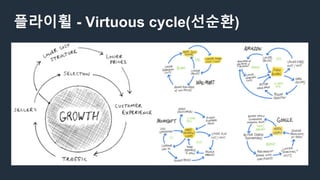
데이터 분석의 딜레마
데이터로하고 싶은일
● 마케팅/광고 최적화, 개인화
● 고객 이탈 방지
● 원인 분석
● 매출 증대
● 성과 측정
● 트렌드 파악/예측
● 쉽고 편한 분석
이미 겪고 있거나 예상되는 문제점들
● 데이터 한군데 저장 어려움
● 다양한 데이터 포맷 정제 필요
● 일단 실험에 드는 부담
● 레거시 vs 신규 시스템
● 기술 내재화 어려움
● 채용 어려움
● 시간도 돈도 없음
● 법과 규제에 따른 데이터 활용 제약 (공유, 식별)
7.
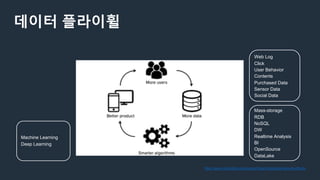
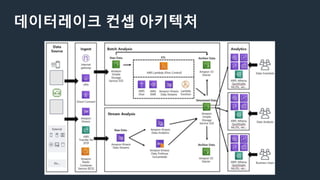
데이터레이크 정의
참고 -https://www.samsungsds.com/global/ko/support/insights/data_lake.html
8.
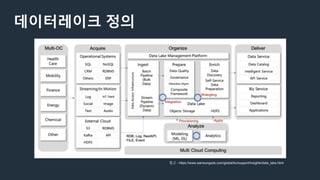
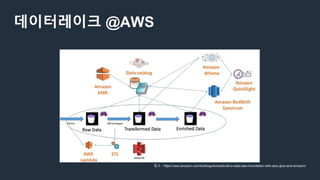
데이터레이크 @AWS
● Centralizedrepository that allows you to
store all your structured and unstructured
data at any scale.
● From dashboards and visualizations to big
data processing, real-time analytics, and
machine learning to guide better decisions.
참고 - https://aws.amazon.com/ko/big-data/datalakes-and-analytics/what-is-a-data-lake/
9.
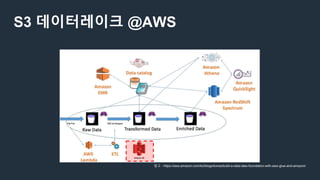
데이터레이크 @AWS
참고 -https://aws.amazon.com/ko/blogs/korea/build-a-data-lake-foundation-with-aws-glue-and-amazon/
10.
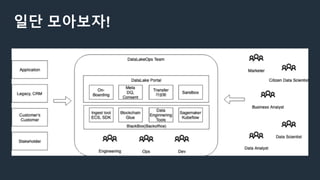
DataOps
@Wikipedia
DataOps is anautomated, process-oriented methodology, used by analytic and data teams, to
improve the quality and reduce the cycle time of data analytics.
@The DataOps Manifesto
Data Science, Data Engineering, Data Management, Big Data,
Business Intelligence, or the like, through our work we have come to value in analytics
11.
DataOps 원칙
https://www.dataopsmanifesto.org/dataops-manifesto.html
1. Continuallysatisfy your customer - 지속적으로 고객을 만족시켜라
2. Value working analytics - 분석을 가치있게 생각하라
3. Embrace change - 변화 수용
4. It's a team sport - 다양한 역할, 기술, 도구 수용
5. Daily interactions - 매일 협력
6. Self-organize - 자기주도
7. Reduce heroism - 영웅주의를 줄여라
8. Reflect - 반성하라
9. Analytics is code - 분석은 코드다
10. Orchestrate - 결합하라
11. Make it reproducible - 재현 가능하게 만들어라
12. Disposable environments - 비용 최소화
13. Simplicity - 단순성
14. Analytics is manufacturing - 분석은 제조와 같다
15. Quality is paramount - 품질이 제일 중요
16. Monitor quality and performance - 품질 및 성능을 모니터링하라
17. Reuse - 재사용하라
18. Improve cycle times - 사이클 타임을 개선하라
12.
이상적인 DataOps
• 목표를중심으로 스스로 조직
• No Hero, Sustainable, Scalable, Process 지향
• Data, Tool, Code, Environment 모두 장악이 필요함
• Reproducible 결과물 -> 분석 Pipeline
• Cross-Functional Team(교차기능 팀)
• Dev, Architect, Ops, Data Scientist, Data Engineer 모두 포함
• 개발자, 운영자, 데이터전문가 (3자 협업 구도)
• 데이터 중심 사고를 하는 사람들이 모여서 일을 하는 것
13.
하지만 엔터프라이즈에서는?
• 경영환경의 변화에 따른 Data 관리 어려움
• 분산된 환경으로 인한 Data Silo 문제
• Data 기반 의사결정 문화 확산 어려움
• 사용자 별 다양한 분석 환경 부족
설계 고려 사항
●No-Ops : Remove existing management (Serverless)
● GitOps : All infra, codes, and scripts are managed in immutable state
● Automation : Communications, Approvals, SRs, Issues
● 우리는 데이터가 없으니 어떤 가치를 줄 수 있을까?
