Download as PDF, PPTX



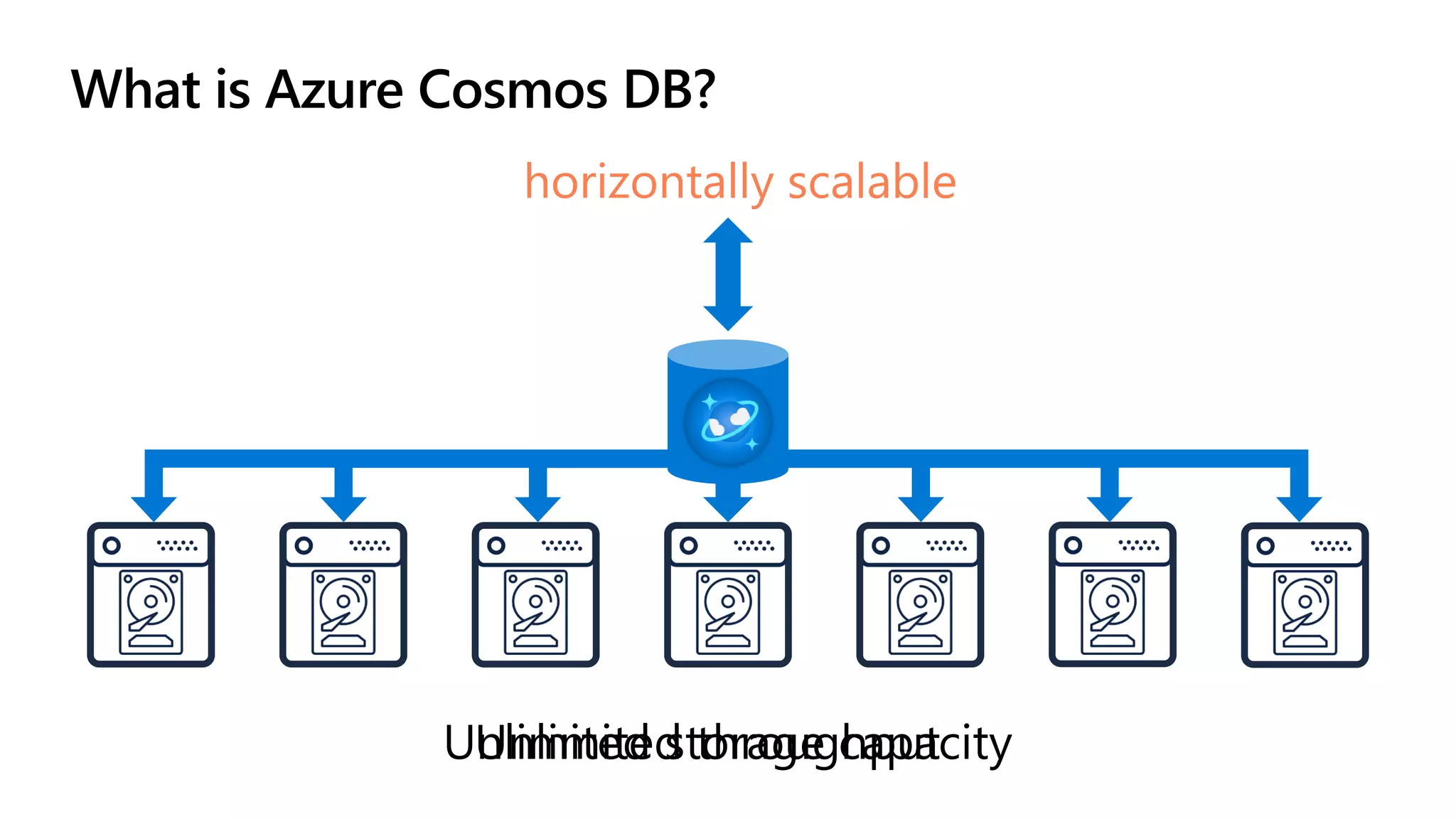
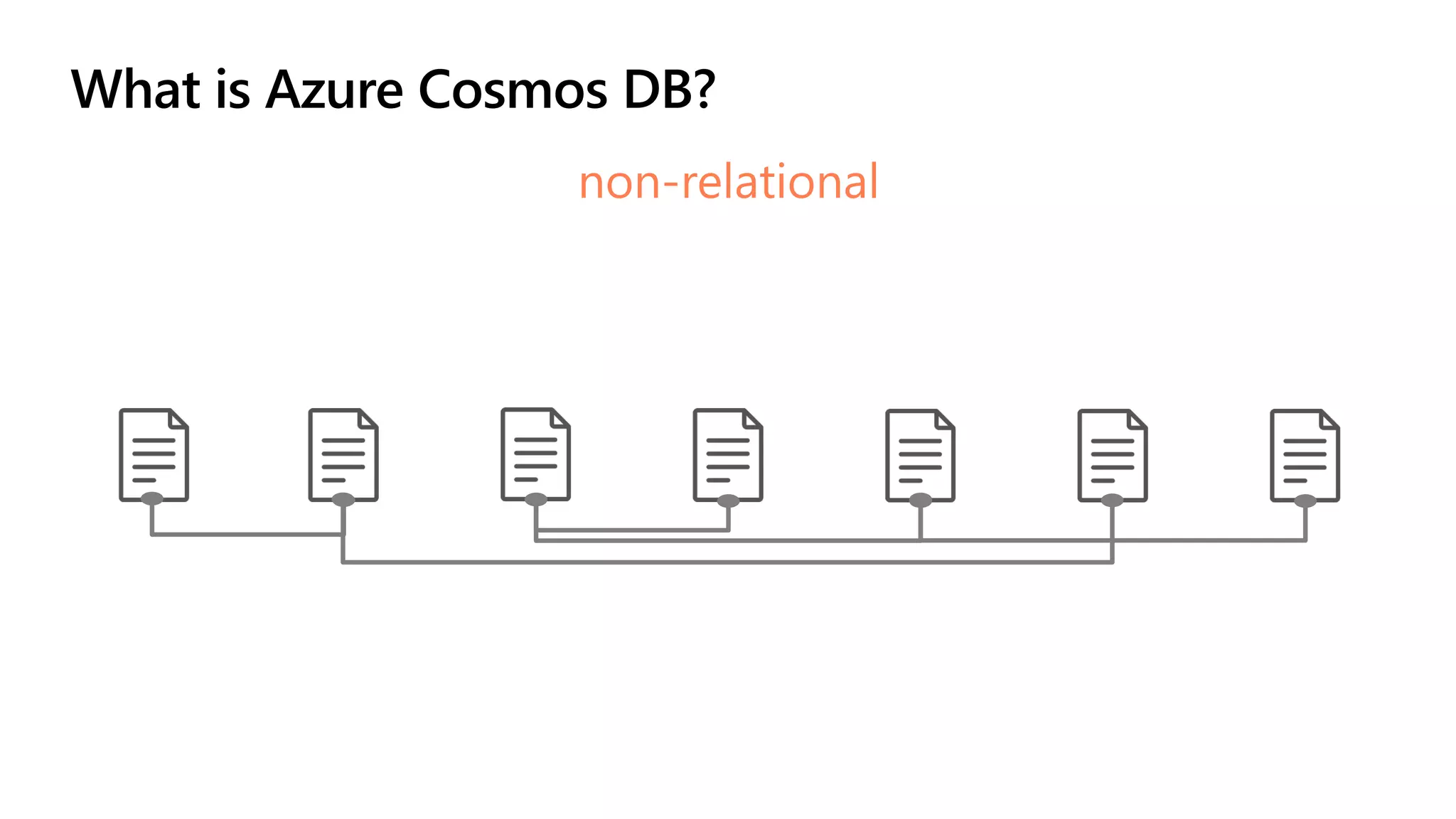
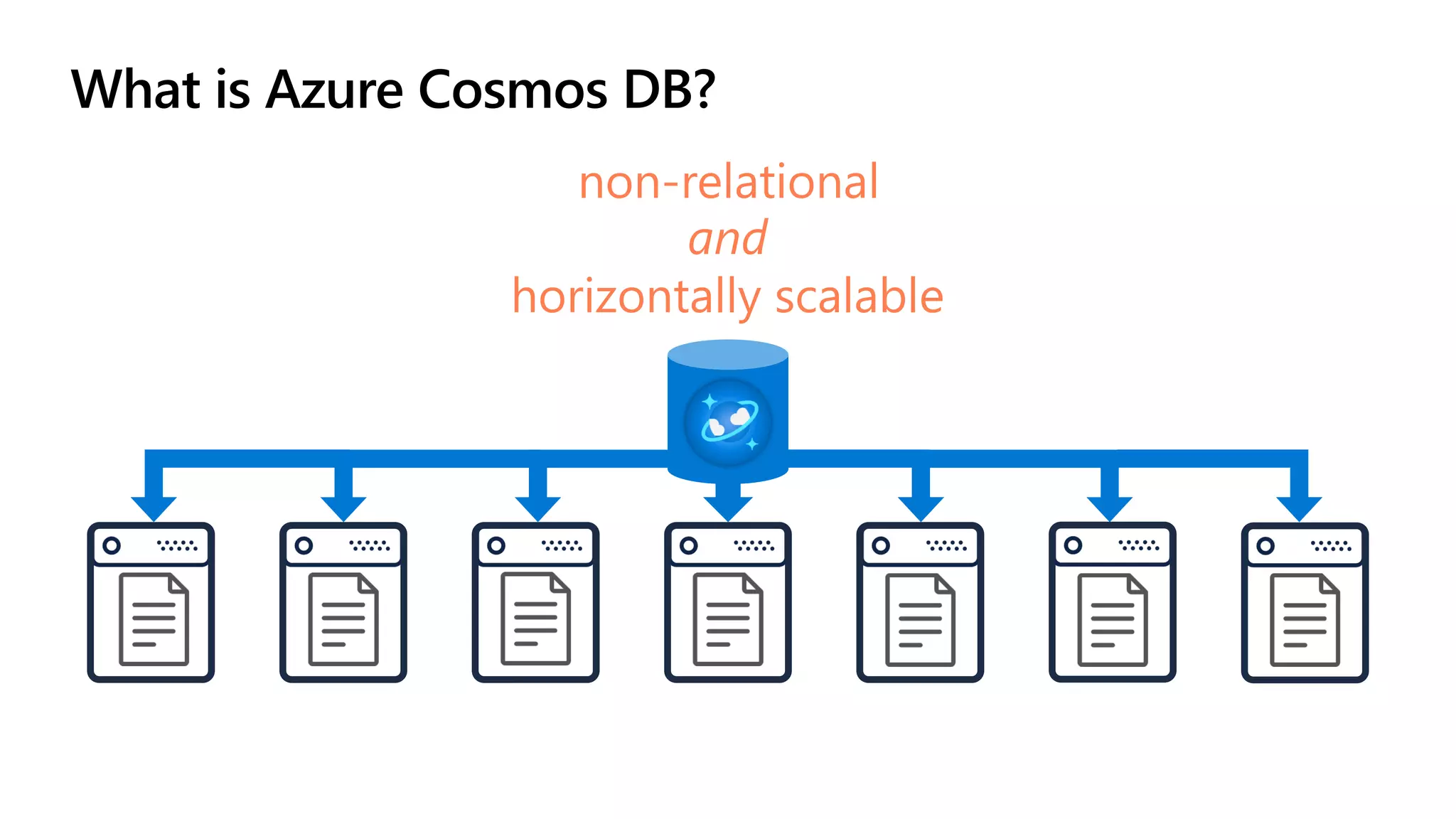



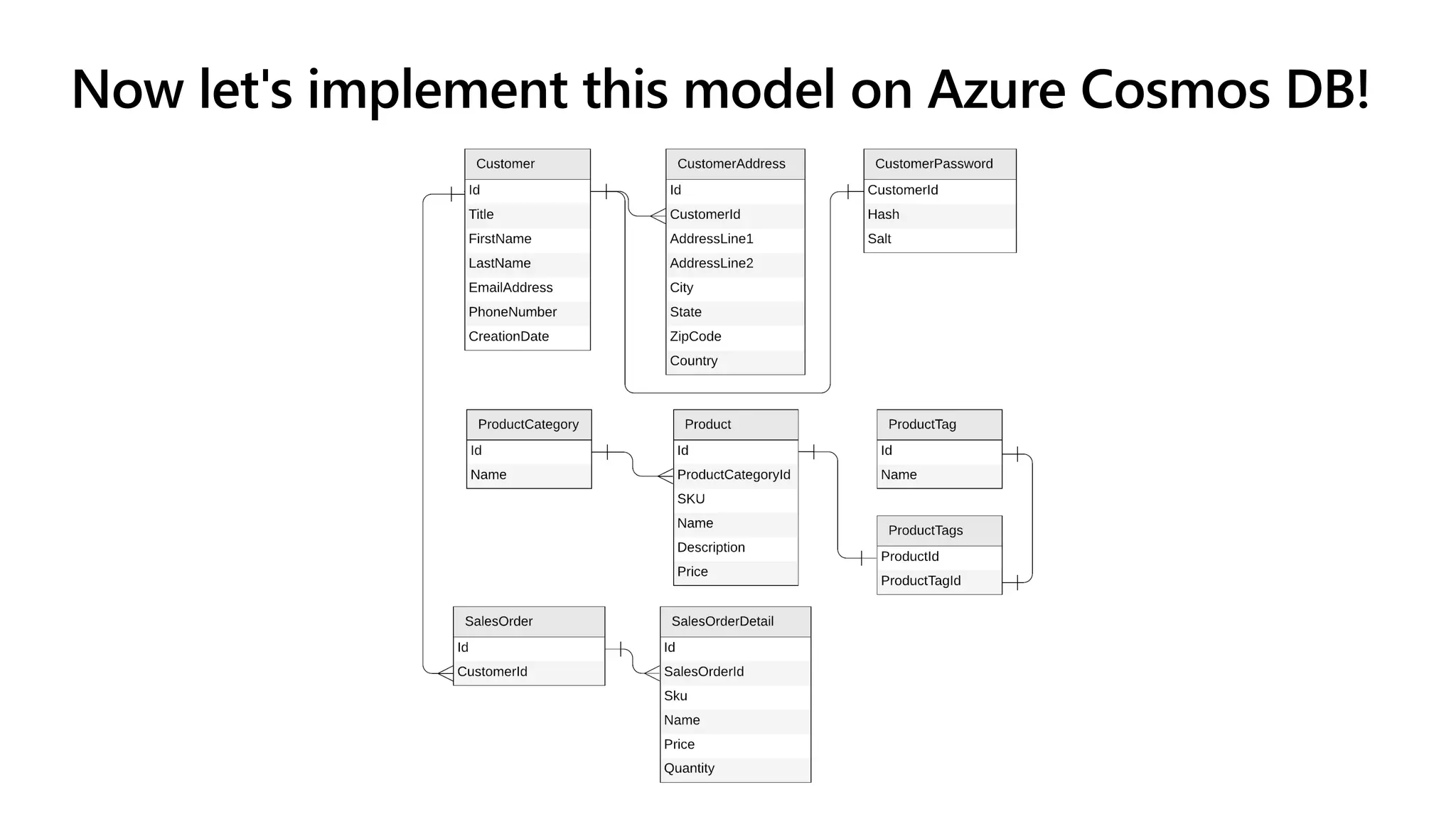
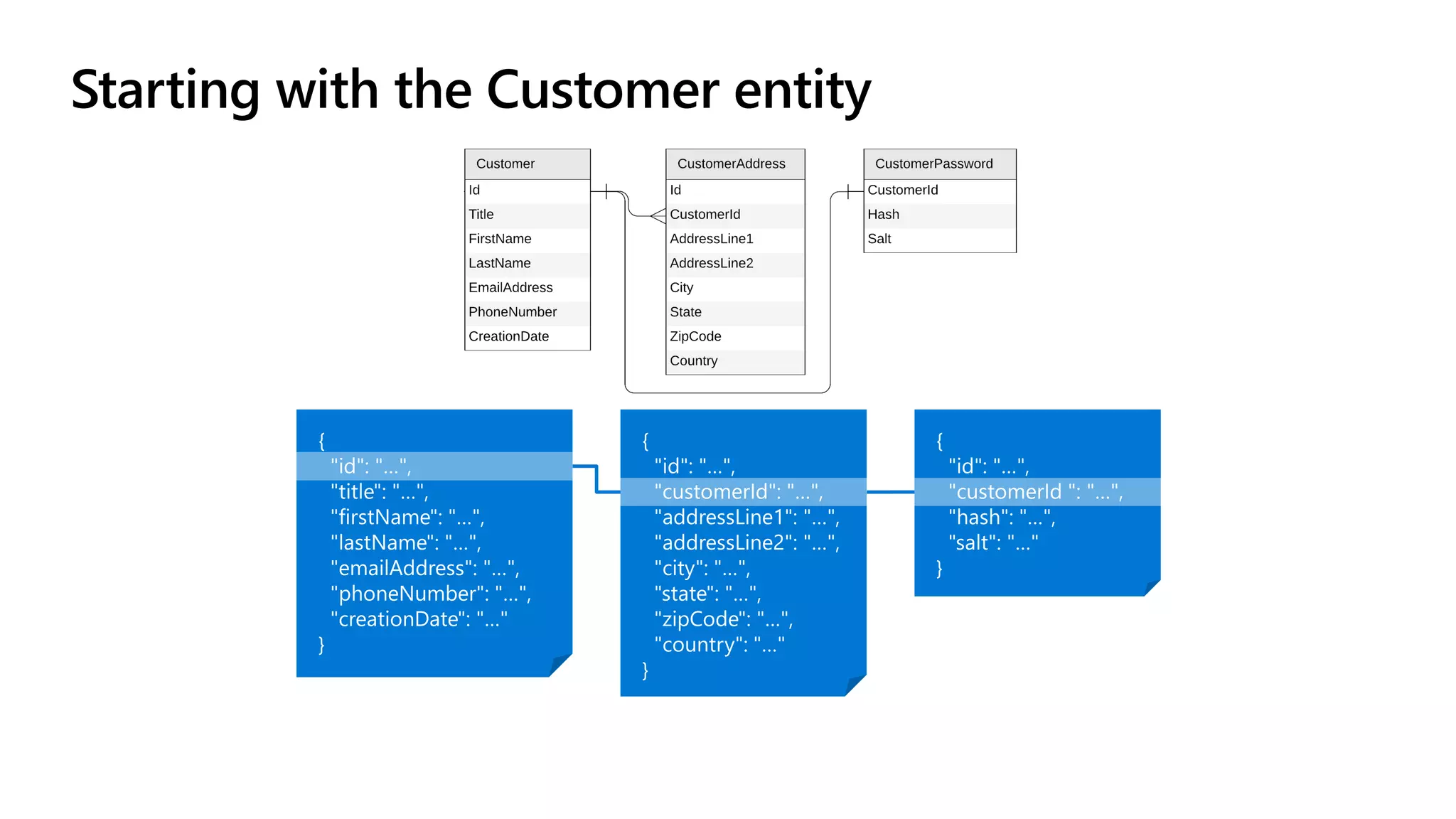

