








![Bloom Filter: Add & Query
m bits (initially set to 0) if f(x) = A,
k hash functions set S[A] = 1
x
Add
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 1 2 m-1 m
6](https://image.slidesharecdn.com/datastructures-bloomfiltersmerkletrees-110417100758-phpapp01/85/Modern-Algorithms-and-Data-Structures-1-Bloom-Filters-Merkle-Trees-13-320.jpg)
![Bloom Filter: Add & Query
m bits (initially set to 0) if f(x) = A,
k hash functions set S[A] = 1
x
Add
f(x)
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1
0 1 2 m-1 m
6](https://image.slidesharecdn.com/datastructures-bloomfiltersmerkletrees-110417100758-phpapp01/85/Modern-Algorithms-and-Data-Structures-1-Bloom-Filters-Merkle-Trees-14-320.jpg)
![Bloom Filter: Add & Query
m bits (initially set to 0) if f(x) = A,
k hash functions set S[A] = 1
x
Add
g(x) f(x)
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1
0 1 2 m-1 m
6](https://image.slidesharecdn.com/datastructures-bloomfiltersmerkletrees-110417100758-phpapp01/85/Modern-Algorithms-and-Data-Structures-1-Bloom-Filters-Merkle-Trees-15-320.jpg)
![Bloom Filter: Add & Query
m bits (initially set to 0) if f(x) = A,
k hash functions set S[A] = 1
x
Add
g(x) f(x) h(x)
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1
0 1 2 m-1 m
6](https://image.slidesharecdn.com/datastructures-bloomfiltersmerkletrees-110417100758-phpapp01/85/Modern-Algorithms-and-Data-Structures-1-Bloom-Filters-Merkle-Trees-16-320.jpg)
![Bloom Filter: Add & Query
m bits (initially set to 0) if f(x) = A,
k hash functions set S[A] = 1
x y
g(y)
Add f(y)
g(x) f(x) h(x)
h(y)
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1
0 1 2 m-1 m
6](https://image.slidesharecdn.com/datastructures-bloomfiltersmerkletrees-110417100758-phpapp01/85/Modern-Algorithms-and-Data-Structures-1-Bloom-Filters-Merkle-Trees-17-320.jpg)
![Bloom Filter: Add & Query
m bits (initially set to 0) if f(x) = A,
k hash functions set S[A] = 1
x y
g(y)
Add f(y)
g(x) f(x) h(x)
h(y)
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1
0 1 2 m-1 m
Query
6](https://image.slidesharecdn.com/datastructures-bloomfiltersmerkletrees-110417100758-phpapp01/85/Modern-Algorithms-and-Data-Structures-1-Bloom-Filters-Merkle-Trees-18-320.jpg)
![Bloom Filter: Add & Query
m bits (initially set to 0) if f(x) = A,
k hash functions set S[A] = 1
x y
g(y)
Add f(y)
g(x) f(x) h(x)
h(y)
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1
0 1 2 m-1 m
f(z) h(z) g(z)
Query
z
6](https://image.slidesharecdn.com/datastructures-bloomfiltersmerkletrees-110417100758-phpapp01/85/Modern-Algorithms-and-Data-Structures-1-Bloom-Filters-Merkle-Trees-19-320.jpg)
![Bloom Filter: Add & Query
m bits (initially set to 0) if f(x) = A,
k hash functions set S[A] = 1
x y
g(y)
Add f(y)
g(x) f(x) h(x)
h(y)
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1
0 1 2 m-1 m
f(z) h(z) g(z)
Query
one bit set to 0
z ⇒z∉S
6](https://image.slidesharecdn.com/datastructures-bloomfiltersmerkletrees-110417100758-phpapp01/85/Modern-Algorithms-and-Data-Structures-1-Bloom-Filters-Merkle-Trees-20-320.jpg)
![Bloom Filter: Hash Functions
k Hash functions: uniform random distribution in [1...m)
k different hash functions
The same hash functions with different salts
Double or triple hashing : g (x) = h (x) + ih (x) mod m
[1]
i 1 2
2 hash functions can mimic k hashing functions
Dillinger, Peter C.; Manolios, Panagiotis (2004b), "Bloom Filters in Probabilistic Verification",
[1]
http://www.ccs.neu.edu/home/pete/pub/bloom-filters-verification.pdf
http://www.strchr.com/hash_functions 7](https://image.slidesharecdn.com/datastructures-bloomfiltersmerkletrees-110417100758-phpapp01/85/Modern-Algorithms-and-Data-Structures-1-Bloom-Filters-Merkle-Trees-21-320.jpg)
![Bloom Filter: Hash Functions
k Hash functions: uniform random distribution in [1...m)
k different hash functions
‣ Cryptographic Hash different salts
The same hash functions withFunctions
(MD5, SHA-1, SHA-256, Tiger, Whirlpool ...)
Double or triple hashing : g (x) = h (x) + ih (x) mod m
[1]
i 1 2
2 hash functions can mimic k hashing functions
‣ Murmur Hashes
http://code.google.com/p/smhasher/
Dillinger, Peter C.; Manolios, Panagiotis (2004b), "Bloom Filters in Probabilistic Verification",
[1]
http://www.ccs.neu.edu/home/pete/pub/bloom-filters-verification.pdf
http://www.strchr.com/hash_functions 7](https://image.slidesharecdn.com/datastructures-bloomfiltersmerkletrees-110417100758-phpapp01/85/Modern-Algorithms-and-Data-Structures-1-Bloom-Filters-Merkle-Trees-22-320.jpg)






