Download to read offline

![+
Definition of Ontology in
Computer Science
n A conceptualization is a mathematical construct that contains
abstract references to (1) objects, (2) relations, (3) functions,
and (4) events as may be observed in a given real world.
n An ontology is a shared, [first order] logical, computer-
stored, specification of such an agreed explicit
conceptualization.
n [Tarski 1908, Gruber 1993, Studer 2000, et al.].](https://image.slidesharecdn.com/2012-04-26-ifip-wg-pptx-120430044659-phpapp02/85/2012-04-26-ifip-wg-pptx-2-320.jpg)

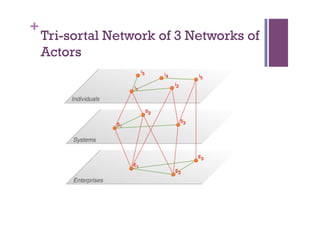




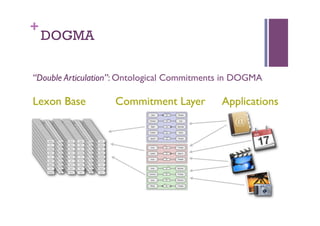



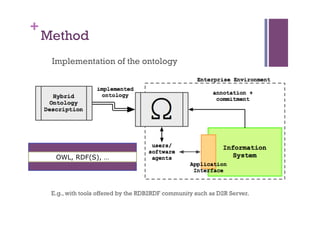

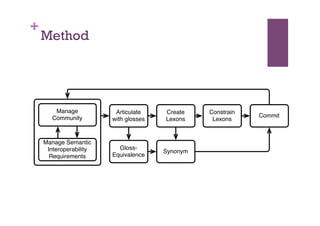


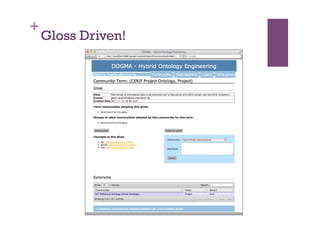




The document discusses the definition and significance of ontologies in computer science, focusing on their role in establishing shared meanings among autonomous systems while facilitating interoperability. It emphasizes the dual perspectives of human and system reasoning, and the need for community involvement in ontology development through methods such as discourse analysis and legacy data utilization. The document also explores hybrid ontology engineering and the integration of natural language processing to enhance semantic interoperation.











































































