人工知能セミナー:確率プログラミングの世界:論理と確率をつなぐ人工知能「深層学習と確率プログラミングを融合したEdwardについて」講演資料 ディープラーニングと確率モデルを統合的に扱うことのできるPythonライブラリEdwardの紹介と解説






![例1 混合ガウス: Edward による推論
深層学習と確率プログラミングを融合した についてEdward 13
T = 500 # サンプル数
qpi = Empirical(tf.Variable(tf.ones([T, K]) / K))
qmu = Empirical(tf.Variable(tf.zeros([T, K, D])))
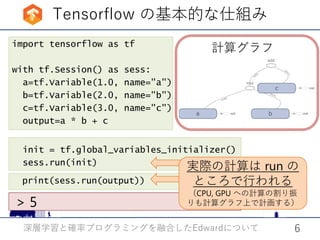
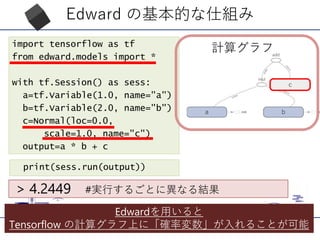
qsigmasq = Empirical(tf.Variable(tf.ones([T, K, D])))
qz = Empirical(tf.Variable(tf.zeros([T, N], dtype=tf.int32)))
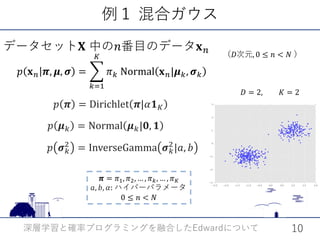
𝑝𝑝 𝐳𝐳|𝐱𝐱 を近似するための分布𝑞𝑞 𝐳𝐳 を定義
inference = ed.Gibbs(
{pi: qpi, mu: qmu, sigmasq: qsigmasq, z: qz},
data={x: x_train})
近似する分布のペアを与えてGibbsサンプリングのための計算グラフを作成
inference.run()
計算を実行](https://image.slidesharecdn.com/edward2017-171019115208/85/Edward-14-320.jpg)

![実例2 : VAE (Variational Auto Encoder)
𝐳𝐳
𝝁𝝁
𝚺𝚺
深層学習と確率プログラミングを融合した についてEdward 15
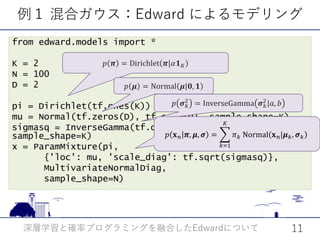
N=100
D=2
Mu=tf.zeros([N, D])
sigma=tf.ones([N, D])
z = Normal(loc=mu,scale=sigma)
hidden = Dense(256)(z.value())
x = Bernoulli(logits=hidden)
Kerasによる
ニューラルネット
のコード
モデル𝑝𝑝(𝐱𝐱, 𝐳𝐳) (デコーダ)
𝐱𝐱](https://image.slidesharecdn.com/edward2017-171019115208/85/Edward-16-320.jpg)
![実例2 : VAE (Variational Auto Encoder)
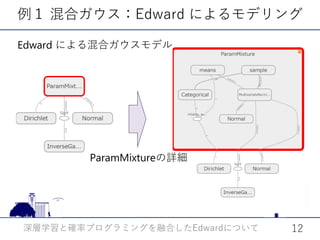
x_ph = tf.placeholder(tf.float32, [N, 256])
mu = Dense(256)(x_ph)
sigma = Dense(256, activation='softplus')(x_ph)
qz = Normal(loc=mu, scale=sigma)
深層学習と確率プログラミングを融合した についてEdward 16
𝐳𝐳
𝝁𝝁
𝚺𝚺
推論𝑞𝑞(𝐳𝐳|𝐱𝐱)(エンコーダ)
𝑞𝑞(𝐳𝐳|𝐱𝐱ph)
Kerasによる
ニューラルネット
のコード
𝐱𝐱ph 𝐱𝐱](https://image.slidesharecdn.com/edward2017-171019115208/85/Edward-17-320.jpg)
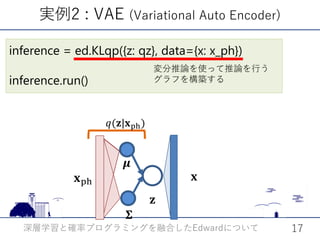
![z = Normal(loc=mu,scale=sigma)
hidden = Dense(4*4*128,activation=None)(z.value())
hidden=Reshape([4,4,128])(hidden)
hidden=Conv2DTranspose(64,(2,2),strides=(2, 2)) (hidden)
hidden=BatchNormalization() (hidden)
hidden=LeakyReLU(alpha=0.2)(hidden)
……
x = Bernoulli(logits=hidden)
実例2 : VAE (Variational Auto Encoder)
18
Kerasを用いてより複雑なニューラルネットのコードを書く
ことも可能
モデル𝑝𝑝(𝐱𝐱, 𝐳𝐳) (デコーダ)](https://image.slidesharecdn.com/edward2017-171019115208/85/Edward-19-320.jpg)
![z = Normal(loc=mu,scale=sigma)
hidden = Dense(4*4*128,activation=None)(z.value())
hidden=Reshape([4,4,128])(hidden)
hidden=Conv2DTranspose(64,(2,2),strides=(2, 2)) (hidden)
hidden=BatchNormalization() (hidden)
hidden=LeakyReLU(alpha=0.2)(hidden)
……
x = Bernoulli(logits=hidden)
実例2 : VAE (Variational Auto Encoder)
19
Kerasを用いてより複雑なニューラルネットのコードを書く
ことも可能
モデル𝑝𝑝(𝐱𝐱, 𝐳𝐳) (デコーダ)
学習データ
アニメイラストの顔データセット
http://www.nurs.or.jp/~nagadomi/
animeface-character-dataset/
生成したデータ](https://image.slidesharecdn.com/edward2017-171019115208/85/Edward-20-320.jpg)

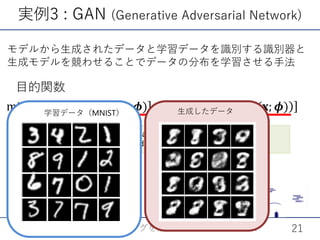












![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Deep Learning 第2章 線形代数](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearningchapter2-180601014406-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)


































