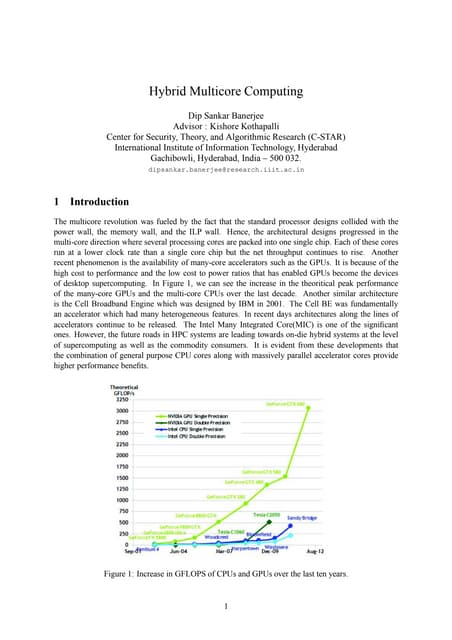


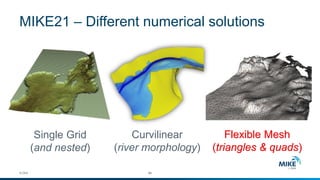
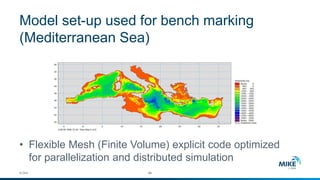

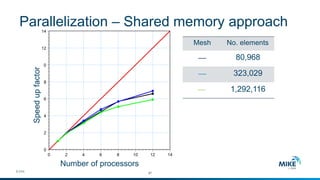

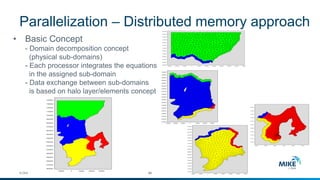
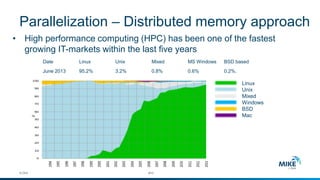
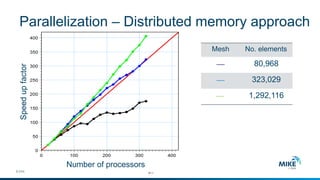


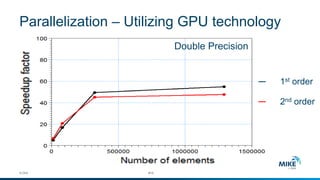

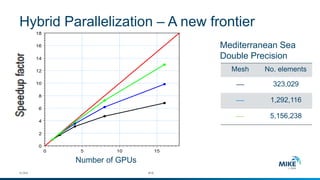
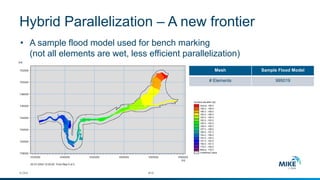
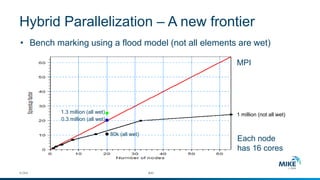
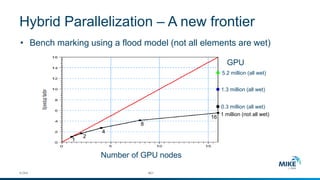
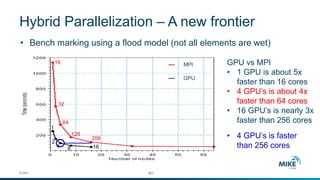
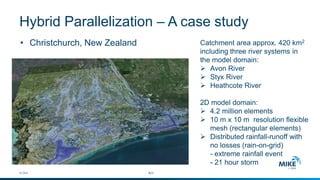






The document discusses advanced parallelization techniques and hardware for 2D modeling, focusing on shared and distributed memory approaches. It highlights the use of GPU technology for accelerating simulations, particularly in hydrodynamic modeling applications, and showcases benchmark results from various models and case studies. The findings suggest that hybrid MPI/GPU methods can significantly enhance performance and reduce computation time in modeling efforts.