Download to read offline





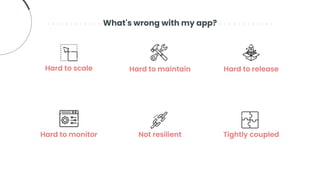











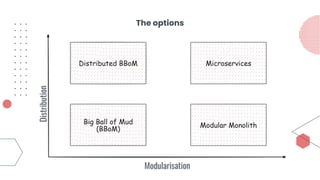
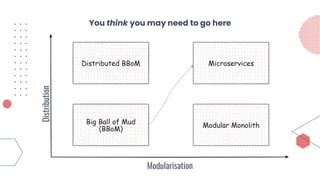
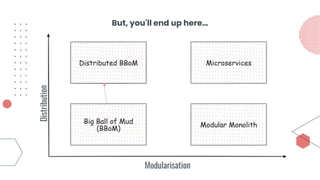
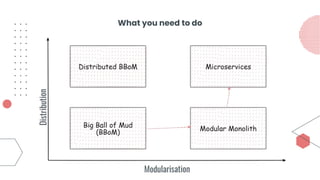


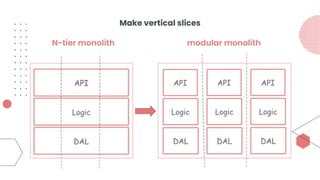
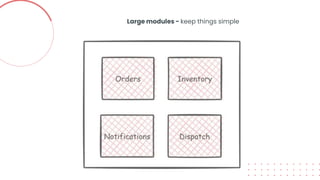
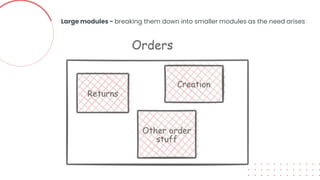
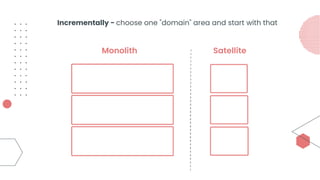



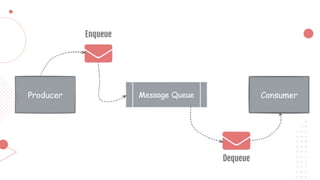


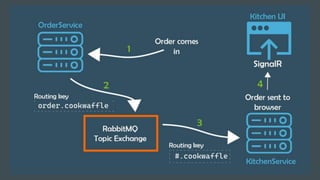





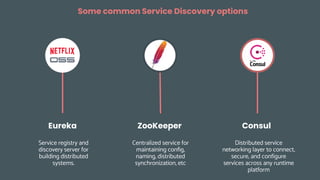


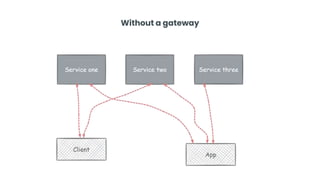
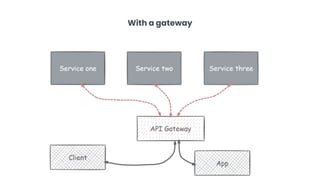

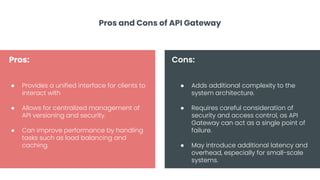



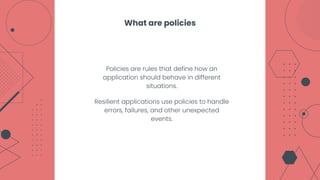


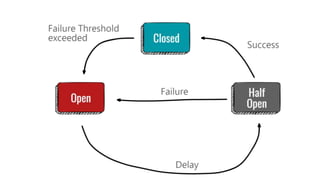



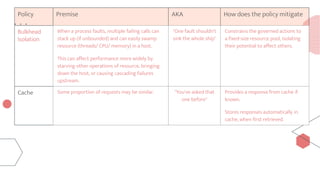




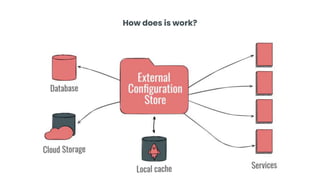








This document provides an overview of building cloud-ready applications in .NET. It defines what makes an application cloud-ready, discusses common issues with legacy applications, and recommends design patterns and practices to address these issues, including loose coupling, high cohesion, messaging, service discovery, API gateways, and resiliency policies. It includes code examples and links to additional resources.



































































