About Speakers
• 성동찬
•KTH, 티몬, 카카오, (현)카카오뱅크 DBA
• 특이사항: ADT 프로젝트 도중 은행으로 튐
• A.k.a 배신자 (장난입니다.ㅎㅎ)
• 한수호
• 2007: (주)아이씨유 공동 창업
• 2012: 카카오에 인수됨(카카오랩으로 사명 변경)
• 카카오에서 계속 잘 지내는 중
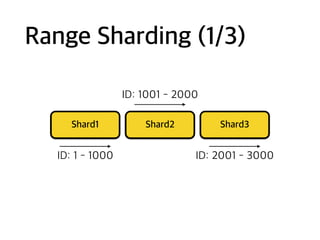
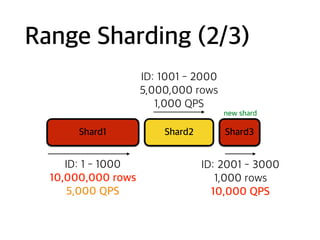
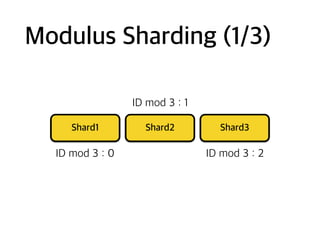
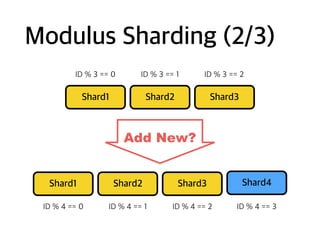
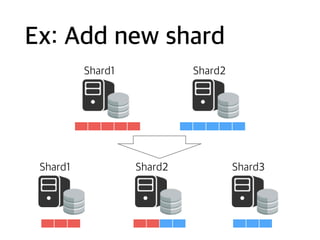
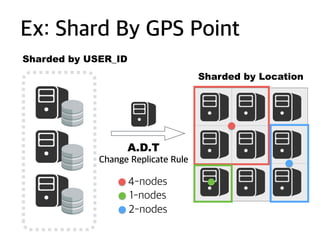
Ex: Change shardrule
ID: 1 - 1000
ID: 1001 - 2000
ID: 2001 - 3000
Range
ID mod 3: 0
ID mod 3: 1
ID mod 3: 2
Modulus
21.
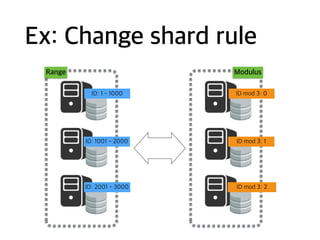
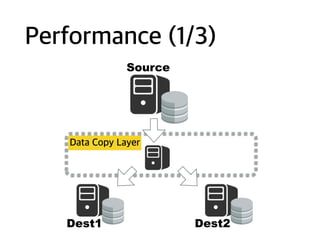
Ex: Copy todiff. DBMS
MySQL
HBase
MongoDB
NO side effect
22.
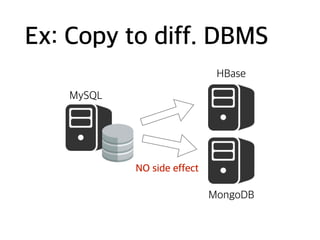
Ex: Copy todiff. schema
MySQL
MySQL
MySQL
ID AGE CNT V
1 30 5 msg1
2 29 10 msg2
ID CNT V
1 5 msg1
ID CNT V
2 10 msg2
NO side effect
23.
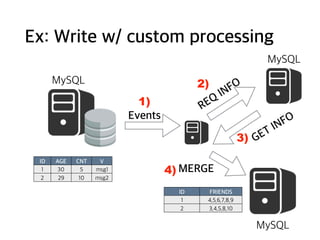
Ex: Write w/custom processing
MySQL
MySQL
MySQL
Events
ID AGE CNT V
1 30 5 msg1
2 29 10 msg2
1) REQ
INFO2)
3) GET INFO
4) MERGE
ID FRIENDS
1 4,5,6,7,8,9
2 3,4,5,8,10
Features
• Table Crawler
•SELECT 쿼리의 반복
SELECT * FROM ? [ WHERE id > ? ] LIMIT ?;
• Binlog Receiver
• MySQL Replication 프로토콜
• Custom Data Handler
• 수집한 데이터의 처리 부분
e.g. Shard reconstruction handler
• 여러 스레드에 의해 동시에 실행됨
32.
