The document provides an introduction to basic concepts in reinforcement learning including:
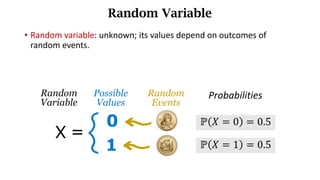
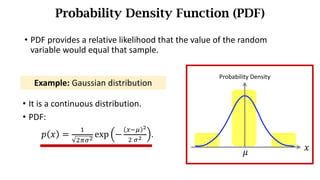
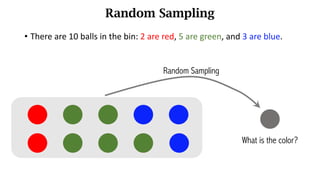
- Random variables and their probability distributions like the probability density function (PDF) and probability mass function (PMF).
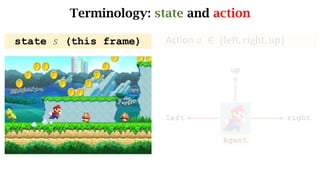
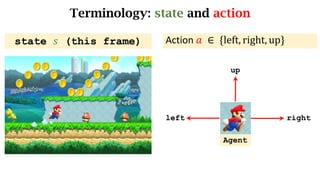
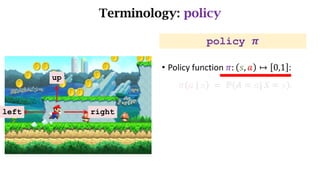
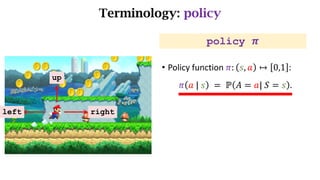
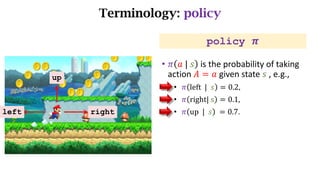
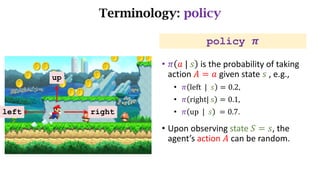
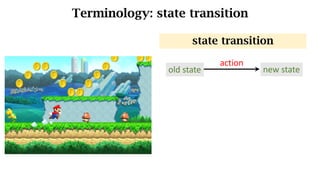
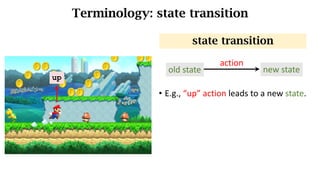
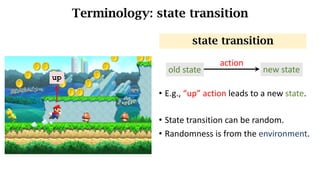
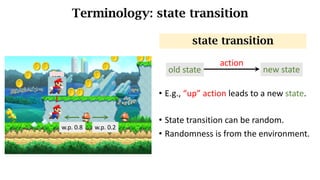
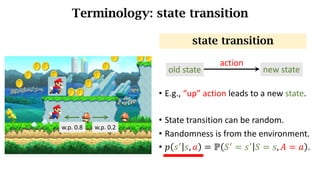
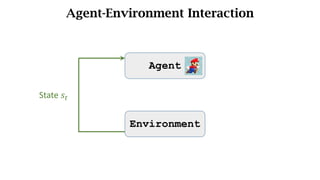
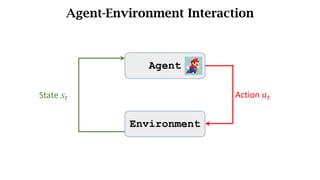
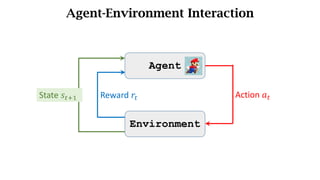
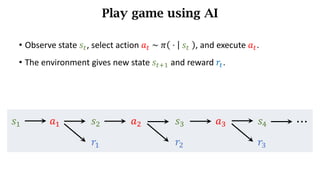
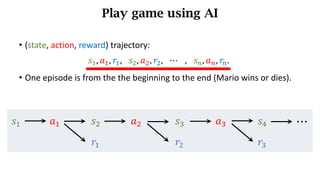
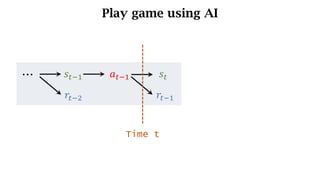
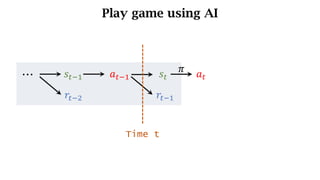
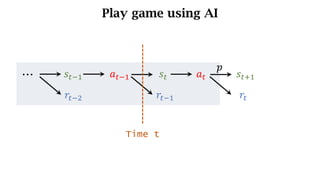
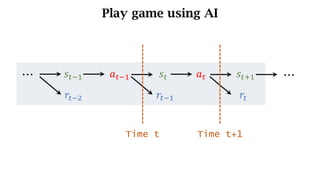
- The interaction between an agent and its environment including states, actions, policies, rewards, and state transitions.
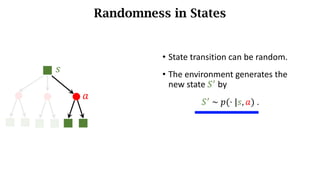
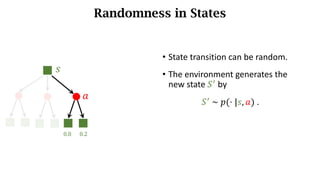
- Sources of randomness from the policy and environment.
- The concept of returns which aggregate future rewards with discounts to account for their declining importance.