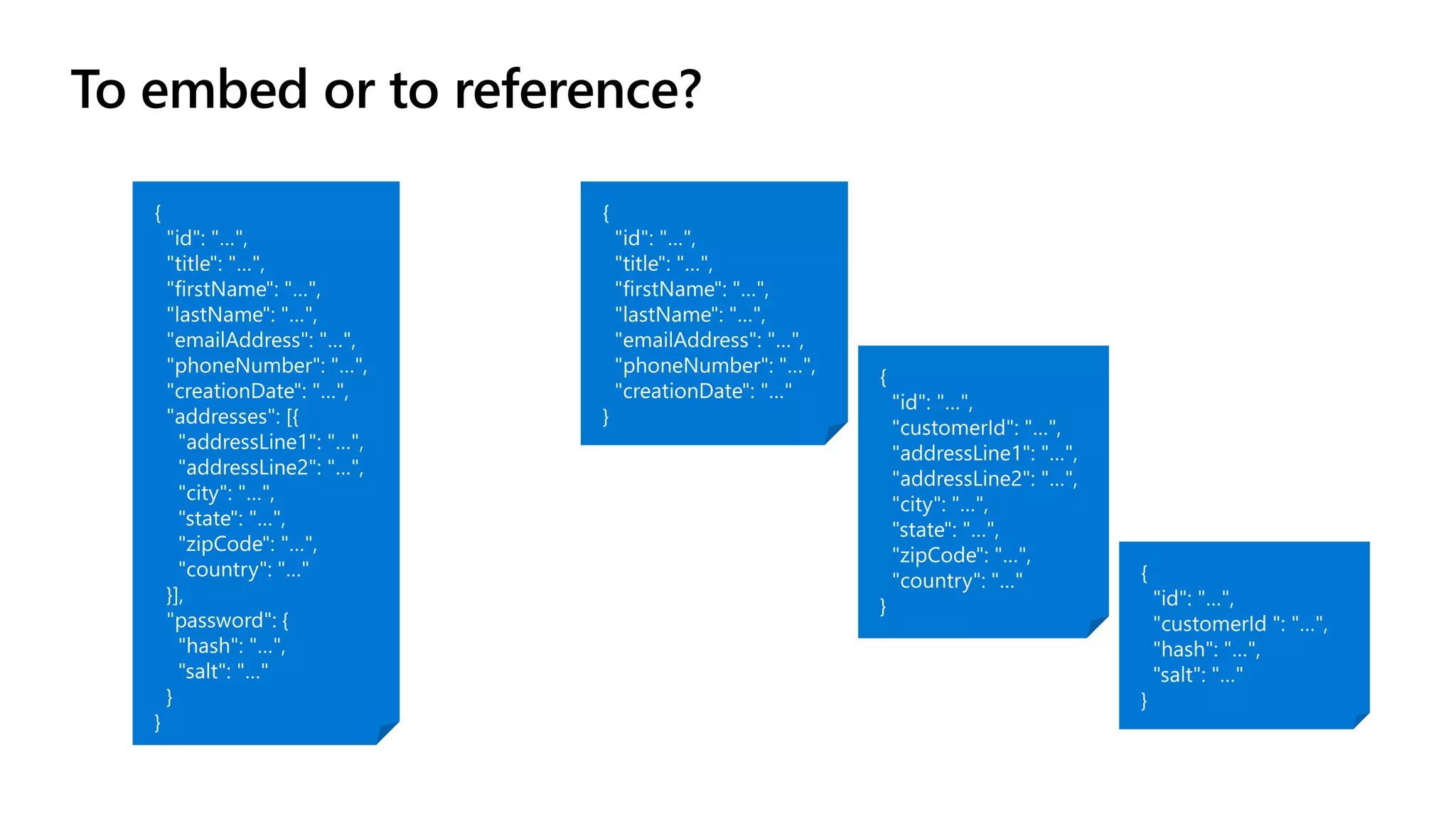


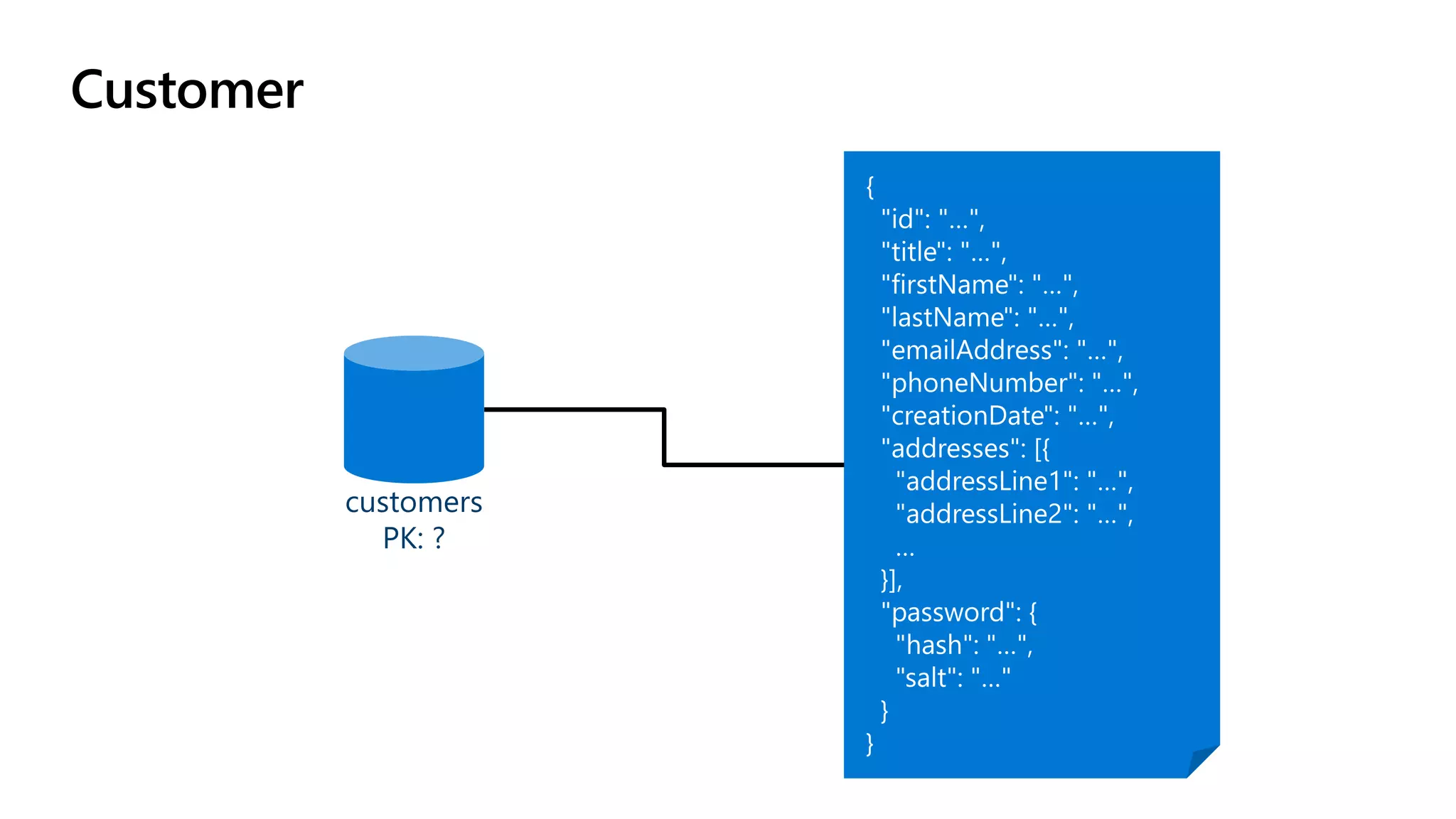
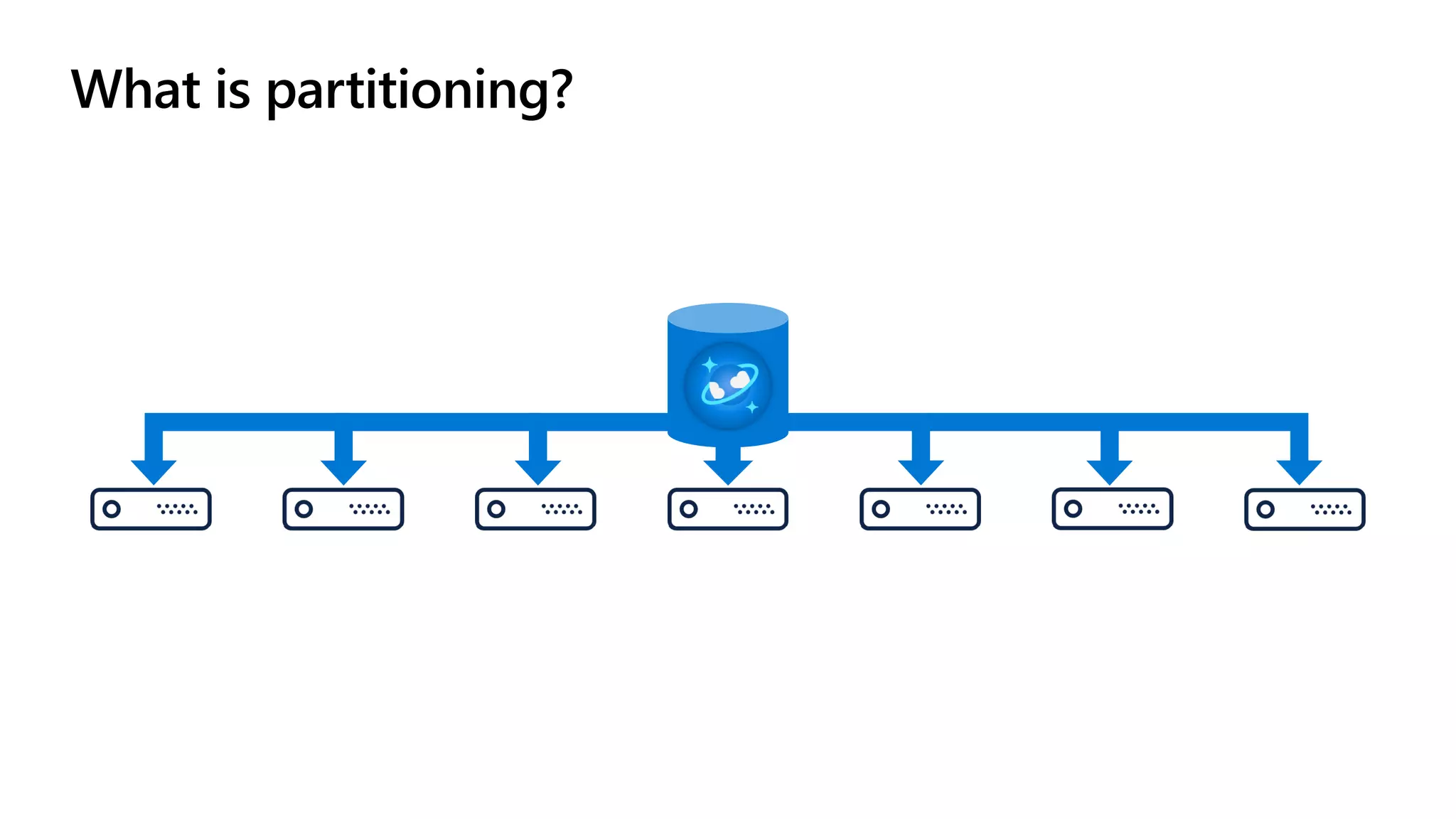
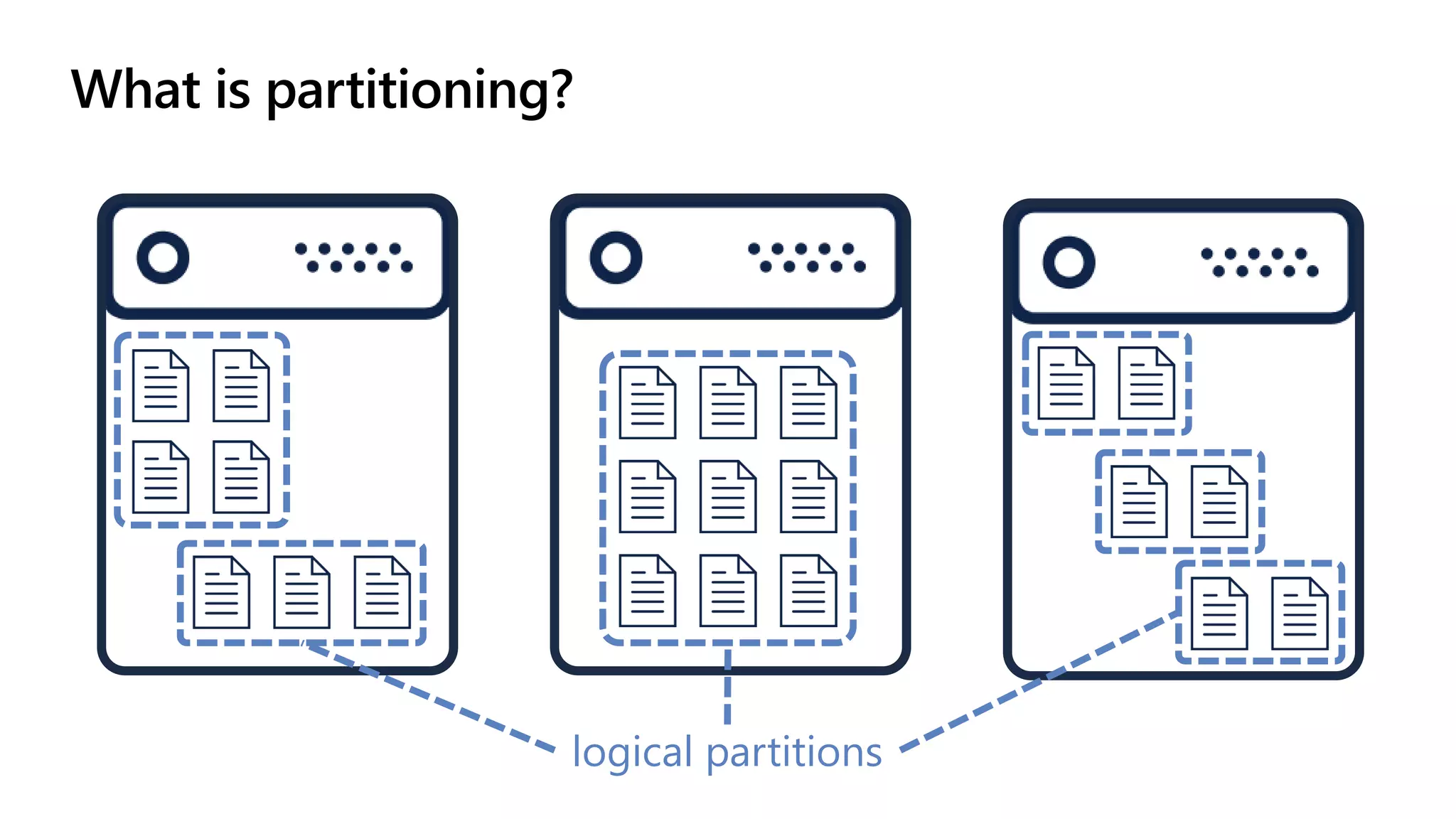
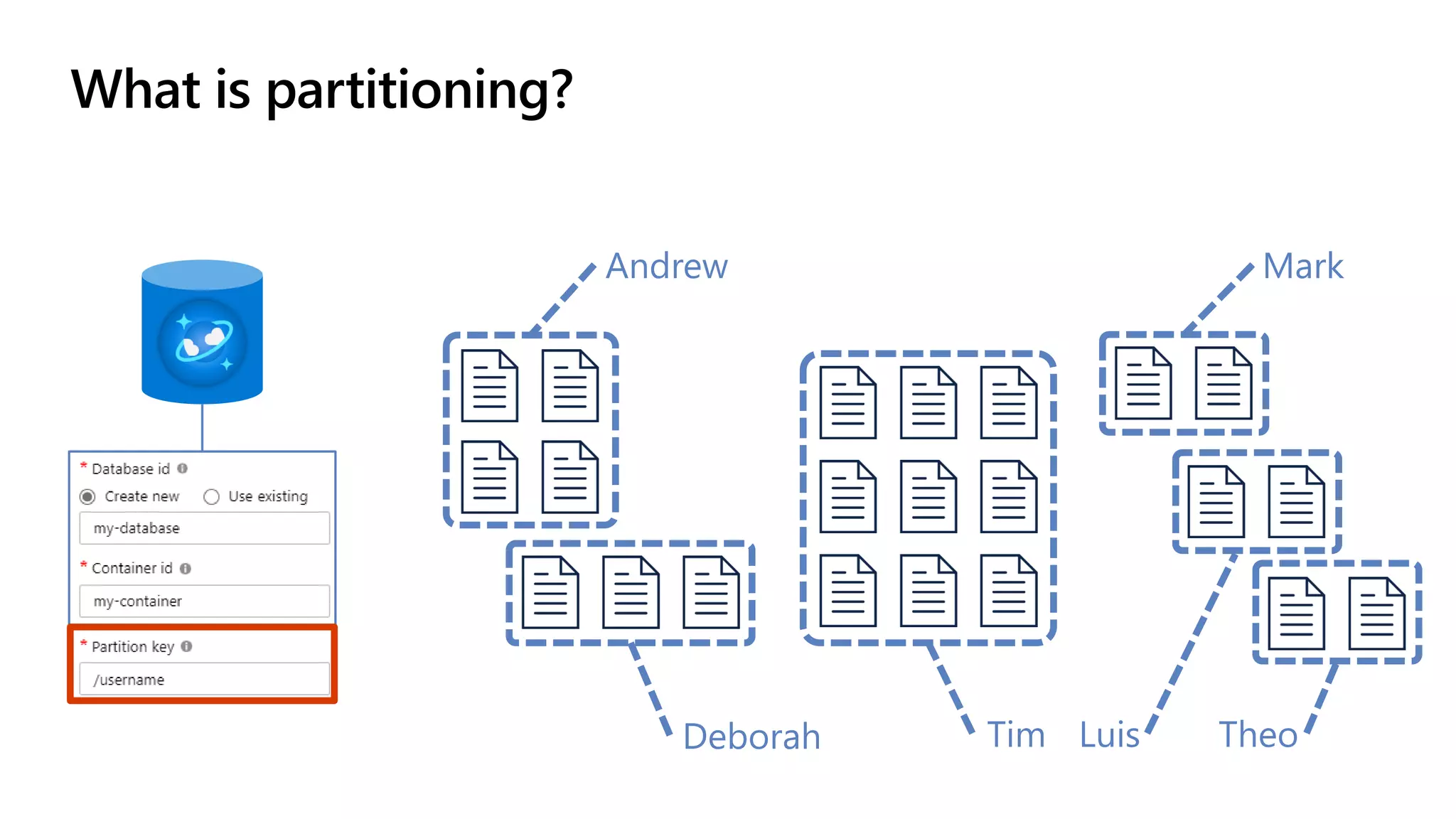
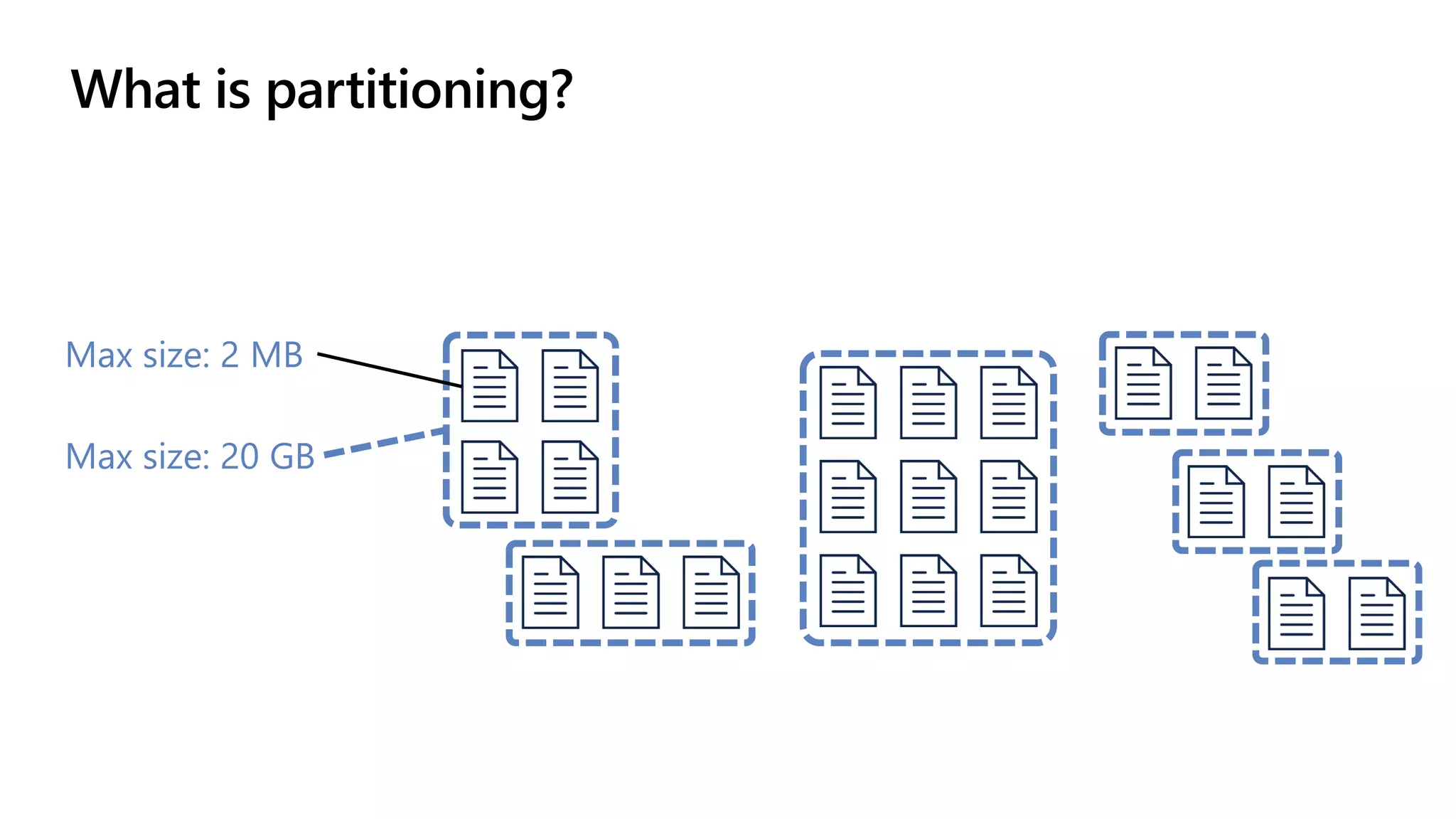
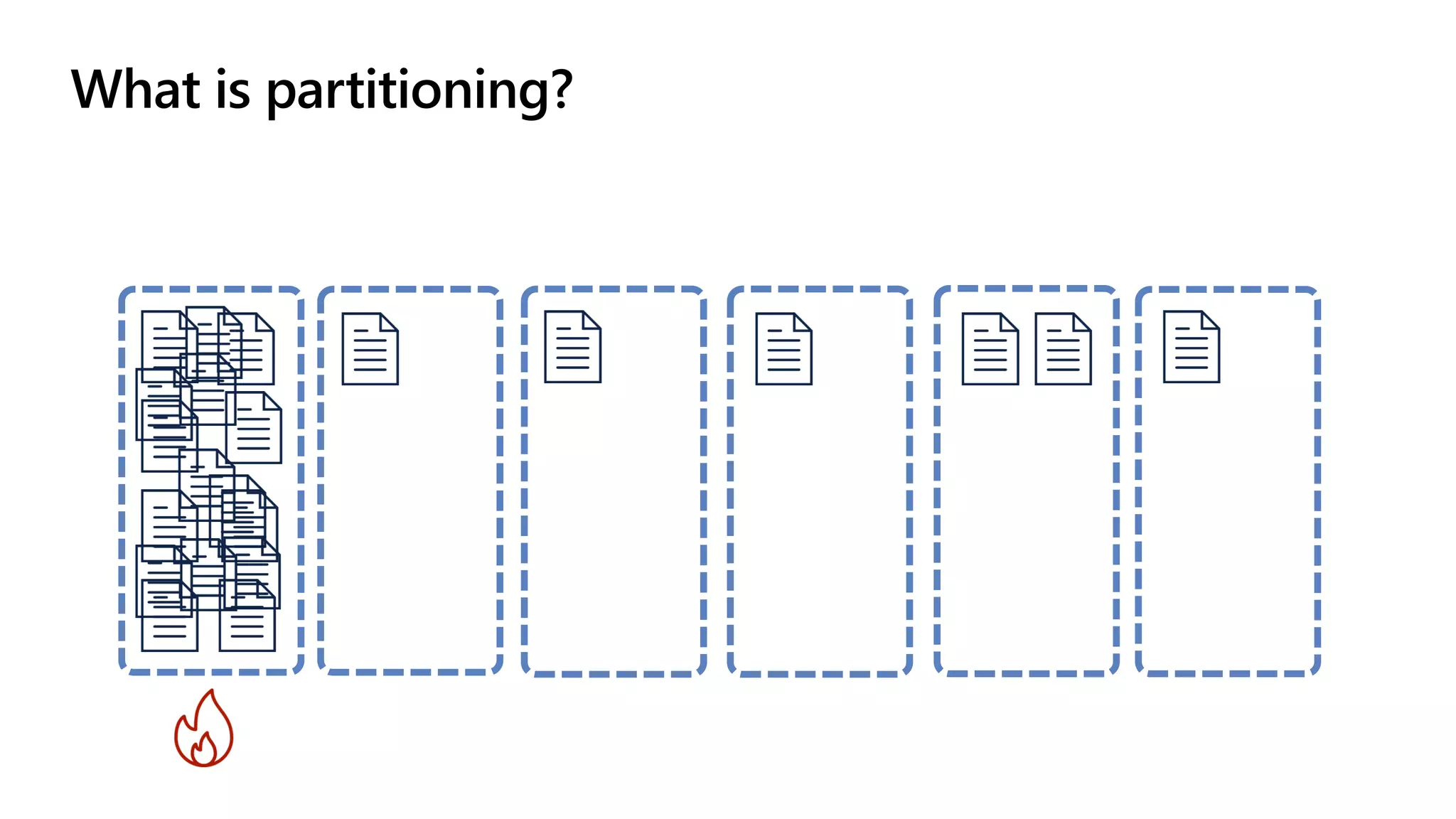
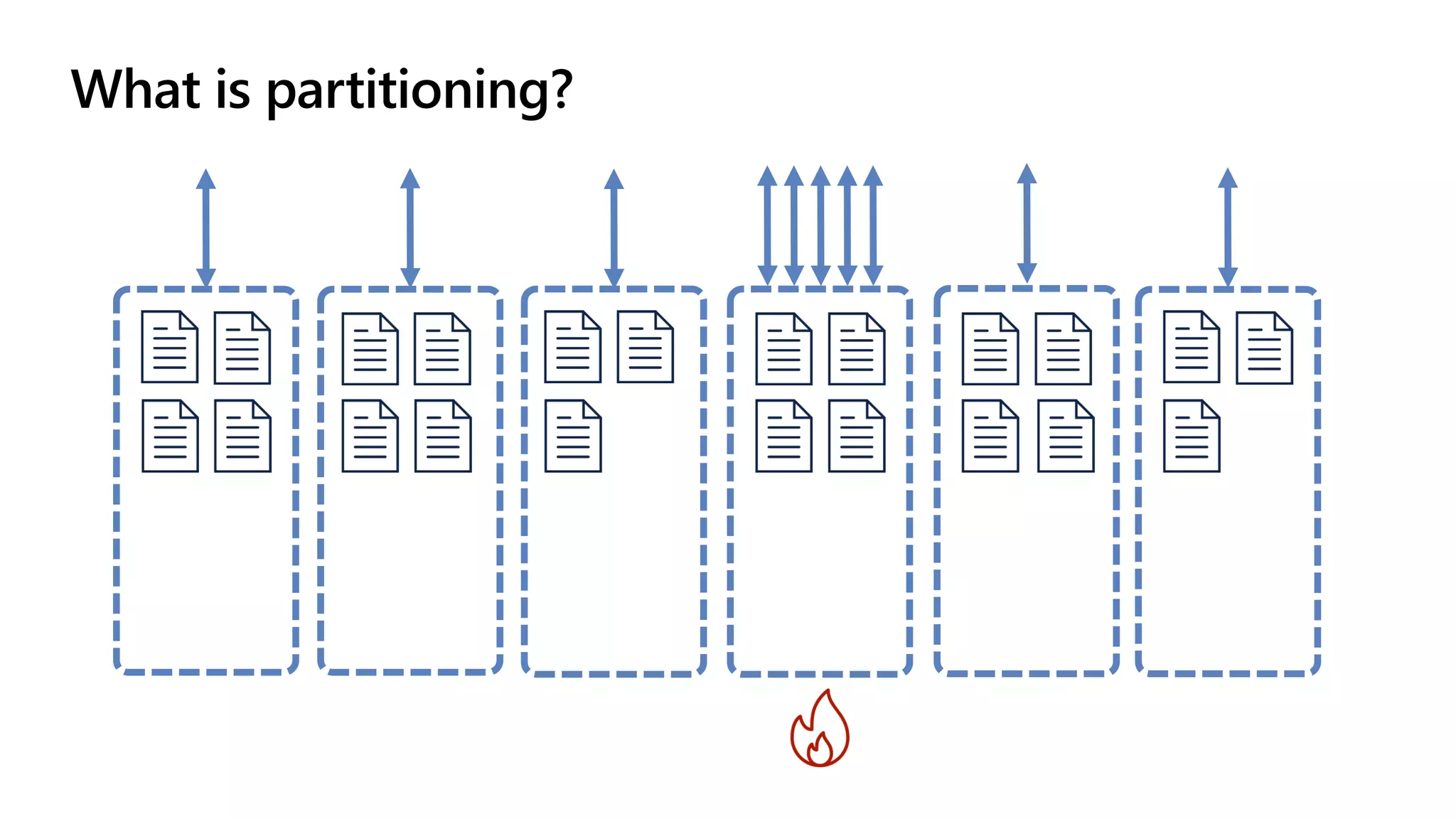
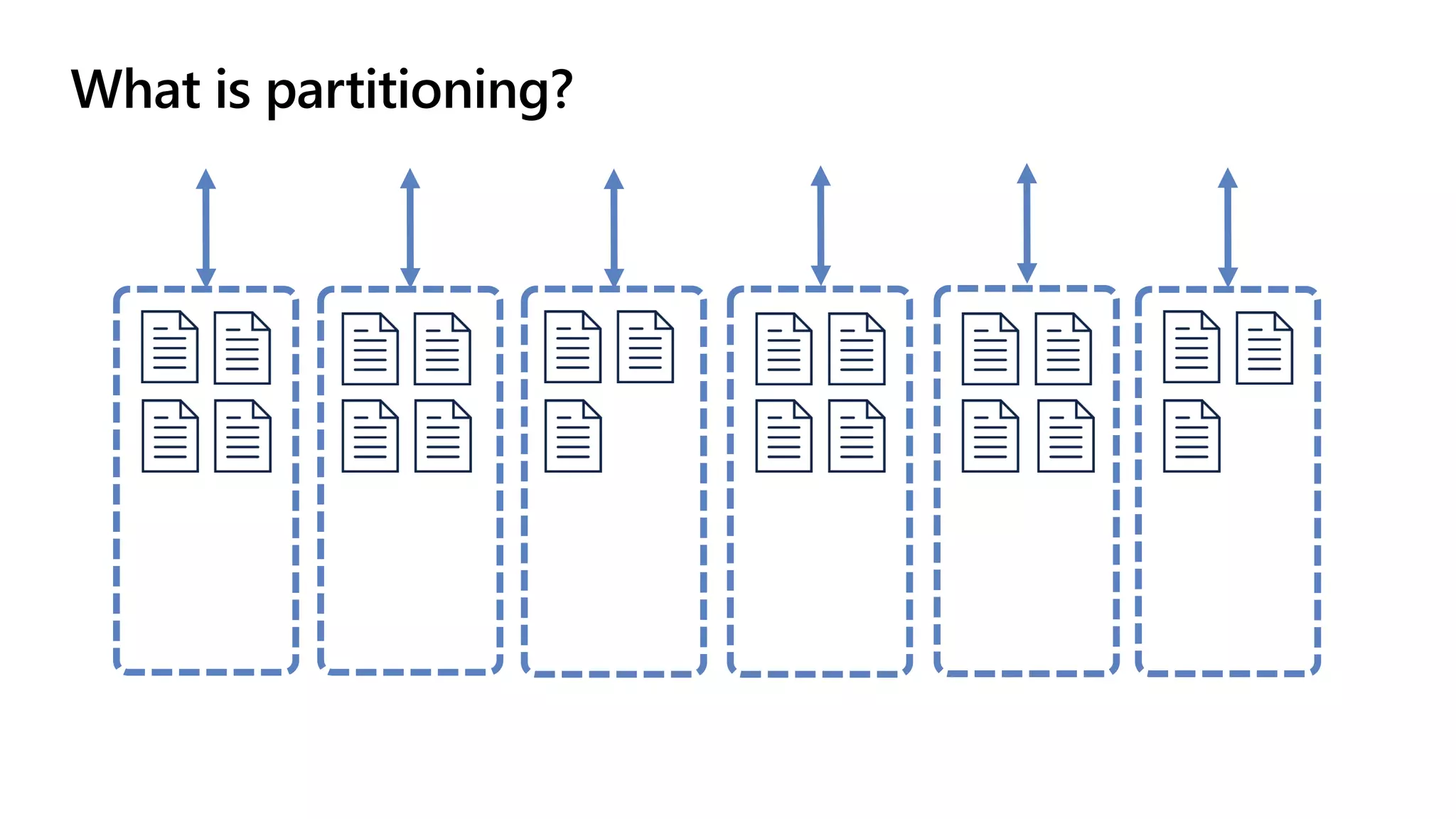
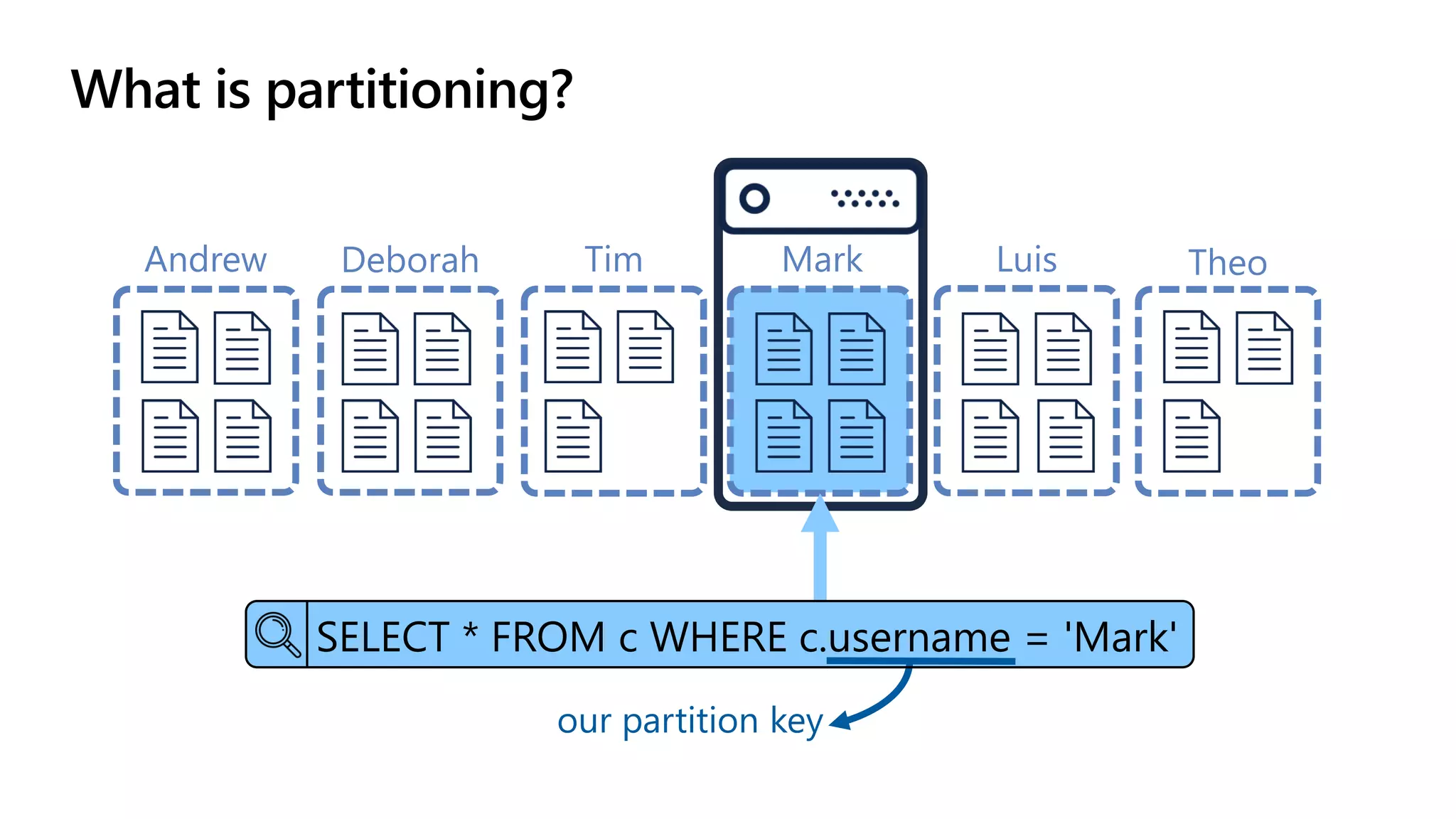
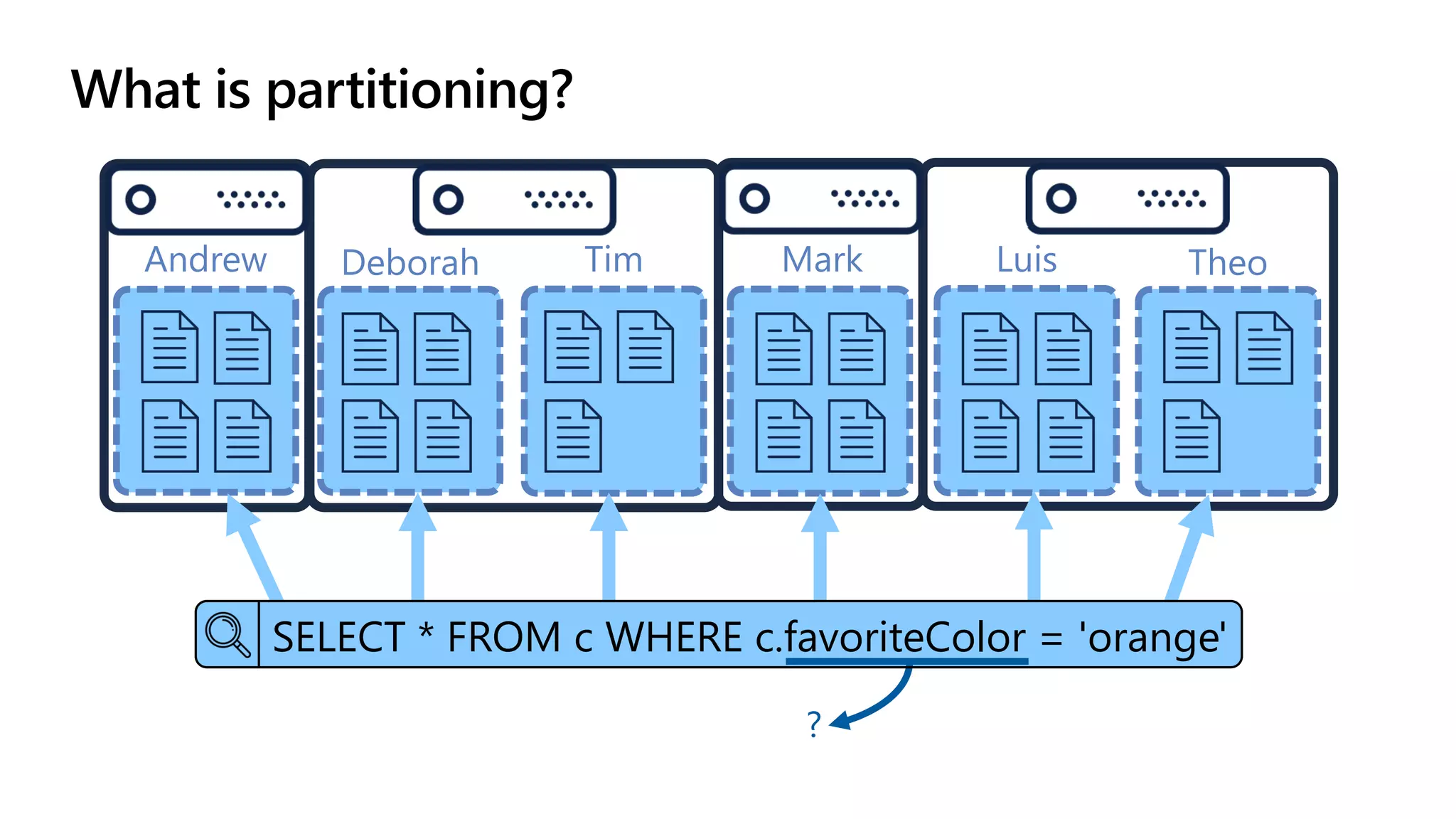
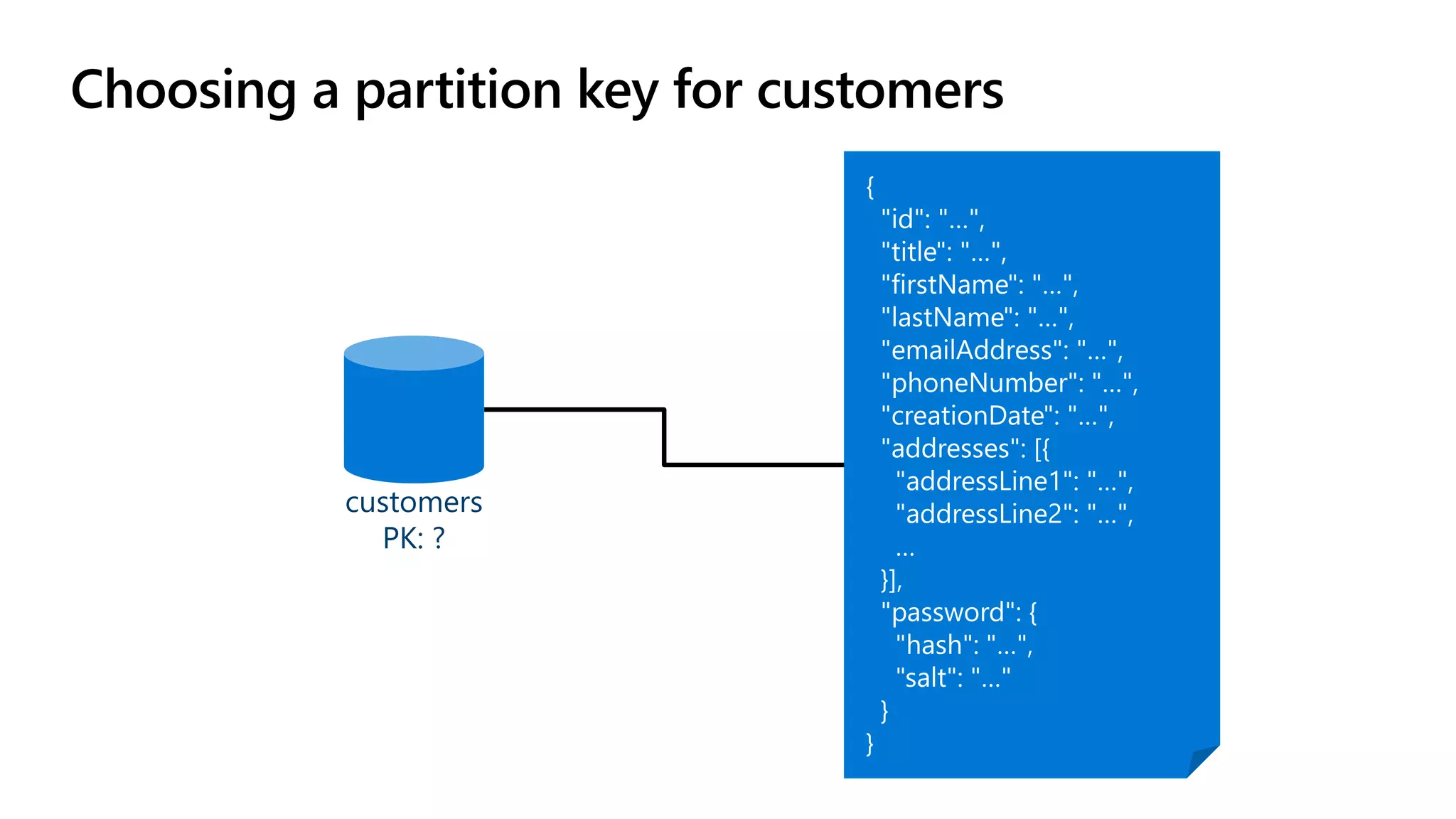