서버리스 아키텍쳐 @Woot.com
참고- https://aws.amazon.com/ko/blogs/korea/our-data-lake-story-how-woot-com-built-a-serverless-data-lake-on-aws/
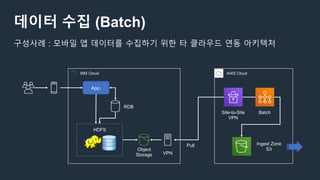
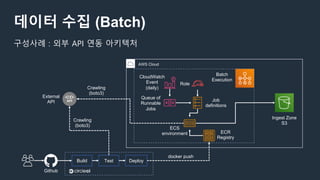
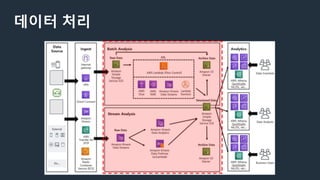
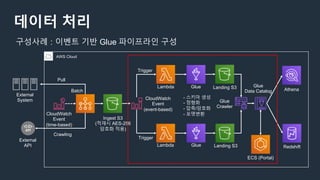
구성사례 : AWS Glue를 사용하여 완전한 서버리스 데이터 웨어하우스로 전환
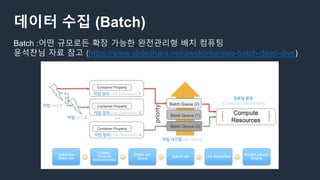
데이터 수집 (스트리밍)
KinesisData Firehose
- 스트리밍 데이터를 데이터 레이크에 로드하는 가장 쉬운 방법
참고 : https://aws.amazon.com/ko/kinesis/data-firehose/
24.
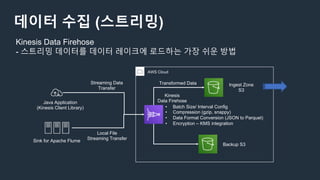
데이터 수집 (스트리밍)
KinesisData Firehose
- 스트리밍 데이터를 데이터 레이크에 로드하는 가장 쉬운 방법
AWS Cloud
Kinesis
Data Firehose
Transformed Data Ingest Zone
S3
Backup S3
Java Application
(Kinesis Client Library)
Sink for Apache Flume
Streaming Data
Transfer
Local File
Streaming Transfer
• Batch Size/ Interval Config
• Compression (gzip, snappy)
• Data Format Conversion (JSON to Parquet)
• Encryption – KMS integration
25.
직접 S3 전송
S3Transfer Acceleration
- 클라이언트와 S3 버킷 사이에서 파일을 빠르고 쉽고 안전하게 장거리 전송
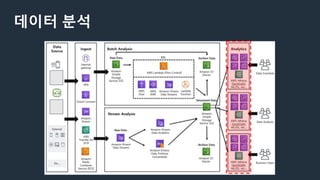
데이터 분석
Sagemaker
- 기계학습 모델을 빠르고 쉽게 구축, 훈련하고 배포까지 지원하는 서비스
레이블 구축 학습 및 튜닝 배포 및 관리
참고 : https://aws.amazon.com/ko/sagemaker/
32.
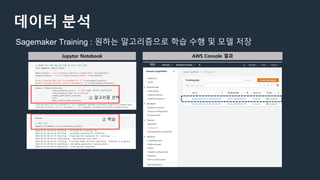
데이터 분석
• Jupyter샌드박스 제공
• Lifecycle 구성 스크립트 활용하여 사전 환경 구성
• https://github.com/aws-samples/amazon-sagemaker-notebook-instance-lifecycle-config-samples
• 사용량 빌링을 위한 Cost Explorer API 연동
• Assume Role을 활용한 원격 Account 분석환경 구성
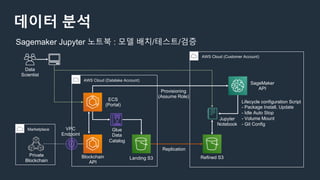
Sagemaker Jupyter 노트북 : 모델 배치/테스트/검증
33.
데이터 분석
AWS Cloud(Datalake Account)
AWS Cloud (Customer Account)
Landing S3
Glue
Data
Catalog
ECS
(Portal)
Refined S3
Private
Blockchain
Marketplace
Blockchain
API
Replication
SageMaker
API
Data
Scientist
Jupyter
Notebook
VPC
Endpoint
Provisioning
(Assume Role)
Lifecycle configuration Script
- Package Install, Update
- Idle Auto Stop
- Volume Mount
- Git Config
Sagemaker Jupyter 노트북 : 모델 배치/테스트/검증
34.
