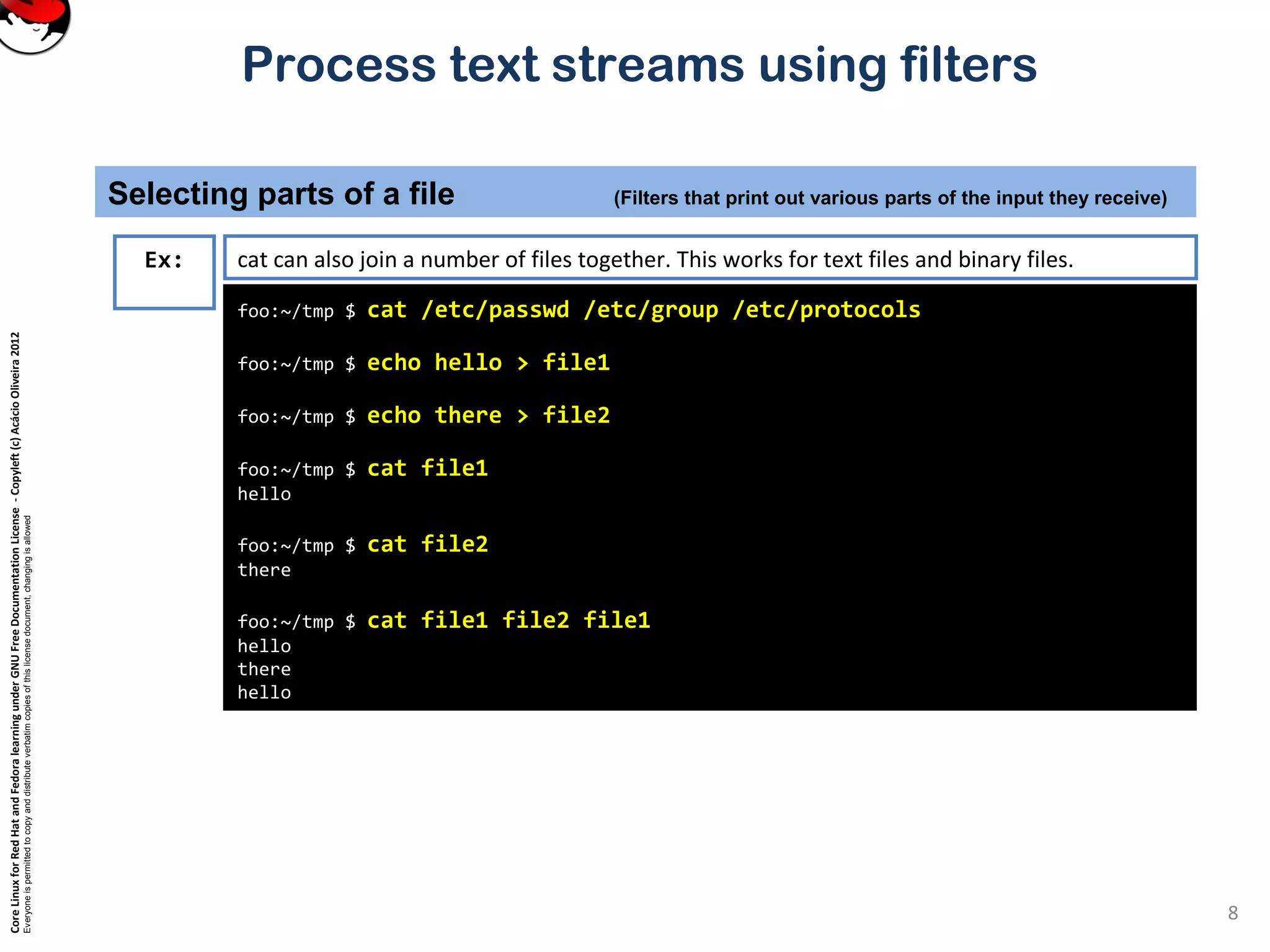
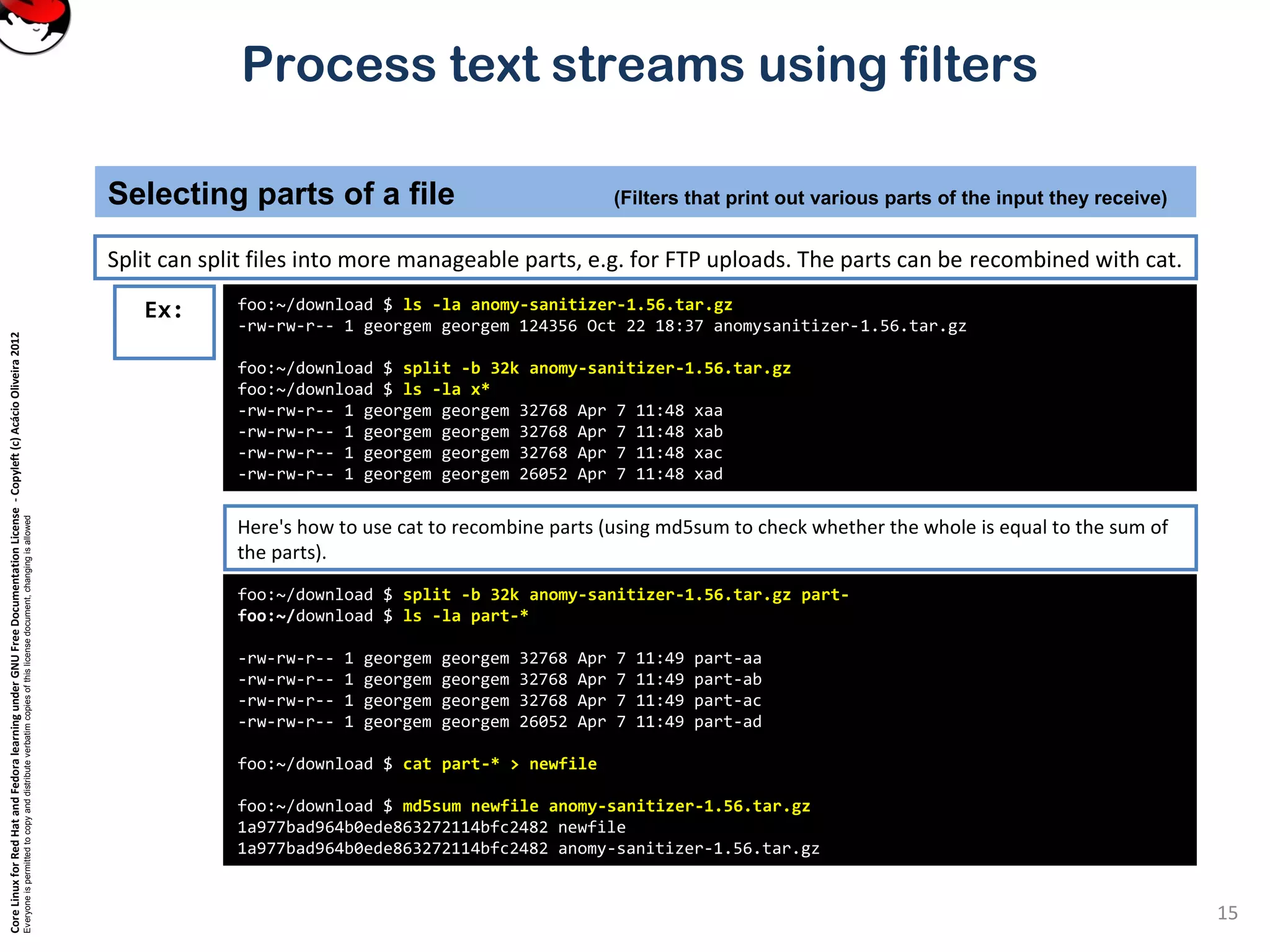
Selecting parts of a file (Filters that print out various parts of the input they receive)
11
root@foo:root # tail /var/log/messages
Apr 7 11:19:34 foo dhcpd: Wrote 9 leases to leases file.