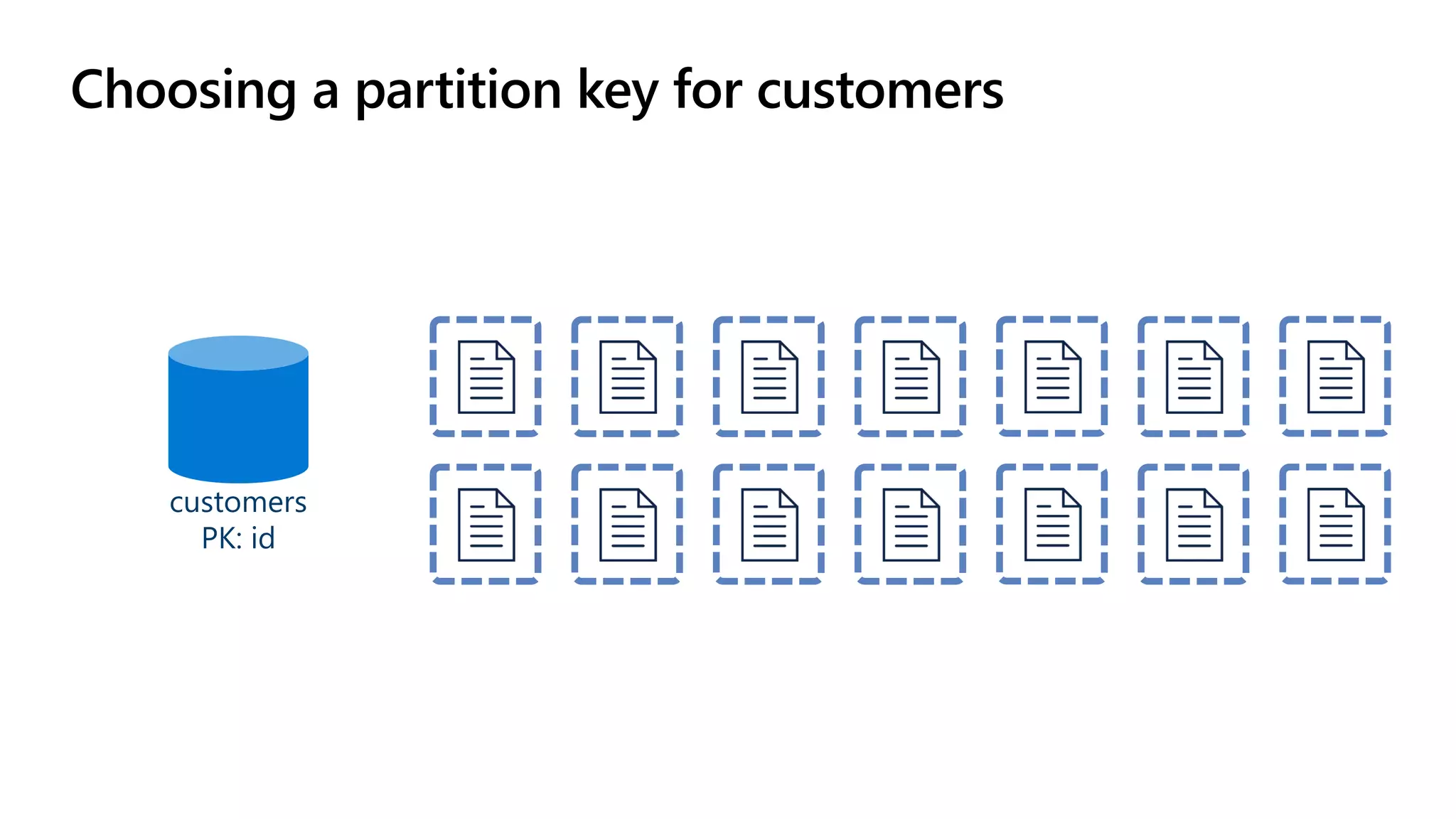
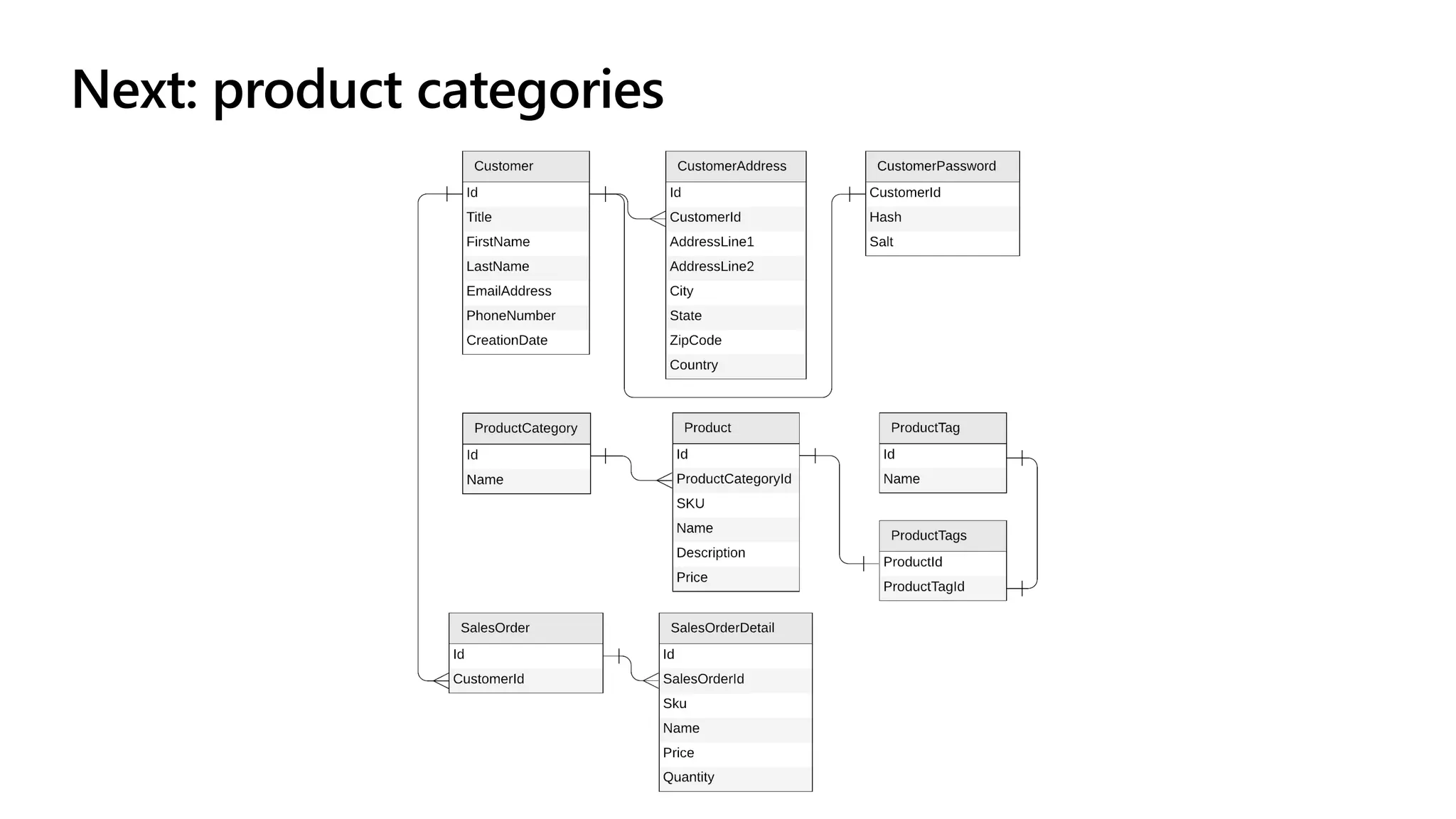