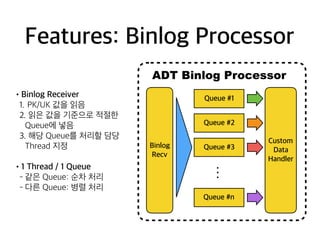
Features: Binlog Processor
Binlog
Recv
Queue#1
Custom
Data
Handler
Queue #2
Queue #3
Queue #n
…
ADT Binlog Processor
•Binlog Receiver
1. PK/UK 값을 읽음
2. 읽은 값을 기준으로 적절한
Queue에 넣음
3. 해당 Queue를 처리할 담당
Thread 지정
•1 Thread / 1 Queue
- 같은 Queue: 순차 처리
- 다른 Queue: 병렬 처리
33.
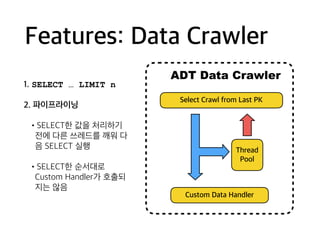
Features: Data Crawler
1.SELECT … LIMIT n
2. 파이프라이닝
•SELECT한 값을 처리하기
전에 다른 쓰레드를 깨워 다
음 SELECT 실행
•SELECT한 순서대로
Custom Handler가 호출되
지는 않음
Select Crawl from Last PK
Custom Data Handler
ADT Data Crawler
Thread
Pool
Req 1. RowFormat
각 Binlog는 Before, After 값이 필요합니다
N/A 1 : a=1, b=2, c=3
Before After
INSERT
1 : a=1, b=99, c=99 1 : a=1, b=2, c=3UPDATE
1 : a=1, b=99, c=99 N/ADELETE
36.
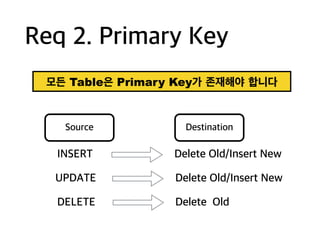
Req 2. PrimaryKey
DELETE
Source Destination
INSERT
UPDATE
Delete Old/Insert New
Delete Old/Insert New
Delete Old
모든 Table은 Primary Key가 존재해야 합니다
37.
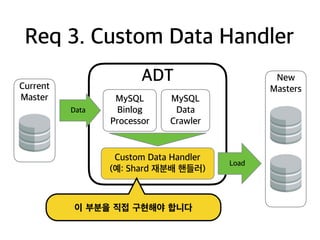
ADT
Req 3. CustomData Handler
MySQL
Binlog
Processor
MySQL
Data
Crawler
Custom Data Handler
(예: Shard 재분배 핸들러)
New
Masters
Load
Current
Master
Data
이 부분을 직접 구현해야 합니다
38.
기타 요구/제약 사항들
•Millisecond 사용 불가
• Alter Table 실시간 반영 안 됨
• 기타 등등...
Why Ignore FK?
•샤드 재구성 하려고 했던 곳이 성능을 위해 FK를 안 쓰는 곳이어서
• FK constraint 체크는 not null, check와 같이 master에서 이미 했
으므로 slave에서 할 필요 없다고 판단
• FK가 데이터 변경을 유발하지 않는 경우: 고려 X
• FK로 인해 다른 테이블 값 변경되는 경우
• table이 다르면 병렬 처리 시 conflict 가능성이 없음
• FK로 인해 같은 테이블 값 변경되는 경우
• 어차피 parent, child row 둘 다 다른 constraint에서 문제가 없
을 경우에만 binlog에 기록되므로 PK, UK만 고려
How Data CrawlerWorks
• SELECT
• SELECT using PK of ex-selected rows
• INSERT
• INSERT IGNORE is required
if Binlog Processor runs together
48.