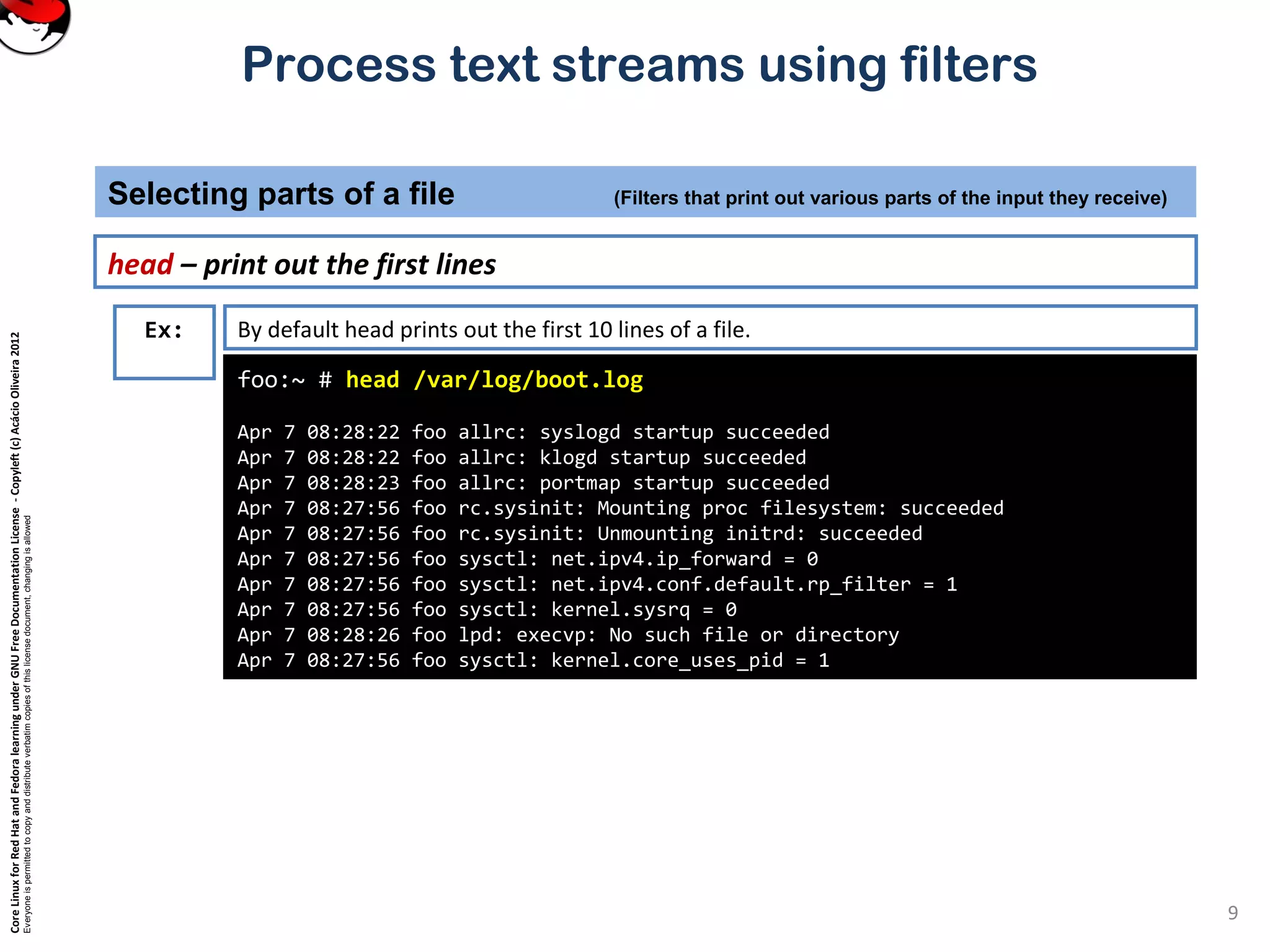
Apr 7 11:19:34 foo dhcpd: DHCPREQUEST for 10.0.0.169 from
00:80:ad:02:65:7c via eth0
Apr 7 11:19:35 foo dhcpd: DHCPACK on 10.0.0.169 to
00:80:ad:02:65:7c via eth0
Apr 7 11:20:01 foo kdm[1151]: Cannot convert Internet address
10.0.0.168 to host name
Apr 7 11:26:46 foo ipop3d[22026]: connect from 10.0.0.10
(10.0.0.10)
Apr 7 11:26:55 foo ipop3d[22028]: connect from 10.0.0.10
(10.0.0.10)
Apr 7 11:26:58 foo ipop3d[22035]: connect from 10.0.0.3 (10.0.0.3)