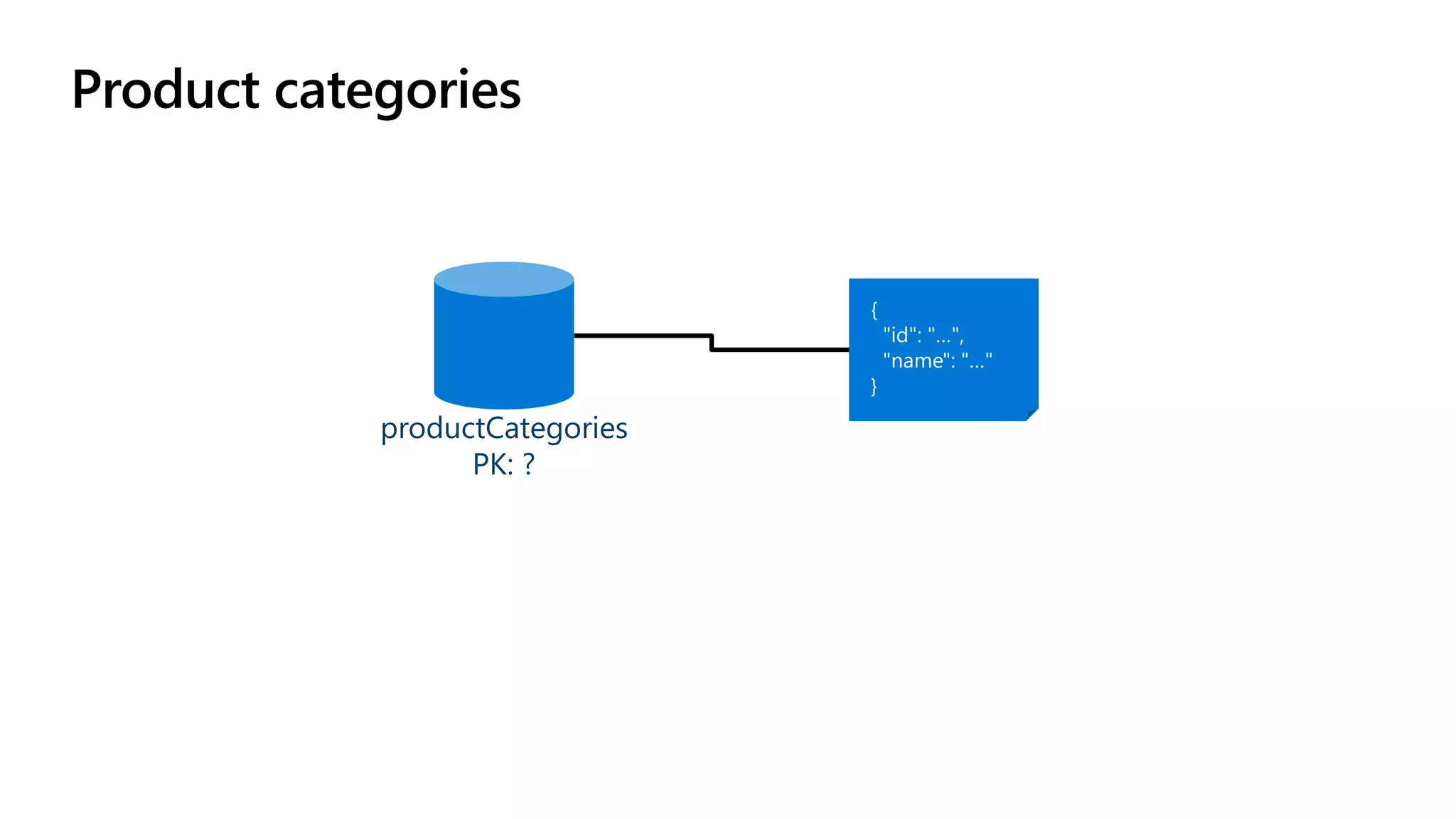
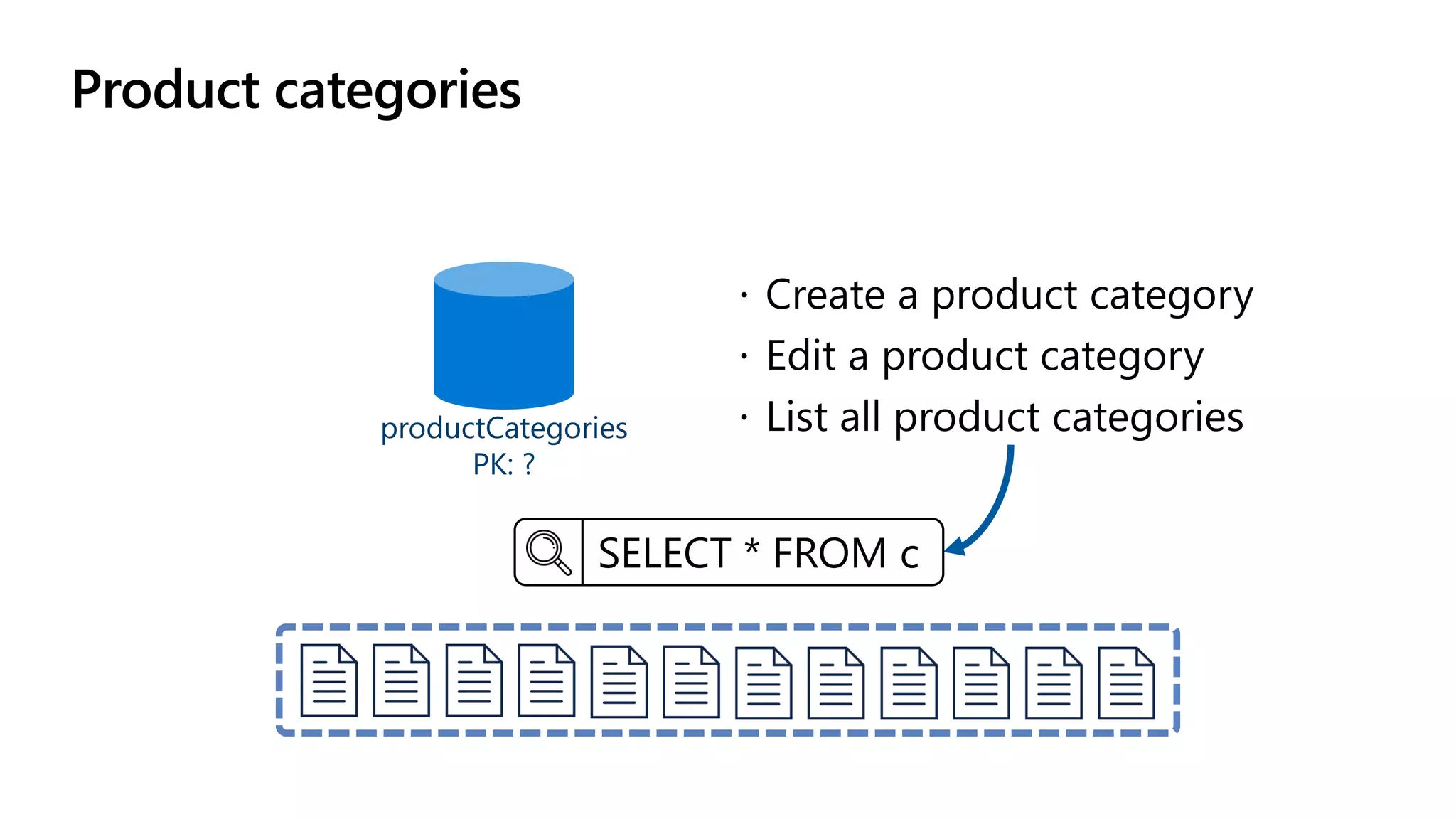
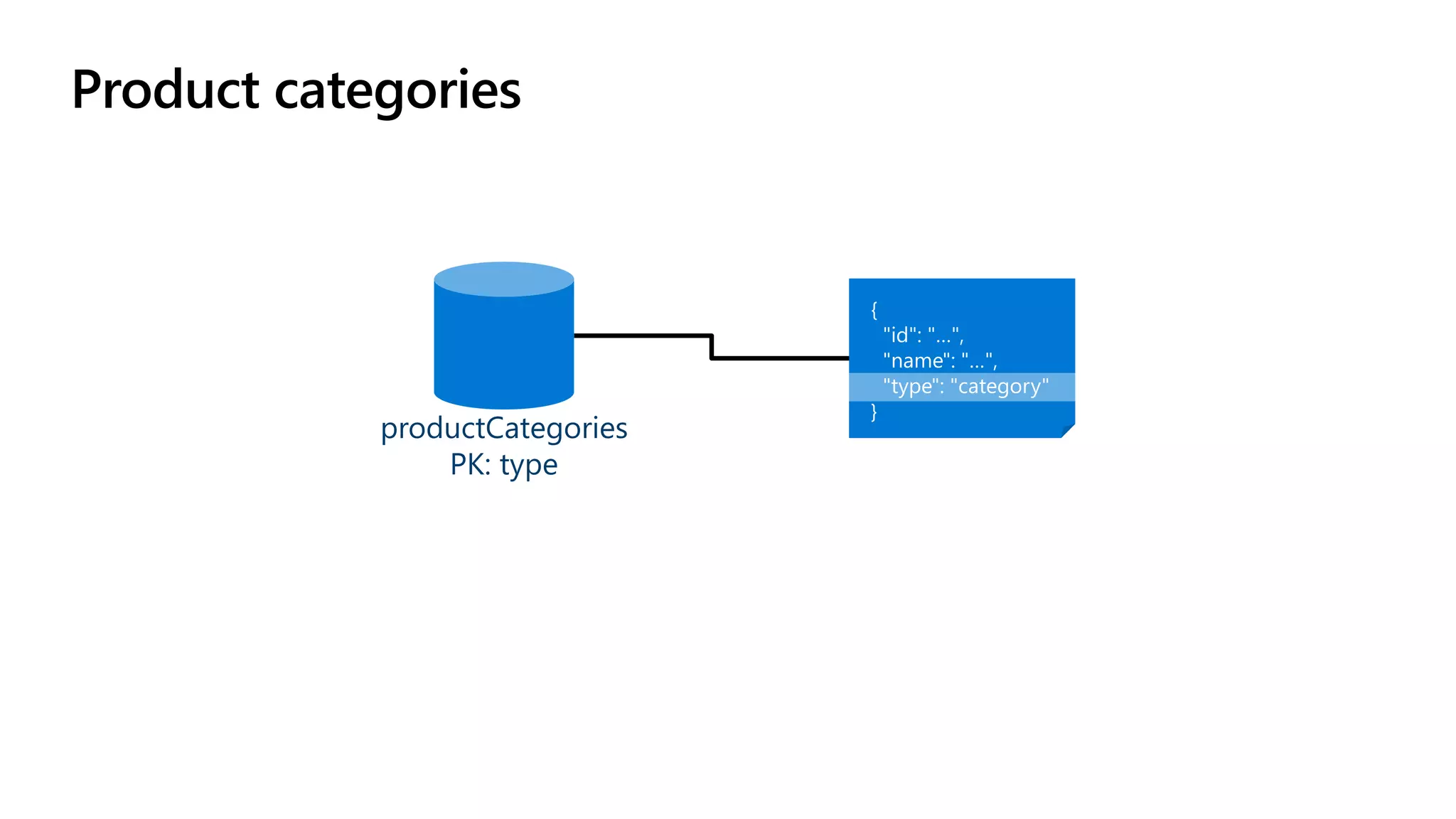
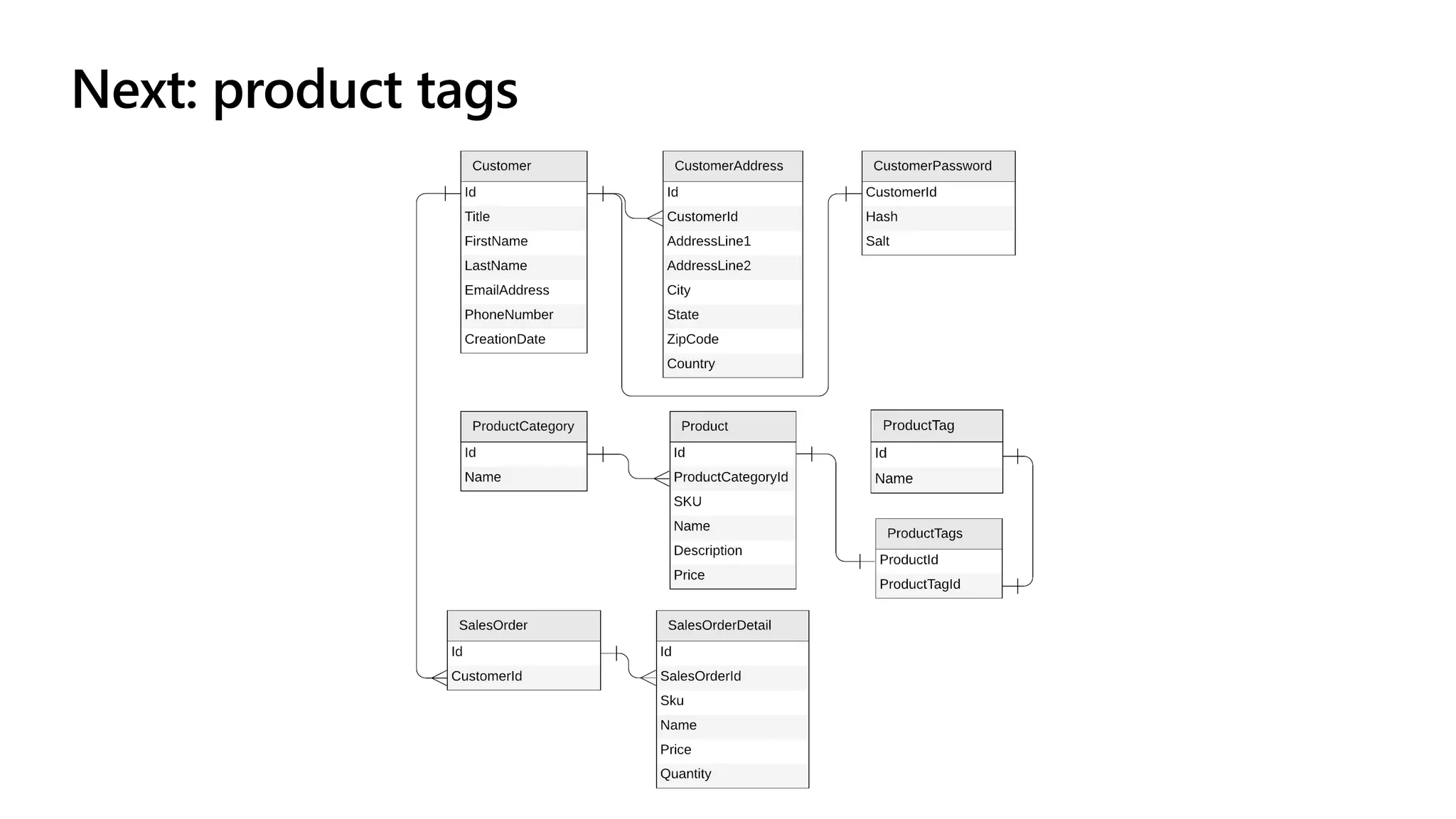
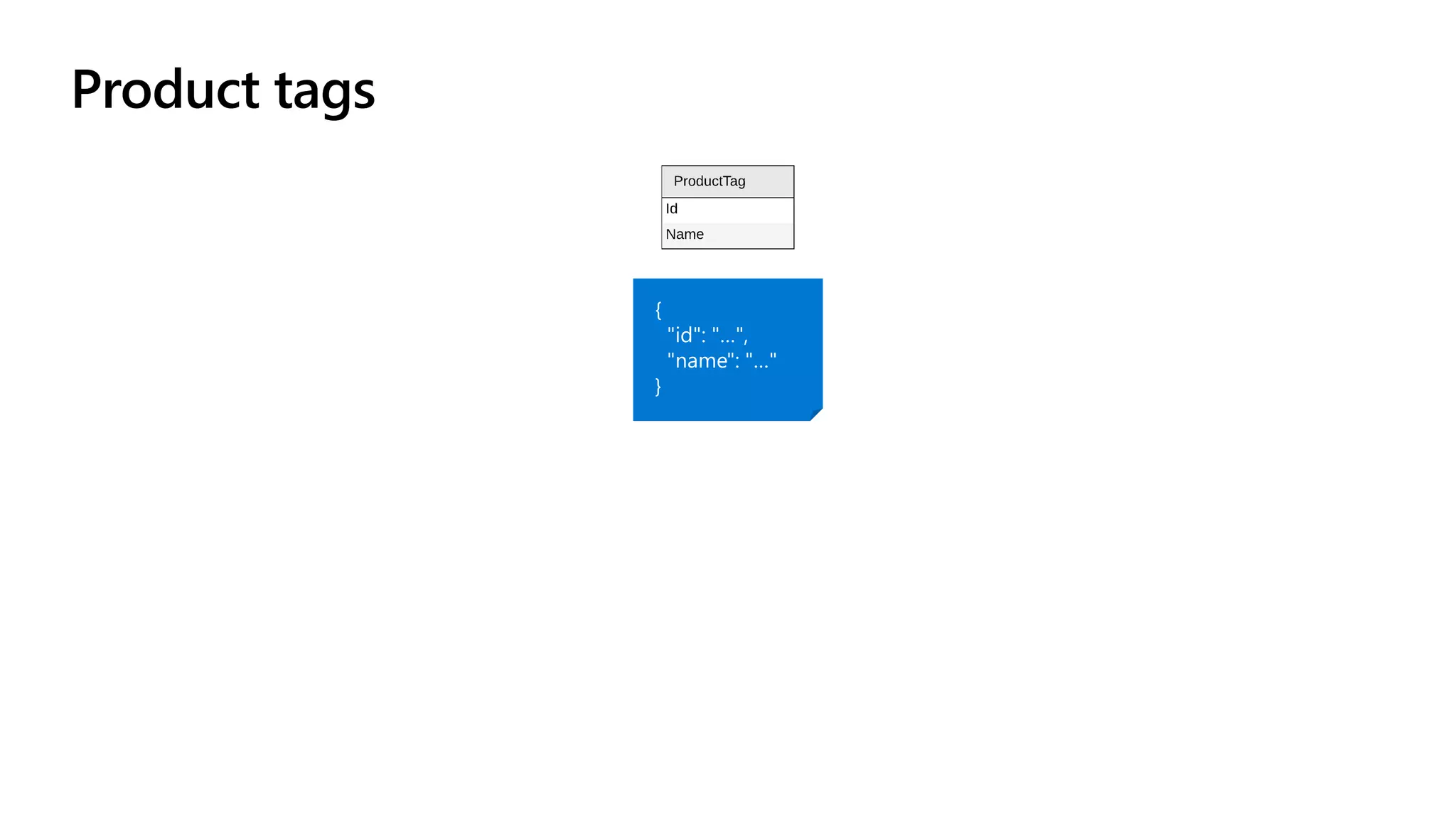