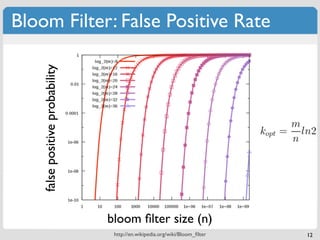




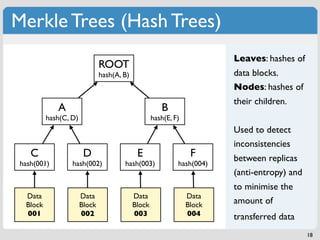
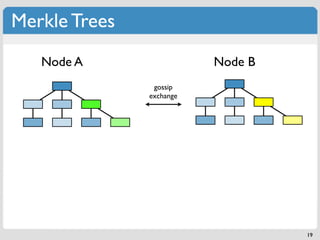
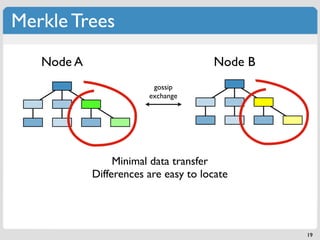
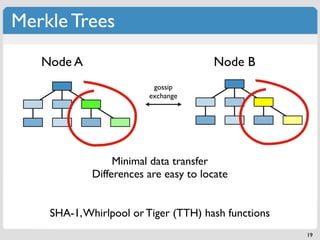

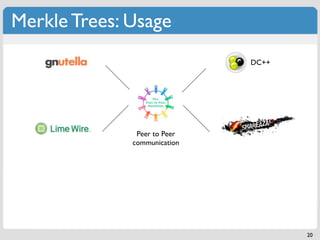
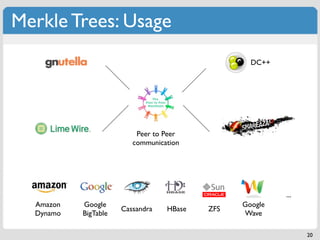







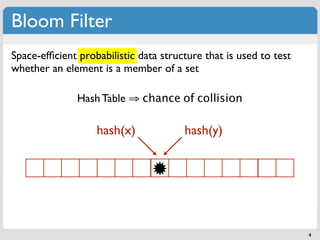
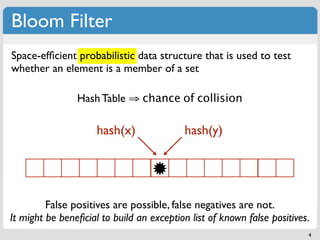
The document discusses 'modern' algorithms and data structures, focusing on Bloom filters and Merkle trees. Bloom filters are space-efficient probabilistic data structures used to test set membership with the possibility of false positives but no false negatives, and they are implemented in systems like Cassandra to optimize I/O operations. Merkle trees, on the other hand, are hash trees that ensure the integrity of data blocks exchanged in peer-to-peer networks, assisting in minimizing data transfer during consistency checks.











![Slides [DAA] Unit 2 Ch 2.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/slidesdaaunit2ch2-220916225930-a9e1cca6-thumbnail.jpg?width=640&height=640&fit=bounds)






























