Apr 7 11:27:01 foo ipop3d[22036]: connect from 10.0.0.3 (10.0.0.3)
Apr 7 11:29:31 foo kdm[21954]: pam_unix2: session started for user
joe, service xdm
Apr 7 11:32:41 foo sshd[22316]: Accepted publickey for root from
10.0.0.143 port 1250 ssh2
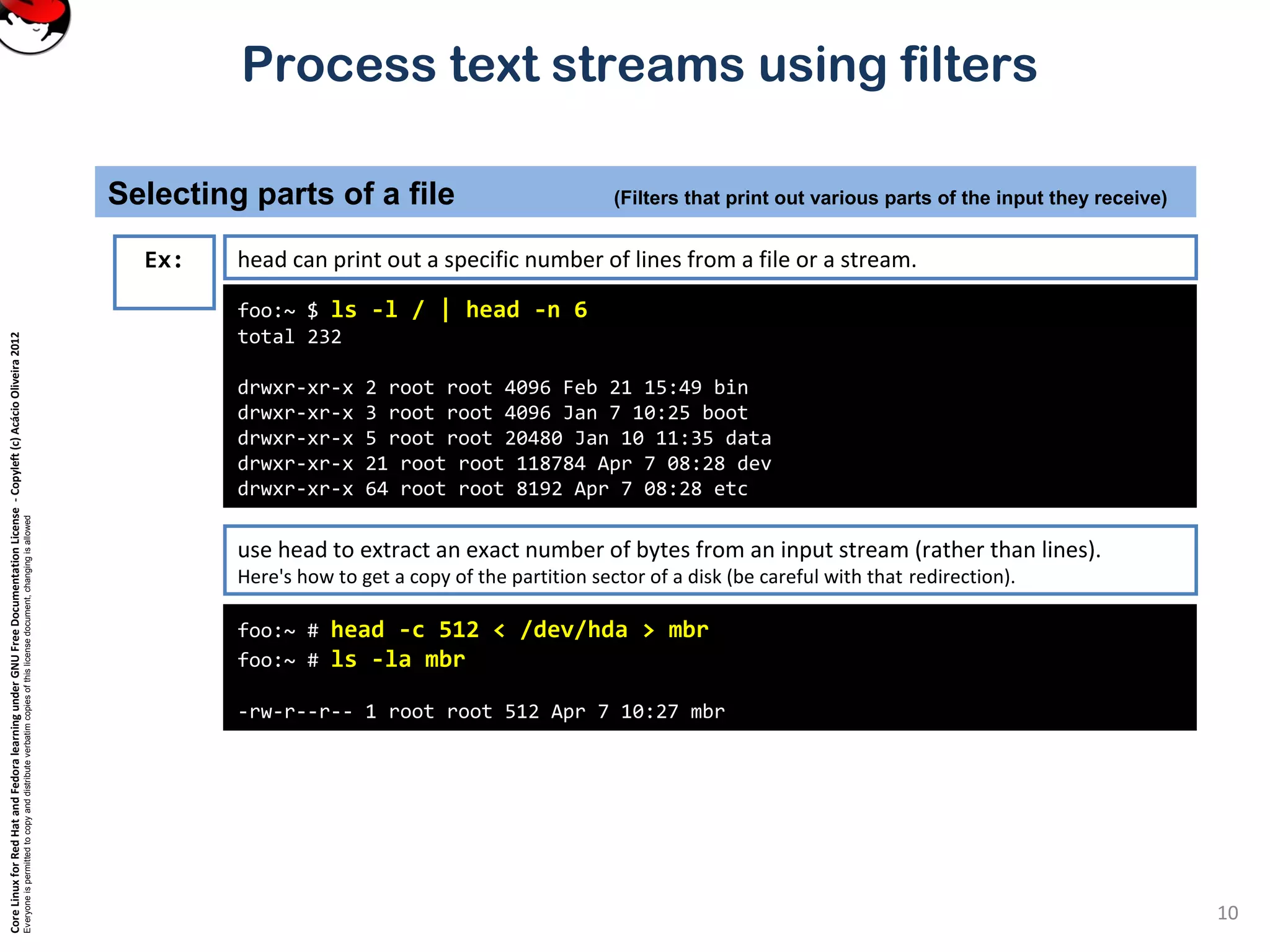
Ex: tail is just like head, but it shows the tail end of the file.
tail can be used to watch a file as it grows.
Run the command tail –f /var/log/messages on one console and then log in on another virtual console.