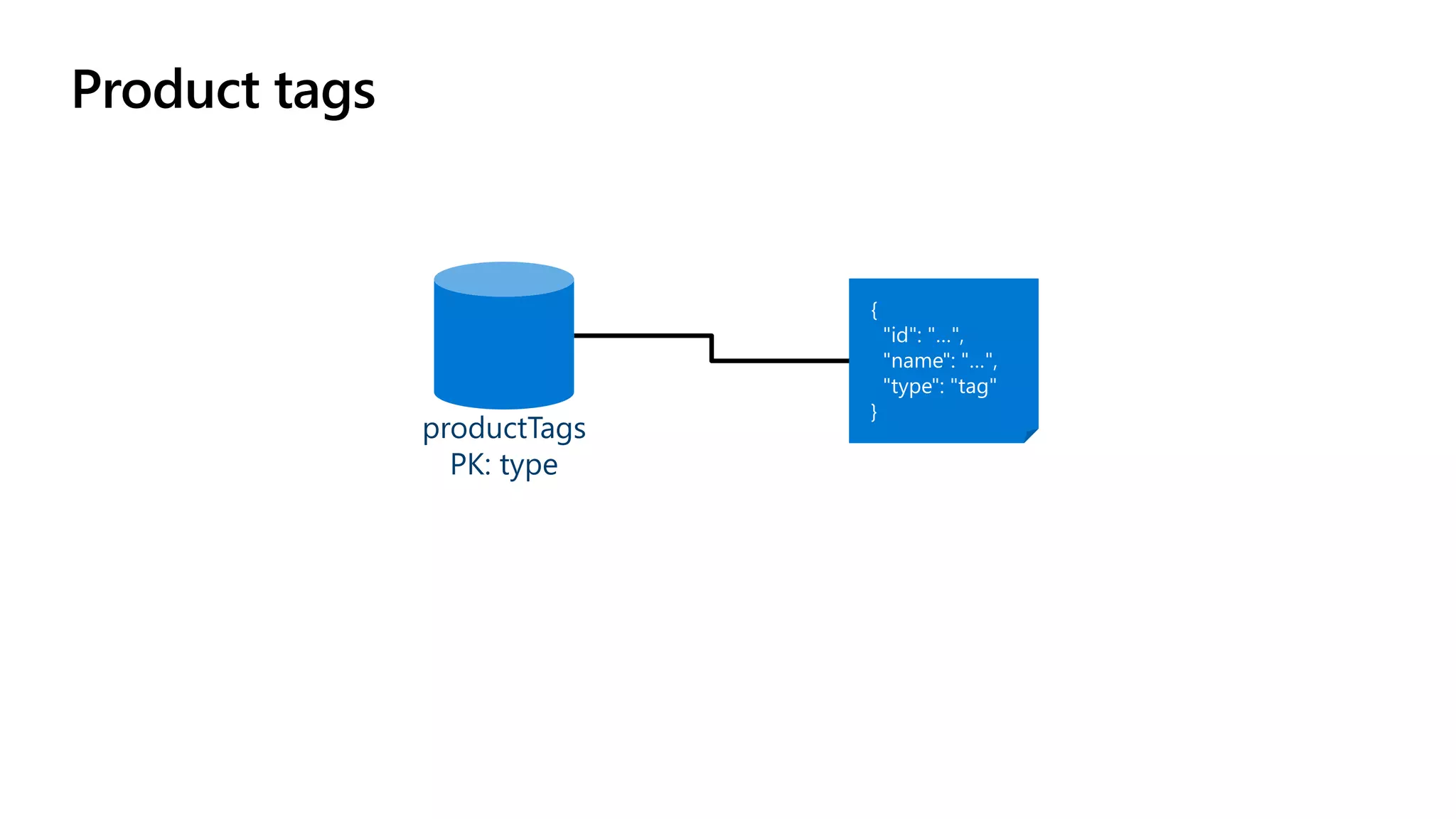
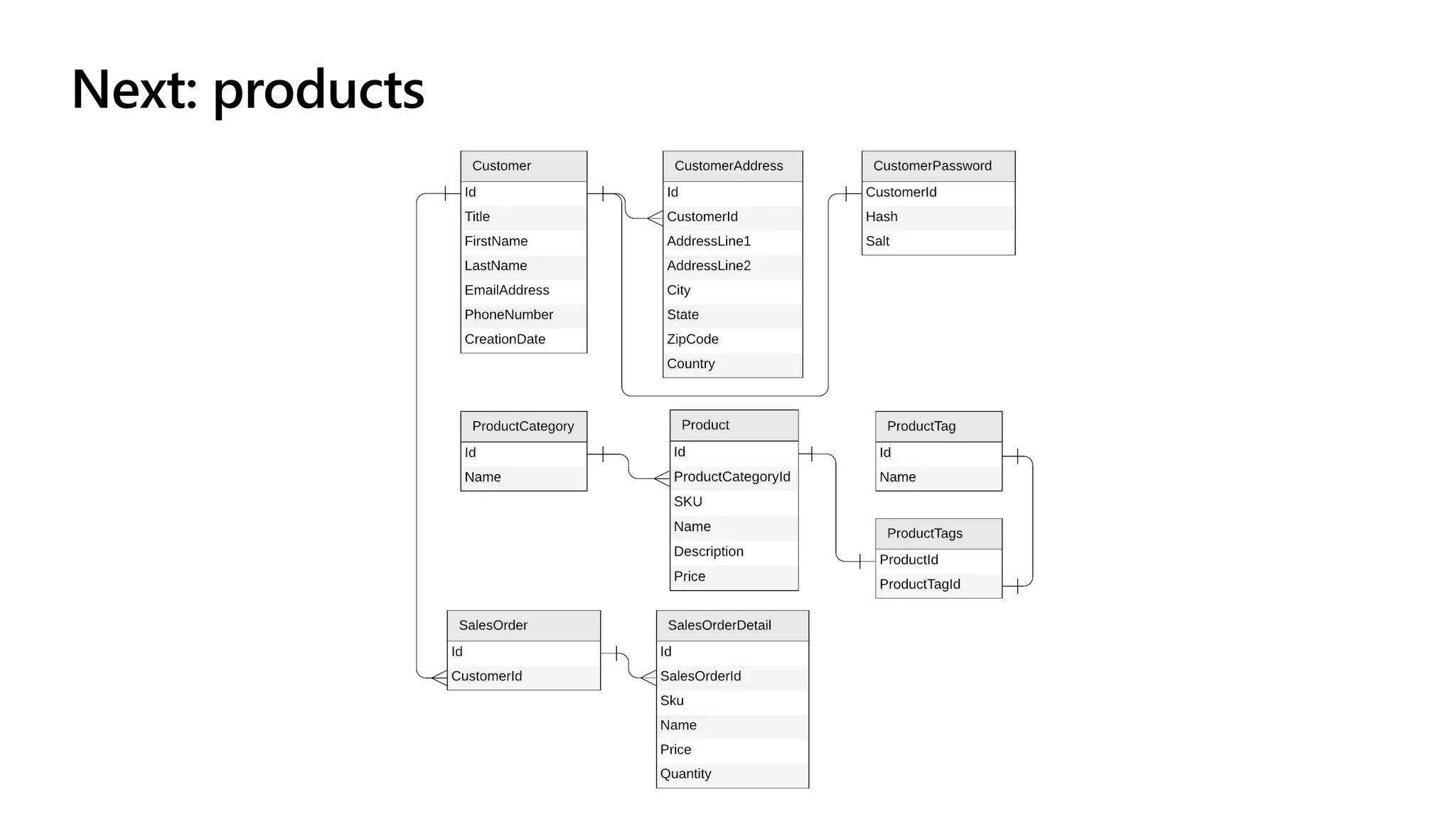
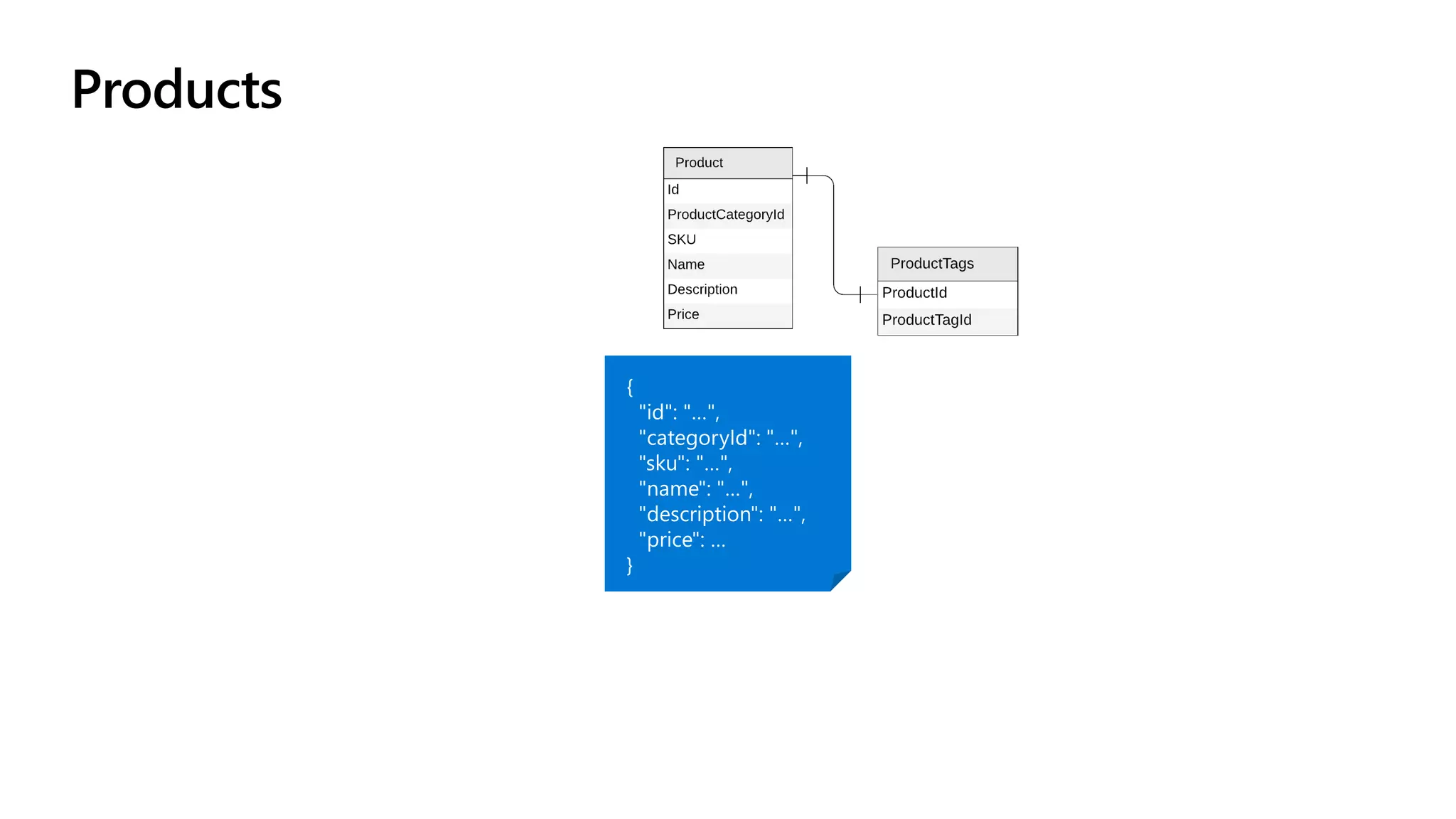
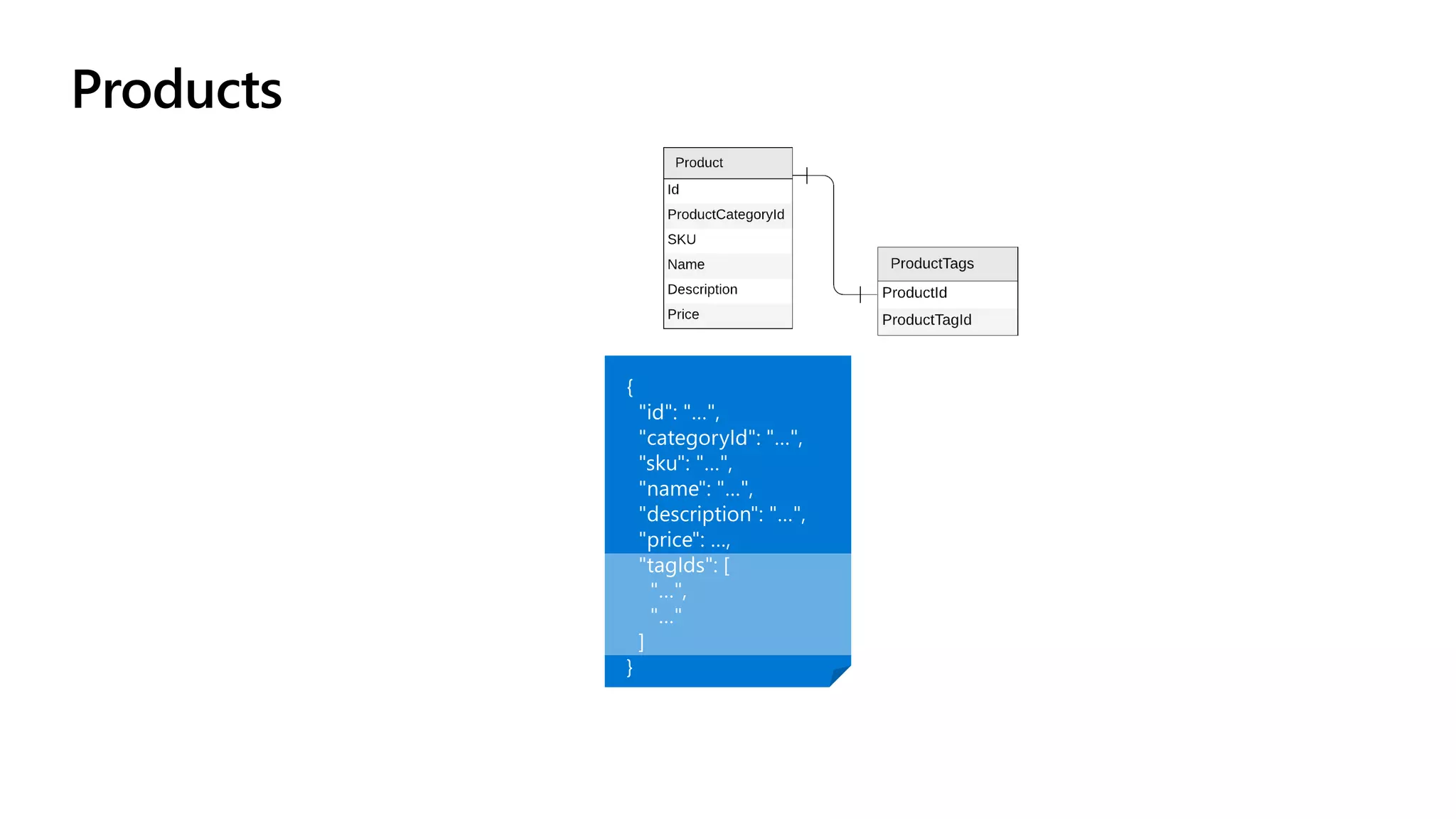
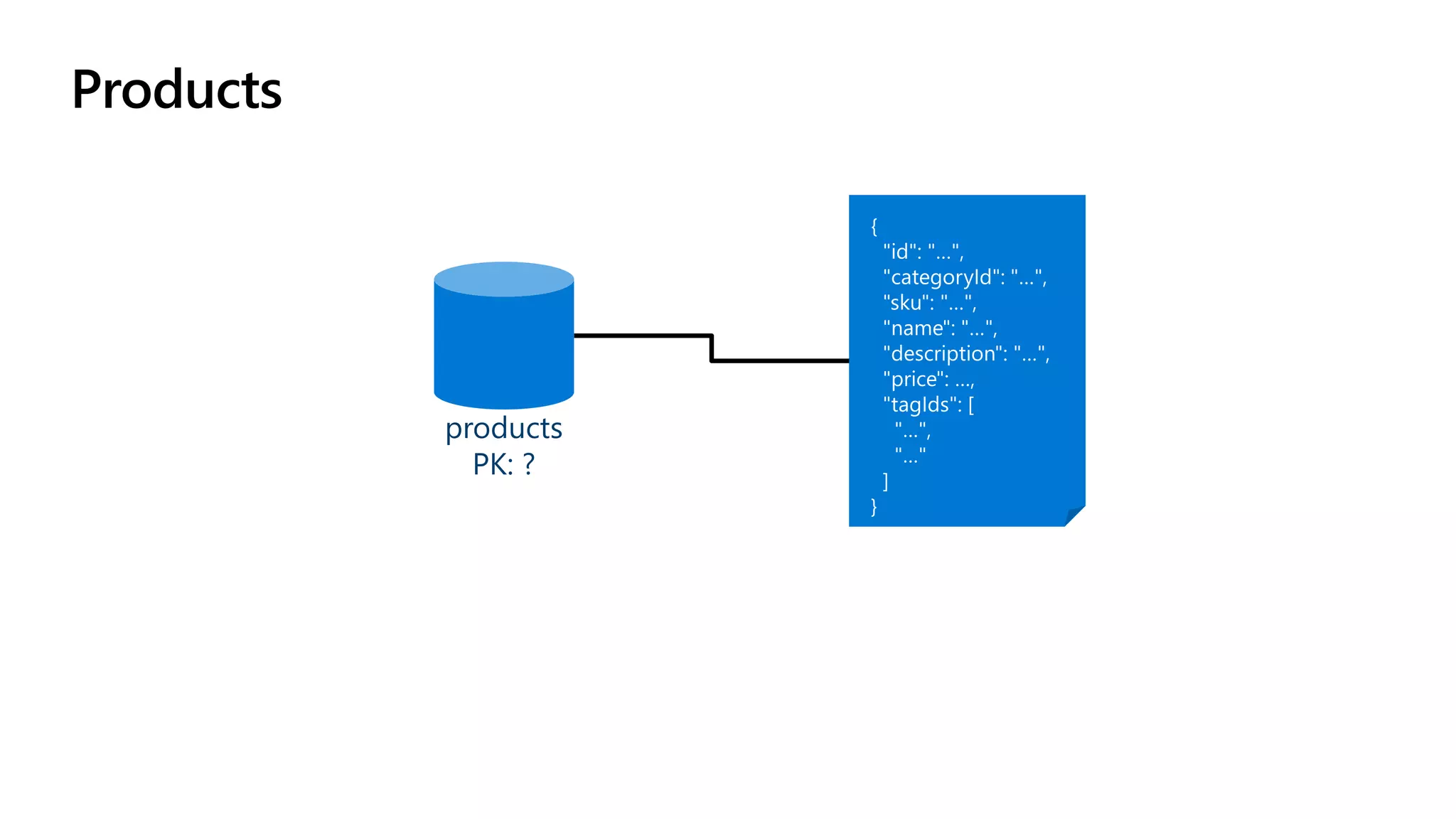
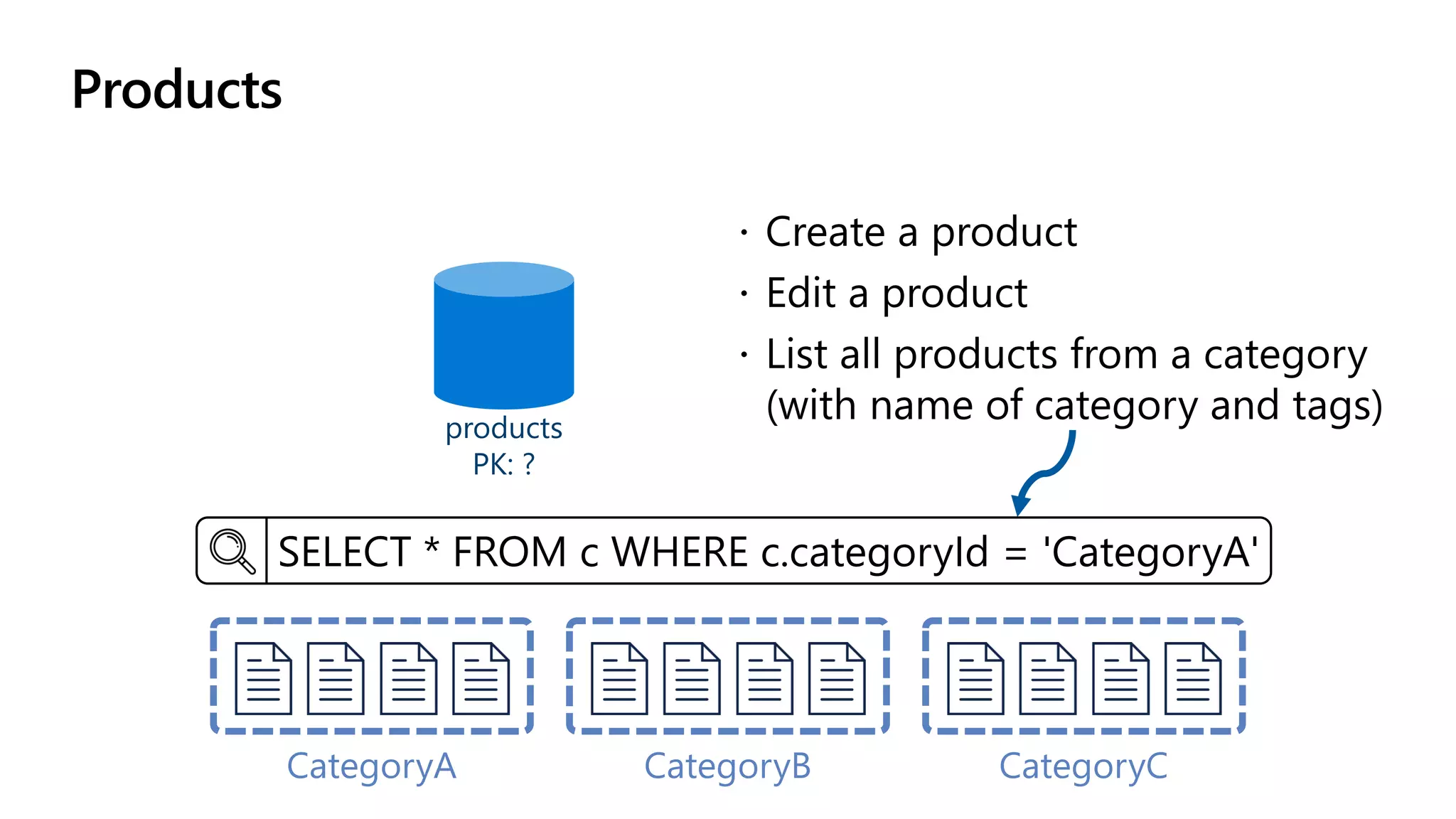
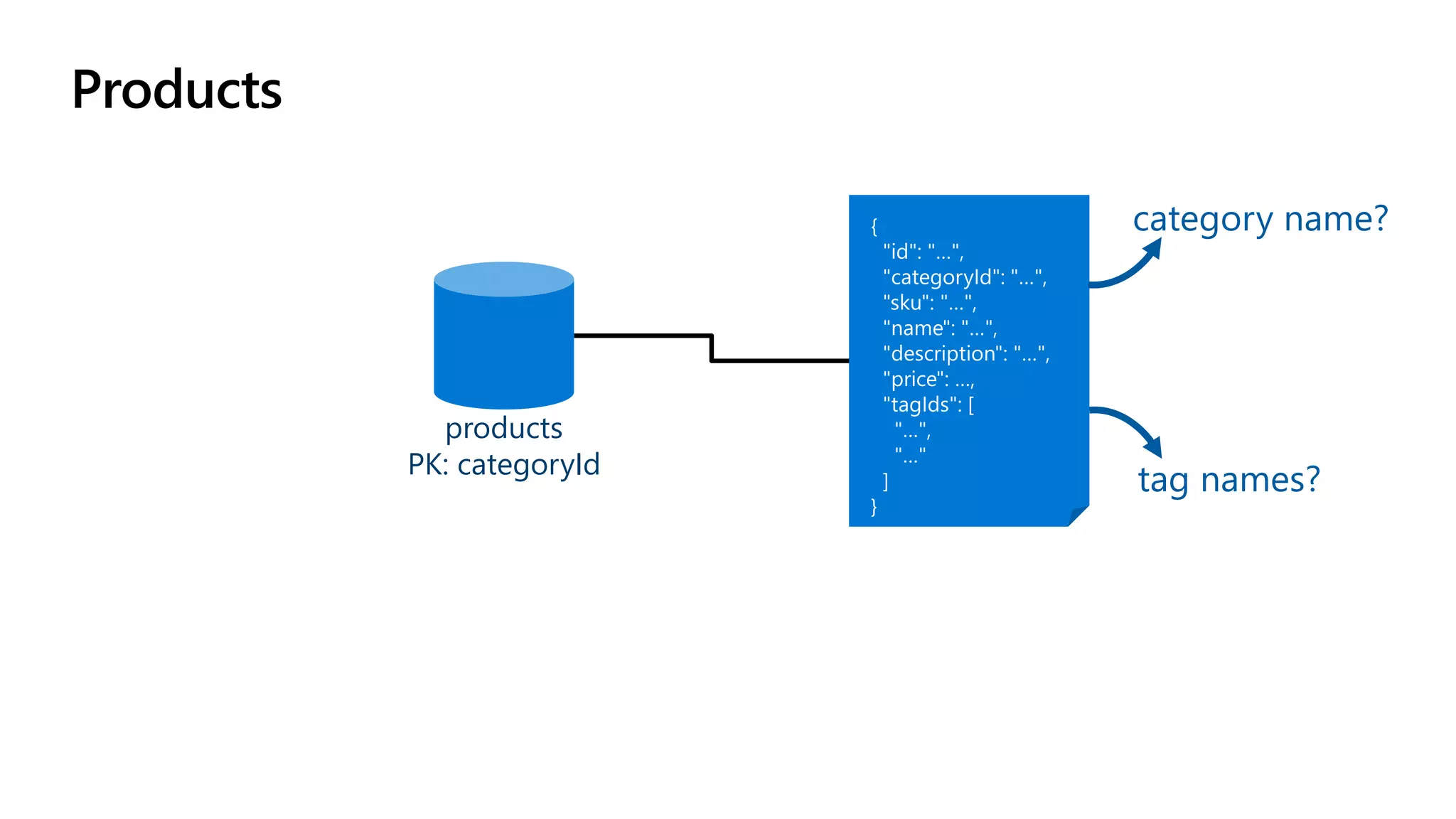
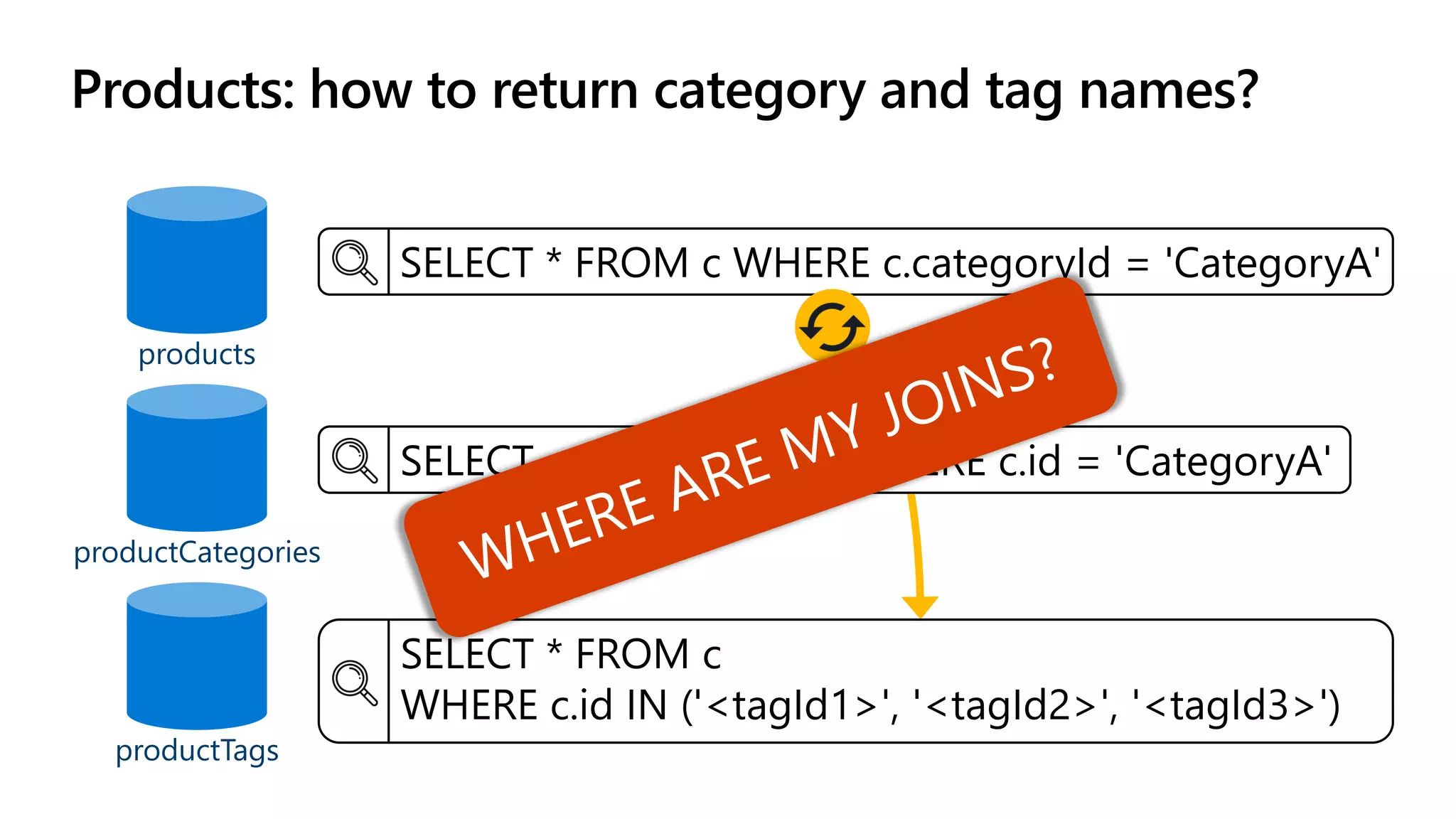