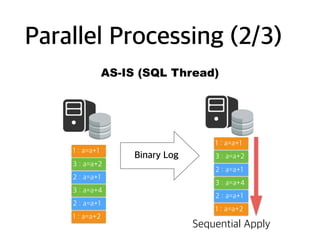
How to HandleBinlog? (1/4)
Row Event
Type
Query to Dest. (normally)
WRITE insert( after )
DELETE delete( before )
UPDATE update( before, after )
Normally binlog events are handled like this.
49.
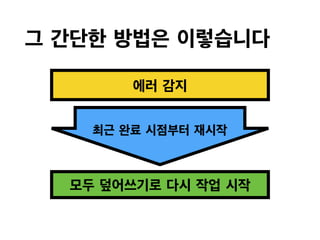
How to HandleBinlog? (2/4)
• However, we should consider…
- Unexpected restart
- Data inserted by Crawler
Overwriting!
50.
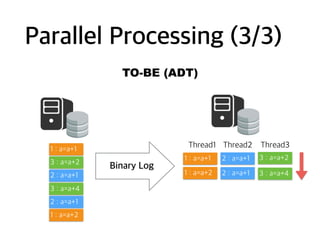
How to HandleBinlog? (3/4)
Row Event
Type
Query to Dest.
(Overwriting)
WRITE replace( after )
DELETE delete( before )
UPDATE
if( before.pk!=after.pk ){
delete( before )
}
replace( after )
51.
How to HandleBinlog? (4/4)
• Normal Query
UPDATE … SET @1=after.1, @2=after.2,…
WHERE pk_col=before.pk
• Transformation 1: Unrolling
DELETE FROM … WHERE pk_col=before.pk;
INSERT INTO … VALUES(after.1, after.2,…);
• Transformation 2: Overwriting
DELETE FROM … WHERE pk_col=before.pk;
REPLACE INTO … VALUES(after.1, after.2,…);
• Transformation 3: Reducing
• Delete [before] only if PK is changed
52.
Strategy 1
• Runsequentially
1. Crawl Data
2. Process Binary Log (after 1 is finished)
• Binlog file (created before starting) is required
• If crawling takes more than 3 days, then…?
53.
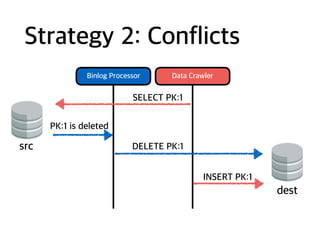
Strategy 2
• Runparallel with master DB
1. Start binlog processor
2. Start Data Crawler (ASAP after 1 is started)
with INSERT IGNORE
• Problem: conflicts
Strategy 2-1
• DataCrawler
- SELECT … FOR UPDATE when crawling
- ROLLBACK after INSERT IGNORE
• Binlog Processor
- Just act normally
Because there’s no logs for locked rows
• Problem: Multi row lock is dangerous for master DB
56.
Strategy 2-2
• BinlogProcessor
- Cache deleted history during a few minutes
• Data Cralwer
- If delete history exists, no INSERT
• Problems
- Complicated: Lock is neccesary for history cache
57.
Strategy 2-3
• Sameas Strategy 2-1, except using slave DB
• If sync is finished with slave,
restart with new config
- Receive binlog from master
Test Scenario
•Split into2 shards from 1 master DB
• Binary log only
•Query many updates into master DB
• 1K active sessions with random DML & data
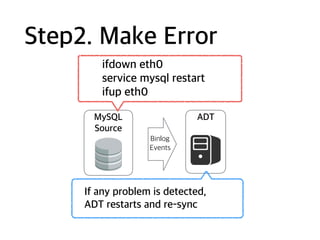
•Make errors
• Master DB: ifdown —> mysql restart —> ifup
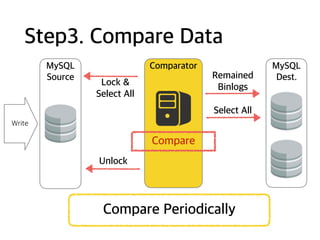
•Compare data
60.
Test DML List
INSERTINTO …
INSERT IGNORE INTO …
INSERT INTO … ON DUPLICATE KEY …
REPLACE INTO …
UPDATE …
DELETE …
61.