tail –n 20 file or tail -20 file will show last 20 lines of file. tail –c 20 file will show last 20 characters of a file.](https://image.slidesharecdn.com/c3zpnzdps4ck52z9pvrn-signature-b02a6c073768d8536fdd50c0a47af6292b168fbd705c8180447bb0b754b59738-poli-141223132219-conversion-gate01/75/3-2-process-text-streams-using-filters-11-2048.jpg)
![CoreLinuxforRedHatandFedoralearningunderGNUFreeDocumentationLicense-Copyleft(c)AcácioOliveira2012
Everyoneispermittedtocopyanddistributeverbatimcopiesofthislicensedocument,changingisallowed
Process text streams using filters
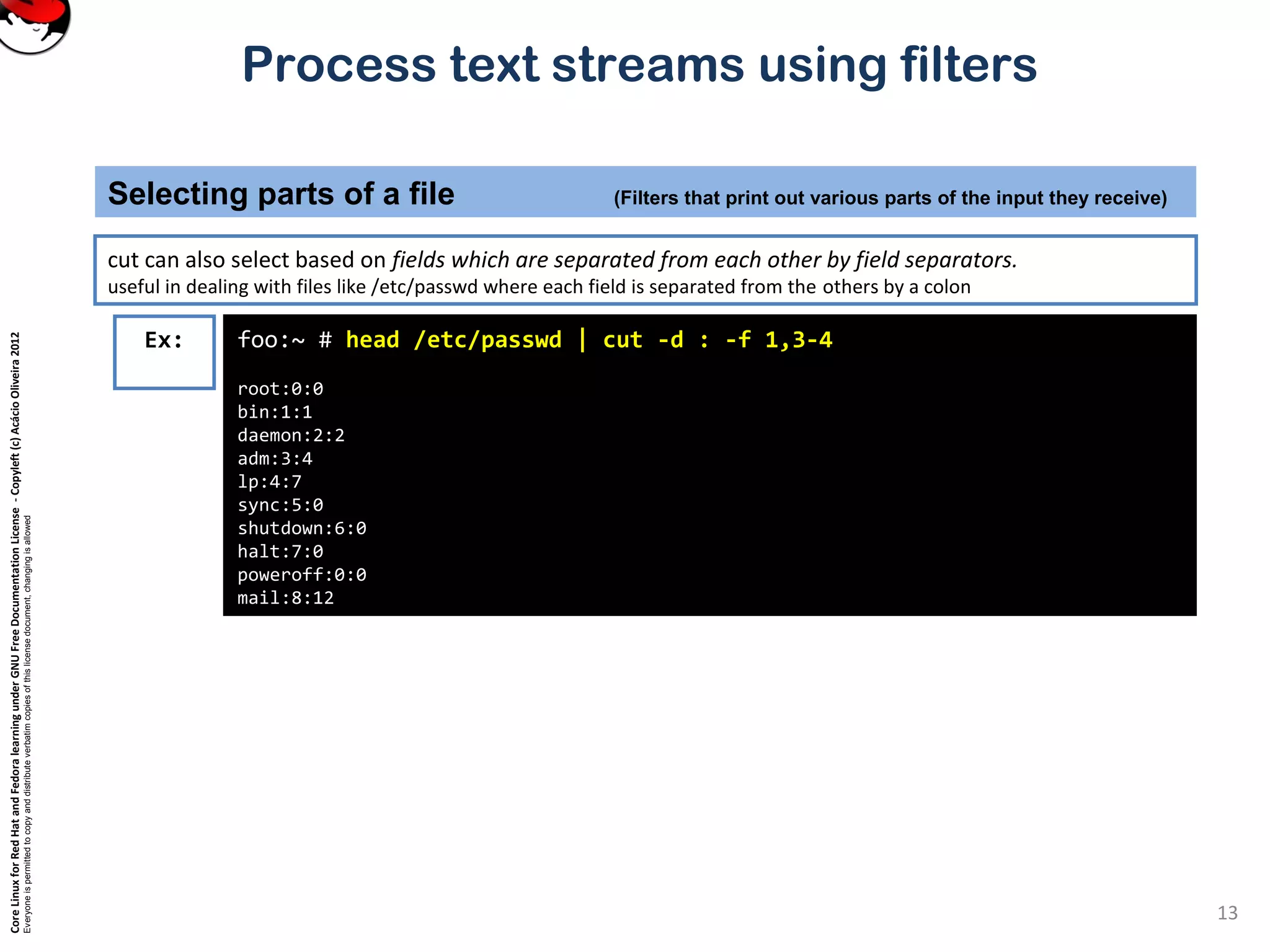