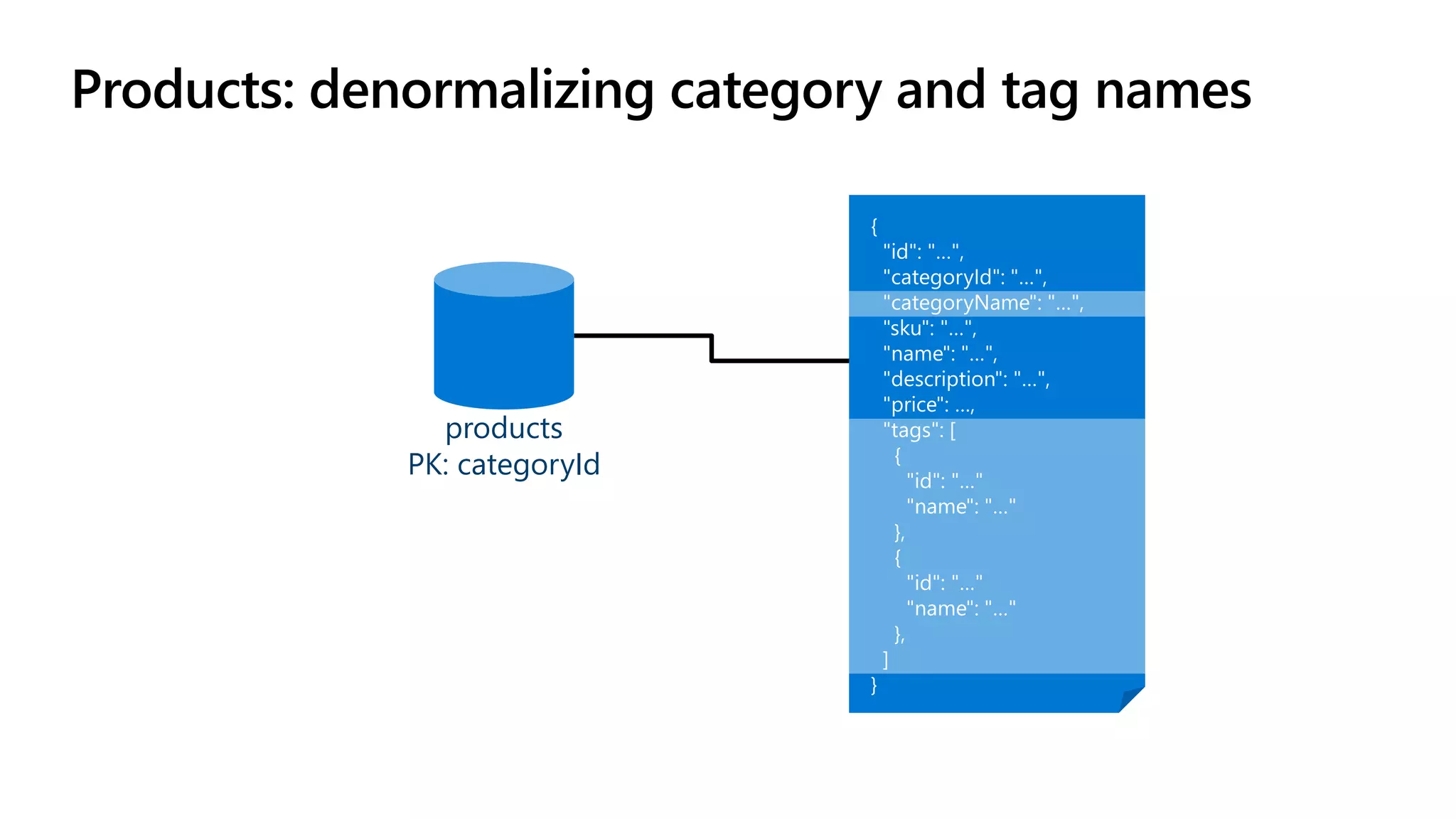
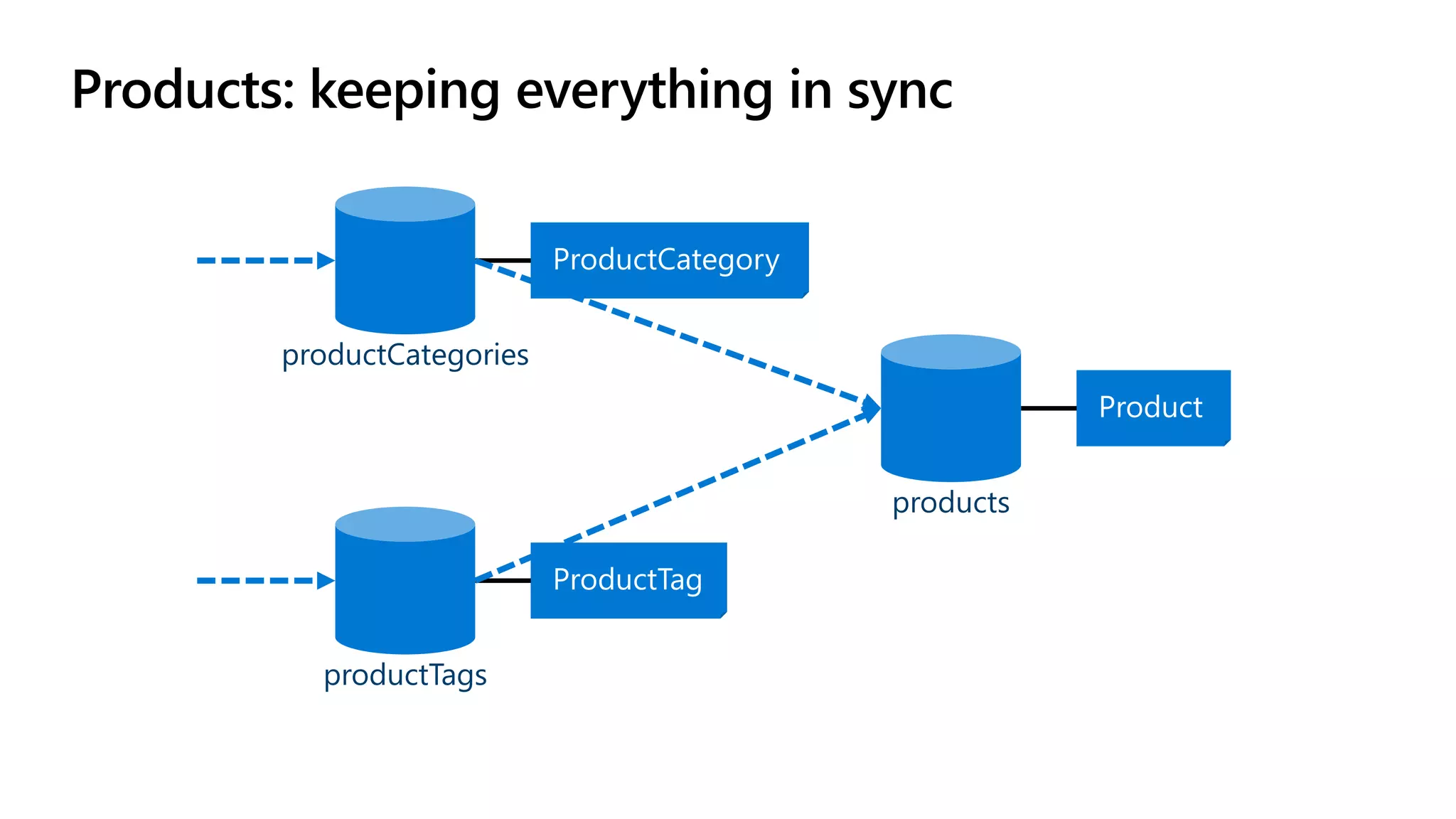

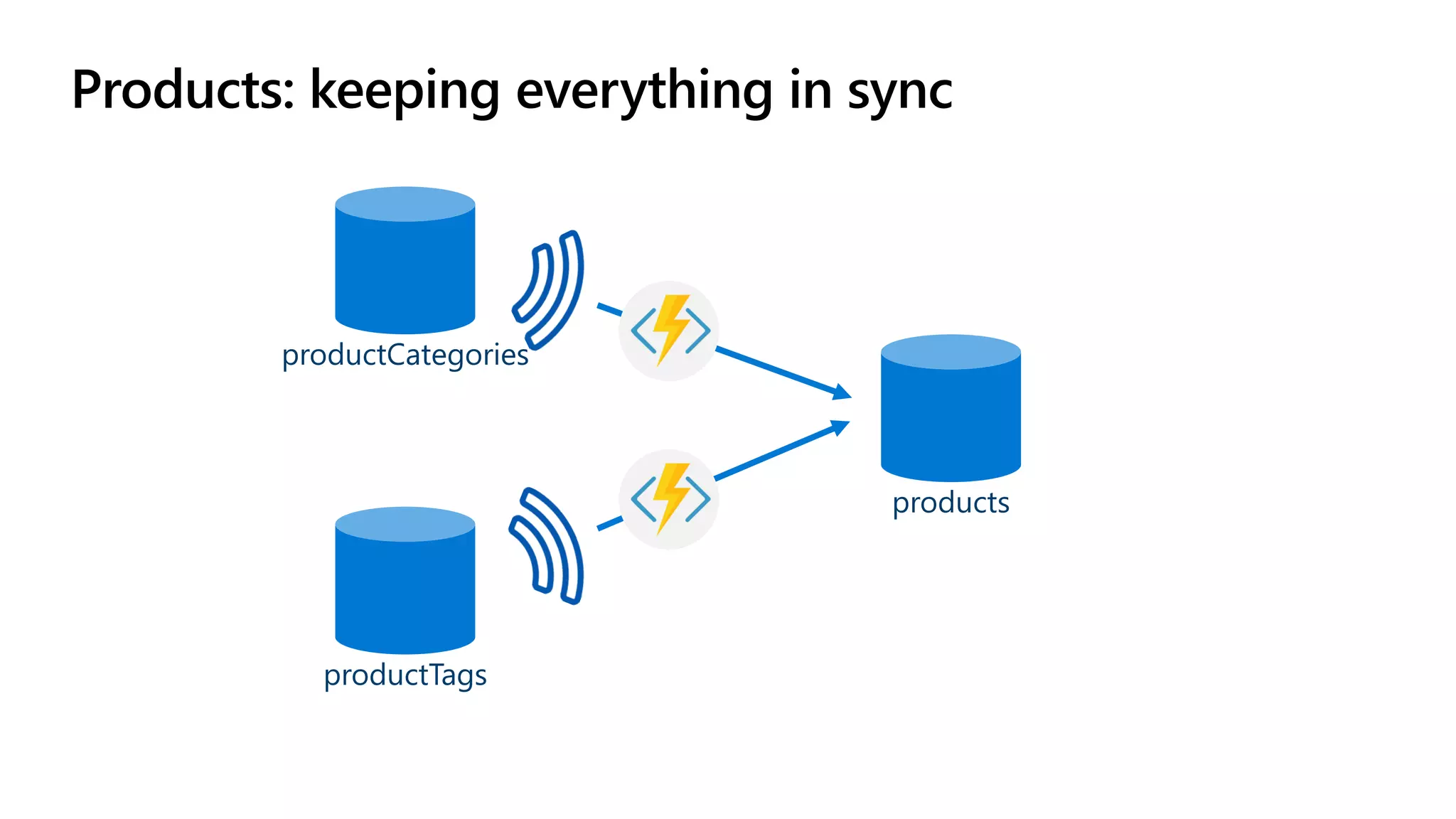
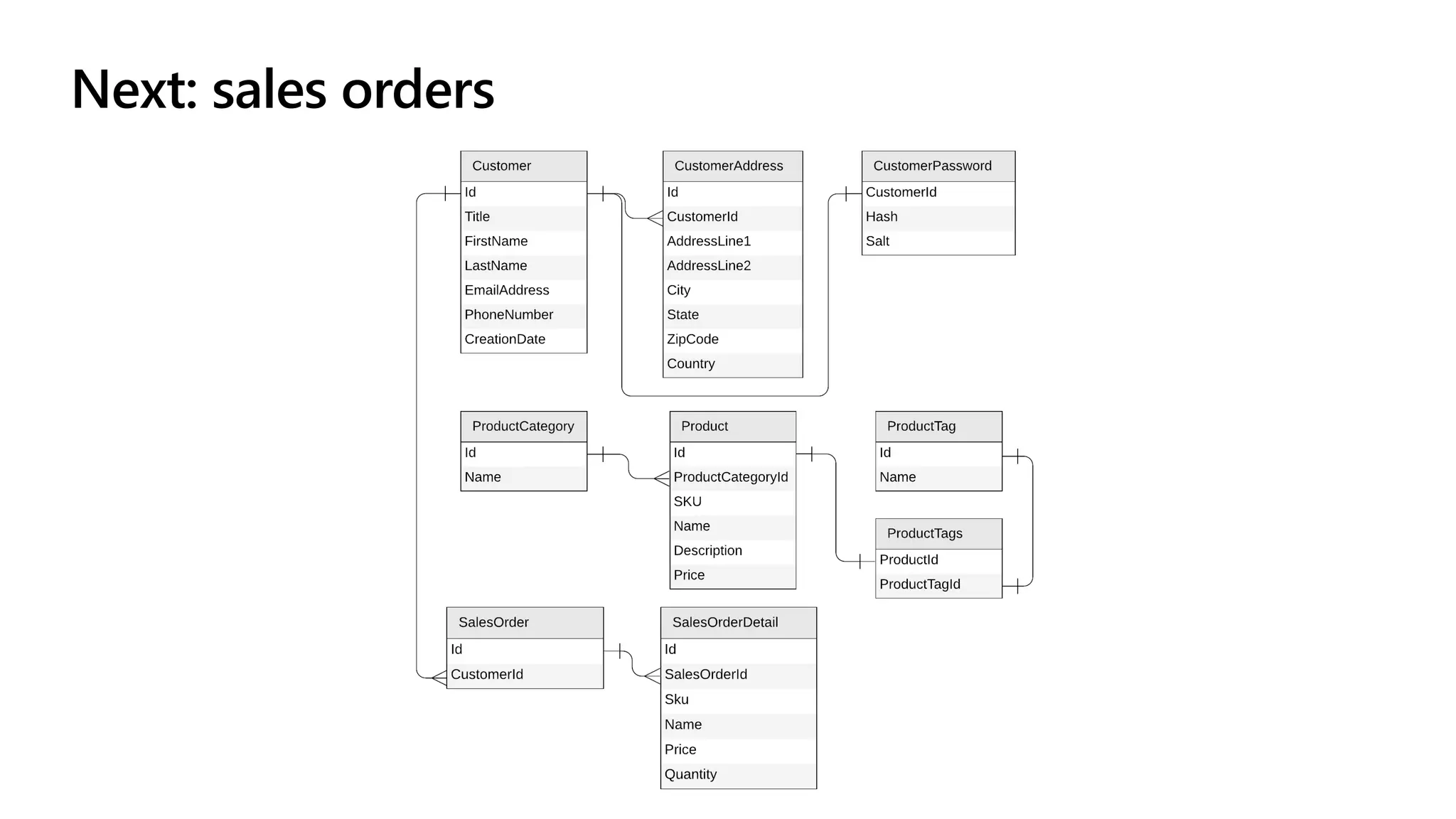