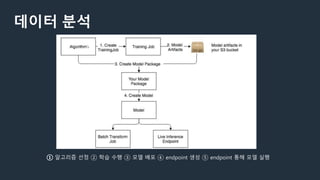
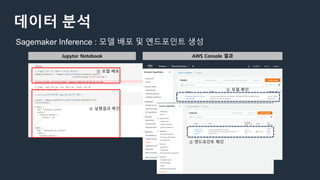
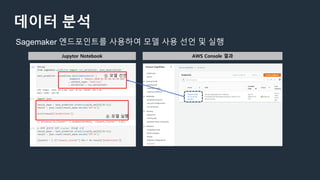
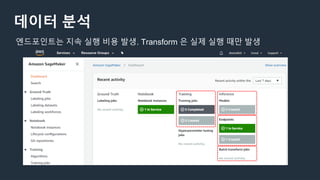
데이터 분석
① 알고리즘선정 ② 학습 수행 ③ 모델 배포 ④ endpoint 생성 ⑤ endpoint 통해 모델 실행
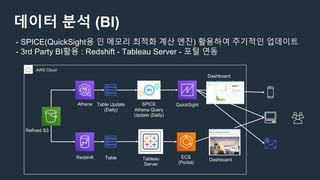
데이터 분석 (BI)
-SPICE(QuickSight용 인 메모리 최적화 계산 엔진) 활용하여 주기적인 업데이트
- 3rd Party BI활용 : Redshift - Tableau Server - 포털 연동
AWS Cloud
Athena
Redshift
QuickSight
Refined S3
Table Update
(Daily)
Table
SPICE
Athena Query
Update (Daily)
Tableau
Server
ECS
(Portal)
Dashboard
Dashboard
41.
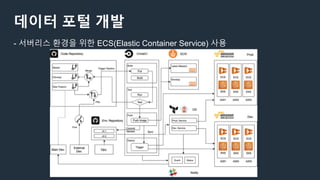
데이터 포털 개발
-서버리스 환경을 위한 ECS(Elastic Container Service) 사용
42.
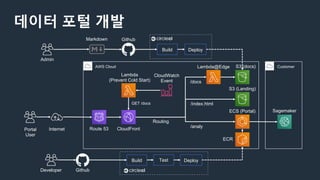
데이터 포털 개발
AWSCloud
Markdown Github
Build Deploy
Lambda
(Prevent Cold Start)
CloudWatch
Event
CloudFront
GET /docs
Portal
User
Internet
S3 (docs)
S3 (Landing)
ECS (Portal) Sagemaker
CustomerLambda@Edge
/docs
/index.html
/analy
Routing
Route 53
Admin
GithubDeveloper
Build DeployTest
ECR
43.
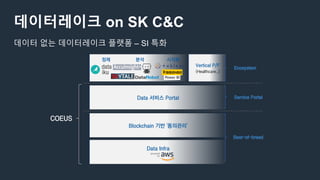
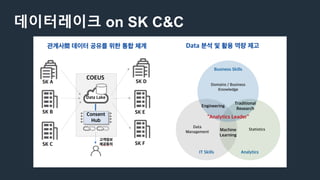
데이터레이크 on SKC&C
Data 서비스 Portal
Blockchain 기반 '동의관리'
Data Infra
정제 분석 시각화
Vertical P/F
(Healthcare..)
Ecosystem
Service Portal
Best-of-breed
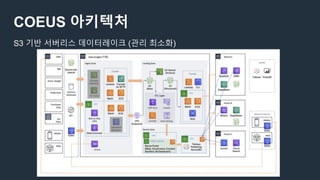
COEUS
데이터 없는 데이터레이크 플랫폼 – SI 특화
정리
• S3 중심서버리스 아키텍처도 충분히 적용 가능
• 완전관리형 서비스만이 정답은 아님 (Challenge)
• 기존 Hadoop ecosystem 통합
• 기존 조직과의 R&R (정보보호, 개발, 인프라)
• 서버리스 컴퓨팅 자원 : EKS on Fargate 검토 (서울 리전은 언제?)


























![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)


![[보험사를 위한 AWS Data Analytics Day] 5_KB금융그룹과 계열사의 AWS 기ᄇ...](https://cdn.slidesharecdn.com/ss_thumbnails/awsdataanalyticsday5kbawsanalyticsjourneybyeong-eokkang-230608094829-c0103aff-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Retail & CPG Day 2019] AWS기반의 Data 분석 플랫폼 구축, 고객사례 (GS SHOP) -김형일, AWS 솔루션즈 ...](https://cdn.slidesharecdn.com/ss_thumbnails/gsshop-191024042351-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[AWS Hero 스페셜] 서버리스 기반 검색 서비스 구축하기 - 이상현(스마일벤처스) :: AWS Community Day Online ...](https://cdn.slidesharecdn.com/ss_thumbnails/aa-201017071333-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWS Hero 스페셜] Amazon Personalize를 통한 개인화/추천 서비스 개발 노하우 - 소성운(크로키닷컴) :: AWS C...](https://cdn.slidesharecdn.com/ss_thumbnails/amazonpersonalize-201017065918-thumbnail.jpg?width=640&height=640&fit=bounds)