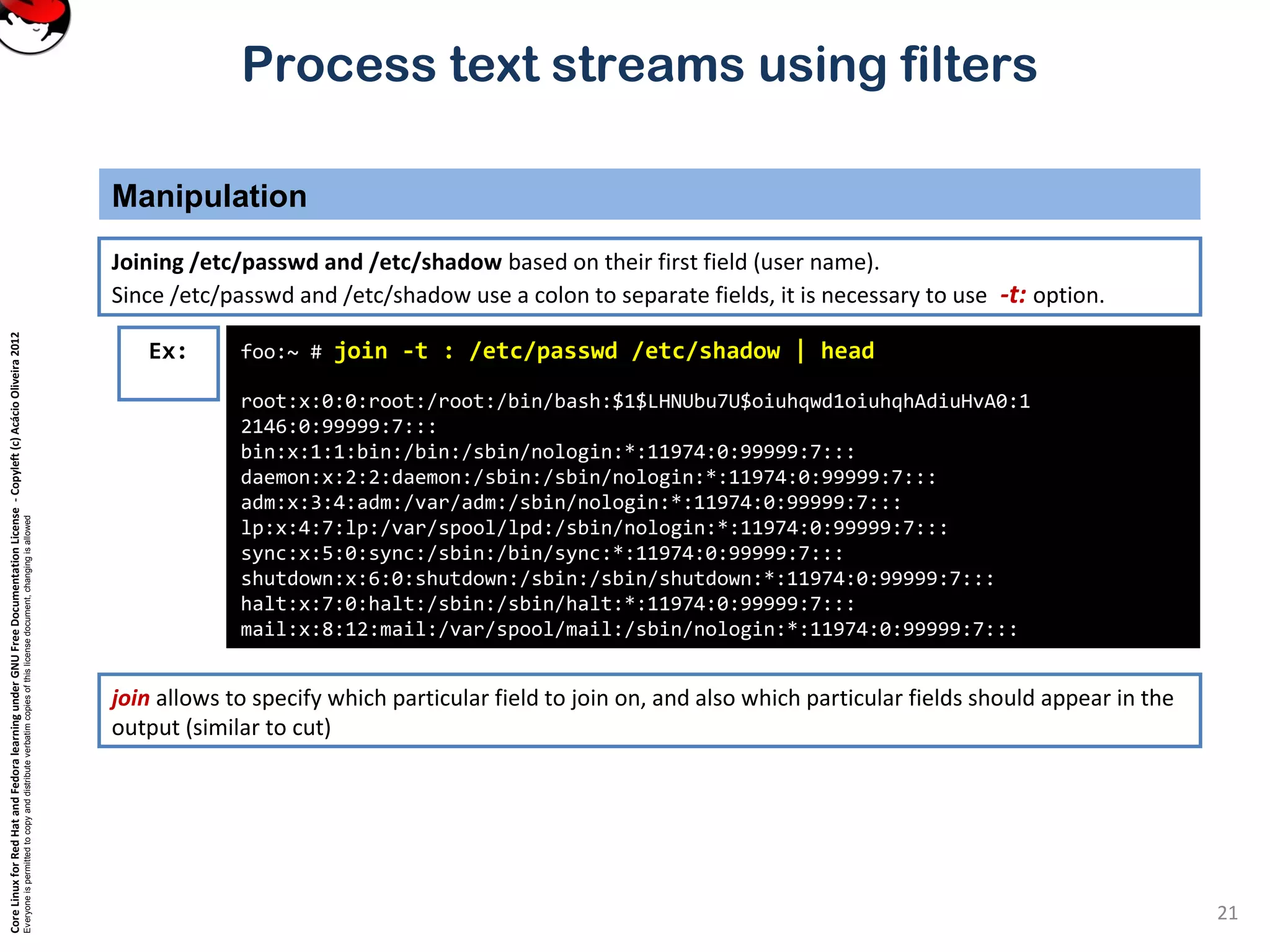
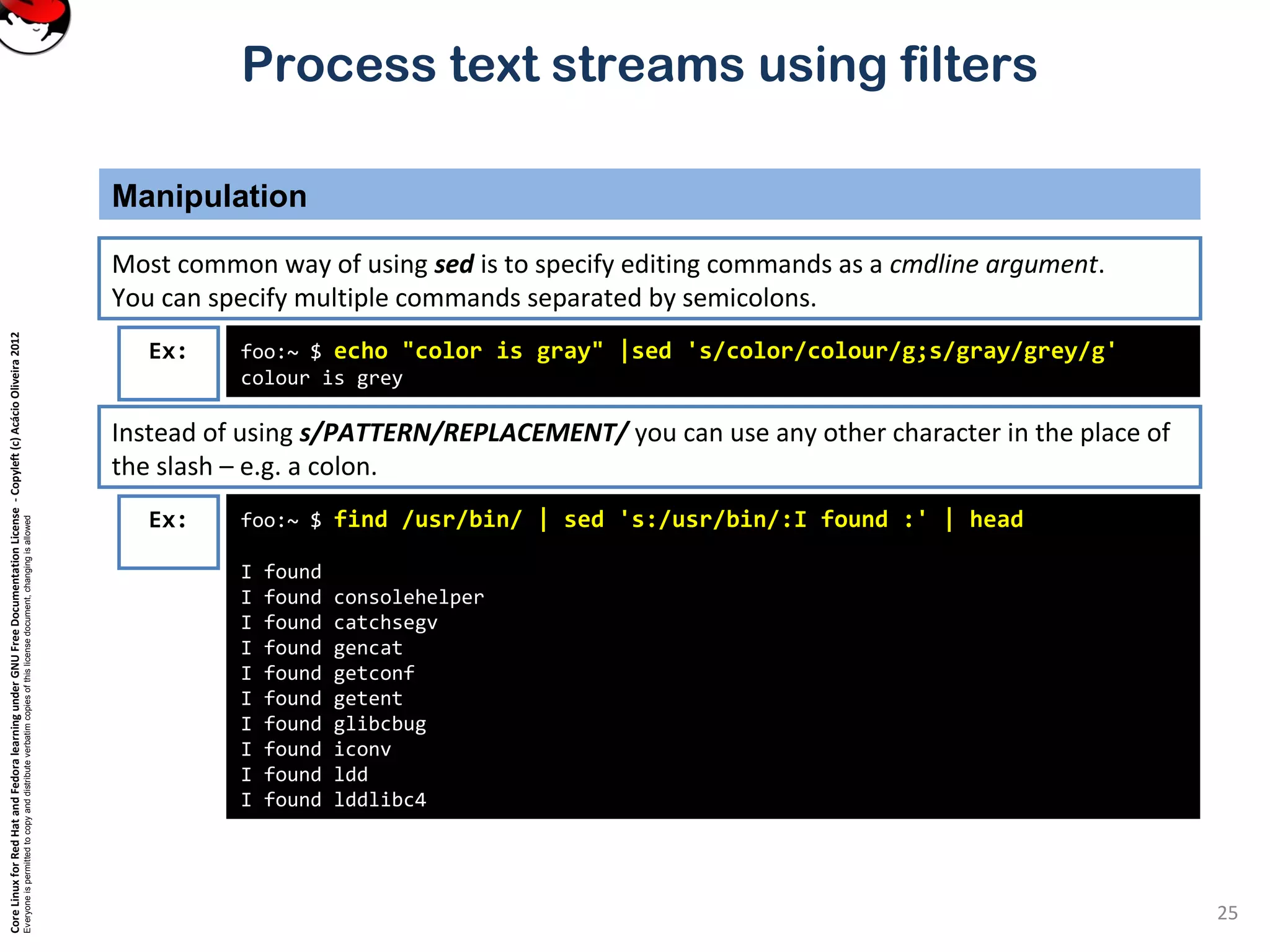
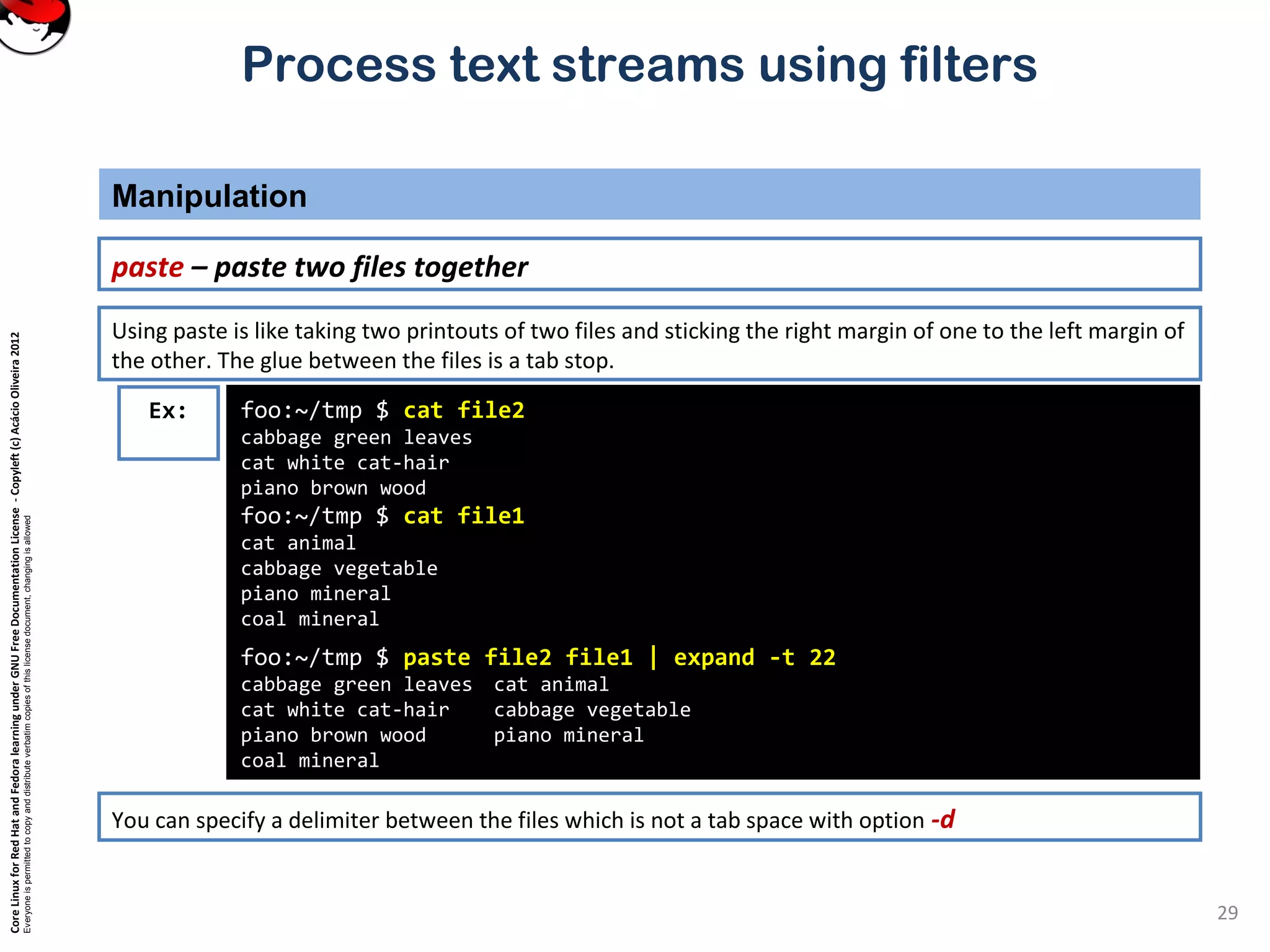
cut – pull out columns
Selecting parts of a file (Filters that print out various parts of the input they receive)
12
root@foo:root # tail /var/log/messages
Apr 7 11:19:34 foo dhcpd: Wrote 9 leases to leases file.
Apr 7 11:19:34 foo dhcpd: DHCPREQUEST for 10.0.0.169 from
00:80:ad:02:65:7c via eth0
Apr 7 11:19:35 foo dhcpd: DHCPACK on 10.0.0.169 to
00:80:ad:02:65:7c via eth0
Apr 7 11:20:01 foo kdm[1151]: Cannot convert Internet address
10.0.0.168 to host name