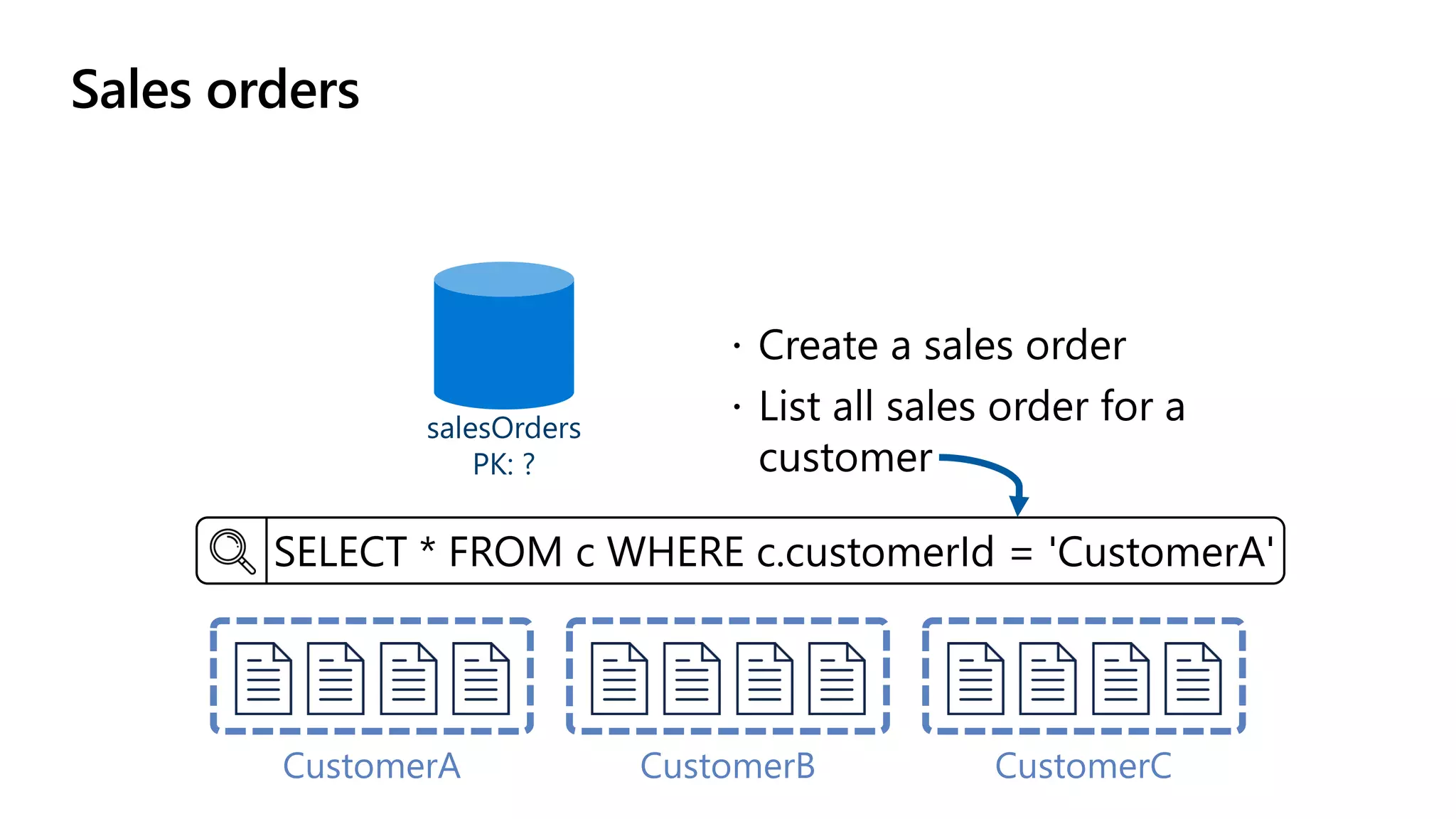
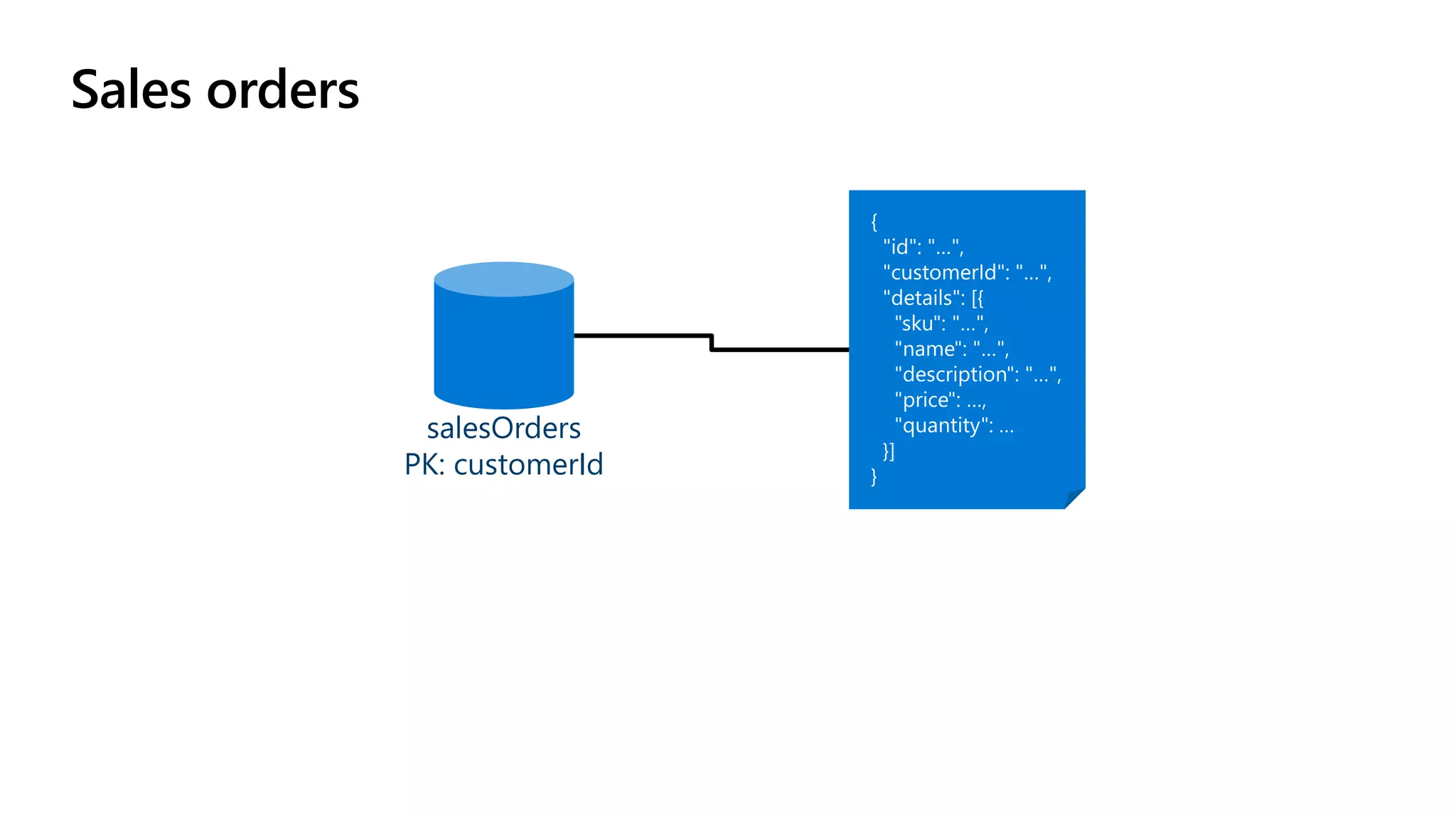
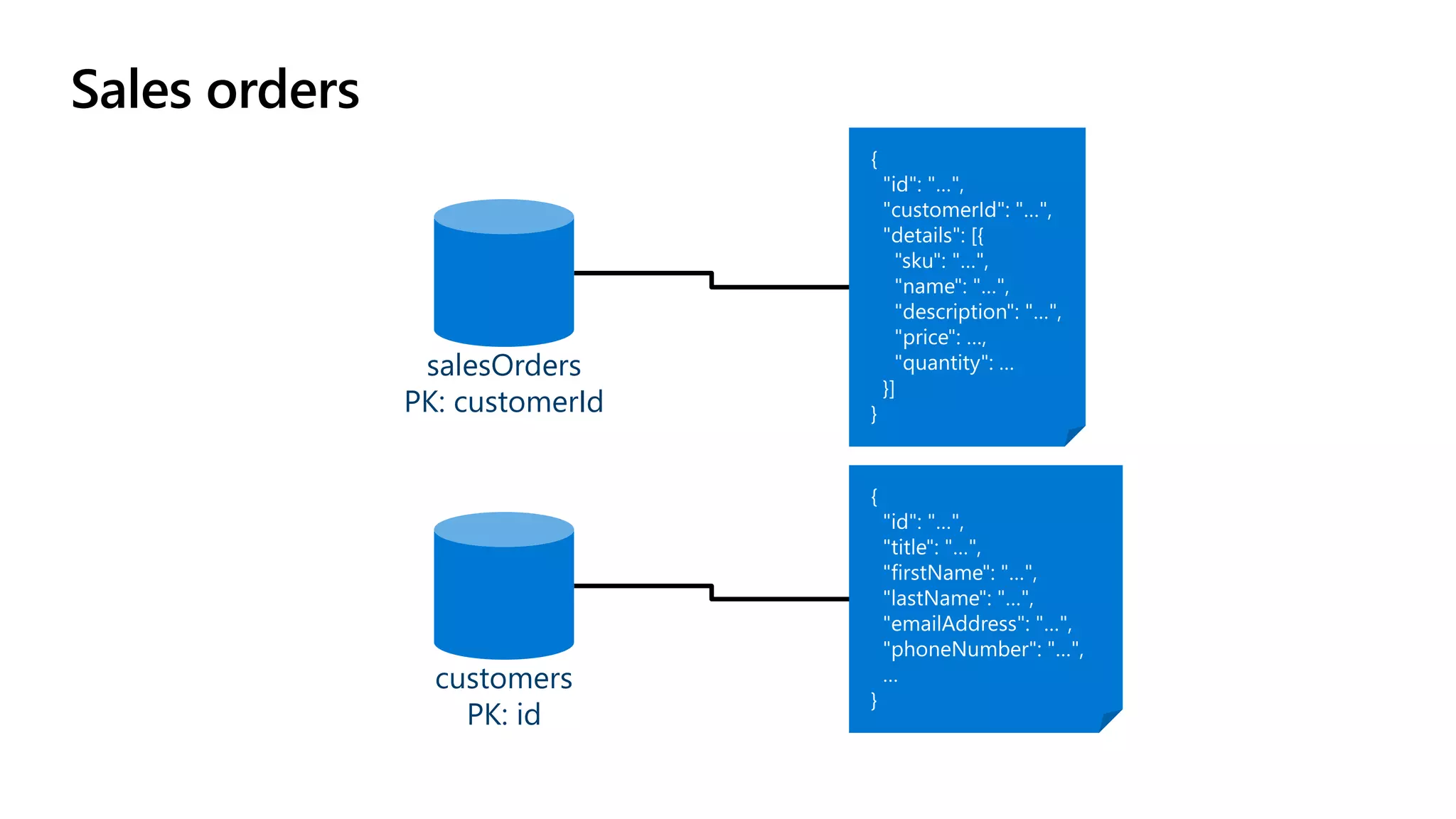

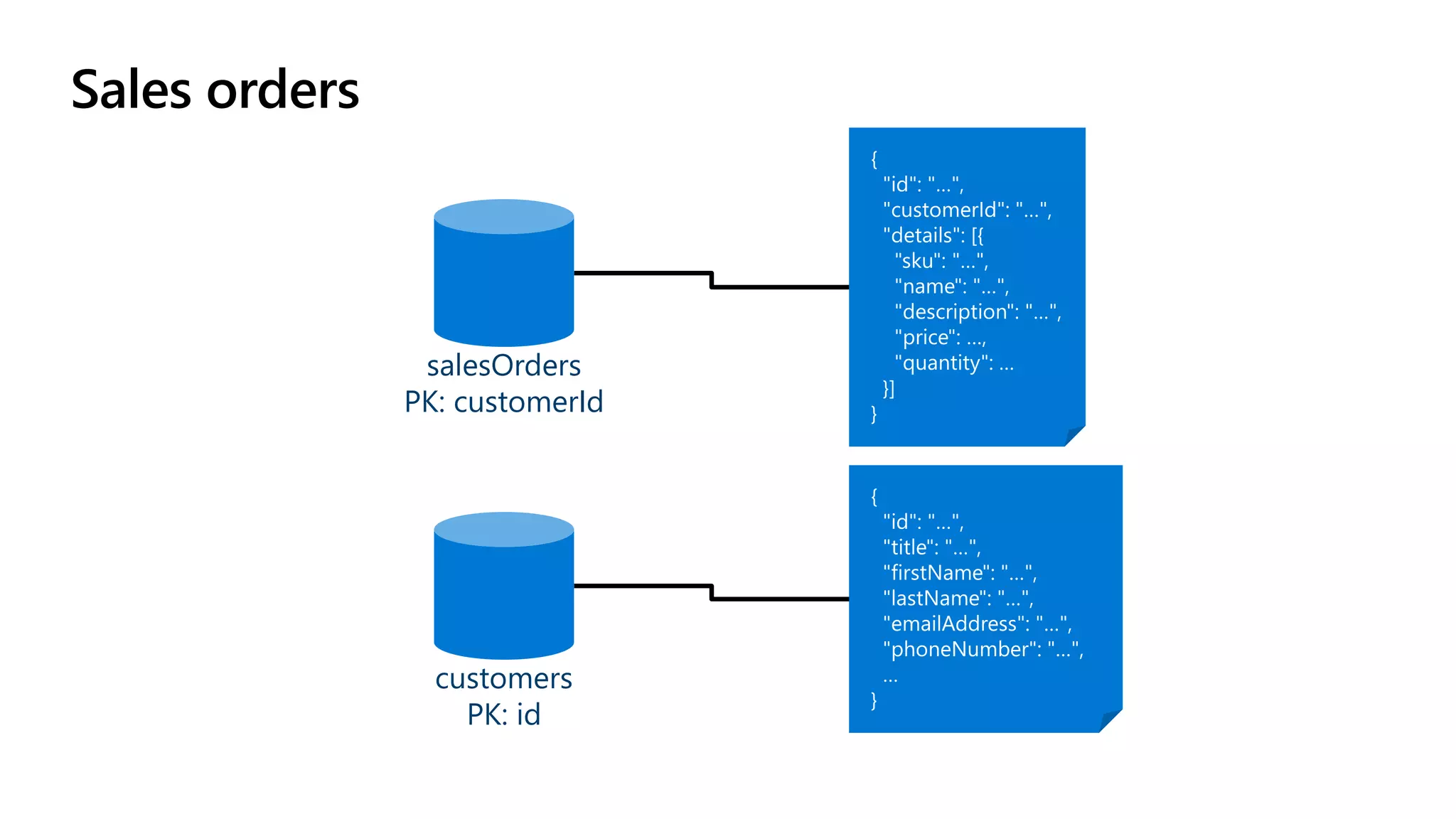
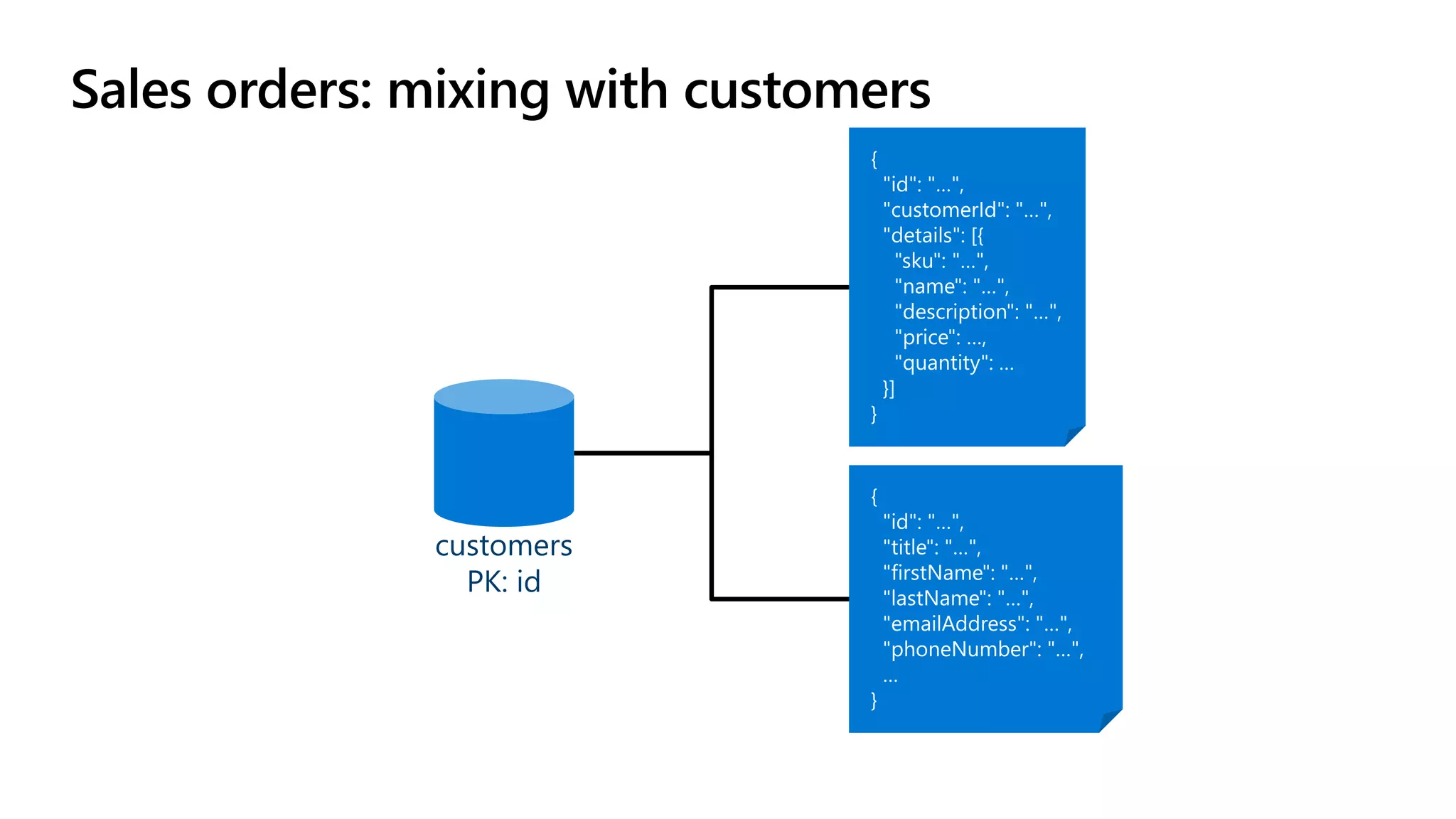
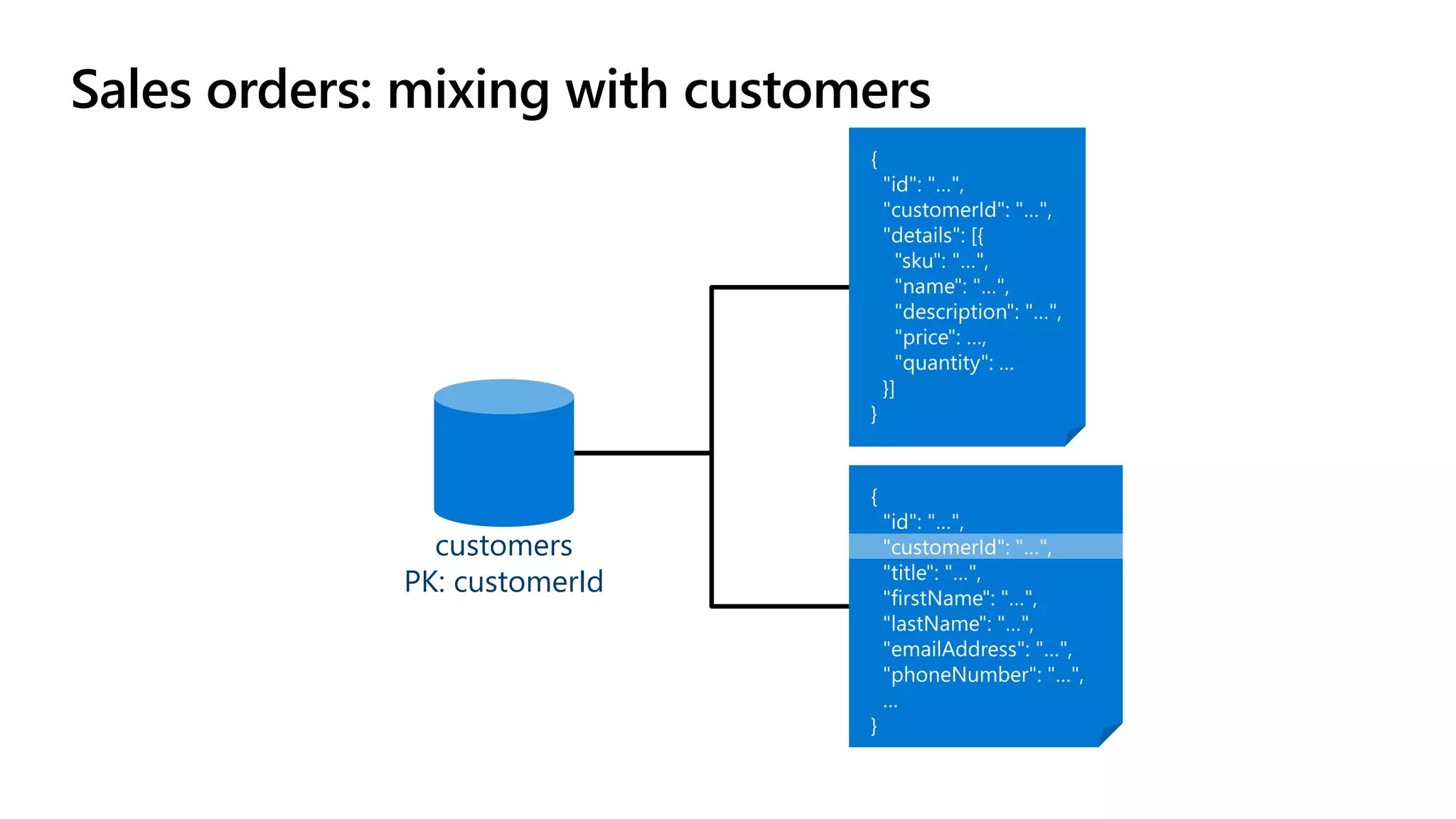
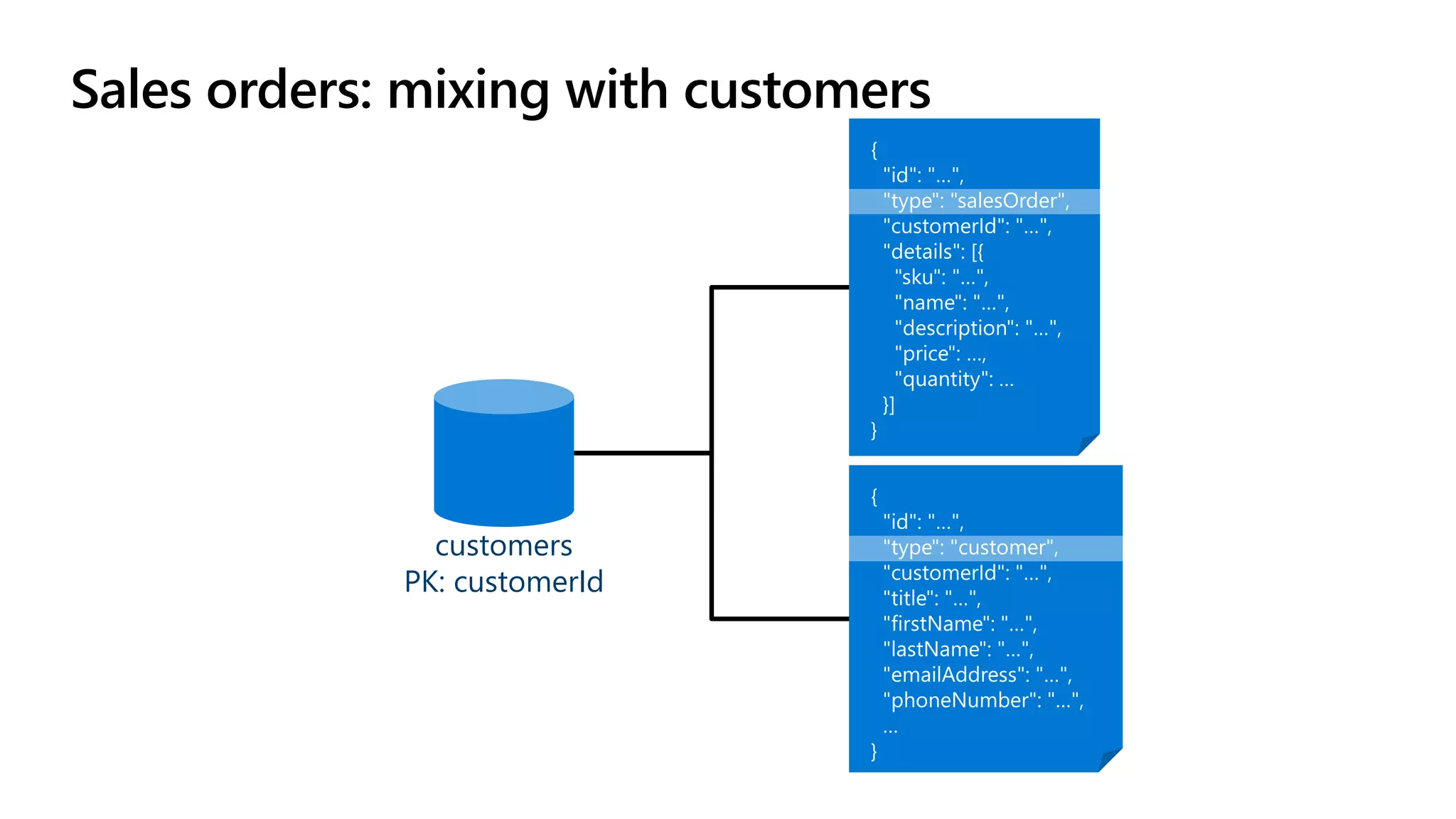
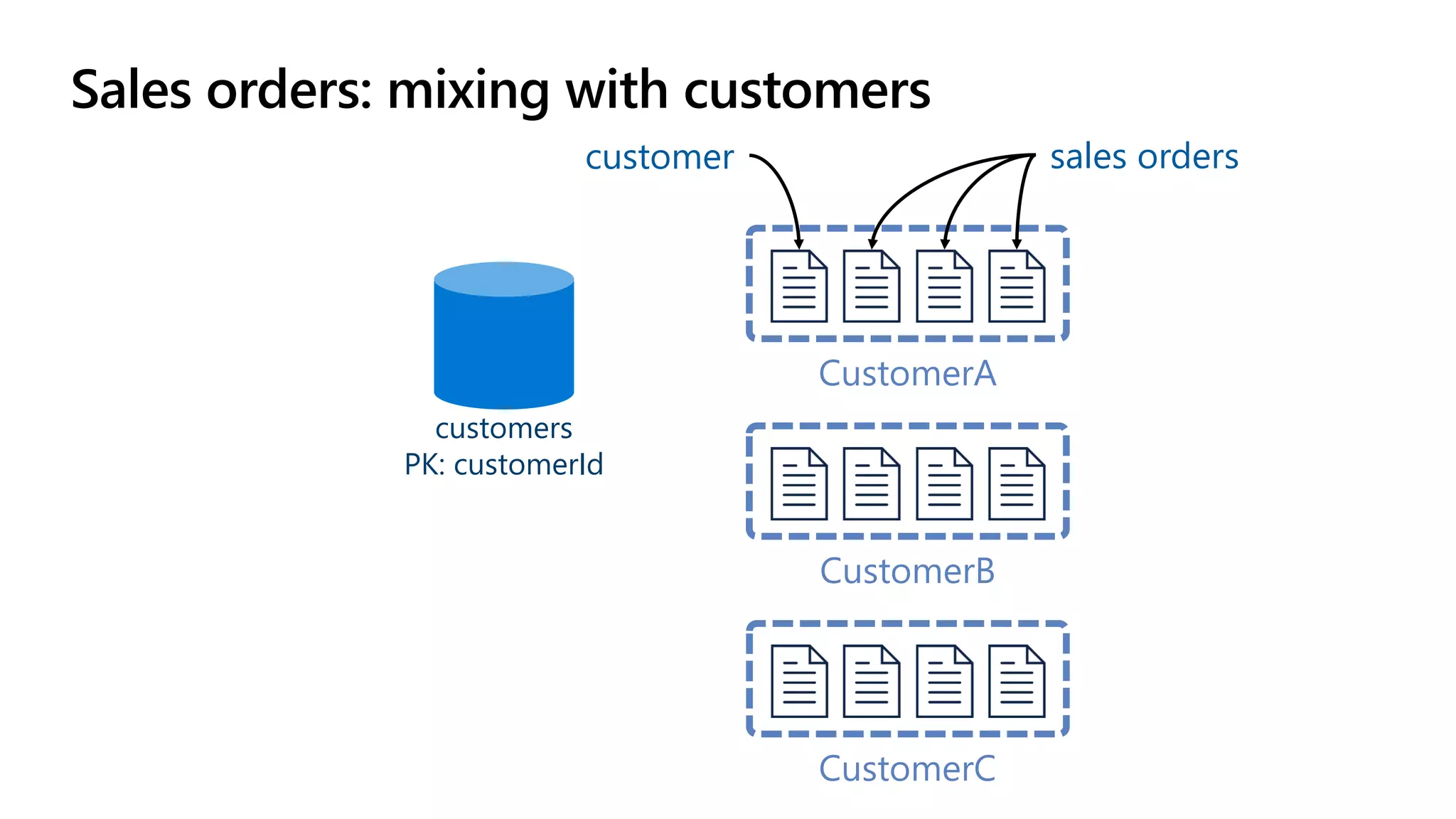