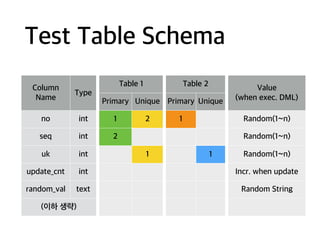
Test Table Schema
Column
Name
Type
Table1 Table 2
Value
(when exec. DML)Primary Unique Primary Unique
no int 1 2 1 Random(1~n)
seq int 2 Random(1~n)
uk int 1 1 Random(1~n)
update_cnt int Incr. when update
random_val text Random String
(이하 생략)
62.
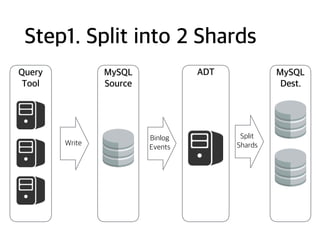
Step1. Split into2 Shards
MySQL
Source
Query
Tool
ADT
Binlog
Events
Write
MySQL
Dest.
Split
Shards
Wish to Applyfor…
Shard reconstruction (default)
MySQL binary log —> NoSQL
Copy data change history into OLAP
MySQL binary log —> Push Notification
Re-construct shards by GPS Point (Kakao Taxi?)
……
Next Dev. Plans
•Change language: Java —> GoLang
• Control Tower: Admin & Monitoring
• Is ADT alive?
• Save checkpoint for ungraceful restart
• Support Multiple DB Types
• Redis, PgSQL, ……
















![Features
• Table Crawler
• SELECT 쿼리의 반복
SELECT * FROM ? [ WHERE id > ? ] LIMIT ?;
• Binlog Receiver
• MySQL Replication 프로토콜
• Custom Data Handler
• 수집한 데이터의 처리 부분
e.g. Shard reconstruction handler
• 여러 스레드에 의해 동시에 실행됨](https://image.slidesharecdn.com/4-170510114403/85/Intro-KaKao-ADT-Almighty-Data-Transmitter-31-320.jpg)














![How to Handle Binlog? (4/4)
• Normal Query
UPDATE … SET @1=after.1, @2=after.2,…
WHERE pk_col=before.pk
• Transformation 1: Unrolling
DELETE FROM … WHERE pk_col=before.pk;
INSERT INTO … VALUES(after.1, after.2,…);
• Transformation 2: Overwriting
DELETE FROM … WHERE pk_col=before.pk;
REPLACE INTO … VALUES(after.1, after.2,…);
• Transformation 3: Reducing
• Delete [before] only if PK is changed](https://image.slidesharecdn.com/4-170510114403/85/Intro-KaKao-ADT-Almighty-Data-Transmitter-51-320.jpg)



























![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]Day #1 MySQL 엔진소개, 튜닝, 백업 및 복구, 업그레이드방법](https://cdn.slidesharecdn.com/ss_thumbnails/day1mysqlintroduction-141212003401-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[오픈소스컨설팅]Nginx 1.2.7 설치가이드__v1](https://cdn.slidesharecdn.com/ss_thumbnails/nginx1-2-7v1-130506223255-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









![[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.](https://cdn.slidesharecdn.com/ss_thumbnails/35-171016061446-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[223]rye, 샤딩을 지원하는 오픈소스 관계형 dbms](https://cdn.slidesharecdn.com/ss_thumbnails/223ryedbms-171016104435-thumbnail.jpg?width=640&height=640&fit=bounds)

![[오픈소스컨설팅]Day #3 MySQL Monitoring, Trouble Shooting](https://cdn.slidesharecdn.com/ss_thumbnails/day3mysqlmonitoringtroubleshooting-141215041202-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[스마트스터디]모바일 애플리케이션 서비스에서의 로그 수집과 분석](https://cdn.slidesharecdn.com/ss_thumbnails/redismongodbmysql-171107063045-thumbnail.jpg?width=640&height=640&fit=bounds)

