Apr 7 11:26:46 foo ipop3d[22026]: connect from 10.0.0.10
(10.0.0.10)
Apr 7 11:26:55 foo ipop3d[22028]: connect from 10.0.0.10
(10.0.0.10)
Apr 7 11:26:58 foo ipop3d[22035]: connect from 10.0.0.3 (10.0.0.3)
Apr 7 11:27:01 foo ipop3d[22036]: connect from 10.0.0.3 (10.0.0.3)
Apr 7 11:29:31 foo kdm[21954]: pam_unix2: session started for user
joe, service xdm
Apr 7 11:32:41 foo sshd[22316]: Accepted publickey for root from
10.0.0.143 port 1250 ssh2
Ex:
Cut can be used to select certain columns of the input stream.
Columns can be defined by either their position, or by being separated by field separators.](https://image.slidesharecdn.com/c3zpnzdps4ck52z9pvrn-signature-b02a6c073768d8536fdd50c0a47af6292b168fbd705c8180447bb0b754b59738-poli-141223132219-conversion-gate01/75/3-2-process-text-streams-using-filters-12-2048.jpg)






This document discusses various UNIX commands for processing text streams and filtering text, including cat, cut, head, tail, and split. It provides examples of using each command to select, modify, or restructure the output. The commands can be used to select parts of files like lines (head/tail) or columns (cut), and to split files into multiple parts (split). Pipelines and redirection are also covered.