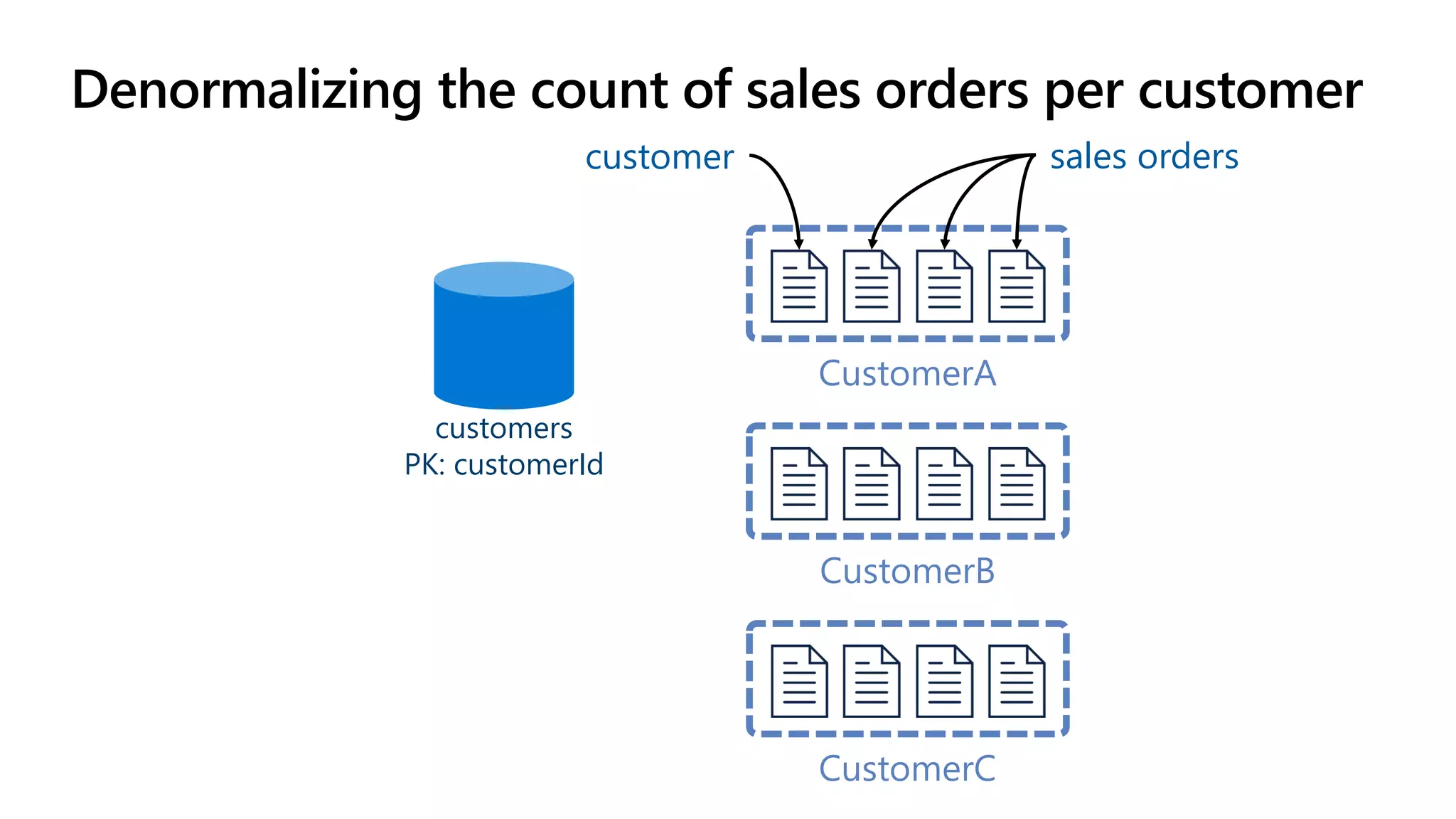
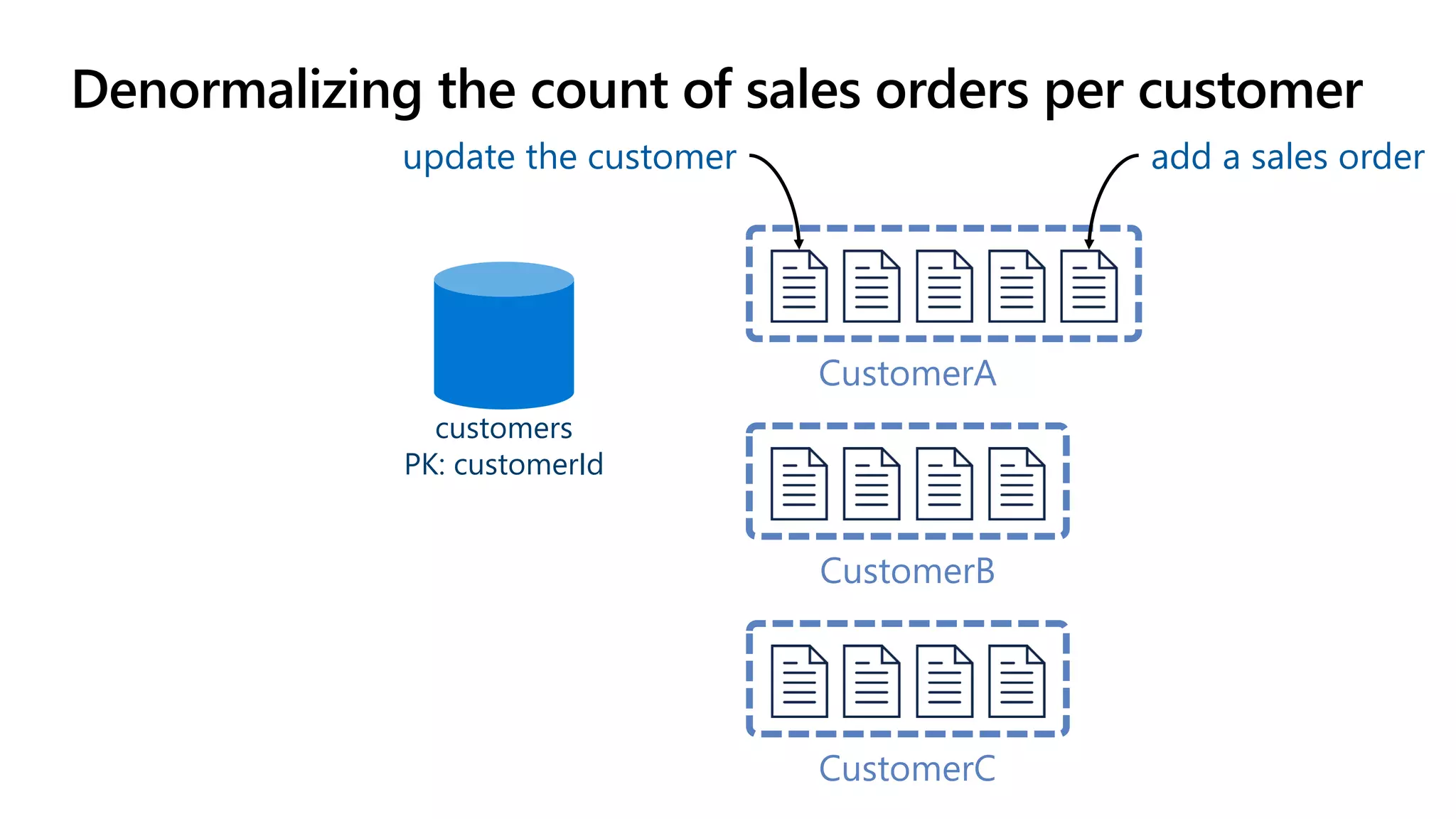
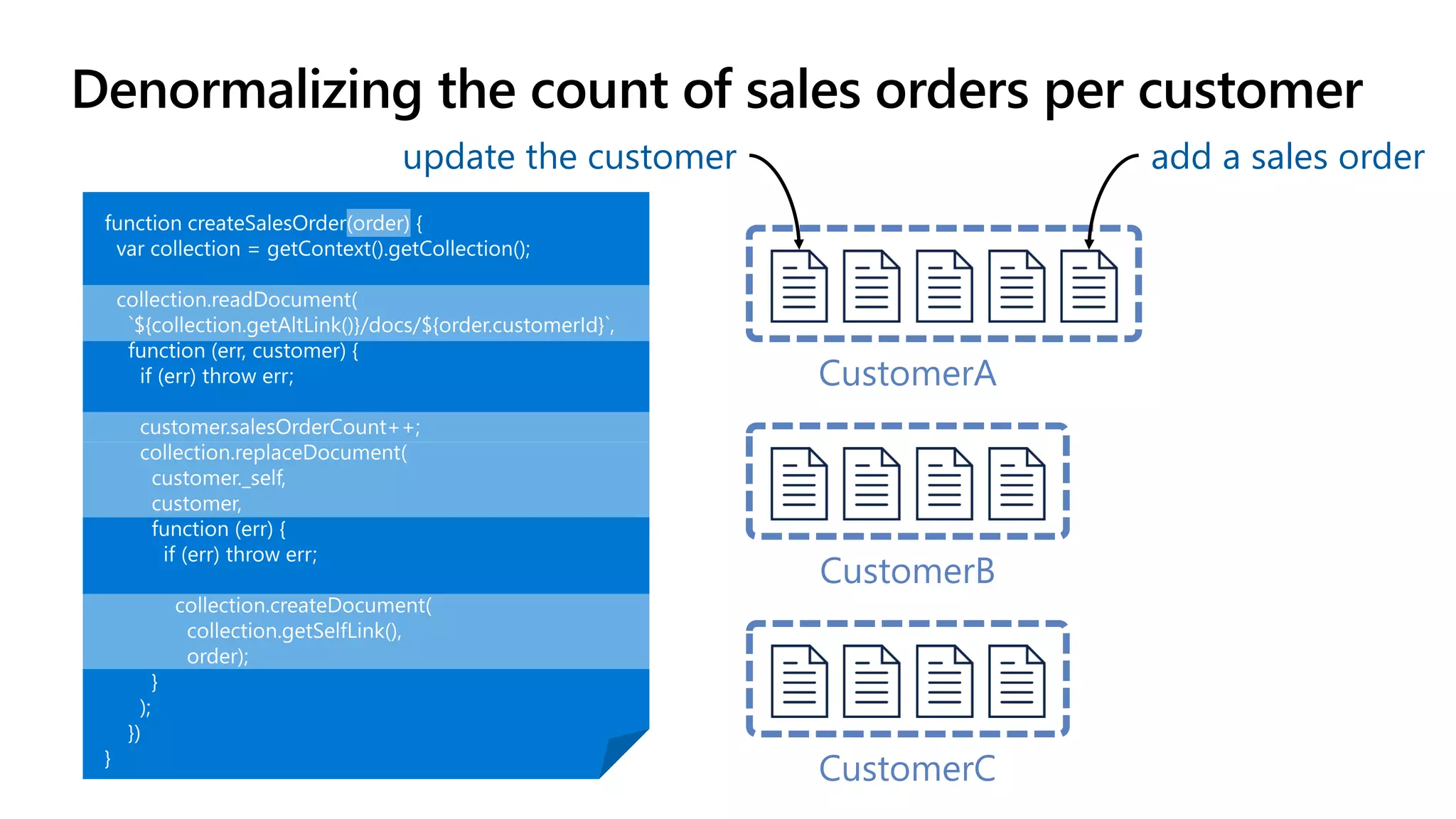

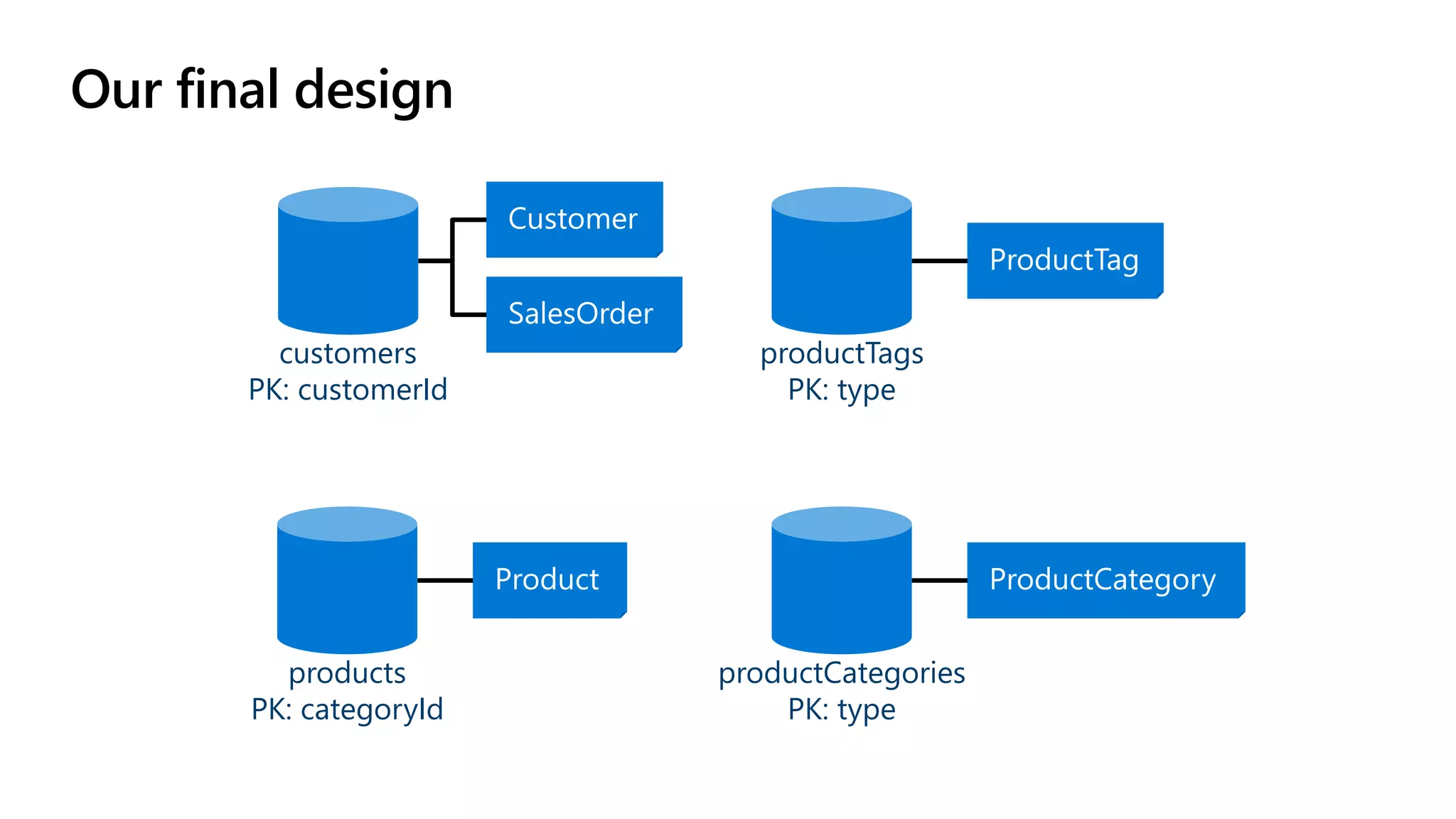
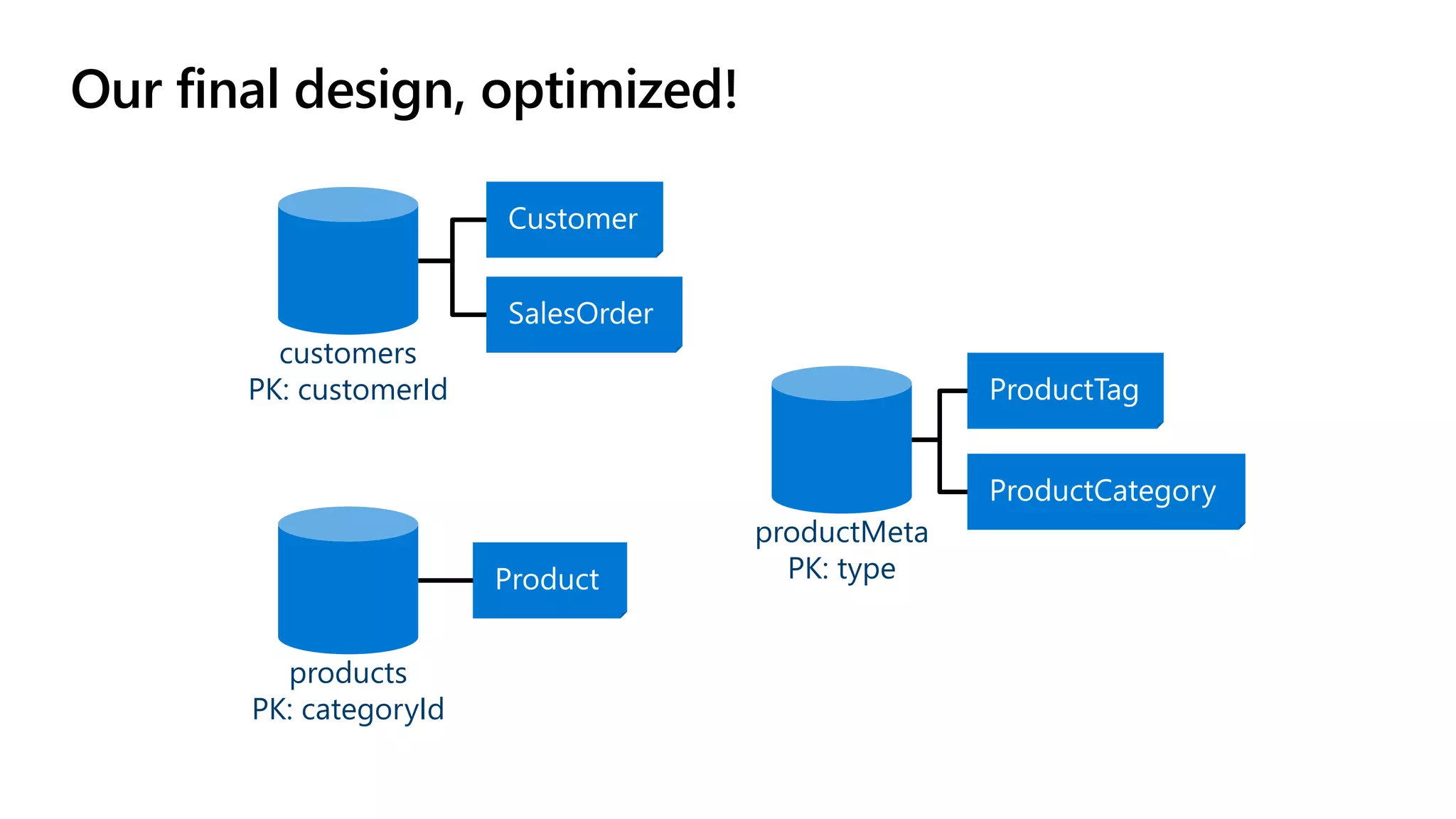



The document discusses data modeling and partitioning in Azure Cosmos DB. It begins with an overview of Cosmos DB's scalability and flexibility as a non-relational database. It then walks through modeling common entities like customers, products, orders and optimizing the data model and partitioning strategy. The key aspects covered include choosing a partition key, embedding vs referencing data, denormalizing for performance, and using change feeds to keep data synchronized across partitions.















































![[db tech showcase Tokyo 2019] Azure Cosmos DB Deep Dive ~ Partitioning, Globa...](https://cdn.slidesharecdn.com/ss_thumbnails/20190927dbtechcosmosdb-190930083325-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Developers Festa Sapporo 2020] Microsoft/GitHubが提供するDeveloper Cloud (Develop...](https://cdn.slidesharecdn.com/ss_thumbnails/20201118devfestamicrosoftgithub-201205093137-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Machine Learning 15minutes! #61] Azure OpenAI Service](https://cdn.slidesharecdn.com/ss_thumbnails/20211127ml15minazureopenaiservice-211206154233-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Serverless OpenHack Tokyo] Azure Serverless (English)](https://cdn.slidesharecdn.com/ss_thumbnails/20191112sohtokyokeynoteen-191114030923-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第43回 Machine Learning 15minutes! × 2] Azure AI Updates](https://cdn.slidesharecdn.com/ss_thumbnails/20200125ml15minazureai-200125062441-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Machine Learning 15minutes! Broadcast #67] Azure AI - Build 2022 Updates and...](https://cdn.slidesharecdn.com/ss_thumbnails/20220625ml15minazureaibuild2022updates-220626102255-c87d66ae-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第50回 Machine Learning 15minutes! Broadcast] Azure Machine Learning - Ignite ...](https://cdn.slidesharecdn.com/ss_thumbnails/20201205ml15minazuremlignite-201205101214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第45回 Machine Learning 15minutes! Broadcast] Azure AI - Build 2020 Updates](https://cdn.slidesharecdn.com/ss_thumbnails/20200530ml15minazureai-200602091349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Developers Festa Sapporo 2019] Azure Updates - Ignite 2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191113devfestaazureignite-191114112700-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Azure Council Experts (ACE) 第37回定例会] Microsoft Azureアップデート情報 (2019/08/22-201...](https://cdn.slidesharecdn.com/ss_thumbnails/20191018aceazureupdate-191021072729-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Serverless OpenHack Tokyo] Azure Serverless (Japanese)](https://cdn.slidesharecdn.com/ss_thumbnails/20191112sohtokyokeynoteja-191114031236-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Azure Council Experts (ACE) 第36回定例会] Microsoft Azureアップデート情報 (2019/06/14-201...](https://cdn.slidesharecdn.com/ss_thumbnails/20190822aceazureupdate-190823012159-thumbnail.jpg?width=640&height=640&fit=bounds)



















